When Confidence Takes the Wrong Path: Diagnosing Retrieval-State Lock-In in RAG
Pith reviewed 2026-06-26 09:08 UTC · model grok-4.3
The pith
RAG answer agreement can signal a locked-in wrong retrieval state rather than correctness, and a three-check rule reaches 91.9% pooled precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Retrieval-state lock-in occurs when sampled answers agree because they share the same defective retrieval state rather than because the answer is correct. The paper diagnoses this by decomposing confidence into three objects: the answer surface, the retrieved evidence, and the retrieval state itself. In the tested KG-RAG system, 42% of errors at five samples carry zero answer dispersion, so agreement supplies no ranking signal, while evidence and retrieval-state checks still flag most of them. The resulting auditable decision rule accepts an answer only when answer, evidence, and retrieval checks all indicate low risk, reaching 91.9% pooled precision against a 69.7% accept-all rate and 7.7%
What carries the argument
retrieval-state lock-in, the condition in which sampled answers agree because they condition on the same defective retrieval state.
If this is right
- 42% of KG-RAG errors and 59% of dense-retrieval errors carry zero answer dispersion at five samples per question.
- Evidence and retrieval-state checks flag most zero-dispersion errors that answer agreement alone cannot rank.
- The three-check rule reaches 91.9% pooled precision while certifying 7.7% of answers as low-risk.
- On the clinical calibration domain the rule reaches 100% precision under an automated judge.
- Confidence in RAG must be treated as object-specific rather than a single black-box score.
Where Pith is reading between the lines
- Similar lock-in rates may occur in RAG architectures that were not tested in the six snapshots.
- The three-check approach could be combined with other uncertainty methods to raise coverage while preserving precision.
- Real-world deployment would still require human validation beyond the automated judge used in the clinical domain.
Load-bearing premise
The six question-answering snapshots and the particular ontology-guided KG-RAG implementation are representative enough that the measured lock-in rates and three-check rule will generalize to other RAG architectures and domains.
What would settle it
Applying the three-check rule to a RAG system or domain outside the six tested snapshots and checking whether precision stays near 91.9 percent.
Figures

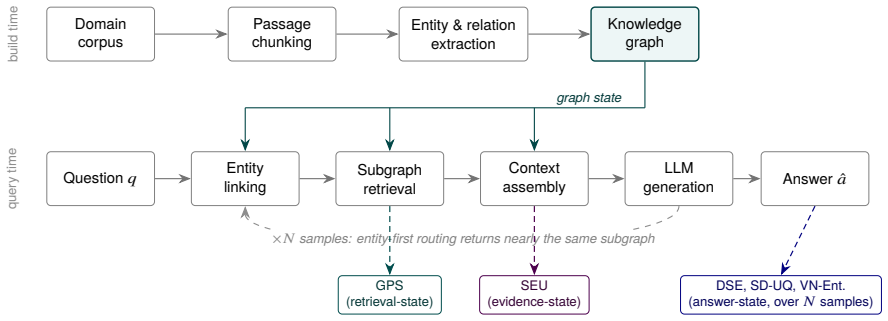
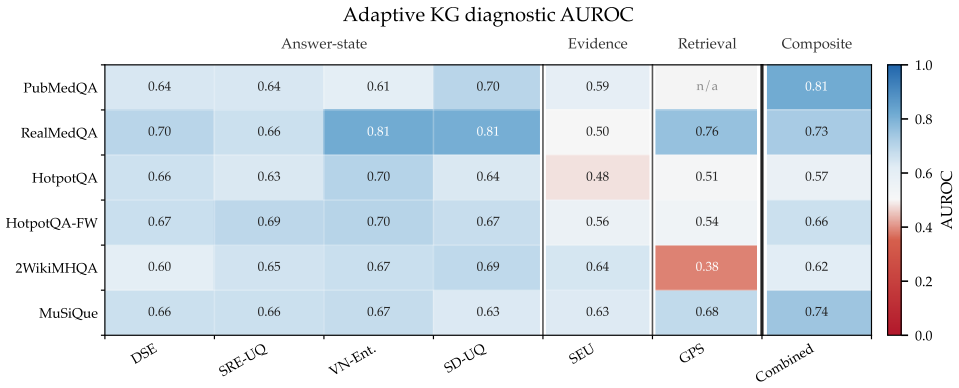
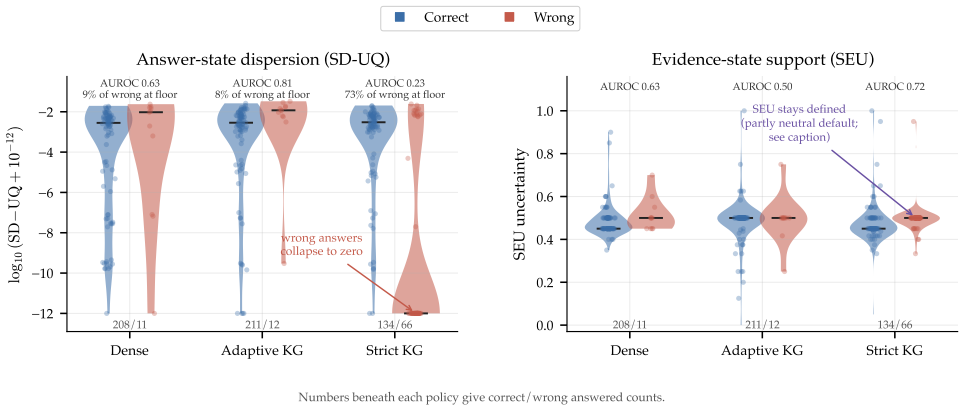

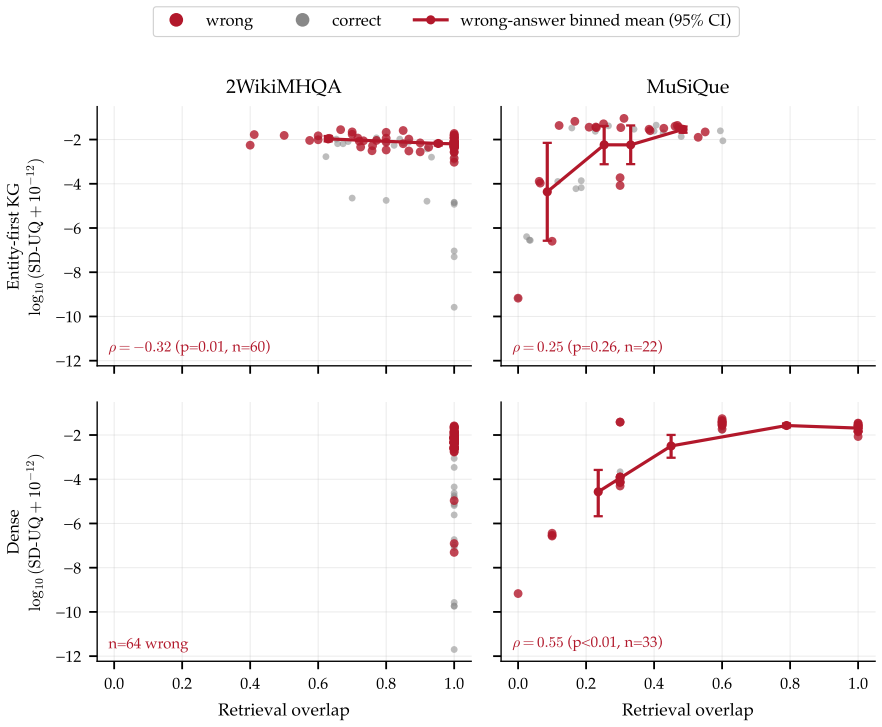

read the original abstract
The trustworthiness of a retrieval-augmented generation (RAG) system depends on more than the answer it returns, yet many black-box uncertainty methods still read agreement among sampled answers as confidence. That inference fails when repeated samples condition on the same defective retrieval state. The state may be empty, with the model falling back on parametric memory, or populated by a coherent but wrong neighbourhood. In either case, the answers agree because the error is stable. The problem is recognised in deployed RAG, but it has lacked a name, a measurable signature, and a prevalence bound. We supply all three. We name the failure retrieval-state lock-in and diagnose it by separating the three objects a single confidence score conflates: the answer surface, the retrieved evidence, and the retrieval state itself. In an inspectable, ontology-guided knowledge-graph RAG (KG-RAG) system across six question-answering snapshots, we measure the agreement blind spot directly: at five samples per question, 42% of KG-RAG errors and 59% of dense-retrieval errors carry zero answer dispersion, so agreement has nothing to rank, while evidence- and retrieval-state checks still flag most of them. The decomposition supports an auditable decision rule: accepting an answer only when answer, evidence, and retrieval checks all agree that it is low-risk reaches 91.9% pooled precision against a 69.7% accept-all rate. The cost is coverage: it certifies only 7.7% of answers as low-risk. On the clinical calibration domain it reaches 100% precision under an automated judge; this is an in-domain automated-label upper bound, not a clinical safety claim, and still needs human validation. Confidence in RAG is object-specific: when answers agree, the useful question is which part of the pipeline to distrust.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard answer-agreement based confidence in RAG can fail due to 'retrieval-state lock-in', where defective retrieval states lead to consistent but wrong answers across samples. In experiments on an ontology-guided KG-RAG system with six QA snapshots, they find 42% of KG-RAG errors and 59% of dense-retrieval errors have zero answer dispersion at 5 samples. They introduce a three-check rule (answer, evidence, retrieval-state) that achieves 91.9% precision at 7.7% coverage, compared to 69.7% for accepting all, with 100% on clinical domain under automated judge.
Significance. This work offers a concrete diagnosis and measurable signature for a recognized issue in RAG trustworthiness, along with an auditable decision rule that trades coverage for higher precision. The explicit decomposition of answer, evidence, and retrieval state, and the reporting of specific percentages on a real system, provide useful empirical grounding. If the lock-in phenomenon and the rule's performance hold more broadly, it could inform better uncertainty estimation practices in retrieval-augmented systems.
major comments (2)
- [Experimental results on six snapshots] The reported lock-in rates of 42% for KG-RAG and 59% for dense-retrieval errors with zero dispersion lack error bars, statistical tests, or confidence intervals, which weakens the strength of the claim that agreement has nothing to rank in these cases.
- [Abstract and experimental setup] The prevalence bounds and the 91.9% precision of the three-check rule are derived from a single ontology-guided KG-RAG implementation plus dense baseline; no replication or ablation on standard vector RAG, LLM rerankers, or other domains is provided, making generalization to deployed RAG systems a load-bearing assumption that requires further support.
minor comments (1)
- [Clinical calibration domain] The 100% precision result is correctly labeled as an automated upper bound requiring human validation, but the presentation could more explicitly discuss the limitations of the automated judge.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our results. We address each major comment below.
read point-by-point responses
-
Referee: [Experimental results on six snapshots] The reported lock-in rates of 42% for KG-RAG and 59% for dense-retrieval errors with zero dispersion lack error bars, statistical tests, or confidence intervals, which weakens the strength of the claim that agreement has nothing to rank in these cases.
Authors: We agree this is a valid point. The six snapshots provide the basis for the pooled rates, but we did not report uncertainty. In the revised manuscript we will add bootstrap confidence intervals computed by resampling across snapshots and will report per-snapshot variation where feasible. This will make the descriptive claim about zero-dispersion subsets more robust while preserving the core observation that agreement supplies no ranking information inside those subsets. revision: yes
-
Referee: [Abstract and experimental setup] The prevalence bounds and the 91.9% precision of the three-check rule are derived from a single ontology-guided KG-RAG implementation plus dense baseline; no replication or ablation on standard vector RAG, LLM rerankers, or other domains is provided, making generalization to deployed RAG systems a load-bearing assumption that requires further support.
Authors: The choice of an ontology-guided, inspectable KG-RAG system was deliberate: only in such a setting can the retrieval state be directly audited to diagnose lock-in. The dense baseline serves as a controlled contrast rather than a comprehensive ablation. We do not assert that the exact 42 % / 59 % or 91.9 % figures generalize; the contribution is the identification of the failure mode and the three-object decomposition. In revision we will expand the limitations and discussion sections to state the scope explicitly and to call for replication on black-box vector RAG and other domains. revision: partial
Circularity Check
No significant circularity; empirical measurements are direct and self-contained
full rationale
The paper reports direct empirical counts of zero-dispersion errors (42% KG-RAG, 59% dense) and the measured precision (91.9%) of a rule that requires agreement across three distinct pipeline objects on held-out snapshots. No equations or derivations reduce a claimed result to a fitted parameter or self-citation by construction; the decision rule is not optimized against the target metric but evaluated as a conservative conjunction, and no load-bearing premise depends on prior author work. The analysis remains within its stated experimental scope without renaming known results or smuggling ansatzes.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of samples
axioms (1)
- domain assumption The KG-RAG implementation provides inspectable retrieval states that can be checked independently of the generated answer.
invented entities (1)
-
retrieval-state lock-in
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amugongo, Paola Mascheroni, Sarah Brooks, Susanne Doering, and Jan Seidel
Lameck Mbangula Amugongo, Pietro Mascheroni, Steven Geoffrey Brooks, Stefan Doering, and Jan Seidel. Retrieval augmented generation for large language models in healthcare: A systematic review. PLOS Digital Health, 4 0 (6): 0 e0000877, 2025. doi:10.1371/journal.pdig.0000877. URL https://journals.plos.org/digitalhealth/article?id=10.1371/journal.pdig.0000877
-
[2]
Self-RAG : Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG : Learning to retrieve, generate, and critique through self-reflection. In International Conference on Learning Representations (ICLR), 2024
2024
-
[3]
INTRYGUE : Induction-aware entropy gating for reliable RAG uncertainty estimation
Alexandra Bazarova, Andrei Volodichev, Daria Kotova, and Alexey Zaytsev. INTRYGUE : Induction-aware entropy gating for reliable RAG uncertainty estimation. arXiv preprint arXiv:2603.21607, 2026
arXiv 2026
-
[4]
Campos, Ant \'o nio Farinhas, Chrysoula Zerva, M \'a rio A
Margarida M. Campos, Ant \'o nio Farinhas, Chrysoula Zerva, M \'a rio A. T. Figueiredo, and Andr \'e F. T. Martins. Conformal prediction for natural language processing: A survey. Transactions of the Association for Computational Linguistics, 12: 0 1619--1638, 2024. doi:10.1162/tacl_a_00715
- [5]
-
[6]
From local to global: A graph RAG approach to query-focused summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[7]
RAGA s: Automated Evaluation of Retrieval Augmented Generation
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. RAGAs : Automated evaluation of retrieval augmented generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, pages 150--158, 2024. doi:10.18653/v1/2024.eacl-demo.16. URL https://aclanthology.org/2024...
-
[8]
Ekaterina Fadeeva, Aleksandr Rubashevskii, Dzianis Piatrashyn, Roman Vashurin, Shehzaad Dhuliawala, Artem Shelmanov, Timothy Baldwin, Preslav Nakov, Mrinmaya Sachan, and Maxim Panov. Faithfulness-aware uncertainty quantification for fact-checking the output of retrieval augmented generation. arXiv preprint arXiv:2505.21072, 2025
Pith/arXiv arXiv 2025
-
[9]
Detecting hallucinations in large language models using semantic entropy
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy. Nature, 630: 0 625--630, 2024
2024
-
[10]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[11]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), 2017
2017
-
[12]
HippoRAG : Neurobiologically inspired long-term memory for large language models
Bernal Jim \'e nez Guti \'e rrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG : Neurobiologically inspired long-term memory for large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[13]
Haoyu Han, Li Ma, Yu Wang, Harry Shomer, Yongjia Lei, Zhisheng Qi, Kai Guo, Zhigang Hua, Bo Long, Hui Liu, Charu C. Aggarwal, and Jiliang Tang. RAG vs.\ GraphRAG : A systematic evaluation and key insights. arXiv preprint arXiv:2502.11371, 2025
arXiv 2025
-
[14]
DeBERTa : Decoding-enhanced BERT with disentangled attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. DeBERTa : Decoding-enhanced BERT with disentangled attention. In International Conference on Learning Representations (ICLR), 2021. URL https://openreview.net/forum?id=XPZIaotutsD
2021
-
[15]
Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V. Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. G-Retriever : Retrieval-augmented generation for textual graph understanding and question answering. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[16]
Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. In Proceedings of the 28th International Conference on Computational Linguistics (COLING), 2020
2020
-
[17]
GRAG : Graph Retrieval-Augmented Generation
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, and Liang Zhao. GRAG : Graph retrieval-augmented generation. In Findings of the Association for Computational Linguistics: NAACL 2025 , pages 4145--4157, 2025. doi:10.18653/v1/2025.findings-naacl.232. URL https://aclanthology.org/2025.findings-naacl.232/
-
[18]
TrustLLM : Trustworthiness in Large Language Models
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, Xiner Li, et al. TrustLLM : Trustworthiness in Large Language Models . arXiv preprint arXiv:2401.05561, 2024
Pith/arXiv arXiv 2024
-
[19]
StructGPT : A general framework for large language model to reason over structured data
Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Xin Zhao, and Ji-Rong Wen. StructGPT : A general framework for large language model to reason over structured data. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023 a
2023
-
[20]
Active Retrieval Augmented Generation
Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969--7992, Singapore, 2023 b . Association for Computational Linguistics. doi:10.18653/v1/2023.emn...
-
[21]
Language models (mostly) know what they know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
Pith/arXiv arXiv 2022
-
[22]
Semantic entropy probes: Robust and cheap hallucination detection in LLMs
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in LLMs . In International Conference on Learning Representations (ICLR), 2025
2025
-
[23]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In International Conference on Learning Representations (ICLR), 2023
2023
-
[24]
Chorok Lee. Decomposing uncertainty in probabilistic knowledge graph embeddings: Why entity variance is not enough. arXiv preprint arXiv:2512.22318, 2025
arXiv 2025
-
[25]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[26]
Simple is effective: The roles of graphs and large language models in knowledge-graph-based retrieval-augmented generation
Mufei Li, Siqi Miao, and Pan Li. Simple is effective: The roles of graphs and large language models in knowledge-graph-based retrieval-augmented generation. In International Conference on Learning Representations (ICLR), 2025 a
2025
-
[27]
Citation-enhanced generation for LLM -based chatbots
Weitao Li, Junkai Li, Weizhi Ma, and Yang Liu. Citation-enhanced generation for LLM -based chatbots. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1451--1466, 2024 a . doi:10.18653/v1/2024.acl-long.79. URL https://aclanthology.org/2024.acl-long.79/
-
[28]
Semantic volume: Quantifying and detecting both external and internal uncertainty in LLMs
Xiaomin Li, Zhou Yu, Ziji Zhang, Yingying Zhuang, Swair Shah, Narayanan Sadagopan, and Anurag Beniwal. Semantic volume: Quantifying and detecting both external and internal uncertainty in LLMs . arXiv preprint arXiv:2502.21239, 2025 b
arXiv 2025
-
[29]
Zixuan Li, Jing Xiong, Fanghua Ye, Chuanyang Zheng, Xun Wu, Jianqiao Lu, Zhongwei Wan, Xiaodan Liang, Chengming Li, Zhenan Sun, Lingpeng Kong, and Ngai Wong. UncertaintyRAG : Span-level uncertainty enhanced long-context modeling for retrieval-augmented generation. arXiv preprint arXiv:2410.02719, 2024 b
arXiv 2024
-
[30]
Teaching models to express their uncertainty in words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words. In Transactions of the Association for Computational Linguistics (TACL), 2022
2022
-
[31]
CtrlA : Adaptive retrieval-augmented generation via inherent control
Huanshuo Liu, Hao Zhang, Zhijiang Guo, Jing Wang, Kuicai Dong, Xiangyang Li, Yi Quan Lee, Cong Zhang, and Yong Liu. CtrlA : Adaptive retrieval-augmented generation via inherent control. In Findings of the Association for Computational Linguistics: ACL 2025, pages 12592--12618, Vienna, Austria, 2025. Association for Computational Linguistics. doi:10.18653/...
-
[32]
Jiayu Liu, Rui Wang, Qing Zong, Yumeng Wang, Cheng Qian, Qingcheng Zeng, Tianshi Zheng, Haochen Shi, Dadi Guo, Baixuan Xu, Chunyang Li, and Yangqiu Song. NAACL : Noise- A w A re verbal confidence calibration for robust large language models in RAG systems. arXiv preprint arXiv:2601.11004, 2026 a
Pith/arXiv arXiv 2026
-
[33]
TruthfulRAG : Resolving factual-level conflicts in retrieval-augmented generation with knowledge graphs
Shuyi Liu, Yuming Shang, and Xi Zhang. TruthfulRAG : Resolving factual-level conflicts in retrieval-augmented generation with knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, 2026 b
2026
-
[34]
Reasoning on graphs: Faithful and interpretable large language model reasoning
Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. Reasoning on graphs: Faithful and interpretable large language model reasoning. In International Conference on Learning Representations (ICLR), 2024
2024
-
[35]
Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation
Shengjie Ma, Chengjin Xu, Xuhui Jiang, Muzhi Li, Huaren Qu, Cehao Yang, Jiaxin Mao, and Jian Guo. Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation. In International Conference on Learning Representations (ICLR), 2025
2025
-
[36]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. SelfCheckGPT : Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[37]
GNN-RAG : Graph neural retrieval for large language model reasoning
Costas Mavromatis and George Karypis. GNN-RAG : Graph neural retrieval for large language model reasoning. In Findings of the Association for Computational Linguistics (ACL), 2025
2025
-
[38]
Adaptive retrieval without self-knowledge? bringing uncertainty back home
Viktor Moskvoretskii, Maria Marina, Mikhail Salnikov, Nikolay Ivanov, Sergey Pletenev, Daria Galimzianova, Nikita Krayko, Vasily Konovalov, Irina Nikishina, and Alexander Panchenko. Adaptive retrieval without self-knowledge? bringing uncertainty back home. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1...
-
[39]
Towards trustworthy retrieval augmented generation for large language models: A survey
Bo Ni, Zheyuan Liu, Leyao Wang, Yongjia Lei, Yuying Zhao, Xueqi Cheng, Qingkai Zeng, Luna Dong, Yinglong Xia, Krishnaram Kenthapadi, et al. Towards trustworthy retrieval augmented generation for large language models: A survey. arXiv preprint arXiv:2502.06872, 2025
arXiv 2025
-
[40]
Kernel language entropy: Fine-grained uncertainty quantification for LLMs from semantic similarities
Alexander Nikitin, Jannik Kossen, Yarin Gal, and Pekka Marttinen. Kernel language entropy: Fine-grained uncertainty quantification for LLMs from semantic similarities. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[41]
GPT-4o mini : Advancing cost-efficient intelligence
OpenAI . GPT-4o mini : Advancing cost-efficient intelligence. Technical report, OpenAI, 2024. URL https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/
2024
-
[42]
Bowman, and Shi Feng
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. In Advances in Neural Information Processing Systems 37 (NeurIPS), 2024
2024
-
[43]
Graph retrieval-augmented generation: A survey
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. Graph retrieval-augmented generation: A survey. ACM Transactions on Information Systems , 2024
2024
-
[44]
Uncertainty quantification in retrieval augmented question answering
Laura Perez-Beltrachini and Mirella Lapata. Uncertainty quantification in retrieval augmented question answering. Transactions on Machine Learning Research (TMLR), 2025
2025
-
[45]
Jingxi Qiu, Zeyu Han, and Cheng Huang. SURE-RAG : Sufficiency and uncertainty-aware evidence verification for selective retrieval-augmented generation. arXiv preprint arXiv:2605.03534, 2026
Pith/arXiv arXiv 2026
-
[46]
Semantic density: Uncertainty quantification for large language models through confidence measurement in semantic space
Xin Qiu and Risto Miikkulainen. Semantic density: Uncertainty quantification for large language models through confidence measurement in semantic space. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[47]
Sentence- BERT : Sentence embeddings using siamese BERT -networks
Nils Reimers and Iryna Gurevych. Sentence- BERT : Sentence embeddings using siamese BERT -networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019
2019
-
[48]
Jing Ren, Bowen Li, Ziqi Xu, Xikun Zhang, Haytham Fayek, and Xiaodong Li. When to trust: A causality-aware calibration framework for accurate knowledge graph retrieval-augmented generation. arXiv preprint arXiv:2601.09241, 2026
arXiv 2026
-
[49]
ARES : An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. ARES : An automated evaluation framework for retrieval-augmented generation systems. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 338--354, Mexico City, Mexico, 2024. Association f...
-
[50]
Zhili Shen, Chenxin Diao, Pavlos Vougiouklis, Pascual Merita, Shriram Piramanayagam, Enting Chen, Damien Graux, Andre Melo, Ruofei Lai, Zeren Jiang, Zhongyang Li, Ye Qi, Yang Ren, Dandan Tu, and Jeff Z. Pan. GeAR : Graph-enhanced agent for retrieval-augmented generation. In Findings of the Association for Computational Linguistics: ACL 2025 , pages 12049-...
-
[51]
Why uncertainty estimation methods fall short in RAG : An axiomatic analysis
Heydar Soudani, Evangelos Kanoulas, and Faegheh Hasibi. Why uncertainty estimation methods fall short in RAG : An axiomatic analysis. In Findings of the Association for Computational Linguistics: ACL 2025, pages 16596--16616, Vienna, Austria, 2025 a . Association for Computational Linguistics. URL https://aclanthology.org/2025.findings-acl.852/
2025
-
[52]
Uncertainty quantification for retrieval-augmented reasoning
Heydar Soudani, Hamed Zamani, and Faegheh Hasibi. Uncertainty quantification for retrieval-augmented reasoning. arXiv preprint arXiv:2510.11483, 2025 b
Pith/arXiv arXiv 2025
-
[53]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. DRAGIN : Dynamic retrieval augmented generation based on the real-time information needs of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12991--13013, Bangkok, Thailand, 2024. Association for C...
-
[54]
Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Shengjie Wang, Chen Lin, Yeyun Gong, Heung-Yeung Shum, and Jian Guo. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph. In International Conference on Learning Representations (ICLR), 2024
2024
-
[55]
Uncertainty-aware dynamic knowledge graphs for reliable question answering
Yu Takahashi, Shun Takeuchi, Kexuan Xin, Guillaume Pelat, Yoshiaki Ikai, Junya Saito, Jonathan Vitale, Shlomo Berkovsky, and Amin Beheshti. Uncertainty-aware dynamic knowledge graphs for reliable question answering. arXiv preprint arXiv:2601.09720, 2026
arXiv 2026
-
[56]
Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D. Manning, and Chelsea Finn. Does my LLM need a better evaluator? Just ask for calibration. In arXiv preprint arXiv:2310.02415, 2023
arXiv 2023
-
[57]
Uncertainty-based abstention in LLMs improves safety and reduces hallucinations
Christian Tomani, Kamalika Chaudhuri, Ivan Evtimov, Daniel Cremers, and Mark Ibrahim. Uncertainty-based abstention in LLMs improves safety and reduces hallucinations. arXiv preprint arXiv:2404.10960, 2024
arXiv 2024
-
[58]
MuSiQue : Multihop questions via single-hop question composition
Harsh Trivedi, Niranjan Bauer, Tushar Khot, and Ashish Sabharwal. MuSiQue : Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10: 0 539--554, 2022
2022
-
[59]
Pragatheeswaran Vipulanandan, Kamal Premaratne, and Dilip Sarkar. Semantic uncertainty quantification of hallucinations in LLMs : A quantum tensor network based method. arXiv preprint arXiv:2601.20026, 2026
arXiv 2026
-
[60]
L-RAG : Balancing context and retrieval with entropy-based lazy loading
Sergii Voloshyn. L-RAG : Balancing context and retrieval with entropy-based lazy loading. arXiv preprint arXiv:2601.06551, 2026
arXiv 2026
-
[61]
Gruber, Thomas Decker, Yinchong Yang, Alireza Javanmardi, Eyke H \"u llermeier, and Florian Buettner
Nassim Walha, Sebastian G. Gruber, Thomas Decker, Yinchong Yang, Alireza Javanmardi, Eyke H \"u llermeier, and Florian Buettner. Fine-grained uncertainty decomposition in large language models: A spectral approach. arXiv preprint arXiv:2509.22272, 2025
arXiv 2025
-
[62]
Correctness is not faithfulness in retrieval augmented generation attributions
Jonas Wallat, Maria Heuss, Maarten de Rijke, and Avishek Anand. Correctness is not faithfulness in retrieval augmented generation attributions. In Proceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval, pages 22--32. Association for Computing Machinery, 2025. doi:10.1145/3731120.3744592
-
[63]
Fei Wang, Xingchen Wan, Ruoxi Sun, Jiefeng Chen, and Sercan O. Arik. Astute RAG : Overcoming imperfect retrieval augmentation and knowledge conflicts for large language models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, 2025
2025
-
[64]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In Proceedings of the Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[65]
Augmenting textual generation via topology aware retrieval
Yu Wang, Nedim Lipka, Ruiyi Zhang, Alexa Siu, Yuying Zhao, Bo Ni, Xin Wang, Ryan Rossi, and Tyler Derr. Augmenting textual generation via topology aware retrieval. arXiv preprint arXiv:2405.17602, 2024. doi:10.48550/arXiv.2405.17602
-
[66]
Junde Wu, Jiayuan Zhu, Yunli Qi, Jingkun Chen, Min Xu, Filippo Menolascina, Yueming Jin, and Vicente Grau. Medical graph RAG : Evidence-based medical large language model via graph retrieval-augmented generation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 28443--28467, 2025. do...
-
[67]
Kevin Wu, Eric Wu, Ally Cassasola, Angela Zhang, Kevin Wei, Teresa Nguyen, Sith Riantawan, Patricia Shi Riantawan, Daniel E. Ho, and James Zou. How well do LLMs cite relevant medical references? A n evaluation framework and analyses. arXiv preprint arXiv:2402.02008, 2024 a
arXiv 2024
-
[68]
ClashEval : Quantifying the tug-of-war between an LLM 's internal prior and external evidence
Kevin Wu, Eric Wu, and James Zou. ClashEval : Quantifying the tug-of-war between an LLM 's internal prior and external evidence. arXiv preprint arXiv:2404.10198, 2024 b
arXiv 2024
-
[69]
When to use graphs in RAG : A comprehensive analysis for graph retrieval-augmented generation
Zhishang Xiang, Chuanjie Wu, Qinggang Zhang, Shengyuan Chen, Zijin Hong, Xiao Huang, and Jinsong Su. When to use graphs in RAG : A comprehensive analysis for graph retrieval-augmented generation. arXiv preprint arXiv:2506.05690, 2025
arXiv 2025
-
[70]
Corrective retrieval augmented generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation. arXiv preprint arXiv:2401.15884, 2024
Pith/arXiv arXiv 2024
-
[71]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018
2018
-
[72]
SeaKR : Self-aware knowledge retrieval for adaptive retrieval augmented generation
Zijun Yao, Weijian Qi, Liangming Pan, Shulin Cao, Linmei Hu, Liu Weichuan, Lei Hou, and Juanzi Li. SeaKR : Self-aware knowledge retrieval for adaptive retrieval augmented generation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 27022--27043, Vienna, Austria, 2025. Association for...
-
[73]
FaithfulRAG : Fact-level conflict modeling for context-faithful retrieval-augmented generation
Qinggang Zhang, Zhishang Xiang, Yilin Xiao, Le Wang, Junhui Li, Xinrun Wang, and Jinsong Su. FaithfulRAG : Fact-level conflict modeling for context-faithful retrieval-augmented generation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pages 21863--21882. Association for Computational Linguistics, 2025. URL htt...
2025
-
[74]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM -as-a-judge with MT -bench and chatbot arena. In Advances in Neural Information Processing Systems 36 (NeurIPS), Datasets and Benchmarks Track, 2023
2023
-
[75]
Wenqing Zheng, Dmitri Kalaev, Noah Fatsi, Daniel Barcklow, Owen Reinert, Igor Melnyk, Senthil Kumar, and C. Bayan Bruss. Revisiting RAG retrievers: An information theoretic benchmark. arXiv preprint arXiv:2602.21553, 2026
arXiv 2026
-
[76]
Poisoning retrieval corpora by injecting adversarial passages
Zexuan Zhong, Ziqing Huang, Alexander Wettig, and Danqi Chen. Poisoning retrieval corpora by injecting adversarial passages. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[77]
What breaks knowledge graph based RAG ? benchmarking and empirical insights into reasoning under incomplete knowledge
Dongzhuoran Zhou, Yuqicheng Zhu, Xiaxia Wang, Hongkuan Zhou, Yuan He, Jiaoyan Chen, Steffen Staab, and Evgeny Kharlamov. What breaks knowledge graph based RAG ? benchmarking and empirical insights into reasoning under incomplete knowledge. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2026
2026
-
[78]
A dihy- dropyridine calcium channel blocker that relaxes vascular smooth muscle
Xiangrong Zhu, Yuexiang Xie, Yi Liu, Yaliang Li, and Wei Hu. Knowledge graph-guided retrieval augmented generation. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8912--8924, 2025 a . doi:10.18653/v1/2025.naacl-long.44...
-
[79]
Certainty in uncertainty: Reasoning over uncertain knowledge graphs with statistical guarantees
Yuqicheng Zhu, Jingcheng Wu, Yizhen Wang, Hongkuan Zhou, Jiaoyan Chen, Evgeny Kharlamov, and Steffen Staab. Certainty in uncertainty: Reasoning over uncertain knowledge graphs with statistical guarantees. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 8730--8752, 2025 b . doi:10.18653/v1/2025.emnlp-main.44...
-
[80]
Two-tiered encoder-based hallucination detection for retrieval-augmented generation in the wild
Ilana Zimmerman, Jadin Tredup, Ethan Selfridge, and Joseph Bradley. Two-tiered encoder-based hallucination detection for retrieval-augmented generation in the wild. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 8--22, Miami, Florida, US, 2024. Association for Computational Linguistics. doi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.