Finding the Evidence: Discovering Decision-Supporting Tokens for On-Policy Reasoning Distillation
Pith reviewed 2026-06-26 08:48 UTC · model grok-4.3
The pith
On-policy reasoning distillation transfers more knowledge when evidence tokens that justify decisions are discovered via entropy and hidden-state similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
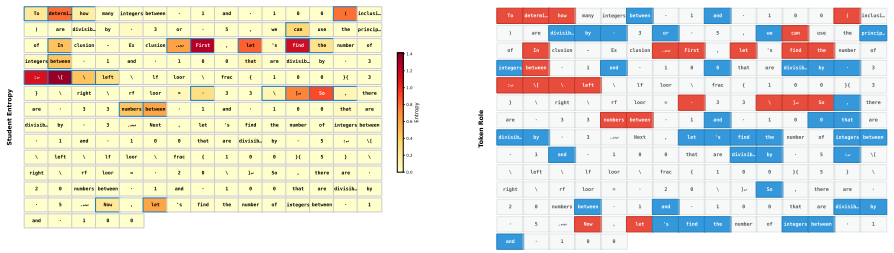
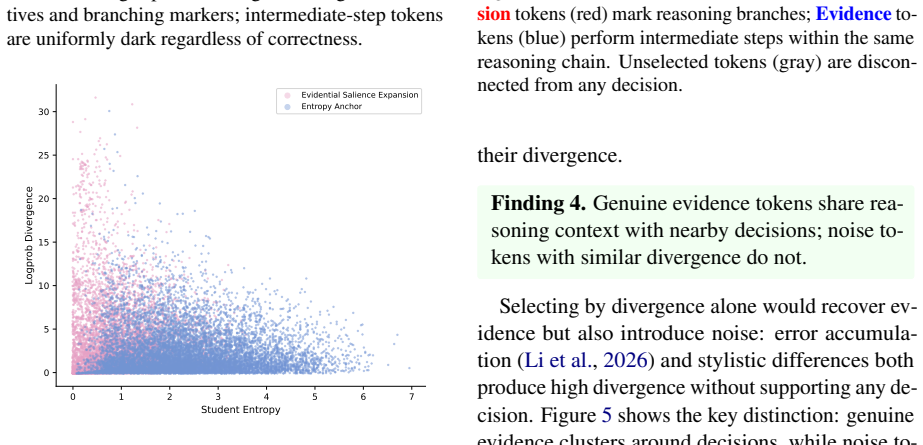
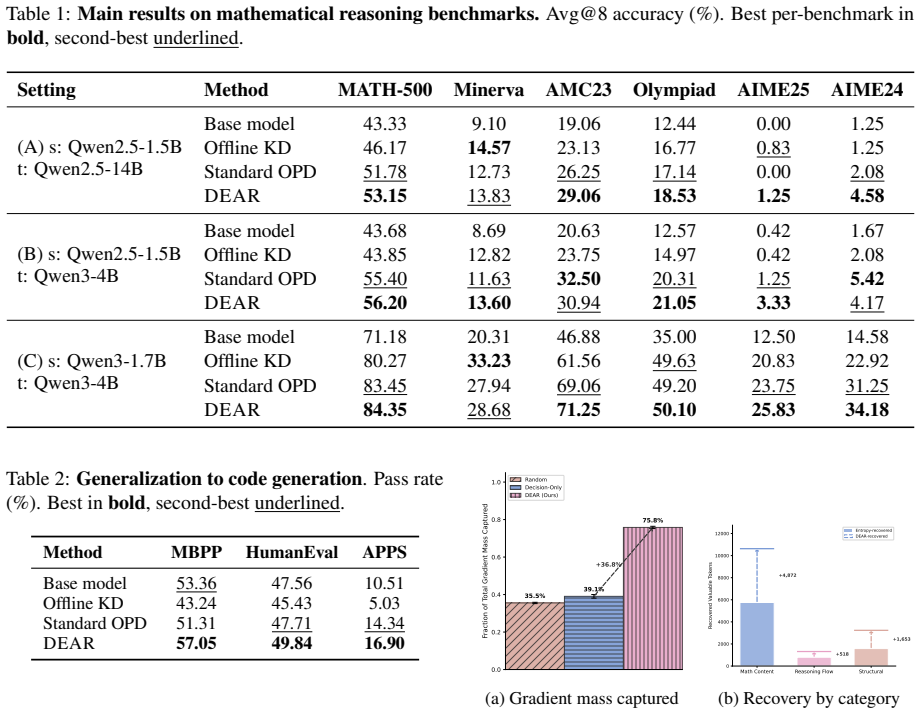
Reasoning chains contain two distinct kinds of knowledge: decisions, which surface through student entropy, and evidence, which appears at positions where the student is confident yet incorrect; DEAR locates the evidence tokens by computing hidden-state cosine similarity to the entropy-selected decision anchors and weighting them by teacher-student divergence to emphasize the largest knowledge gaps, allowing both types of tokens to receive targeted supervision during on-policy distillation.
What carries the argument
DEAR's evidence discovery mechanism, which ranks tokens by hidden-state cosine similarity to entropy-identified decision anchors boosted by teacher-student divergence.
If this is right
- Student models reach higher accuracy on competition math problems after distillation.
- Code generation performance increases on standard benchmarks.
- The gains appear consistently across different student-teacher model size pairs.
- Evidence tokens identified this way contain the intermediate steps missed by decision-only supervision.
Where Pith is reading between the lines
- The same selection logic could be tested on non-math reasoning tasks such as logical deduction or scientific explanation.
- Overconfident student errors may systematically mark the locations where human-like justification is needed.
- Human inspection of the selected tokens could check whether they align with the actual logical steps used in correct solutions.
- Replacing cosine similarity with other representation distances might change which evidence is chosen and affect final gains.
Load-bearing premise
The tokens selected by entropy followed by hidden-state cosine similarity to decision anchors are the actual evidence that justifies the decisions and carries the transferable knowledge.
What would settle it
An ablation that removes or randomizes the evidence-selection step and shows that the performance gains on math and code benchmarks disappear.
Figures







read the original abstract
On-policy distillation transfers reasoning ability through dense token-level supervision, yet the nature of the transferable signal remains unclear. We discover that reasoning chains contain two types of knowledge that require different discovery mechanisms: decisions (where to branch), which surface through student uncertainty, and evidence (intermediate steps that justify decisions), which hides in positions where the student is confident yet wrong. Current methods capture only decisions; the substantive knowledge in evidence tokens remains untransferred. We propose DEAR(Decision-Evidence Aware Reasoning Distillation), which first identifies decisions via student entropy, then discovers their supporting evidence through hidden-state cosine similarity to decision anchors, boosted by teacher-student divergence to prioritize the largest knowledge gaps. Across three student-teacher configurations on math and code benchmarks, DEAR consistently outperforms standard OPD, with up to +2.5pp on competition math and +5.7pp on code generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on-policy reasoning distillation transfers two distinct types of knowledge—decisions (identified via student entropy) and evidence (intermediate justifying steps hidden in confident-but-wrong positions)—and proposes DEAR to discover the latter via hidden-state cosine similarity to decision anchors, modulated by teacher-student divergence. It reports that DEAR outperforms standard OPD across three student-teacher pairs on math and code benchmarks, with gains up to +2.5pp on competition math and +5.7pp on code generation.
Significance. If the cosine-similarity procedure is shown to isolate causally relevant evidence tokens rather than correlated high-uncertainty positions, the work would provide a concrete mechanism for more targeted knowledge transfer in reasoning distillation and a useful decomposition of what is learned during on-policy training. The empirical gains are modest but consistent; the primary value would lie in establishing the mechanistic interpretation rather than the raw numbers alone.
major comments (2)
- [Experiments] Experiments section: the attribution of the reported gains (+2.5pp math, +5.7pp code) to the evidence-discovery step is not supported by any ablation that removes or perturbs only the cosine-similarity component while retaining entropy-based decision selection and divergence boosting; without such controls it is impossible to rule out that the benefit arises from simply surfacing high-divergence tokens irrespective of the 'evidence' framing.
- [Method] Method section (DEAR description): the claim that hidden-state cosine similarity to decision anchors isolates 'substantive evidence that justifies decisions' is presented as the core innovation, yet no direct validation (counterfactual token masking, human relevance ratings, or comparison against random high-entropy tokens) is provided to establish that these tokens carry the transferable justifying knowledge rather than a non-causal correlate.
minor comments (1)
- [Abstract] Abstract: the phrase 'three student-teacher configurations' is used without naming the models or datasets, which would aid immediate assessment of scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight the need for stronger controls to attribute gains specifically to the evidence-discovery mechanism. We address each point below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the attribution of the reported gains (+2.5pp math, +5.7pp code) to the evidence-discovery step is not supported by any ablation that removes or perturbs only the cosine-similarity component while retaining entropy-based decision selection and divergence boosting; without such controls it is impossible to rule out that the benefit arises from simply surfacing high-divergence tokens irrespective of the 'evidence' framing.
Authors: We agree that the current experiments compare full DEAR against standard on-policy distillation but lack a targeted ablation that disables only the cosine-similarity step while retaining entropy-based decision selection and divergence modulation. This limits causal attribution of the gains. We will add this ablation (and the corresponding results) in the revised manuscript. revision: yes
-
Referee: [Method] Method section (DEAR description): the claim that hidden-state cosine similarity to decision anchors isolates 'substantive evidence that justifies decisions' is presented as the core innovation, yet no direct validation (counterfactual token masking, human relevance ratings, or comparison against random high-entropy tokens) is provided to establish that these tokens carry the transferable justifying knowledge rather than a non-causal correlate.
Authors: The manuscript motivates the cosine-similarity procedure from the observed pattern that evidence tokens appear in confident-but-wrong positions and reports consistent empirical gains across three student-teacher pairs. However, we acknowledge that direct causal validations such as token-masking experiments, human ratings, or explicit comparison to random high-entropy tokens are absent. We will include additional analysis addressing this in the revision. revision: yes
Circularity Check
No significant circularity; empirical method evaluated on external benchmarks
full rationale
The paper defines DEAR procedurally (entropy for decisions, cosine similarity plus divergence for evidence) and reports benchmark gains on math/code tasks. No equations, fitted parameters, or self-citations are shown that reduce any claimed result to its inputs by construction. The derivation chain consists of an algorithmic procedure whose outputs are measured against independent test sets, making the reported improvements non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InInternational Conference on Learning Representations, volume 2024, pages 21246–21263
On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, volume 2024, pages 21246–21263. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and 1 others
2024
-
[2]
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, Hao Peng, Yu Cheng, and 4 others
-
[3]
Process Reinforcement through Implicit Rewards. CoRR, abs/2502.01456. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, and 1 others
-
[4]
arXiv preprint arXiv:2405.16064
Keypoint-based progressive chain-of-thought distillation for llms. arXiv preprint arXiv:2405.16064. Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, and Baobao Chang
-
[5]
InThe Thirteenth Inter- national Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
Omni-MATH: A Uni- versal Olympiad Level Mathematic Benchmark for Large Language Models. InThe Thirteenth Inter- national Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[6]
InInternational Conference on Learning Representations, volume 2024, pages 32694–32717
Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, volume 2024, pages 32694–32717. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yu- jie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun
2024
-
[7]
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. InProceedings of the 62nd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thai- land, August 11-16, 2024, pages 3828–3850. Associ- ation for Computational Linguistics. Zhiwei H...
2024
-
[8]
DeepMath-103K: A Large-Scale, Challenging, De- contaminated, and Verifiable Mathematical Dataset for Advancing Reasoning.CoRR, abs/2504.11456. Dan Hendrycks, Steven Basart, Saurav Kadavath, Man- tas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt
-
[9]
InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Bench- marks 2021, December 2021, virtual
Measuring Coding Challenge Com- petence With APPS. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Bench- marks 2021, December 2021, virtual. Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean
2021
-
[10]
Distilling the knowledge in a neural network. CoRR, abs/1503.02531. Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee
-
[11]
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron
Entropy-aware on-policy distillation of language models.arXiv preprint arXiv:2603.07079. Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron
-
[12]
Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, and 1 others
-
[13]
arXiv preprint arXiv:2604.13016
Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe. arXiv preprint arXiv:2604.13016. Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Ling- ming Zhang
-
[14]
InAdvances in Neural Information Processing Systems 36: An- nual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,
Is Your Code Generated by Chat- GPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. InAdvances in Neural Information Processing Systems 36: An- nual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,
2023
-
[15]
Demystifying opd: Length in- flation and stabilization strategies for large language models.arXiv preprint arXiv:2604.08527. MAA
-
[16]
Changshuo Shen, Leheng Sheng, Yuxin Chen, An Zhang, and Xiang Wang
The linear representation hypothesis and the ge- ometry of large language models.arXiv preprint arXiv:2311.03658. Changshuo Shen, Leheng Sheng, Yuxin Chen, An Zhang, and Xiang Wang
-
[17]
Reasoning can be restored by correcting a few decision tokens.arXiv preprint arXiv:2605.16874. Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu
-
[18]
InProceedings of the Twentieth European Conference on Computer Systems, EuroSys 2025, Rotterdam, The Netherlands, 30 March 2025 - 3 April 2025, pages 1279–1297
HybridFlow: A Flexible and Efficient RLHF Framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys 2025, Rotterdam, The Netherlands, 30 March 2025 - 3 April 2025, pages 1279–1297. ACM. Qwen Team
2025
-
[19]
Ian Tenney, Dipanjan Das, and Ellie Pavlick
Qwen3 Technical Report.CoRR, abs/2505.09388. Ian Tenney, Dipanjan Das, and Ellie Pavlick
-
[20]
Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084. An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayi- heng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Ji- axi Yang, Jingren Zhou, Junyang Lin, Kai Dang, and 22 others
-
[21]
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin
Qwen2.5 Technical Report.CoRR, abs/2412.15115. Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin
-
[22]
Learn- ing beyond teacher: Generalized on-policy distil- lation with reward extrapolation.arXiv preprint arXiv:2602.12125. Dongxu Zhang, Zhichao Yang, Sepehr Janghorbani, Jun Han, Andrew Ressler II, Qian Qian, Gregory D Lyng, Sanjit Singh Batra, and Robert E Tillman
-
[23]
Fast and effective on-policy distillation from reasoning prefixes.arXiv preprint arXiv:2602.15260. 10 A Why Cosine Similarity Detects Evidence Membership In causal transformers, the hidden state at posi- tion t after L layers, hL t , is not merely a repre- sentation of token yt but the model’s compressed working memory encoding all causally accessible con...
arXiv 2021
-
[24]
Relevance
confirm that deep- layer representations are dominated by semantic and functional information, with syntactic features attenuating. While these findings originate from encoder models, subsequent work on autoregres- sive LLMs has confirmed that deep layers similarly encode task-relevant semantics over surface form. This means cosine similarity at deep laye...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.