Recognition: unknown
TIP: Token Importance in On-Policy Distillation
Pith reviewed 2026-05-10 13:23 UTC · model grok-4.3
The pith
Informative tokens in on-policy distillation come from high student entropy positions and low-entropy positions with high teacher divergence where the student is overconfident and wrong.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that informative tokens in on-policy distillation arise in two regions: high student entropy and low student entropy paired with high teacher-student divergence, the latter marking cases of student overconfidence on incorrect outputs. Entropy-based selection of 50 percent of tokens matches or exceeds full-token training and cuts peak memory by up to 47 percent. Isolating the low-entropy high-divergence subset allows training on fewer than 10 percent of tokens to nearly match full baselines. The taxonomy supplies a theoretical reason entropy is useful yet incomplete and motivates type-aware sampling rules that combine uncertainty with disagreement.
What carries the argument
TIP, the two-axis taxonomy that classifies every token by student entropy on one axis and teacher-student divergence on the other to isolate regions carrying dense corrective signal.
If this is right
- Entropy sampling alone already matches full training at 50 percent token retention and reduces memory by up to 47 percent.
- Adding the low-entropy high-divergence region lets under 10 percent of tokens nearly recover full performance.
- On long-horizon planning tasks, training on fewer than 20 percent of tokens can surpass the full-token baseline.
- The same two-region pattern holds across Qwen and Llama teacher-student pairs on MATH-500 and AIME benchmarks.
Where Pith is reading between the lines
- The same divergence signal could flag overconfident errors for post-training correction outside the distillation setting.
- Type-aware sampling might transfer to offline distillation or reinforcement learning from AI feedback where token value also varies.
- Adaptive rules that re-estimate entropy and divergence on the fly during training could further improve efficiency as the student improves.
Load-bearing premise
That high teacher-student divergence at low-entropy positions reliably marks factual mistakes by the student rather than stylistic differences or valid alternative answers.
What would settle it
A controlled run on a benchmark with verifiably correct teacher labels in which training exclusively on the low-entropy high-divergence tokens produces no gain over random or entropy-only selection of the same budget.
Figures



read the original abstract
On-policy knowledge distillation (OPD) trains a student on its own rollouts under token-level supervision from a teacher. Not all token positions matter equally, but existing views of token importance are incomplete. We ask a direct question: which tokens carry the most useful learning signal in OPD? Our answer is that informative tokens come from two regions: positions with high student entropy, and positions with low student entropy plus high teacher--student divergence, where the student is overconfident and wrong. Empirically, student entropy is a strong first-order proxy: retaining $50\%$ of tokens with entropy-based sampling matches or exceeds all-token training while reducing peak memory by up to $47\%$. But entropy alone misses a second important region. When we isolate low-entropy, high-divergence tokens, training on fewer than $10\%$ of all tokens nearly matches full-token baselines, showing that overconfident tokens carry dense corrective signal despite being nearly invisible to entropy-only rules. We organize these findings with TIP (Token Importance in on-Policy distillation), a two-axis taxonomy over student entropy and teacher--student divergence, and give a theoretical explanation for why entropy is useful yet structurally incomplete. This view motivates type-aware token selection rules that combine uncertainty and disagreement. We validate this picture across three teacher--student pairs spanning Qwen3, Llama, and Qwen2.5 on MATH-500 and AIME 2024/2025, and on the DeepPlanning benchmark for long-horizon agentic planning, where Q3-only training on $<$$20\%$ of tokens surpasses full-token OPD. Our experiments are implemented by extending the OPD repository https://github.com/HJSang/OPSD_OnPolicyDistillation, which supports memory-efficient distillation of larger models under limited GPU budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TIP, a two-axis taxonomy for token importance in on-policy distillation (OPD) based on student entropy and teacher-student divergence. It claims that the most informative tokens lie in two regions—high student entropy positions, and low-entropy positions with high divergence (interpreted as cases where the student is overconfident and factually wrong)—and that training on fewer than 10% of tokens selected via this taxonomy nearly matches full-token OPD performance on MATH-500, AIME 2024/2025, and DeepPlanning benchmarks across Qwen3, Llama, and Qwen2.5 teacher-student pairs, while reducing peak memory by up to 47%. A theoretical sketch explains why entropy is a useful but incomplete proxy, motivating type-aware selection rules.
Significance. If the empirical results and taxonomy hold, the work offers a practical route to memory-efficient OPD and a clearer account of why certain tokens carry dense learning signal. The validation across three model families and both math and long-horizon planning tasks is a strength, as is the open-source extension of the OPSD repository. The significance would increase if the performance gains can be attributed specifically to corrective signal rather than generic disagreement sampling.
major comments (2)
- [Abstract and TIP taxonomy section] Abstract and the section introducing the TIP taxonomy: the claim that low-entropy, high-divergence tokens are positions 'where the student is overconfident and wrong' and therefore supply 'dense corrective signal' is not supported by direct evidence. Divergence (KL or cross-entropy) measures any distributional mismatch and does not distinguish factual error from stylistic alternatives or multiple valid tokens; no per-token ground-truth audit of the student's argmax token is reported to confirm factual incorrectness rather than mere non-match with the teacher.
- [Experiments] Experiments section (MATH-500/AIME and DeepPlanning results): while the <10% token selection nearly matches full OPD, the manuscript does not report variance across random seeds or statistical tests for the 'nearly matches' claim, nor does it ablate whether the gains persist when the low-entropy high-divergence tokens are replaced by random disagreement samples of equal size. This leaves open whether the two-axis taxonomy is necessary or whether any high-divergence sampling suffices.
minor comments (2)
- [Theoretical explanation] The theoretical explanation for why entropy is 'structurally incomplete' would benefit from a short formal derivation or counter-example showing a low-entropy high-divergence case that entropy alone cannot capture.
- [Figures] Figure captions and axis labels for the entropy-divergence scatter plots should explicitly state the token sampling fractions used in each panel to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the TIP taxonomy and experimental validation. We address each major point below and outline revisions to improve precision and rigor.
read point-by-point responses
-
Referee: [Abstract and TIP taxonomy section] Abstract and the section introducing the TIP taxonomy: the claim that low-entropy, high-divergence tokens are positions 'where the student is overconfident and wrong' and therefore supply 'dense corrective signal' is not supported by direct evidence. Divergence (KL or cross-entropy) measures any distributional mismatch and does not distinguish factual error from stylistic alternatives or multiple valid tokens; no per-token ground-truth audit of the student's argmax token is reported to confirm factual incorrectness rather than mere non-match with the teacher.
Authors: We agree that the phrasing 'overconfident and wrong' is an interpretive claim rather than one backed by per-token ground-truth verification. Divergence indeed captures any mismatch, and in domains with multiple valid continuations it would not isolate factual errors. Our interpretation is grounded in the task domains (mathematical reasoning and long-horizon planning), where the teacher is a stronger model and low-entropy student predictions that diverge are typically incorrect next steps or facts; the theoretical sketch further motivates why such positions yield corrective signal. To address the concern directly, we will revise the abstract and taxonomy section to qualify the language (e.g., 'positions where the student is overconfident yet diverges from the teacher, supplying dense corrective signal in our benchmarks') and add an explicit limitations paragraph on the assumptions underlying the interpretation. This is a partial revision focused on textual clarification. revision: partial
-
Referee: Experiments section (MATH-500/AIME and DeepPlanning results): while the <10% token selection nearly matches full OPD, the manuscript does not report variance across random seeds or statistical tests for the 'nearly matches' claim, nor does it ablate whether the gains persist when the low-entropy high-divergence tokens are replaced by random disagreement samples of equal size. This leaves open whether the two-axis taxonomy is necessary or whether any high-divergence sampling suffices.
Authors: The absence of reported variance and formal statistical tests is a valid gap in experimental rigor. While our runs used fixed seeds and produced consistent outcomes across the three model families, we will add standard deviations from repeated runs and include a brief statistical note in the revised experiments section. Regarding the ablation, we did not compare our type-aware selection against random high-divergence samples of equal size. The two-axis taxonomy is motivated by the empirical finding that entropy-only selection misses the low-entropy high-divergence region (as shown in our entropy-ablation results), and the theory explains why entropy is incomplete. To directly test necessity versus generic disagreement sampling, we will incorporate this ablation in the revision, reporting performance for random disagreement tokens versus TIP-selected tokens. This constitutes a partial revision. revision: partial
Circularity Check
No significant circularity; empirical taxonomy with independent theoretical sketch
full rationale
The paper presents TIP as a two-axis taxonomy derived from empirical token-selection experiments on entropy and teacher-student divergence, with performance gains shown on MATH-500, AIME, and DeepPlanning benchmarks. No central quantity (e.g., importance score or region boundary) is defined in terms of parameters fitted to the target accuracy metric, nor does any prediction reduce by construction to the input data. The theoretical explanation for entropy's incompleteness is offered as a post-hoc sketch rather than a self-referential derivation. Self-citation is limited to the authors' prior OPD code repository and does not bear load for any uniqueness theorem or ansatz. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A stronger teacher model supplies useful token-level supervision to the student.
invented entities (1)
-
TIP taxonomy
no independent evidence
Forward citations
Cited by 7 Pith papers
-
TRACE: Distilling Where It Matters via Token-Routed Self On-Policy Alignment
TRACE improves math reasoning by distilling only on annotator-marked critical spans with forward KL on correct key spans, optional reverse KL on errors, and GRPO elsewhere, gaining 2.76 points over GRPO while preservi...
-
The Extrapolation Cliff in On-Policy Distillation of Near-Deterministic Structured Outputs
On-policy distillation has an extrapolation cliff at closed-form lambda*(p,b,c) set by teacher modal probability, warm-start mass, and clip strength, past which training shifts from format-preserving to format-collapsing.
-
Rubric-based On-policy Distillation
Rubric-based on-policy distillation allows training student models using only teacher responses by generating scoring rubrics from contrasts and using them for on-policy optimization, achieving superior performance an...
-
Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
On-policy distillation gains efficiency from early foresight in module focus and update directions, enabling EffOPD to accelerate training 3x with comparable performance.
-
Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
On-policy distillation gains efficiency from early foresight in module allocation and low-rank update directions, enabling EffOPD to accelerate training by 3x via adaptive extrapolation without extra modules or tuning.
-
SOD: Step-wise On-policy Distillation for Small Language Model Agents
SOD reweights on-policy distillation strength step-by-step using divergence to stabilize tool use in small language model agents, yielding up to 20.86% gains and 26.13% on AIME 2025 for a 0.6B model.
-
SimCT: Recovering Lost Supervision for Cross-Tokenizer On-Policy Distillation
SimCT recovers discarded teacher signal in cross-tokenizer on-policy distillation by enlarging supervision to jointly realizable multi-token continuations, yielding consistent gains on math reasoning and code generati...
Reference graph
Works this paper leans on
-
[1]
Gkd: Generalized knowledge distillation for auto- regressive sequence models,
URL https: //arxiv.org/abs/2306.13649. Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning.ICML,
-
[2]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617,
work page internal anchor Pith review arXiv
-
[3]
URLhttps://arxiv.org/abs/2407.21783. Yuxian Gu, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. MiniPLM: Knowledge distillation for pre-training language models.arXiv preprint arXiv:2410.17215,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2510.24021 , year =
Haiduo Huang, Jiangcheng Song, Yadong Zhang, and Pengju Ren. SelecTKD: Selective token- weighted knowledge distillation for LLMs.arXiv preprint arXiv:2510.24021,
-
[6]
URLhttps://arxiv.org/abs/2305.12870. Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models.arXiv preprint arXiv:2603.07079,
-
[7]
10 Minsang Kim and Seung Jun Baek. Explain in your own words: Improving reasoning via token- selective dual knowledge distillation.arXiv preprint arXiv:2603.13260,
-
[8]
Sequence-level knowledge distillation
URL https: //arxiv.org/abs/1606.07947. M Pawan Kumar, Benjamin Packer, and Daphne Koller. Self-paced learning for latent variable models.NeurIPS,
-
[9]
URL https://arxiv.org/abs/2412.15115. Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. InInternational Conference on Machine Learning (ICML),
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. CRISP: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Rethinking selective knowledge distillation.arXiv preprint arXiv:2602.01395,
Almog Tavor, Itay Ebenspanger, Neil Cnaan, and Mor Geva. Rethinking selective knowledge distillation.arXiv preprint arXiv:2602.01395,
-
[12]
Jiapeng Wang, Yiwen Hu, Yanzipeng Gao, Haoyu Wang, Shuo Wang, Hongyu Lu, Jiaxin Mao, Wayne Xin Zhao, Junyi Li, and Ji-Rong Wen. Entropy-guided token dropout: Training autoregres- sive language models with limited domain data.arXiv preprint arXiv:2512.23422, 2025a. Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong-hui Chen,...
- [13]
-
[14]
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. Overconfident errors need stronger correction: Asymmetric confidence penalties for reinforcement learning.arXiv preprint arXiv:2602.21420, 2026a. Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. PACED: Distillation and self-distillation at the frontier of student competence.arX...
-
[15]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
-
[18]
EDIS: Diagnosing LLM reasoning via entropy dynamics.arXiv preprint arXiv:2602.01288,
Chenghua Zhu, Siyan Wu, Xiangkang Zeng, Zishan Xu, Zhaolu Kang, Yifu Guo, Yuquan Lu, Junduan Huang, Guojing Zhou, et al. EDIS: Diagnosing LLM reasoning via entropy dynamics.arXiv preprint arXiv:2602.01288,
-
[19]
large-divergence
Assumption 2(Token-separable approximation).For tractability, we neglect off-diagonal gradient interactions across token positions. Concretely, fort̸=s we treat the centered cross-token covariance E[(gt −¯µt)(gs −¯µs)⊤] as lower-order, so that the quadratic term admits a token-separable approximation. Derivation.ExpandL(θ−ηˆg)via smoothness whereˆg= P t w...
2026
-
[20]
off” (54.4%), restating the problem, while the teacher prefers “written
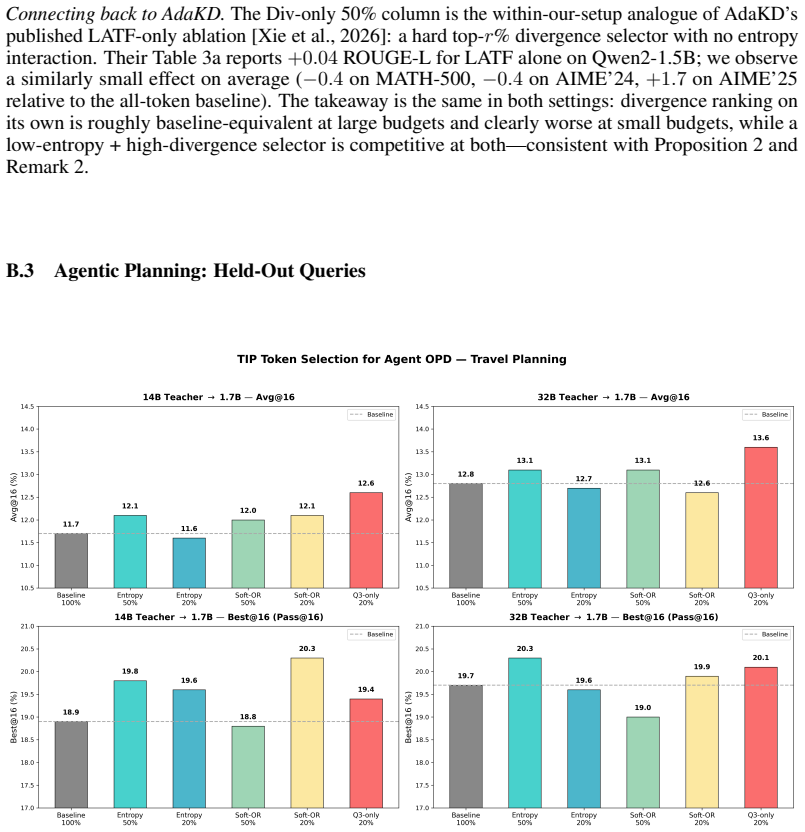
Best@16 results show the same pattern: overconfident-token training improves the upper tail of performance, not just the mean. Figure 4 complements Table 7 with a finer-grained view. The Avg@16 panels confirm the main- text findings: Q3-only 20% leads for both teacher sizes (12.6 and 13.6 vs. baselines of 11.7 and 12.8), and entropy-only 50% improves over...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.