Evaluating self-supervised echocardiographic representations across downstream extraction strategies for left-ventricular segmentation and ejection fraction estimation
Pith reviewed 2026-06-26 08:51 UTC · model grok-4.3
The pith
Self-supervised echo representations require multiple downstream extraction strategies to evaluate their quality fairly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
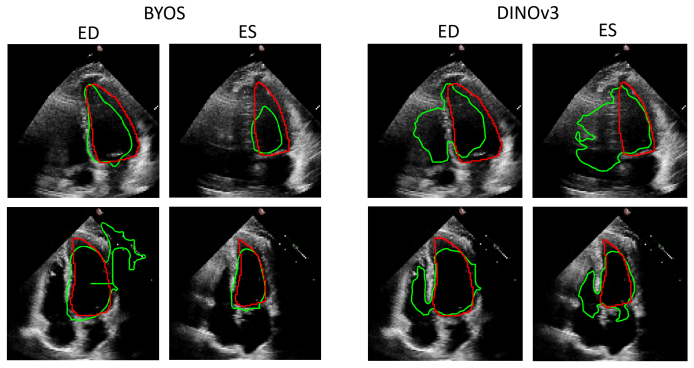
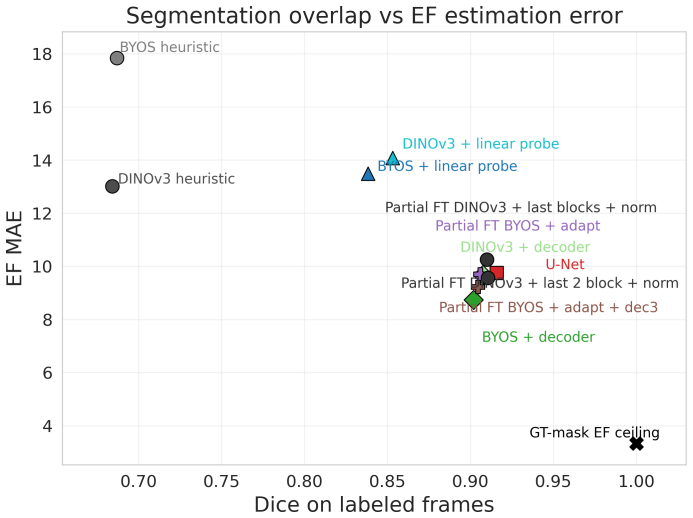
When the same self-supervised representations are probed with increasing expressivity, performance on left-ventricular segmentation and ejection fraction changes dramatically: heuristic extraction produces Dice 0.684–0.687 and EF MAE 13–18, whereas a frozen lightweight decoder reaches Dice 0.902–0.906 and EF MAE 8.74–9.65, nearly matching supervised baselines. The ordering and apparent usefulness of representation families therefore depend on the extraction strategy chosen.
What carries the argument
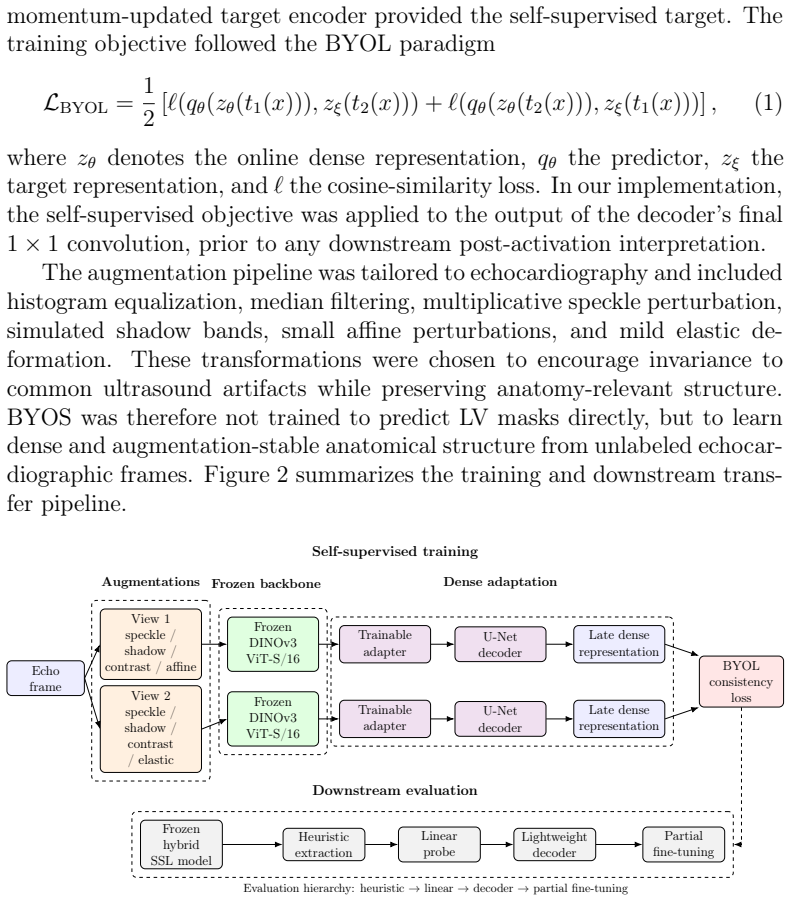
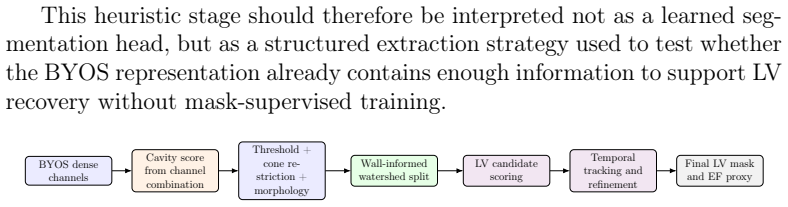
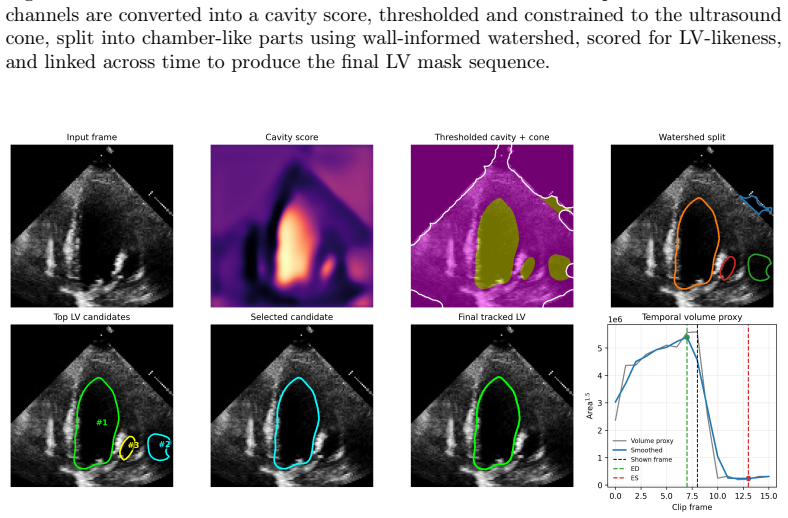
A hierarchy of downstream extraction strategies (heuristic extraction, frozen linear probes, frozen lightweight decoder probes, partial fine-tuning) applied to DINOv3 and BYOS representations for dense echocardiographic tasks.
If this is right
- Single-probe evaluations can substantially understate the task-relevant information present in frozen SSL representations for dense prediction.
- Fair comparison of SSL methods for echocardiography requires testing across multiple extraction strategies rather than one fixed probe.
- Both generic and task-adapted SSL families show large gains once a lightweight decoder is allowed, indicating that probe choice affects apparent utility more than representation family alone.
- Conclusions drawn from heuristic-only or linear-only evaluations are likely to be incomplete for clinical dense tasks.
Where Pith is reading between the lines
- Benchmarks that rely solely on linear probes may prematurely discard SSL representations that become competitive once a modest decoder is introduced.
- The same probe-dependence pattern is likely to appear in other dense medical imaging domains such as cardiac MRI or CT segmentation.
- Development effort might usefully shift toward lightweight task-specific heads that better unlock existing representations rather than focusing exclusively on pretraining improvements.
Load-bearing premise
The hierarchy of extraction strategies measures recoverable information from the representations rather than performance differences being driven mainly by the probes themselves.
What would settle it
A new extraction hierarchy that reverses the relative ranking of DINOv3 versus BYOS or makes heuristic extraction competitive with the lightweight decoder on the same EchoNet-Dynamic splits would falsify the claim.
Figures


read the original abstract
Self-supervised learning (SSL) is increasingly used in medical imaging to reduce annotation requirements, but representation quality is often judged using a single downstream evaluation setting. For dense clinical tasks, this can confound representation quality with the capacity of the downstream model used to recover task-relevant information. We present a systematic evaluation of self-supervised representations for left-ventricular segmentation and ejection fraction (EF) estimation from apical four-chamber echocardiography on EchoNet-Dynamic. Rather than relying on a single downstream probe, we compare a hierarchy of extraction strategies with increasing expressivity: heuristic extraction without mask-supervised training, frozen linear probes, frozen lightweight decoder probes, and partial fine-tuning. We apply this framework to two complementary representation families: generic frozen self-DIstillation with NO labels (DINOv3) features and a task-adapted dense self-supervised representation, Bootstrap Your Own Segmentation (BYOS). In both families, heuristic extraction substantially understated what was recoverable from the frozen representation. For DINOv3, performance improved from Dice 0.684 and EF mean absolute error (MAE) 13.01 under heuristic extraction to Dice 0.906 and EF MAE 9.65 with a frozen lightweight decoder, approaching a supervised U-Net baseline (Dice 0.915, EF MAE 9.72). For BYOS, performance improved from Dice 0.687 and EF MAE 17.83 under heuristic extraction to Dice 0.902 and EF MAE 8.74 with a frozen lightweight decoder. These results show that conclusions about self-supervised representation quality in dense echocardiographic analysis depend strongly on the downstream extraction strategy used for evaluation. We therefore argue that multi-strategy evaluation is an important methodological consideration for SSL in dense medical image analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates self-supervised representations from DINOv3 and BYOS for left-ventricular segmentation and ejection fraction estimation on EchoNet-Dynamic. It compares a hierarchy of extraction strategies (heuristic, frozen linear probe, frozen lightweight decoder, partial fine-tuning) and reports that heuristic extraction yields low performance (Dice ~0.68, higher EF MAE) while frozen lightweight decoders reach Dice ~0.90 and EF MAE reductions approaching a supervised U-Net baseline, concluding that single-strategy evaluation can mislead about SSL representation quality and that multi-strategy evaluation is needed for dense medical image tasks.
Significance. If the central empirical pattern holds after addressing controls, the work has moderate methodological significance for SSL evaluation in medical imaging by showing how downstream probe choice affects apparent representation quality. The comparison across two representation families on a public dataset is a strength; the manuscript does not ship machine-checked proofs, reproducible code, or parameter-free derivations.
major comments (2)
- [Abstract] Abstract: the central claim that the hierarchy isolates recoverable information from the representations (rather than probe capacity dominating) is not supported by any controls such as random or untrained backbones; without these, the large gains from heuristic (Dice 0.684) to frozen lightweight decoder (Dice 0.906) for DINOv3 could reflect decoder architecture rather than intrinsic representation properties, which is load-bearing for the argument that 'conclusions about self-supervised representation quality depend strongly on the downstream extraction strategy'.
- [Abstract] Abstract and methods description of probes: no architecture details, hyperparameters, or training protocol are given for the 'frozen lightweight decoder' or the 'heuristic extraction' baseline, preventing assessment of whether the reported improvements (e.g., EF MAE 13.01 to 9.65 for DINOv3) are robust or reproducible.
minor comments (2)
- The abstract reports point estimates without variance, confidence intervals, or statistical tests across the multiple strategies and representation families.
- A summary table aggregating Dice and EF MAE for all four extraction strategies and both SSL families would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the manuscript accordingly to strengthen the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the hierarchy isolates recoverable information from the representations (rather than probe capacity dominating) is not supported by any controls such as random or untrained backbones; without these, the large gains from heuristic (Dice 0.684) to frozen lightweight decoder (Dice 0.906) for DINOv3 could reflect decoder architecture rather than intrinsic representation properties, which is load-bearing for the argument that 'conclusions about self-supervised representation quality depend strongly on the downstream extraction strategy'.
Authors: We agree that controls with random or untrained backbones are needed to more rigorously isolate representation quality from probe capacity. The current experiments compare extraction strategies on the same pre-trained representations but do not include such baselines. We will add experiments with randomly initialized backbones paired with the lightweight decoder in the revised manuscript to confirm that the observed gains are attributable to the self-supervised representations. revision: yes
-
Referee: [Abstract] Abstract and methods description of probes: no architecture details, hyperparameters, or training protocol are given for the 'frozen lightweight decoder' or the 'heuristic extraction' baseline, preventing assessment of whether the reported improvements (e.g., EF MAE 13.01 to 9.65 for DINOv3) are robust or reproducible.
Authors: We agree that the manuscript lacks the necessary details on probe architectures, hyperparameters, and training protocols. In the revised version, we will expand the Methods section to provide complete specifications for the frozen lightweight decoder (including layer structure and dimensions), the heuristic extraction baseline, all hyperparameters, optimization settings, and training protocols for both tasks to support reproducibility and evaluation of the reported improvements. revision: yes
Circularity Check
Empirical comparison with no derivations or self-referential reductions
full rationale
The paper reports experimental results from applying a hierarchy of extraction strategies to two SSL representation families on the fixed EchoNet-Dynamic dataset. No equations, fitted parameters, or predictions are presented; performance numbers (Dice, MAE) are direct measurements. The central claim that single-strategy evaluation can mislead is justified by those measurements rather than by any reduction to inputs by construction, self-citation chains, or imported uniqueness theorems. This is a standard empirical methodology paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption EchoNet-Dynamic is a representative benchmark for apical four-chamber left-ventricular segmentation and ejection fraction estimation
Reference graph
Works this paper leans on
-
[1]
R. M. Lang, L. P. Badano, V. Mor-Avi, J. Afilalo, A. Armstrong, L. Er- nande, F. A. Flachskampf, E. Foster, S. A. Goldstein, T. Kuznetsova, et al., Recommendations for cardiac chamber quantification by echocar- diography in adults: an update from the american society of echocar- diography and the european association of cardiovascular imaging, Eu- ropean ...
2015
-
[2]
J. Noble, D. Boukerroui, Ultrasound image segmentation: a sur- vey, IEEE Transactions on Medical Imaging 25 (2006) 987–1010. doi:10.1109/TMI.2006.877092
-
[3]
Ouyang, B
D. Ouyang, B. He, A. Ghorbani, N. Yuan, J. Ebinger, P. A. H. Curt P. Langlotz, R. A. Harrington, D. H. Liang, E. A. Ashley, J. Y. Zou, Video-based ai for beat-to-beat assessment of cardiac function, Nature 580 (2020)
2020
-
[4]
In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV)
S. Azizi, B. Mustafa, F. Ryan, Z. Beaver, J. Freyberg, J. Deaton, A. Loh, A. Karthikesalingam, S. Kornblith, T. Chen, V. Natarajan, M. Norouzi, Bigself-supervisedmodelsadvancemedicalimageclassification, in: 2021 32 IEEE/CVFInternationalConferenceonComputerVision(ICCV),2021, pp. 3458–3468. doi:10.1109/ICCV48922.2021.00346
-
[5]
Z. Zhou, V. Sodha, J. Pang, M. B. Gotway, J. Liang, Models genesis, Medical Image Analysis 67 (2021) 101840. doi:https://doi.org/10.1016/j.media.2020.101840
-
[6]
T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations, in: H. D. III, A. Singh (Eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, PMLR, 2020, pp. 1597–1607
2020
-
[7]
Grill, F
J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond, E. Buchatskaya, C.Doersch, B.A. Pires, Z.D. Guo, M. G.Azar, B.Piot, K. Kavukcuoglu, R. Munos, M. Valko, Bootstrap your own latent a new approach to self-supervised learning, in: Proceedings of the 34th Inter- national Conference on Neural Information Processing Systems, NIPS ’20, Curran Associa...
2020
-
[8]
Caron, H
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, A. Joulin, Emerging properties in self-supervised vision transformers, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 9630–9640
2021
-
[9]
O. Siméoni, H. V. Vo, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V. Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sen- tana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. Jégou, P. Labatut, P. Bojanowski, DINOv3, 2025. URL: https://arxiv.org/abs/2508.1...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
D. L. Ferreira, C. Lau, Z. Salaymang, R. Arnaout, Self-supervised learn- ing for label-free segmentation in cardiac ultrasound, Nature Commu- nications 16 (2025) 4070. doi:10.1038/s41467-025-59451-5
-
[11]
U-Net: Convolutional Networks for Biomedical Image Segmentation
O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation., CoRR abs/1505.04597 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
S. Majchrowska, A. Hildeman, R. Mokhtari, T. Diethe, P. Teare, Exploring interpretable echo analysis using self-supervised parcels, 33 Computers in Biology and Medicine 192 (2025) 110322. URL: https://www.sciencedirect.com/science/article/pii/S0010482525006730. doi:https://doi.org/10.1016/j.compbiomed.2025.110322
-
[13]
N. Park, W. Kim, B. Heo, T. Kim, S. Yun, What do self-supervised vision transformers learn?, International Conference on Learning Rep- resentations (2023)
2023
-
[14]
Seince, L
M. Seince, L. L. Folgoc, L. F. D. Souza, E. Angelini, Dense self- supervised learning for medical image segmentation, in: N. Bur- gos, C. Petitjean, M. Vakalopoulou, S. Christodoulidis, P. Coupe, H. Delingette, C. Lartizien, D. Mateus (Eds.), Proceedings of The 7nd International Conference on Medical Imaging with Deep Learning, vol- ume 250 ofProceedings ...
2024
-
[15]
From entropy to epiplexity: Rethinking infor- mation for computationally bounded intelligence,
M. Finzi, S. Qiu, Y. Jiang, P. Izmailov, J. Kolter, A. Wilson, From entropy to epiplexity: Rethinking information for computationally bounded intelligence, CoRR (2026). doi:10.48550/arXiv.2601.03220. 34 Appendix A. Reproducibility details Data and preprocessing.All experiments used the EchoNet-Dynamic dataset with official split assignments taken directly...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.