ENVS: Environment-Native Verified Search for Long-Horizon GUI Agents
Pith reviewed 2026-06-26 08:28 UTC · model grok-4.3
The pith
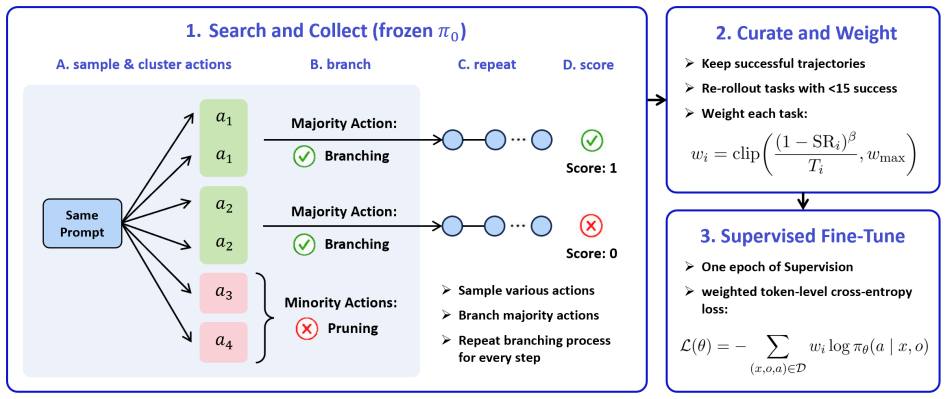
ENVS constructs verified supervision for GUI agents by branching over actions in live VMs and retaining only successful trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
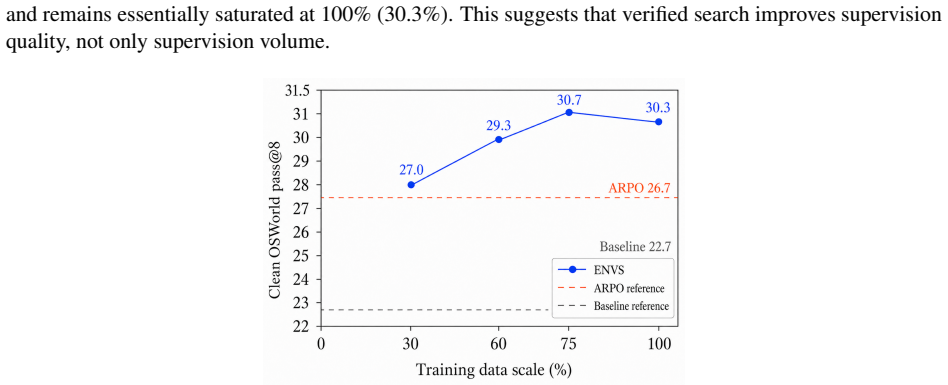
ENVS is a training-time search-and-filter pipeline that uses the environment to construct verified supervision before policy optimization: it branches over behaviorally distinct GUI actions in live OSWorld VMs, verifies successful leaves, and trains from globally balanced step-level supervision. On the 300-task OSWorld pool, ENVS reaches 30.3 pass@8 on original evaluations and 29.0 on OSWorld-Noisy, outperforming matched ARPO-style online RL while reducing compute from 184-192 to 138-153 GPU-hours; even with only 30% of its search data, ENVS reaches 27.0 pass@8, exceeding ARPO from the base model. Training from noisy environments also better preserves visual-reasoning abilities on auxiliary
What carries the argument
Environment-Native Verified Search (ENVS), a pipeline that branches over behaviorally distinct GUI actions in live OSWorld VMs, verifies successful leaves, and generates globally balanced step-level supervision for subsequent policy optimization.
If this is right
- Higher pass@8 rates on the 300-task OSWorld pool than matched online RL baselines.
- Reduced training compute from 184-192 to 138-153 GPU-hours while improving results.
- Stronger robustness on OSWorld-Noisy, a benchmark for recoverable desktop interruptions.
- Competitive performance retained even when using only 30% of the search data.
- Better preservation of visual-reasoning scores on auxiliary benchmarks such as OSWorld-G Refusal and BLINK Functional Correspondence.
Where Pith is reading between the lines
- The verification filter might reduce the need for human-curated demonstrations by automatically selecting successful paths in any environment that supports rollouts.
- Applying the same branching-and-verify step to web or mobile agents could test whether environment-native filtering generalizes beyond desktop VMs.
- Iterative application of ENVS across multiple rounds of search might enable scaling to tasks with horizons longer than those tested in the current 300-task pool.
Load-bearing premise
Branching over distinct GUI actions in live VMs and retaining only verified successful leaves produces globally balanced step-level supervision that improves policy optimization without introducing search-induced bias or distribution shift.
What would settle it
A comparison in which the verified ENVS data produces no performance gain over ARPO-style RL when the total number of training trajectories and their diversity are matched exactly.
Figures

read the original abstract
As multimodal agents move from interface understanding to real software control, successful trajectory discovery in live desktop environments becomes a key challenge. GUI tasks require long-horizon sequences of precise mouse and keyboard actions, while feedback is sparse, delayed, and costly to obtain through VM rollouts. We propose Environment-Native Verified Search (ENVS), a training-time search-and-filter pipeline that uses the environment to construct verified supervision before policy optimization: it branches over behaviorally distinct GUI actions in live OSWorld VMs, verifies successful leaves, and trains from globally balanced step-level supervision. To evaluate robustness under realistic desktop interruptions, we also introduce OSWorld-Noisy, a dynamic benchmark for recoverable desktop interruptions that preserves the original tasks while testing whether agents can refocus, dismiss, wait, or recover under live perturbations. On the 300-task OSWorld pool, ENVS reaches 30.3 pass@8 on original evaluations and 29.0 on OSWorld-Noisy, outperforming matched ARPO-style online RL while reducing compute from 184-192 to 138-153 GPU-hours; even with only 30% of its search data, ENVS reaches 27.0 pass@8, exceeding ARPO from the base model. Training from noisy environments also better preserves visual-reasoning abilities on auxiliary benchmarks, including OSWorld-G Refusal (16.7 vs. 1.9) and BLINK Functional Correspondence (26.2 vs. 23.1).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Environment-Native Verified Search (ENVS), a training-time pipeline that branches over behaviorally distinct GUI actions in live OSWorld VMs, verifies successful leaves via environment rollouts, and trains policies from the resulting globally balanced step-level supervision. It introduces the OSWorld-Noisy benchmark for testing recovery from dynamic desktop interruptions and reports that ENVS achieves 30.3 pass@8 (29.0 on Noisy) on the 300-task OSWorld pool, outperforming matched ARPO-style online RL while using less compute (138-153 vs. 184-192 GPU-hours); even with 30% of the search data it exceeds the ARPO baseline, and training on noisy environments better preserves visual reasoning on auxiliary tasks.
Significance. If the performance and efficiency gains hold after isolating the contribution of the search-and-filter mechanism, ENVS would offer a practical route to scalable verified supervision for long-horizon GUI agents, addressing sparse feedback and high rollout costs. The OSWorld-Noisy benchmark is a useful addition for evaluating robustness to realistic interruptions.
major comments (1)
- [Abstract] Abstract: the central claim that branching + verified-success filtering produces 'globally balanced step-level supervision' that drives the reported gains (30.3 pass@8, compute reduction, robustness on OSWorld-Noisy) is load-bearing, yet the manuscript provides no control that holds data distribution (action statistics, horizon length, task difficulty) fixed while varying only the search procedure; without such isolation it remains possible that retained successful leaves systematically differ from ARPO-sampled trajectories, so the improvement could be driven by curation rather than the ENVS mechanism itself.
minor comments (1)
- [Abstract] Abstract: the efficiency numbers (GPU-hours) and data-subset result (30% of search data) are presented without accompanying details on variance, number of runs, or exact matching criteria between ENVS and ARPO training budgets.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The concern about isolating the contribution of the search-and-filter mechanism is well-taken, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that branching + verified-success filtering produces 'globally balanced step-level supervision' that drives the reported gains (30.3 pass@8, compute reduction, robustness on OSWorld-Noisy) is load-bearing, yet the manuscript provides no control that holds data distribution (action statistics, horizon length, task difficulty) fixed while varying only the search procedure; without such isolation it remains possible that retained successful leaves systematically differ from ARPO-sampled trajectories, so the improvement could be driven by curation rather than the ENVS mechanism itself.
Authors: We agree that an explicit control isolating the search procedure while holding data distribution fixed would strengthen the central claim. The current ARPO baseline matches environment, task pool, and compute budget but does not enforce identical action statistics or horizon lengths. In the revised version we will add a targeted ablation: (1) a 'curation-only' baseline that samples trajectories via the same ARPO policy and then applies post-hoc success filtering to match the leaf distribution of ENVS, and (2) an 'ENVS-without-verification' variant that retains the branching tree but trains on all leaves rather than verified-success leaves. These controls will quantify how much of the reported gains (pass@8, compute reduction, and OSWorld-Noisy robustness) are attributable to the verified-search mechanism versus distribution shift. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential reductions
full rationale
The paper contains no equations, derivations, or mathematical claims. Its central results are direct empirical measurements (pass@8 scores, GPU-hours, auxiliary benchmark performance) on external benchmarks (OSWorld, OSWorld-Noisy) against a matched external baseline (ARPO-style online RL). No load-bearing step reduces to a fitted parameter, self-citation chain, or definitional equivalence. The method description (branching + verified-success filtering) is presented as an engineering procedure whose value is assessed by held-out task success, not by internal consistency with its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Live OSWorld VMs provide accurate and timely verification of whether a trajectory completes the intended GUI task
invented entities (1)
-
OSWorld-Noisy benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Thinking fast and slow with deep learning and tree search
Thomas Anthony, Zheng Tian, and David Barber. Thinking fast and slow with deep learning and tree search. arXiv preprint arXiv:1705.08439, 2017
arXiv 2017
-
[2]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InInternational Conference on Machine Learning, pages 41–48, 2009
2009
-
[3]
SeeClick: Harnessing GUI grounding for advanced visual GUI agents, 2024
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. SeeClick: Harnessing GUI grounding for advanced visual GUI agents, 2024
2024
-
[4]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Christopher Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. InInternational Conference on Machine Learning, 2020
2020
-
[5]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[6]
Efficient selectivity and backup operators in monte-carlo tree search
Rémi Coulom. Efficient selectivity and backup operators in monte-carlo tree search. InInternational Conference on Computers and Games, pages 72–83. Springer, 2006
2006
-
[7]
The entropy mechanism of reinforcement learning for reasoning language models, 2025
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models, 2025
2025
-
[8]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
2025
-
[9]
Mind2Web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems, 2023
2023
-
[10]
Emergent complexity and zero-shot transfer via unsupervised environment design
Michael Dennis, Natasha Jaques, Eugene Vinitsky, Alexandre Bayen, Stuart Russell, Andrew Critch, and Sergey Levine. Emergent complexity and zero-shot transfer via unsupervised environment design. InAdvances in Neural Information Processing Systems, 2020
2020
-
[11]
Agentic reinforced policy optimization, 2025
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. Agentic reinforced policy optimization, 2025
2025
-
[12]
Reinforced self-training (ReST) for language modeling, 2023
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (ReST) for language modeling, 2023
2023
-
[13]
CogAgent: A visual language model for GUI agents, 2023
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxuan Zhang, Juanzi Li, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. CogAgent: A visual language model for GUI agents, 2023
2023
-
[14]
Prioritized level replay
Minqi Jiang, Edward Grefenstette, and Tim Rocktäschel. Prioritized level replay. InInternational Conference on Machine Learning, 2021
2021
-
[15]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. InEuropean Conference on Machine Learning, pages 282–293. Springer, 2006
2006
-
[16]
VisualWebArena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. InAnnual Meeting of the Association for Computational Linguistics, 2024
2024
-
[17]
Tree search for language model agents
Jing Yu Koh, Stephen McAleer, Daniel Fried, and Ruslan Salakhutdinov. Tree search for language model agents. InInternational Conference on Learning Representations, 2025. Also available as arXiv:2407.01476. 10
arXiv 2025
-
[18]
Let’s verify step by step, 2023
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023
2023
-
[19]
ProRL: Prolonged reinforcement learning expands reasoning boundaries in large language models, 2025
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. ProRL: Prolonged reinforcement learning expands reasoning boundaries in large language models, 2025
2025
-
[20]
ARPO: End-to-end policy optimization for GUI agents with experience replay, 2025
Fanbin Lu, Zhisheng Zhong, Shu Liu, Chi-Wing Fu, and Jiaya Jia. ARPO: End-to-end policy optimization for GUI agents with experience replay, 2025
2025
-
[21]
ScreenAgent: A vision language model-driven computer control agent, 2024
Runliang Niu, Jindong Li, Shiqi Wang, Yali Fu, Xiyu Hu, Xueyuan Leng, He Kong, Yi Chang, and Qi Wang. ScreenAgent: A vision language model-driven computer control agent, 2024
2024
-
[22]
Evolving curricula with regret-based environment design
Jack Parker-Holder, Minqi Jiang, Michael Dennis, Mikayel Samvelyan, Jakob Foerster, Edward Grefenstette, and Tim Rocktäschel. Evolving curricula with regret-based environment design. InInternational Conference on Machine Learning, 2022
2022
-
[23]
Robust adversarial reinforcement learning
Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta. Robust adversarial reinforcement learning. InInternational Conference on Machine Learning, 2017
2017
-
[24]
Pomerleau
Dean A. Pomerleau. ALVINN: An autonomous land vehicle in a neural network. InAdvances in Neural Information Processing Systems, 1989
1989
-
[25]
Agent Q: Advanced reasoning and learning for autonomous AI agents, 2024
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent Q: Advanced reasoning and learning for autonomous AI agents, 2024
2024
-
[26]
ToolRL: Reward is all tool learning needs, 2025
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs, 2025
2025
-
[27]
UI-TARS: Pioneering automated GUI interaction with native agents, 2025
Yujia Qin et al. UI-TARS: Pioneering automated GUI interaction with native agents, 2025
2025
-
[28]
AndroidWorld: A dynamic benchmarking environment for autonomous agents, 2024
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyamagundlu, Timothy Lillicrap, and Oriana Riva. AndroidWorld: A dynamic benchmarking environment for autonomous agents, 2024
2024
-
[29]
Gordon, and J
Stéphane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics, pages 627–635, 2011
2011
-
[30]
Mastering atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
2020
-
[31]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[32]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models, 2024
2024
-
[33]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the g...
2016
-
[34]
Mastering the game of Go without human knowledge.Nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and Demis Hassabis. Mastering the game of Go without human knowledge.Nature, 550(7676):354–359, 2017. 11
2017
-
[35]
Reda Bahi Slaoui, William R. Clements, Jakob N. Foerster, and Sebastien Toth. Robust visual domain randomiza- tion for reinforcement learning.arXiv preprint arXiv:1910.10537, 2020
arXiv 1910
-
[36]
Seea-r1: Tree-structured reinforcement fine-tuning for self-evolving embodied agents, 2025
Wanxin Tian, Shijie Zhang, Kevin Zhang, Xiaowei Chi, Chunkai Fan, Junyu Lu, Yulin Luo, Qiang Zhou, Yiming Zhao, Ning Liu, Siyu Lin, Zhiyuan Qin, Xiaozhu Ju, Shanghang Zhang, and Jian Tang. Seea-r1: Tree-structured reinforcement fine-tuning for self-evolving embodied agents, 2025. URL https://arxiv.org/abs/2506. 21669
2025
-
[37]
Domain random- ization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain random- ization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 23–30, 2017
2017
-
[38]
RAGEN: Understanding self-evolution in LLM agents via multi-turn reinforcement learning, 2025
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. RAGEN: Understanding self-evolution in LLM agents via multi-turn reinforcement learning, 2025
2025
-
[39]
OS-ATLAS: A foundation action model for generalist GUI agents, 2024
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, and Yu Qiao. OS-ATLAS: A foundation action model for generalist GUI agents, 2024
2024
-
[40]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information P...
2024
-
[41]
Aguvis: Unified pure vision agents for autonomous GUI interaction, 2024
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous GUI interaction, 2024
2024
-
[42]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems, 2023
2023
-
[43]
DAPO: An open-source LLM reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
2025
-
[44]
Robust deep reinforcement learning against adversarial perturbations on state observations
Huan Zhang, Hongge Chen, Chaowei Xiao, Bo Li, Mingyan Liu, Duane Boning, and Cho-Jui Hsieh. Robust deep reinforcement learning against adversarial perturbations on state observations. InAdvances in Neural Information Processing Systems, 2020
2020
-
[45]
Clpo: Curriculum learning meets policy optimization for llm reasoning, 2025
Shijie Zhang, Guohao Sun, Kevin Zhang, Xiang Guo, and Rujun Guo. Clpo: Curriculum learning meets policy optimization for llm reasoning, 2025. URLhttps://arxiv.org/abs/2509.25004
Pith/arXiv arXiv 2025
-
[46]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, Tao Yu, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, Tao Yu, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations, 2024. 12 A Preliminaries A.1 GUI agents as partially observed con...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.