Exposing the Illusion of Erasure in Knowledge Editing for LLMs
Pith reviewed 2026-06-26 09:08 UTC · model grok-4.3
The pith
Knowledge editing in LLMs suppresses original facts rather than erasing them from the model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Popular knowledge editing methods using low-rank updates do not overwrite existing knowledge but instead redistribute it within the model's representation space. These methods act as targeted suppression mechanisms that reduce the likelihood of expressing original facts rather than removing them. The edited knowledge lies in narrow, anisotropic regions of the loss landscape that are highly sensitive to perturbations, which explains why indirect and adversarial prompts consistently surface the original information.
What carries the argument
Low-rank updates that redistribute knowledge into narrow anisotropic loss regions instead of overwriting it.
If this is right
- Edited models remain vulnerable to recovery of the original facts through indirect prompting.
- Post-hoc knowledge updates cannot guarantee permanent removal of information in deployed systems.
- The suppression effect appears consistently across different LLM architectures.
- Applications that rely on knowledge editing for fact correction or alignment require reevaluation of their reliability.
Where Pith is reading between the lines
- True removal of facts may require changes during initial training rather than post-hoc edits.
- The same suppression pattern could affect other post-training modifications such as safety alignments.
- Developers might test edits by attempting recovery across a wider range of prompt styles before deployment.
Load-bearing premise
The chosen adversarial elicitation prompts and loss-landscape analysis are enough to detect whether knowledge has been erased or only suppressed.
What would settle it
A knowledge editing procedure after which no prompt variation, including newly designed adversarial ones, can recover the original fact would show that true erasure is possible.
Figures

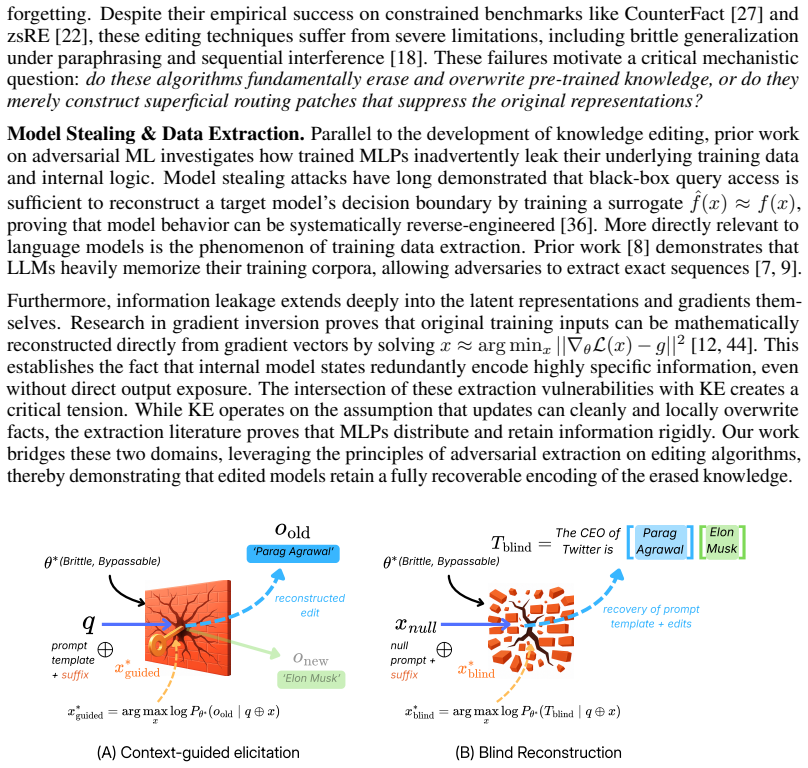
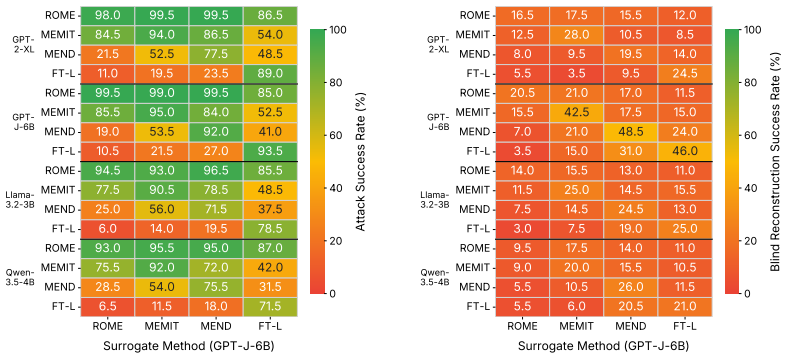


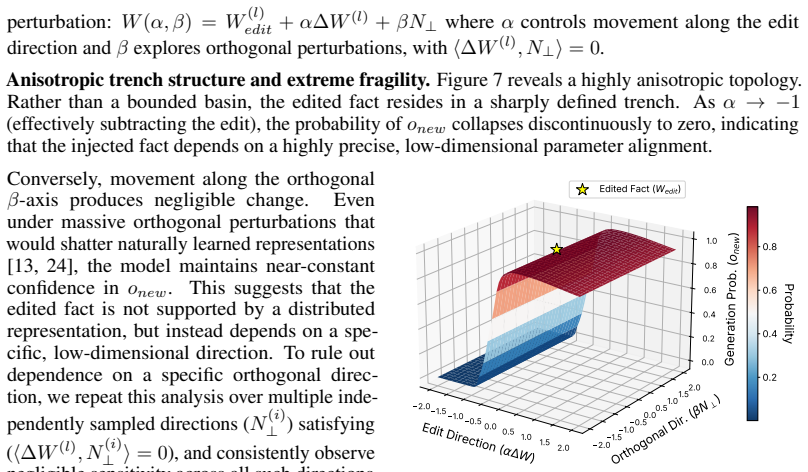









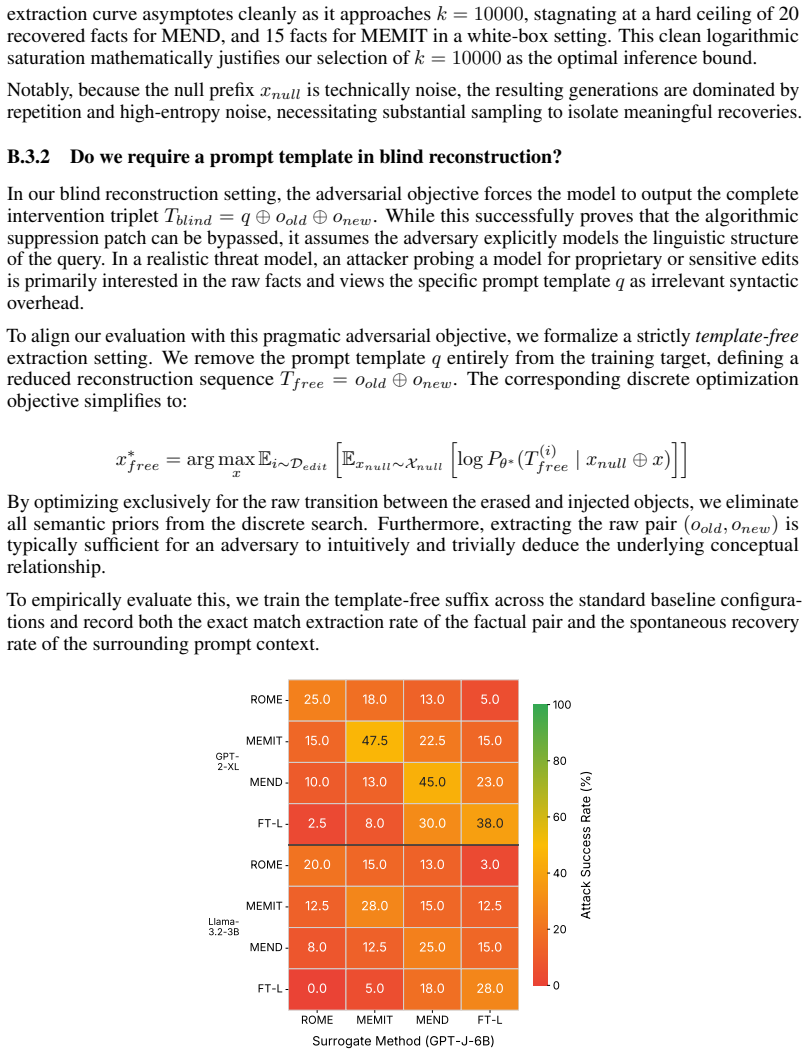


read the original abstract
Knowledge Editing (KE) has emerged as a frontier for updating specific facts in LLMs without costly retraining, but its reliability and underlying mechanisms remain poorly understood. In this work, we examine KE from an adversarial elicitation perspective, revealing that edited knowledge is often not fully erased and continues to surface, with consistent failures observed across diverse model architectures. To explain this behavior, we conduct a mechanistic analysis of popular KE methods. We show that low-rank updates do not overwrite existing knowledge but instead redistribute it within the model's representation space. Furthermore, we find that these methods act as targeted suppression mechanisms that reduce the likelihood of expressing original facts, rather than removing them from the model. Analysis of the loss landscape reveals that edited knowledge lies in narrow, anisotropic regions that are highly sensitive to perturbations, making them highly vulnerable to indirect prompting and adversarial attacks. By exposing these profound architectural vulnerabilities, our work proves that KE algorithms are inherently bypassable and motivates a fundamental reevaluation of how we deploy post-hoc updates in several LLM applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines knowledge editing (KE) in LLMs via adversarial elicitation and mechanistic analysis, claiming that low-rank updates do not erase facts but redistribute them in representation space, functioning as targeted suppression; loss-landscape analysis shows edited knowledge occupies narrow, anisotropic regions vulnerable to indirect prompts, proving KE methods are inherently bypassable across architectures.
Significance. If the empirical patterns hold, the work identifies a core limitation in post-hoc editing techniques, showing that apparent success on direct probes masks residual knowledge accessible via perturbations; this would motivate reevaluation of KE deployment in safety-critical or fact-sensitive applications and encourage development of more robust editing or verification methods.
major comments (2)
- [Mechanistic analysis and loss-landscape sections] The central mechanistic claim—that low-rank updates redistribute rather than attenuate original knowledge encodings—rests on indirect evidence (adversarial prompt success rates and loss-surface curvature). This inference is load-bearing for the 'illusion of erasure' conclusion but lacks direct localization of the pre-edit representation (e.g., via causal tracing or cosine similarity of fact encodings before/after edit), leaving the redistribution interpretation underdetermined relative to partial suppression.
- [Experimental setup and results] The abstract and results assert consistent failures 'across diverse model architectures,' yet the provided text gives no details on model sizes, number of edits, statistical controls, or baseline comparisons; without these, it is unclear whether the reported vulnerability generalizes or is an artifact of specific experimental choices.
minor comments (1)
- [Loss landscape analysis] Notation for 'anisotropic regions' and 'narrow high-curvature' areas in the loss landscape should be defined more precisely (e.g., via Hessian eigenvalues or perturbation norms) to allow replication.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for clarification and strengthening. We address each major comment below and commit to revisions that enhance the rigor of our claims without altering the core findings.
read point-by-point responses
-
Referee: [Mechanistic analysis and loss-landscape sections] The central mechanistic claim—that low-rank updates redistribute rather than attenuate original knowledge encodings—rests on indirect evidence (adversarial prompt success rates and loss-surface curvature). This inference is load-bearing for the 'illusion of erasure' conclusion but lacks direct localization of the pre-edit representation (e.g., via causal tracing or cosine similarity of fact encodings before/after edit), leaving the redistribution interpretation underdetermined relative to partial suppression.
Authors: We appreciate this observation on the strength of evidence. Our mechanistic conclusions are supported by the combination of high adversarial elicitation rates (indicating residual knowledge) and the loss-landscape analysis showing narrow, high-curvature regions post-edit, which is inconsistent with uniform attenuation. However, we agree that direct measures would reduce ambiguity. In the revised version, we will add cosine similarity computations between pre-edit and post-edit activations for the edited facts across layers, along with a brief discussion of why causal tracing was not the primary tool (due to its computational cost on large models). This will make the redistribution interpretation more robust. revision: yes
-
Referee: [Experimental setup and results] The abstract and results assert consistent failures 'across diverse model architectures,' yet the provided text gives no details on model sizes, number of edits, statistical controls, or baseline comparisons; without these, it is unclear whether the reported vulnerability generalizes or is an artifact of specific experimental choices.
Authors: We regret that the experimental details were not sufficiently prominent in the version reviewed. The manuscript reports results on Llama-2-7B, Llama-2-13B, Mistral-7B, and GPT-J-6B, using 150 edits per method drawn from CounterFact and ZsRE, with performance aggregated over three random seeds (reporting mean and standard deviation). Baselines include unedited models and alternative KE methods (ROME, MEMIT). In the revision, we will expand the 'Experimental Setup' section with a dedicated table listing all model sizes, edit counts, hyperparameters, and statistical procedures to ensure full reproducibility and address concerns about generalization. revision: yes
Circularity Check
No circularity; empirical claims rest on observations without self-referential derivations
full rationale
The paper advances its central claims (low-rank KE updates redistribute rather than erase knowledge; edits act as suppression; edited facts occupy narrow anisotropic loss regions) via adversarial elicitation experiments and loss-landscape measurements. No equations, fitted parameters, or derivation chains are presented that reduce any result to its own inputs by construction. No self-citation is invoked as a uniqueness theorem or load-bearing premise for the mechanistic interpretation. The analysis is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM internal representations can be meaningfully analyzed via low-rank updates and loss landscapes
Reference graph
Works this paper leans on
-
[1]
One mask to rule them all: On hidden facts after editing and how to find them
Anonymous. One mask to rule them all: On hidden facts after editing and how to find them. In Submitted to ACL Rolling Review - January 2026, 2026. URL https://openreview.net/ forum?id=41ugxl82Xx. under review
2026
-
[2]
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirho- seini, C. McKinnon, C. Chen, C. Olsson, C. Olah, D. Hernandez, D. Drain, D. Ganguli, D. Li, E. Tran-Johnson, E. Perez, J. Kerr, J. Mueller, J. Ladish, J. Landau, K. Ndousse, K. Lukosuite, L. Lovitt, M. Sellitto, N. Elhage, N. Schiefer, N. Mercado, N. DasSarma, R...
Pith/arXiv arXiv 2022
-
[3]
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, page 610–623, New York, NY , USA,
2021
-
[4]
In: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency
Association for Computing Machinery. ISBN 9781450383097. doi: 10.1145/3442188. 3445922. URLhttps://doi.org/10.1145/3442188.3445922
-
[5]
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot. Machine unlearning, 2020. URLhttps://arxiv.org/abs/1912.03817
arXiv 2020
-
[6]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amo...
Pith/arXiv arXiv 2020
-
[7]
N. D. Cao, W. Aziz, and I. Titov. Editing factual knowledge in language models, 2021. URL https://arxiv.org/abs/2104.08164
arXiv 2021
-
[8]
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson, A. Oprea, and C. Raffel. Extracting training data from large language models, 2021. URLhttps://arxiv.org/abs/2012.07805
arXiv 2021
-
[9]
N. Carlini, D. Ippolito, M. Jagielski, K. Lee, F. Tramer, and C. Zhang. Quantifying memorization across neural language models, 2023. URLhttps://arxiv.org/abs/2202.07646
Pith/arXiv arXiv 2023
-
[10]
C. Dai, L. Lu, and P. Zhou. Stealing training data from large language models in decentralized training through activation inversion attack, 2025. URL https://arxiv.org/abs/2502. 16086
2025
-
[11]
D. Dai, L. Dong, Y . Hao, Z. Sui, B. Chang, and F. Wei. Knowledge neurons in pretrained transformers, 2022. URLhttps://arxiv.org/abs/2104.08696
arXiv 2022
-
[12]
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur. Sharpness-aware minimization for efficiently improving generalization, 2021. URLhttps://arxiv.org/abs/2010.01412
Pith/arXiv arXiv 2021
-
[13]
J. Geiping, H. Bauermeister, H. Dröge, and M. Moeller. Inverting gradients – how easy is it to break privacy in federated learning?, 2020. URLhttps://arxiv.org/abs/2003.14053
arXiv 2020
-
[14]
B. Ghorbani, S. Krishnan, and Y . Xiao. An investigation into neural net optimization via hessian eigenvalue density, 2019. URLhttps://arxiv.org/abs/1901.10159. 10
Pith/arXiv arXiv 2019
-
[15]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Mar...
Pith/arXiv arXiv 2024
-
[16]
P. Guo, A. Syed, A. Sheshadri, A. Ewart, and G. K. Dziugaite. Mechanistic unlearning: Robust knowledge unlearning and editing via mechanistic localization, 2024. URL https: //arxiv.org/abs/2410.12949
arXiv 2024
-
[17]
P. Hase, M. Bansal, B. Kim, and A. Ghandeharioun. Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models, 2023. URLhttps://arxiv.org/abs/2301.04213
arXiv 2023
-
[18]
Flat minima.Neural Computation, 9(1):1–42, 1997
S. Hochreiter and J. Schmidhuber. Flat minima.Neural Computation, 9(1):1–42, 01 1997. ISSN 0899-7667. doi: 10.1162/neco.1997.9.1.1. URL https://doi.org/10.1162/neco. 1997.9.1.1
-
[19]
J. Hoelscher-Obermaier, J. Persson, E. Kran, I. Konstas, and F. Barez. Detecting edit failures in large language models: An improved specificity benchmark, 2023. URL https://arxiv. org/abs/2305.17553
arXiv 2023
- [20]
-
[21]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, Mar. 2023. ISSN 1557-7341. doi: 10.1145/3571730. URL http://dx.doi.org/10.1145/ 3571730
-
[22]
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On large-batch training for deep learning: Generalization gap and sharp minima, 2017. URL https://arxiv. org/abs/1609.04836
Pith/arXiv arXiv 2017
-
[23]
O. Levy, M. Seo, E. Choi, and L. Zettlemoyer. Zero-shot relation extraction via reading comprehension. In R. Levy and L. Specia, editors,Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 333–342, Vancouver, Canada, Aug. 2017. Association for Computational Linguistics. doi: 10.18653/v1/K17-1034. URL https://a...
-
[24]
O. Levy, M. Seo, E. Choi, and L. Zettlemoyer. Zero-shot relation extraction via reading comprehension, 2017. URLhttps://arxiv.org/abs/1706.04115
Pith/arXiv arXiv 2017
-
[25]
H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein. Visualizing the loss landscape of neural nets, 2018. URLhttps://arxiv.org/abs/1712.09913
Pith/arXiv arXiv 2018
-
[26]
S. Lin, J. Hilton, and O. Evans. Truthfulqa: Measuring how models mimic human falsehoods,
-
[27]
URLhttps://arxiv.org/abs/2109.07958
-
[28]
K. Meng, D. Bau, A. Andonian, and Y . Belinkov. Locating and editing factual associations in gpt, 2023. URLhttps://arxiv.org/abs/2202.05262
Pith/arXiv arXiv 2023
-
[29]
K. Meng, A. S. Sharma, A. Andonian, Y . Belinkov, and D. Bau. Mass-editing memory in a transformer, 2023. URLhttps://arxiv.org/abs/2210.07229
Pith/arXiv arXiv 2023
-
[30]
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning. Fast model editing at scale, 2022. URLhttps://arxiv.org/abs/2110.11309. 12
arXiv 2022
-
[31]
E. Mitchell, C. Lin, A. Bosselut, C. D. Manning, and C. Finn. Memory-based model editing at scale, 2022. URLhttps://arxiv.org/abs/2206.06520
arXiv 2022
-
[32]
Language Models are Unsupervised Multitask Learners
OpenAI. Language Models are Unsupervised Multitask Learners. https://cdn.openai. com/better-language-models/language_models_are_unsupervised_multitask_ learners.pdf
-
[33]
Politou, A
E. Politou, A. Michota, E. Alepis, M. Pocs, and C. Patsakis. Backups and the right to be forgotten in the gdpr: An uneasy relationship.Computer Law & Security Review, 34(6): 1247–1257, 2018
2018
-
[34]
A. Roberts, C. Raffel, and N. Shazeer. How much knowledge can you pack into the parameters of a language model?, 2020. URLhttps://arxiv.org/abs/2002.08910
Pith/arXiv arXiv 2020
-
[35]
R. Shokri, M. Stronati, C. Song, and V . Shmatikov. Membership inference attacks against machine learning models, 2017. URLhttps://arxiv.org/abs/1610.05820
Pith/arXiv arXiv 2017
-
[36]
X. Song, Z. Wang, K. He, G. Dong, Y . Mou, J. Zhao, and W. Xu. Knowledge editing on black-box large language models, 2024. URLhttps://arxiv.org/abs/2402.08631
arXiv 2024
-
[37]
Steier, A
A. Steier, A. Manoel, A. Haushalter, and M. V . Segbroeck. Nemotron-pii: Synthesized data for privacy-preserving ai, 2025. URL https://huggingface.co/datasets/nvidia/ Nemotron-PII
2025
-
[38]
F. Tramèr, F. Zhang, A. Juels, M. K. Reiter, and T. Ristenpart. Stealing machine learning models via prediction apis, 2016. URLhttps://arxiv.org/abs/1609.02943
Pith/arXiv arXiv 2016
-
[39]
M. N. Uddin, A. Saeidi, D. Handa, A. Seth, T. C. Son, E. Blanco, S. Corman, and C. Baral. UnSeenTimeQA: Time-sensitive question-answering beyond LLMs’ memorization. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1873–1913,...
1913
-
[40]
URL https://aclanthology.org/2025.acl-long
doi: 10.18653/v1/2025.acl-long.94. URL https://aclanthology.org/2025.acl-long. 94/
-
[41]
Wang and A
B. Wang and A. Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model.https://github.com/kingoflolz/mesh-transformer-jax, May 2021
2021
-
[42]
P. Wang, N. Zhang, B. Tian, Z. Xi, Y . Yao, Z. Xu, M. Wang, S. Mao, X. Wang, S. Cheng, K. Liu, Y . Ni, G. Zheng, and H. Chen. Easyedit: An easy-to-use knowledge editing framework for large language models, 2024. URLhttps://arxiv.org/abs/2308.07269
arXiv 2024
-
[43]
S. Wang, Y . Zhu, H. Liu, Z. Zheng, C. Chen, and J. Li. Knowledge editing for large language models: A survey, 2024. URLhttps://arxiv.org/abs/2310.16218
arXiv 2024
-
[44]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
Pith/arXiv arXiv 2025
-
[45]
P. Youssef, Z. Zhao, C. Seifert, and J. Schlötterer. Tracing and reversing edits in llms, 2026. URLhttps://arxiv.org/abs/2505.20819
arXiv 2026
-
[46]
N. Zhang, Y . Yao, B. Tian, P. Wang, S. Deng, M. Wang, Z. Xi, S. Mao, J. Zhang, Y . Ni, S. Cheng, Z. Xu, X. Xu, J.-C. Gu, Y . Jiang, P. Xie, F. Huang, L. Liang, Z. Zhang, X. Zhu, J. Zhou, and H. Chen. A comprehensive study of knowledge editing for large language models, 2024. URL https://arxiv.org/abs/2401.01286
arXiv 2024
-
[47]
B. Zhao, K. R. Mopuri, and H. Bilen. idlg: Improved deep leakage from gradients, 2020. URL https://arxiv.org/abs/2001.02610. 13
arXiv 2020
-
[48]
C. Zhu, A. S. Rawat, M. Zaheer, S. Bhojanapalli, D. Li, F. Yu, and S. Kumar. Modifying memories in transformer models, 2020. URLhttps://arxiv.org/abs/2012.00363
arXiv 2020
-
[49]
implicit
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023. URL https://arxiv.org/abs/2307. 15043. 14 Appendix A Additional Observations Beyond the primary analyses presented in the main text, we report several additional observations that discuss and highlight fun...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.