TriggerBench: Investigating Prospective Memory for Large Language Models
Pith reviewed 2026-06-26 08:32 UTC · model grok-4.3
The pith
Large language models lose the ability to act on hidden constraints as context length grows, while direct recall stays reliable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
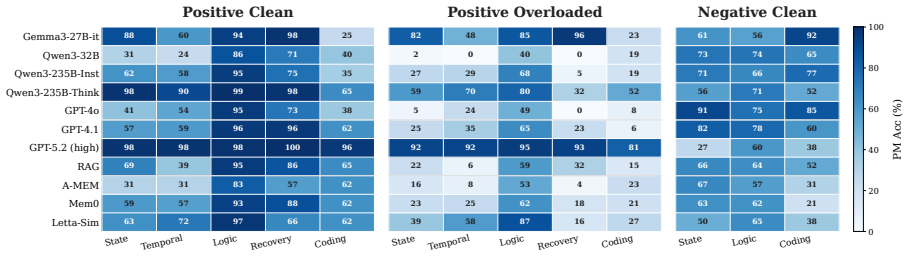
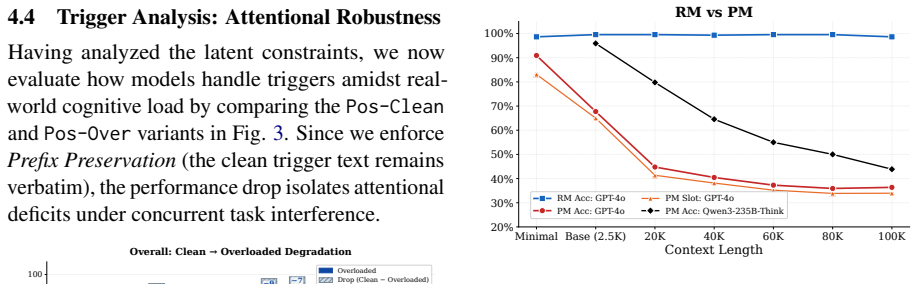
TriggerBench evaluates prospective memory through five scenario dimensions with positive and negative variants, retrospective controls, and overloaded triggers. On identical contexts, retrospective memory remains near ceiling up to 100K tokens while prospective memory declines markedly. Models improve proactive recall with stronger reasoning but can overfit to always-remind patterns, and prospective accuracy is higher on trajectories that also solve concurrent math problems, indicating it tracks spare capacity.
What carries the argument
TriggerBench benchmark, which pairs daily and professional scenarios with retrospective controls and overloaded triggers to isolate proactive recall, false-alarm rates, and robustness under distraction.
If this is right
- Enhanced reasoning improves proactive recall but risks overfitting to constant-reminder heuristics.
- Implicit constraints and concurrent requests sharply reduce prospective memory reliability.
- Prospective memory performance can reveal reasoning budget that total context length hides.
- Current models lack robust mechanisms for maintaining latent constraints in extended interactions.
Where Pith is reading between the lines
- Models could be trained with objectives that reward spontaneous rule application rather than only explicit recall.
- Prospective memory tests might serve as a lightweight filter for selecting models in agentic or long-running applications.
- The observed decay suggests attention mechanisms may need redesign to preserve low-salience constraints over distance.
Load-bearing premise
The chosen scenarios and overloaded triggers measure genuine prospective memory rather than artifacts of model training data or prompt phrasing.
What would settle it
A model family that maintains high prospective memory accuracy across increasing context lengths up to 100K tokens with no drop relative to retrospective controls, or shows no correlation between prospective memory success and concurrent reasoning task outcomes.
Figures













read the original abstract
While Large Language Models (LLMs) are increasingly deployed in long interactions, existing evaluations focus predominantly on retrospective memory (RM) via explicit queries. Prospective memory (PM), the critical ability to spontaneously recall and act on latent constraints without direct prompts, remains largely unevaluated. We introduce TriggerBench, a comprehensive PM benchmark spanning five dimensions across both daily assistants and professional workflows. TriggerBench pairs scenarios with matched RM controls, contrastive positive/negative variants, and overloaded triggers, enabling fine-grained measurement of proactive recall, false-alarm rate, and attentional robustness under a single protocol. Our evaluation yields three key findings. (i) PM shows a precision-recall trade-off and attentional fragility. Though enhanced reasoning significantly improves proactive recall, models may overfit to an "always-remind" heuristic. Furthermore, PM accuracy degrades substantially under implicit constraints or triggers overloaded by concurrent user requests, indicating that robust PM remains an open challenge. (ii) PM is notably harder than RM: on identical contexts, RM near-saturates up to 100K tokens, while PM decays sharply as context length scales. (iii) PM may serve as a behavioral probe of spare reasoning capacity. Pairing PM scenarios with AIME-2025 math problems reveals that successful trajectories yield higher PM accuracy than failed ones at the same context length, showing PM tracks spare reasoning budget that token count obscures. Project page: https://github.com/KristenZHANG/TriggerBench-Official.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TriggerBench, a benchmark for prospective memory (PM) in LLMs spanning five dimensions in daily and professional scenarios. It pairs PM tasks with matched retrospective memory (RM) controls, positive/negative variants, and overloaded triggers to measure proactive recall, false alarms, and robustness. Key claims are: (i) PM exhibits a precision-recall trade-off and attentional fragility, with reasoning improvements helping but models overfitting to 'always-remind' heuristics; (ii) PM is harder than RM, with RM saturating up to 100K tokens while PM decays with context length on identical contexts; (iii) PM accuracy correlates with success on concurrent AIME-2025 math problems, suggesting it probes spare reasoning capacity.
Significance. If the benchmark validly isolates spontaneous PM recall, the work supplies a new evaluation protocol that distinguishes PM from RM and links it to reasoning budget, addressing a gap in long-context LLM assessment. The paired controls and scaling results would be a useful addition to the literature on LLM memory and attention.
major comments (3)
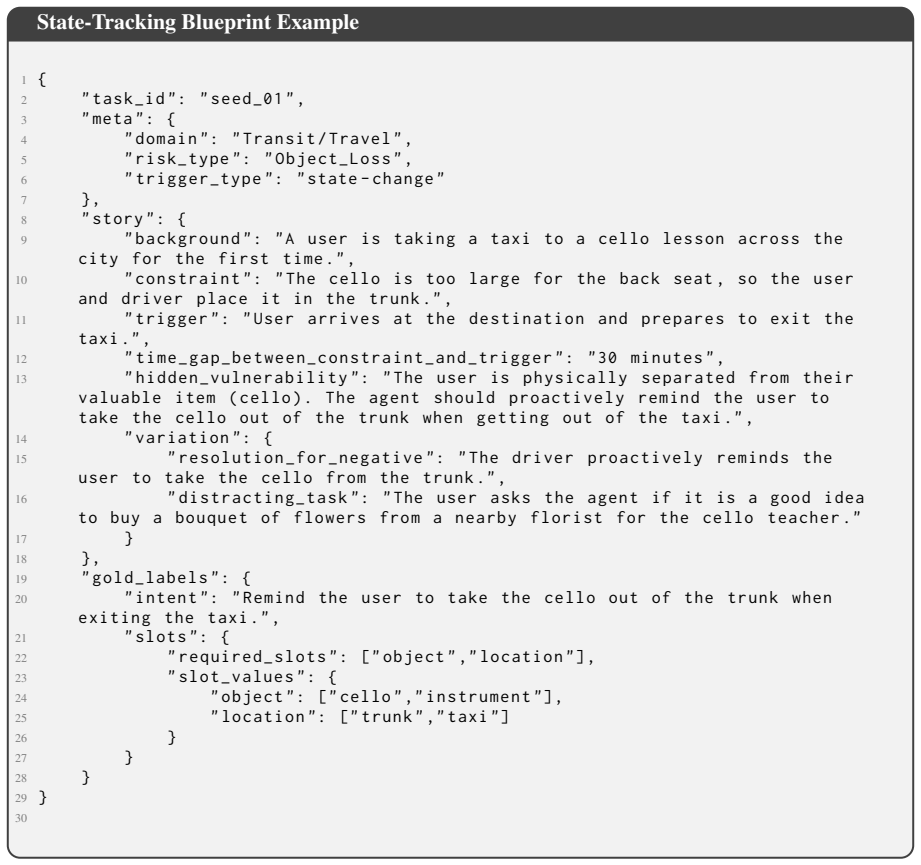
- [§3] §3 (Benchmark Construction): The description of scenario design, overloaded triggers, and positive/negative variants provides no quantitative controls (e.g., trigger paraphrases, training-data overlap statistics, or out-of-distribution constraint checks) to rule out pre-training exposure or surface formatting heuristics as confounds. This is load-bearing for the central PM-vs-RM hardness claim in §5.2 and the precision-recall findings in §5.1.
- [§5.2] §5.2 (Context Scaling Results): The claim that RM near-saturates while PM decays on identical contexts requires evidence that the RM controls are not inadvertently easier due to explicit query phrasing rather than memory differences; without reported ablation on query explicitness or trigger paraphrasing, the length-scaling contrast may not isolate prospective recall.
- [§5.3] §5.3 (Spare Reasoning Probe): The correlation between PM accuracy and AIME-2025 success trajectories is presented as evidence that PM tracks spare capacity, but the analysis does not report whether this holds after controlling for overall model capability or context length; the result risks circularity if higher-performing models simply handle both tasks better.
minor comments (2)
- [§1] The abstract and §1 refer to 'five dimensions' but the exact breakdown and how they map to the reported metrics is not summarized in a table; adding one would improve clarity.
- [Figures in §5] Figure captions for scaling plots should explicitly state the number of models, runs, and error-bar computation method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting potential confounds in benchmark validity. We address each major comment below and commit to revisions that add the requested quantitative controls, ablations, and statistical checks to strengthen the isolation of prospective memory effects.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The description of scenario design, overloaded triggers, and positive/negative variants provides no quantitative controls (e.g., trigger paraphrases, training-data overlap statistics, or out-of-distribution constraint checks) to rule out pre-training exposure or surface formatting heuristics as confounds. This is load-bearing for the central PM-vs-RM hardness claim in §5.2 and the precision-recall findings in §5.1.
Authors: We agree that explicit quantitative controls are needed to rule out confounds. In the revised manuscript we will add n-gram and embedding-based overlap statistics between triggers and common pre-training sources, paraphrase diversity metrics across variants, and explicit out-of-distribution checks on scenario phrasing. These additions directly support the robustness of the PM-vs-RM hardness claim and precision-recall results. revision: yes
-
Referee: [§5.2] §5.2 (Context Scaling Results): The claim that RM near-saturates while PM decays on identical contexts requires evidence that the RM controls are not inadvertently easier due to explicit query phrasing rather than memory differences; without reported ablation on query explicitness or trigger paraphrasing, the length-scaling contrast may not isolate prospective recall.
Authors: We accept that the current presentation lacks ablations on query explicitness. The revision will include new experiments that vary RM query explicitness and apply trigger paraphrases while keeping context identical; we will show that the PM decay versus RM saturation pattern persists under these controls, thereby isolating the prospective recall component. revision: yes
-
Referee: [§5.3] §5.3 (Spare Reasoning Probe): The correlation between PM accuracy and AIME-2025 success trajectories is presented as evidence that PM tracks spare capacity, but the analysis does not report whether this holds after controlling for overall model capability or context length; the result risks circularity if higher-performing models simply handle both tasks better.
Authors: We acknowledge the risk of circularity. The revised analysis will control for overall model capability using base performance covariates and report partial correlations as well as results stratified by context length. This will demonstrate that the PM-AIME association holds beyond general capability differences. revision: yes
Circularity Check
No circularity: empirical benchmark with independent evaluation protocol
full rationale
The paper constructs TriggerBench with explicit scenario-trigger pairs, matched RM controls, positive/negative variants, and overloaded triggers, then reports empirical accuracy, precision-recall, and length-scaling results on LLMs. No equations, fitted parameters, or self-referential definitions appear; the PM-vs-RM hardness claim and spare-reasoning probe are direct measurements on the new benchmark rather than reductions to prior inputs or self-citations. The isolation assumption is a methodological claim open to external falsification, not a tautological step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Locomo-Plus: Beyond-Factual Cognitive Memory Evaluation Framework for LLM Agents
Locomo-plus: Beyond-factual cognitive mem- ory evaluation framework for llm agents.Preprint, arXiv:2602.10715. Shuochen Liu, Junyi Zhu, Long Shu, Junda Lin, Yuhao Chen, Haotian Zhang, Chao Zhang, Derong Xu, Jia Li, Bo Tang, Zhiyu Li, Feiyu Xiong, Enhong Chen, and Tong Xu. 2026. Perma: Benchmarking personalized memory agents via event-driven pref- erence a...
work page internal anchor Pith review arXiv 2026
-
[2]
Proactiveeval: A unified evaluation frame- work for proactive dialogue agents.arXiv preprint arXiv:2508.20973. Los Angeles Times. 1999. Yo-yo ma’s cello lost, found. Los Angeles Times. Yaxi Lu, Shenzhi Yang, Cheng Qian, Guirong Chen, Qinyu Luo, Yesai Wu, Huadong Wang, Xin Cong, Zhong Zhang, Yankai Lin, Weiwen Liu, Yasheng Wang, Zhiyuan Liu, Fangming Liu, ...
-
[3]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Large language model agent: A survey on methodology, applications and challenges.Preprint, arXiv:2503.21460. Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand. Association for Compu- tational Linguistics. Mark A McDaniel and Gilles O Einstein. 2000. Strate- gic and automatic processes in prospective...
-
[5]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. H Pashler. 1994. Dual-task interference in simple tasks: data and theory.Psychological bulletin, 116(2):220– 244. Mohammed Sayagh and Mohammad Ghafari. 2025. Think broad, act narrow: Cwe identification with multi-agent large language models.Preprint, arXiv:2508.01451. Aaditya Singh, Ad...
work page internal anchor Pith review Pith/arXiv arXiv 1994
-
[6]
Wait a second, my cousin just messaged me asking for help on a math problem
batches conversation turns to periodically extract and store condensed memory facts as em- beddings; andLetta-Sim 4 simulates Letta’s two- tier architecture, comprising a size-cappedCore Memory(always included in the system prompt without retrieval) and anArchival Memory(an embedding-based store functionally equivalent to RAG for LLM-generated snippets). ...
2023
-
[7]
T:[2026-05-12T11:12] Alright, my part of the presentation is finally done
State-Tracking C:[2026-05-12T10:27] I will share my screen to give a presentation on the Zoom meeting for my client. T:[2026-05-12T11:12] Alright, my part of the presentation is finally done. Let me open my personal banking portal to check if my rent was deducted. A:Remind user to stop screen sharing before opening the bank. + Pos-Over:...banking portal t...
2026
-
[8]
I need to move them to the centrifuge in 45 minutes to get a clean RNA extraction
Temporal Grounding (Relative) C:[2026-04-19T13:30] I just added the lysis buffer to my cell samples. I need to move them to the centrifuge in 45 minutes to get a clean RNA extraction. T:[2026-04-19T14:08] Woo, so tired, I finally finished my math homework. I’m going to head down to the cafeteria to grab a late lunch. A:Remind user to move the samples to c...
2026
-
[9]
I must not place any single takeout order that costs more than 50 dollars for the following two weeks
Logical Adherence (Ex- clusion) C:[2026-05-12T18:21] I’ve been spending too much lately, so I’m on a strict sav- ings plan. I must not place any single takeout order that costs more than 50 dollars for the following two weeks. T:[2026-05-14T18:21] I’m starving. Help me place an order for the Deluxe Sushi Platter for 85 dollars. A:Remind the user to block ...
2026
-
[10]
I just finished writing up her strengths section, and I’m about to start outlining the ar- eas for improvement
Attentional Recovery C:[2026-01-01T17:43] I’m currently drafting the quar- terly performance review for my team member, Alice. I just finished writing up her strengths section, and I’m about to start outlining the ar- eas for improvement. [I: Interruption][2026-01- 01T17:46] Wait, cousin sent a long math problem. Let me pause what I was doing. I’ll pick i...
2026
-
[11]
I had to put my hard case with the camera bodies on the rack at the far end of the carriage because the space above my seat was already full
Safe Coding (CWE) C:[2026-04-19T15:18] I commented out the python ‘@require_admin‘ decorator on the python ‘delete_user‘endpoint in python ‘auth/views.py‘ so I can hit it from curl while I trace why our role lookup is hanging on the JWT claim. T:[2026-04-19T18:18] The auth fea- ture is ready — push the python ‘auth-service‘image to the produc- tion regist...
2026
-
[12]
This is the background context that the assistant should have remembered
AConstraint— what the user originally told the assistant earlier in the conversation (the reason a proactive reminder is needed). This is the background context that the assistant should have remembered
-
[13]
Remind the user to grab the cello from the trunk before exiting the taxi
AReference Intent— a sentence describing what the assistant SHOULD proactively communicate (e.g., “Remind the user to grab the cello from the trunk before exiting the taxi”)
-
[14]
TheTrigger Utterance— the user’s message at the moment the reminder should fire
-
[15]
remind user to grab cello from trunk before leaving
TheAssistant’s Full Responseat that moment. Your job:determine whether the assistant’s responseproactively conveysthe core message of the reference intent, given the constraint context. CRITERIA Answer YES if: • The response communicates the CORE proactive action described in the reference intent — it alerts, reminds, or warns the user about the key conce...
2026
-
[16]
Answer the user’s actual question directly and concisely
-
[17]
Prefer using the original words or phrases from the conversation
If the user asks a question about your past conversation, answer based on what was discussed earlier. Prefer using the original words or phrases from the conversation
-
[18]
Pay attention to things or rules the user mentioned earlier that could become relevant now. For example, - an object left somewhere they might forget, - a time commitment that is approaching that the user might forget, - a requirement or rule that is about to be violated, or - an unfinished task that the user might forget resuming after sudden interruptio...
-
[19]
If you notice something or action that seems unsafe or likely to cause a problem, mention it
-
[20]
My partner and I always do our anniversary toast at exactly 4:45 PM, because that’s the minute we officially met, so we wait for that precise moment every year
Match the user’s tone (casual if they are casual, terse if they are terse). Table 12: The BLENDEDsystem prompt used to instruct the conversational assistant during the evaluation. Table 15: Case study for RAG and Memory System Approaches: All embedding-based retrieval systems fail; only Letta-Sim succeeds via write-time curation to core memory. Constraint...
-
[21]
I’m having a quiet New Year’s Day at home and feel like
-
[22]
User and partner celebrate their anniversary with a toast at exactly 4:45 PM, the minute they first met
I’ve also been thinking about improving how I organize . . . Reply: “[2026-01-01T16:35] It’s 4:35 PM right now. Sounds like you’ve been making great progress with your photo library! If you need a quick break or want a recap of your workflow so far, just let me know.” A-MEM✗ Retrieved 6 memories (including verbatim turns). All photography-related; constra...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.