Quantifying the Agreement Between Data-Influence and Data-Similarity to Understand LLM Behavior
Pith reviewed 2026-06-26 08:43 UTC · model grok-4.3
The pith
Data-similarity and data-influence rankings of LLM training documents agree significantly, with asymmetry favoring consistency in one direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
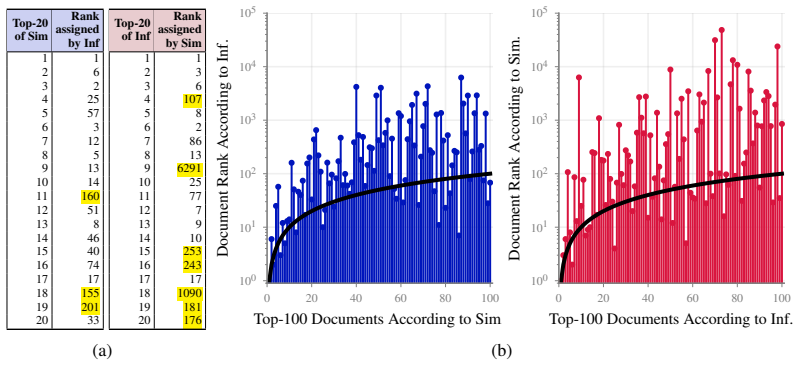
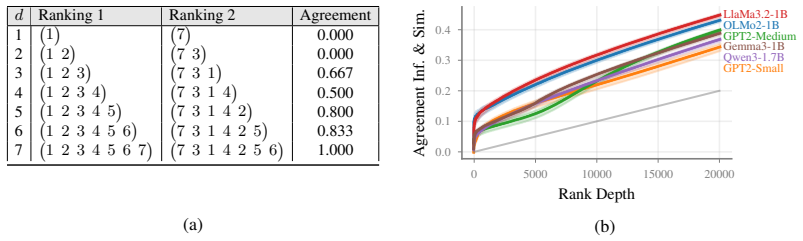
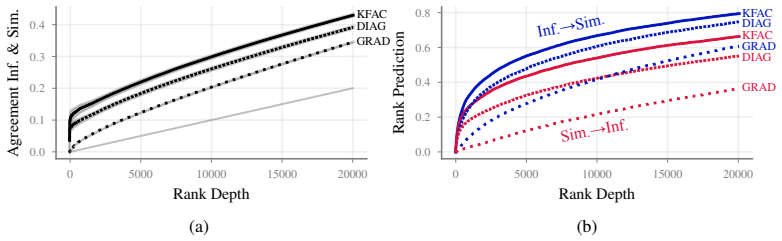
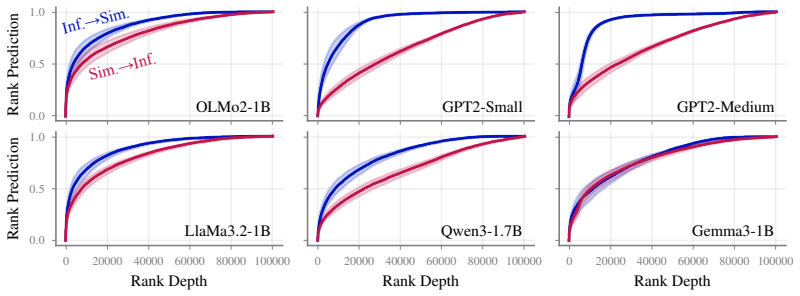
By ranking training documents according to data-similarity and data-influence and then computing the overlap between the two rankings, the measures agree significantly, but the top documents of data-similarity are assigned more consistent ranks by data-influence than the other way around. This pattern is observed across experiments on OLMo2-1B, Qwen3-1.7B, LlaMa3.2-1B, Gemma3-1B, and GPT2, and it supports using costly data-influence computations only to refine the top results obtained from data-similarity.
What carries the argument
Overlap between ranked lists of training documents produced by data-similarity versus data-influence measures.
If this is right
- Data-similarity can serve as a practical first pass for identifying influential training documents.
- Data-influence can be applied selectively to the top-ranked documents from similarity to improve precision at lower total cost.
- The observed agreement and asymmetry pattern generalizes across at least five different 1B-scale language models.
- Ranked-list overlap provides a direct, quantitative way to compare tracing methods without requiring labeled ground-truth tasks.
Where Pith is reading between the lines
- The asymmetry may indicate that data-similarity surfaces a core subset of documents that influence also identifies reliably, while influence surfaces additional documents that similarity ranks less stably.
- Practitioners could adopt a two-stage pipeline in which similarity first narrows the candidate set and influence only re-ranks the shortlist.
- If the pattern persists at larger scales, it would reduce the computational barrier to routine training-data attribution for deployed models.
Load-bearing premise
That measuring overlap between two ranked lists of training documents is enough to establish how well data-similarity and data-influence agree when the goal is to trace LLM outputs.
What would settle it
A controlled experiment in which ground-truth influential documents are known in advance and the observed ranking overlap fails to predict actual tracing accuracy or the reported asymmetry disappears.
Figures






























read the original abstract
One way to understand LLM behavior is to trace its output back to the training data. Two types of measures are commonly used for output tracing: data-similarity and data-influence. The former is cheaper while the latter is believed to be more accurate. Even though many works have compared them for ground-truth tasks, no such comparisons exist for output tracing. Here, we fill this gap and precisely quantify the commonalities and differences between the two measures. We do this by first ranking the training documents according to each measure and then computing the overlap between the two rankings. Our main finding is that the two rankings agree significantly, but there is an asymmetry between them: The top documents of data-similarity are assigned more consistent ranks by data-influence than the other way around. This result is valid across a range of experiments involving OLMo2-1B, Qwen3-1.7B, LlaMa3.2-1B, Gemma3-1B, and GPT2. We exploit the asymmetry to obtain a favorable cost-accuracy trade-off by using the costly data-influence to refine the results of data-similarity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to quantify agreement between data-similarity and data-influence for tracing LLM outputs to training data by ranking documents under each measure and measuring ranking overlap. It reports significant agreement with an asymmetry (top documents from data-similarity receive more consistent ranks under data-influence than the reverse), demonstrates this across OLMo2-1B, Qwen3-1.7B, LlaMa3.2-1B, Gemma3-1B and GPT2, and proposes using data-influence to refine data-similarity results for an improved cost-accuracy trade-off.
Significance. If ranking overlap reliably proxies agreement in tracing fidelity, the work would enable more efficient hybrid attribution methods for understanding LLM behavior. The multi-model validation and explicit asymmetry finding are strengths, but the absence of ground-truth tracing tasks to confirm that overlap corresponds to actual output influence limits the result's significance for behavioral claims.
major comments (2)
- [Experimental setup / Results] The central methodological choice to use ranking overlap (top-k intersection or rank correlation) as a direct proxy for agreement between the two measures, without any ground-truth tracing task for validation, is load-bearing for all claims about LLM behavior; prior work used such tasks, and nothing here tests whether high-overlap documents are the ones that truly drive outputs (see skeptic note on proxy alignment).
- [Results] The reported asymmetry and hybrid trade-off could be artifacts of score normalization or thresholding rather than behavioral agreement; no controls or sensitivity analysis for these choices are described, undermining the cross-model consistency claim.
minor comments (1)
- [Abstract] The abstract does not specify the exact overlap metric (e.g., top-k vs. Spearman) or the precise definition of 'consistent ranks,' which should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on our paper. We address the major comments below, clarifying our methodological choices and committing to additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental setup / Results] The central methodological choice to use ranking overlap (top-k intersection or rank correlation) as a direct proxy for agreement between the two measures, without any ground-truth tracing task for validation, is load-bearing for all claims about LLM behavior; prior work used such tasks, and nothing here tests whether high-overlap documents are the ones that truly drive outputs (see skeptic note on proxy alignment).
Authors: Our primary objective is to quantify the agreement between data-similarity and data-influence measures through their induced rankings on training documents for given outputs. While we acknowledge that ranking overlap is a proxy for measure agreement rather than a direct test of tracing fidelity to actual output drivers, this approach allows us to compare the two measures in a setting where ground-truth attribution tasks are not readily available for the models studied. We will revise the manuscript to explicitly discuss this distinction, reference prior work on ground-truth tasks, and add a limitations section on the proxy's implications for behavioral claims. revision: partial
-
Referee: [Results] The reported asymmetry and hybrid trade-off could be artifacts of score normalization or thresholding rather than behavioral agreement; no controls or sensitivity analysis for these choices are described, undermining the cross-model consistency claim.
Authors: We agree that sensitivity to normalization and thresholding choices is important to verify. In the revised version, we will include additional experiments and controls that vary the score normalization procedures and threshold values used for ranking, demonstrating that the observed asymmetry and the benefits of the hybrid approach persist across these variations. This will strengthen the cross-model consistency claims. revision: yes
Circularity Check
No circularity: purely empirical ranking overlap with no self-referential derivations
full rationale
The paper conducts an empirical comparison by ranking training documents according to data-similarity and data-influence, then measuring overlap between those rankings across multiple LLMs. No equations, fitted parameters, or derivations are present that reduce the reported agreement or asymmetry to inputs by construction. The analysis relies on direct computation of rank overlaps rather than any self-definitional, fitted-prediction, or self-citation load-bearing steps. Prior work is cited only for context on ground-truth tasks, not as a load-bearing justification for the current results. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ranking overlap between data-similarity and data-influence is a valid measure of their agreement for output tracing
Reference graph
Works this paper leans on
-
[1]
Variational
Shen, Yuesong and Daheim, Nico and Cong, Bai and Nickl, Peter and Marconi, Gian Maria and Raoul, Bazan Clement Emile Marcel and Yokota, Rio and Gurevych, Iryna and Cremers, Daniel and Khan, Mohammad Emtiyaz and M. Variational. 2024 , month = jul, pages =
2024
-
[2]
Sharpness-Aware
Foret, Pierre and Kleiner, Ariel and Mobahi, Hossein and Neyshabur, Behnam , year =. Sharpness-Aware. International
-
[3]
Khan, Mohammad Emtiyaz and Rue, Håvard , month = jun, year =. The. doi:10.48550/arXiv.2107.04562 , publisher =
-
[4]
An overview of gradient descent optimization algorithms
Ruder, Sebastian , month = jun, year =. An overview of gradient descent optimization algorithms , url =. doi:10.48550/arXiv.1609.04747 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1609.04747
-
[5]
The Memory Perturbation Equation: Understanding Model's Sensitivity to Data , author=
-
[6]
Cong, Bai and Daheim, Nico and Shen, Yuesong and Cremers, Daniel and Yokota, Rio and Khan, Mohammad Emtiyaz and Möllenhoff, Thomas , month = nov, year =. Variational. doi:10.48550/arXiv.2411.04421 , publisher =
-
[7]
Daheim, Nico and Möllenhoff, Thomas and Ponti, Edoardo Maria and Gurevych, Iryna and Khan, Mohammad Emtiyaz , month = aug, year =. Model. doi:10.48550/arXiv.2310.12808 , publisher =
-
[8]
Foundations and Trends® in Machine Learning , author =
User-friendly introduction to. Foundations and Trends® in Machine Learning , author =. 2024 , note =. doi:10.1561/2200000100 , number =
-
[9]
and Carbin, Michael , month = jul, year =
Frankle, Jonathan and Dziugaite, Gintare Karolina and Roy, Daniel M. and Carbin, Michael , month = jul, year =. Linear. doi:10.48550/arXiv.1912.05671 , publisher =
-
[10]
Matena, Michael and Raffel, Colin , month = aug, year =. Merging. doi:10.48550/arXiv.2111.09832 , publisher =
-
[11]
Ilharco, Gabriel and Ribeiro, Marco Tulio and Wortsman, Mitchell and Gururangan, Suchin and Schmidt, Ludwig and Hajishirzi, Hannaneh and Farhadi, Ali , month = mar, year =. Editing. doi:10.48550/arXiv.2212.04089 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.04089
-
[12]
Bae, Juhan and Ng, Nathan and Lo, Alston and Ghassemi, Marzyeh and Grosse, Roger , month = sep, year =. If. doi:10.48550/arXiv.2209.05364 , publisher =
-
[13]
Grosse, Roger and Bae, Juhan and Anil, Cem and Elhage, Nelson and Tamkin, Alex and Tajdini, Amirhossein and Steiner, Benoit and Li, Dustin and Durmus, Esin and Perez, Ethan and Hubinger, Evan and Lukošiūtė, Kamilė and Nguyen, Karina and Joseph, Nicholas and McCandlish, Sam and Kaplan, Jared and Bowman, Samuel R. , month = aug, year =. Studying. doi:10.485...
-
[14]
Bae, Juhan and Lin, Wu and Lorraine, Jonathan and Grosse, Roger , month = may, year =. Training. doi:10.48550/arXiv.2405.12186 , publisher =
-
[15]
Hara, Satoshi and Nitanda, Atsushi and Maehara, Takanori , year =. Data. Advances in
-
[16]
Basu, Samyadeep and Pope, Philip and Feizi, Soheil , month = feb, year =. Influence. doi:10.48550/arXiv.2006.14651 , publisher =
-
[17]
Nickl, Peter and Xu, Lu and Tailor, Dharmesh and Möllenhoff, Thomas and Khan, Mohammad Emtiyaz , month = jan, year =. The. doi:10.48550/arXiv.2310.19273 , publisher =
-
[18]
Park, Sung Min and Georgiev, Kristian and Ilyas, Andrew and Leclerc, Guillaume and Madry, Aleksander , year =
-
[19]
Li, Zhe and Zhao, Wei and Li, Yige and Sun, Jun , month = dec, year =. Do. doi:10.48550/arXiv.2409.19998 , publisher =
-
[20]
Li, Rui and Klasson, Marcus and Solin, Arno and Trapp, Martin , month = nov, year =. Streamlining. doi:10.48550/arXiv.2411.18425 , publisher =
-
[21]
Choe, Sang Keun and Ahn, Hwijeen and Bae, Juhan and Zhao, Kewen and Kang, Minsoo and Chung, Youngseog and Pratapa, Adithya and Neiswanger, Willie and Strubell, Emma and Mitamura, Teruko and Schneider, Jeff and Hovy, Eduard and Grosse, Roger and Xing, Eric , month = may, year =. What is. doi:10.48550/arXiv.2405.13954 , publisher =
-
[22]
Wang, Xu and Hu, Yan and Du, Wenyu and Cheng, Reynold and Wang, Benyou and Zou, Difan , month = feb, year =. Towards. doi:10.48550/arXiv.2502.11812 , publisher =
-
[23]
Syed, Aaquib and Rager, Can and Conmy, Arthur , month = nov, year =. Attribution. doi:10.48550/arXiv.2310.10348 , publisher =
-
[24]
Hanna, Michael and Pezzelle, Sandro and Belinkov, Yonatan , month = jul, year =. Have. doi:10.48550/arXiv.2403.17806 , publisher =
-
[25]
Axiomatic Attribution for Deep Networks
Sundararajan, Mukund and Taly, Ankur and Yan, Qiqi , month = jun, year =. Axiomatic. doi:10.48550/arXiv.1703.01365 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1703.01365
-
[26]
Messmer, Bettina and Sabolčec, Vinko and Jaggi, Martin , month = feb, year =. Enhancing. doi:10.48550/arXiv.2502.10361 , publisher =
-
[27]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Allal, Loubna Ben and Lozhkov, Anton and Bakouch, Elie and Blázquez, Gabriel Martín and Penedo, Guilherme and Tunstall, Lewis and Marafioti, Andrés and Kydlíček, Hynek and Lajarín, Agustín Piqueres and Srivastav, Vaibhav and Lochner, Joshua and Fahlgren, Caleb and Nguyen, Xuan-Son and Fourrier, Clémentine and Burtenshaw, Ben and Larcher, Hugo and Zhao, Ha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.02737
-
[28]
doi:10.48550/arXiv.2310.00902 , publisher =
Kwon, Yongchan and Wu, Eric and Wu, Kevin and Zou, James , month = mar, year =. doi:10.48550/arXiv.2310.00902 , publisher =
-
[29]
and Hajishirzi, Hannaneh , year =
Walsh, Evan Pete and Soldaini, Luca and Groeneveld, Dirk and Lo, Kyle and Arora, Shane and Bhagia, Akshita and Gu, Yuling and Huang, Shengyi and Jordan, Matt and Lambert, Nathan and Schwenk, Dustin and Tafjord, Oyvind and Anderson, Taira and Atkinson, David and Brahman, Faeze and Clark, Christopher and Dasigi, Pradeep and Dziri, Nouha and Ettinger, Allyso...
-
[30]
SOAP: Improving and Stabilizing Shampoo using Adam
Vyas, Nikhil and Morwani, Depen and Zhao, Rosie and Kwun, Mujin and Shapira, Itai and Brandfonbrener, David and Janson, Lucas and Kakade, Sham , month = jan, year =. doi:10.48550/arXiv.2409.11321 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.11321
-
[31]
Shampoo: Preconditioned Stochastic Tensor Optimization
Gupta, Vineet and Koren, Tomer and Singer, Yoram , month = mar, year =. Shampoo:. doi:10.48550/arXiv.1802.09568 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.09568
-
[32]
Martens, James and Grosse, Roger , month = jun, year =. Optimizing. doi:10.48550/arXiv.1503.05671 , publisher =
-
[33]
Gao, Kai-Xin and Liu, Xiao-Lei and Huang, Zheng-Hai and Wang, Min and Wang, Shuangling and Wang, Zidong and Xu, Dachuan and Yu, Fan , month = nov, year =. Eigenvalue-corrected. doi:10.48550/arXiv.2011.13609 , publisher =
-
[34]
Estimating
Pruthi, Garima and Liu, Frederick and Kale, Satyen and Sundararajan, Mukund , year =. Estimating
-
[35]
Ilyas, Andrew and Park, Sung Min and Engstrom, Logan and Leclerc, Guillaume and Madry, Aleksander , month = feb, year =. Datamodels:. doi:10.48550/arXiv.2202.00622 , publisher =
-
[36]
Feldman, Vitaly and Zhang, Chiyuan , month = aug, year =. What. doi:10.48550/arXiv.2008.03703 , publisher =
-
[37]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, Joshua and Lee-Thorp, James and Jong, Michiel de and Zemlyanskiy, Yury and Lebrón, Federico and Sanghai, Sumit , month = dec, year =. doi:10.48550/arXiv.2305.13245 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.13245
-
[38]
doi:10.48550/arXiv.2402.14905 , publisher =
Liu, Zechun and Zhao, Changsheng and Iandola, Forrest and Lai, Chen and Tian, Yuandong and Fedorov, Igor and Xiong, Yunyang and Chang, Ernie and Shi, Yangyang and Krishnamoorthi, Raghuraman and Lai, Liangzhen and Chandra, Vikas , month = jun, year =. doi:10.48550/arXiv.2402.14905 , publisher =
-
[39]
Liu, Jiacheng and Blanton, Taylor and Elazar, Yanai and Min, Sewon and Chen, Yen-Sung and. 2025 , month = jul, pages =. doi:10.18653/v1/2025.acl-demo.18 , url =
-
[40]
Direct. Neuron , author =. 2020 , pages =. doi:10.1016/j.neuron.2019.12.002 , number =
-
[41]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author =
Martingale posterior distributions , volume =. Journal of the Royal Statistical Society Series B: Statistical Methodology , author =. 2024 , pages =. doi:10.1093/jrsssb/qkad005 , language =
-
[42]
Elsayed, Mohamed and Mahmood, A. Rupam , month = nov, year =. doi:10.48550/arXiv.2210.11639 , publisher =
-
[43]
Dangel, Felix and Eschenhagen, Runa and Ormaniec, Weronika and Fernandez, Andres and Tatzel, Lukas and Kristiadi, Agustinus , month = jan, year =. Position:. doi:10.48550/arXiv.2501.19183 , publisher =
-
[44]
Journal of the American Statistical Association , author=
The. Journal of the American Statistical Association , author =. 1974 , note =. doi:10.1080/01621459.1974.10482962 , number =
-
[45]
Journal of the American Statistical Association , author =
Influential. Journal of the American Statistical Association , author =. 1979 , note =. doi:10.2307/2286747 , number =
-
[46]
Xia, Mengzhou and Malladi, Sadhika and Gururangan, Suchin and Arora, Sanjeev and Chen, Danqi , year =
-
[47]
while my\_mcmc: gently(samples) -
Wiecki, Thomas , month = may, year =. while my\_mcmc: gently(samples) -
-
[48]
Is your batch size the problem?
Srećković, Teodora and Geiping, Jonas and Orvieto, Antonio , month = jun, year =. Is your batch size the problem?. doi:10.48550/arXiv.2506.12543 , publisher =
-
[49]
doi:10.48550/arXiv.2402.04333 , publisher =
Xia, Mengzhou and Malladi, Sadhika and Gururangan, Suchin and Arora, Sanjeev and Chen, Danqi , month = feb, year =. doi:10.48550/arXiv.2402.04333 , publisher =
-
[51]
and Hajishirzi, Hannaneh , year =
Xu, Hao and Liu, Jiacheng and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh , year =. Infini-gram mini:. doi:10.48550/ARXIV.2506.12229 , language =
-
[52]
Daxberger, Erik and Kristiadi, Agustinus and Immer, Alexander and Eschenhagen, Runa and Bauer, Matthias and Hennig, Philipp , month = mar, year =. Laplace. doi:10.48550/arXiv.2106.14806 , publisher =
-
[53]
Benzing, Frederik , month = jun, year =. Gradient. doi:10.48550/arXiv.2201.12250 , publisher =
-
[54]
Pick-to-
Marks, Daniel and Paccagnan, Dario , month = feb, year =. Pick-to-
-
[55]
Khan, Mohammad Emtiyaz , month = jun, year =. Knowledge. doi:10.48550/arXiv.2506.14262 , publisher =
-
[56]
New insights and perspectives on the natural gradient method , url =
Martens, James , month = sep, year =. New insights and perspectives on the natural gradient method , url =. doi:10.48550/arXiv.1412.1193 , publisher =
-
[57]
Koh, Pang Wei W and Ang, Kai-Siang and Teo, Hubert and Liang, Percy S , year =. On the
-
[58]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timothée and Rozière, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume , month = feb, year =. doi:10.48550/arXiv.2302.13971 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971
-
[59]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2005
-
[60]
Penedo, Guilherme and Kydlíček, Hynek and allal, Loubna Ben and Lozhkov, Anton and Mitchell, Margaret and Raffel, Colin and Werra, Leandro Von and Wolf, Thomas , month = oct, year =. The. doi:10.48550/arXiv.2406.17557 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.17557
-
[61]
Sun, Weiwei and Liu, Haokun and Kandpal, Nikhil and Raffel, Colin and Yang, Yiming , month = may, year =. Enhancing. doi:10.48550/arXiv.2505.18513 , publisher =
-
[62]
Did the neurons read your book? document-level membership inference for large language models , url =
Meeus, Matthieu and Jain, Shubham and Rei, Marek and de Montjoye, Yves-Alexandre , year =. Did the neurons read your book? document-level membership inference for large language models , url =. 33rd
-
[63]
Carlini, Nicholas and Chien, Steve and Nasr, Milad and Song, Shuang and Terzis, Andreas and Tramer, Florian , month = apr, year =. Membership. doi:10.48550/arXiv.2112.03570 , publisher =
-
[64]
Singla, Vasu and Sandoval-Segura, Pedro and Goldblum, Micah and Geiping, Jonas and Goldstein, Tom , month = nov, year =. A. doi:10.48550/arXiv.2311.03386 , publisher =
-
[65]
Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan , month = aug, year =. Towards. doi:10.48550/arXiv.2308.03281 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.03281
-
[66]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke , editor =. 2017 , pages =. doi:10.18653/v1/P17-1147 , booktitle = acl, publisher =
-
[67]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , month = oct, year =. doi:10.48550/arXiv.1606.05250 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.05250
-
[68]
Rajpurkar, Pranav and Jia, Robin and Liang, Percy , month = jun, year =. Know. doi:10.48550/arXiv.1806.03822 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.03822
-
[69]
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
Longpre, Shayne and Hou, Le and Vu, Tu and Webson, Albert and Chung, Hyung Won and Tay, Yi and Zhou, Denny and Le, Quoc V. and Zoph, Barret and Wei, Jason and Roberts, Adam , month = feb, year =. The. doi:10.48550/arXiv.2301.13688 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2301.13688
-
[70]
and Rajagopal, Dheeraj and Bolukbasi, Tolga and Dixon, Lucas and Tenney, Ian , year =
Chang, Tyler A. and Rajagopal, Dheeraj and Bolukbasi, Tolga and Dixon, Lucas and Tenney, Ian , year =. Scalable
-
[71]
Towards a Science of AI Evaluations,
Rethinking Machine Unlearning for Large Language Models , author =. 2025 , month = feb, journal =. doi:10.1038/s42256-025-00985-0 , url =
-
[72]
Wuhrmann, Arthur and Kucherenko, Anastasiia and Kucharavy, Andrei , year =. Low-. doi:10.48550/arXiv.2507.01844 , archiveprefix =. 2507.01844 , primaryclass =
-
[73]
Robertson, Stephen and Zaragoza, Hugo , year =. The. Foundations and Trends. doi:10.1561/1500000019 , url =
-
[74]
2024 , month = dec, journal = nips, volume =
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and Bansal, Hritik and Guha, Etash and Keh, Sedrick and Arora, Kushal and Garg, Saurabh and Xin, Rui and Muennighoff, Niklas and Heckel, Reinhard and Mercat, Jean and Chen, Mayee and Gururangan, Suchin and Wortsman, Mitchell and Albalak, Alon and Bitton, Yona...
2024
-
[75]
Infini-Gram:
Liu, Jiacheng and Min, Sewon and Zettlemoyer, Luke and Choi, Yejin and Hajishirzi, Hannaneh , year =. Infini-Gram:. First
-
[76]
Jaeckel, Louis A , year =. The
-
[77]
Understanding
Koh, Pang Wei and Liang, Percy , booktitle = icml, year =. Understanding
-
[78]
Dennis and Weisberg, Sanford , year =
Cook, R. Dennis and Weisberg, Sanford , year =. Characterizations of an. Technometrics , volume =. doi:10.1080/00401706.1980.10486199 , url =
-
[79]
Han, Xiaochuang and Wallace, Byron C. and Tsvetkov, Yulia. Explaining Black Box Predictions and Unveiling Data Artifacts through Influence Functions. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.492
-
[80]
Towards Tracing Knowledge in Language Models Back to the Training Data
Akyurek, Ekin and Bolukbasi, Tolga and Liu, Frederick and Xiong, Binbin and Tenney, Ian and Andreas, Jacob and Guu, Kelvin. Towards Tracing Knowledge in Language Models Back to the Training Data. 2022. doi:10.18653/v1/2022.findings-emnlp.180
-
[81]
F ast IF : Scalable Influence Functions for Efficient Model Interpretation and Debugging
Guo, Han and Rajani, Nazneen and Hase, Peter and Bansal, Mohit and Xiong, Caiming. F ast IF : Scalable Influence Functions for Efficient Model Interpretation and Debugging. 2021. doi:10.18653/v1/2021.emnlp-main.808
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.