DiT-Reward: Generative Representations for Text-to-Image Reward Modeling
Pith reviewed 2026-06-26 08:33 UTC · model grok-4.3
The pith
Converting pretrained Diffusion Transformers into reward models by processing near-clean latents outperforms HPSv3 on all four evaluated preference benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
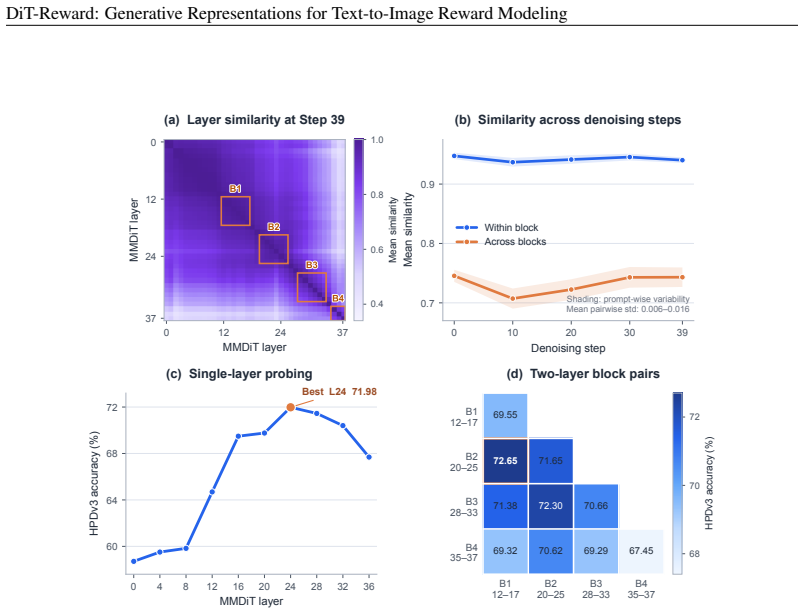
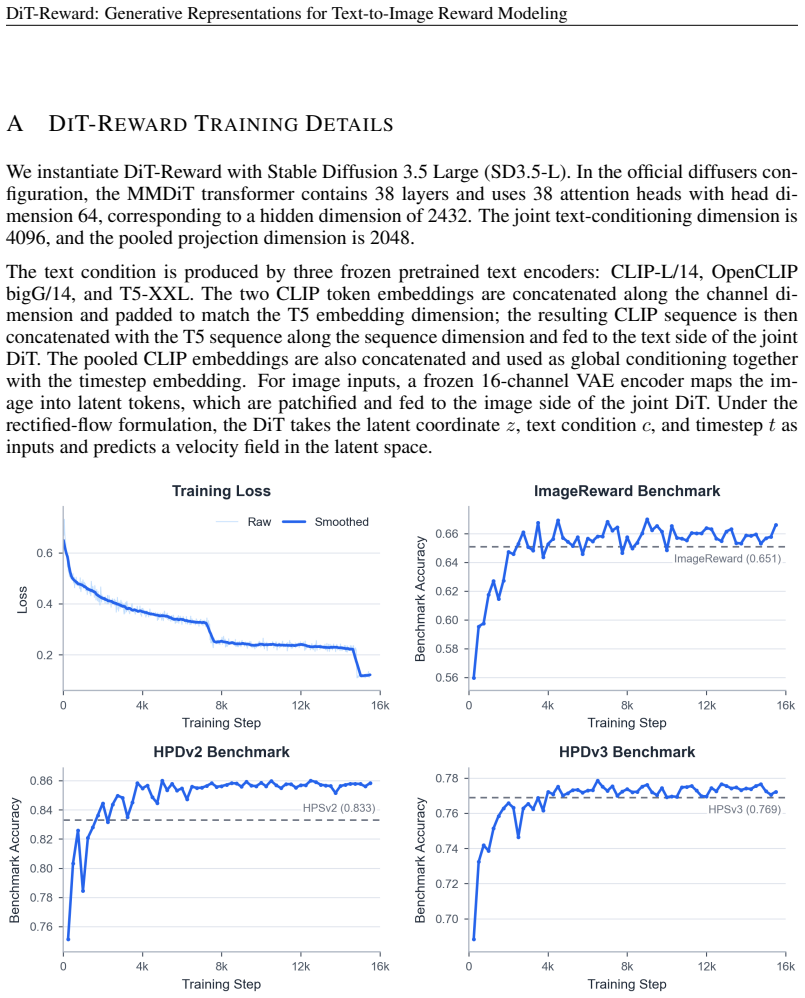
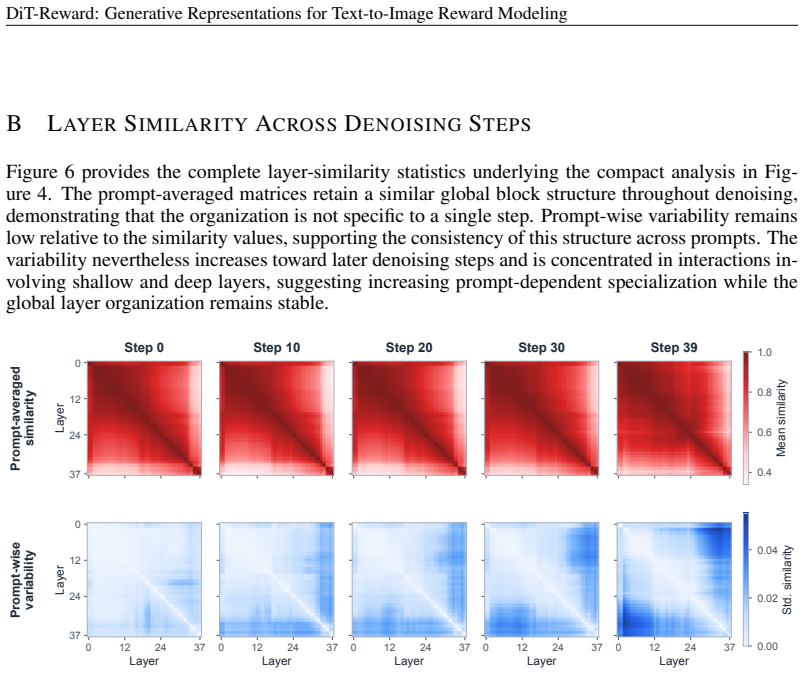
DiT-Reward converts a pretrained text-to-image Diffusion Transformer into a reward model by processing near-clean image latents and aggregating text-conditioned image representations across transformer layers. Under the same training data mixture as HPSv3, DiT-Reward outperforms HPSv3 on all four evaluated preference benchmarks, reaching 85.6% on HPDv2 and 77.6% on HPDv3. When the generative backbone is frozen, a lightweight learned head can still extract meaningful preference predictions from its representations. Probing across depth further reveals that downstream reward performance is strongest in the middle-to-late layers and benefits from combining representations across different stage
What carries the argument
Aggregation of text-conditioned image representations across transformer layers from near-clean latents in a pretrained Diffusion Transformer, used to produce preference scores.
If this is right
- Outperforms HPSv3 on HPDv2 at 85.6% and HPDv3 at 77.6% under matched training data.
- A lightweight learned head suffices when the generative backbone stays frozen.
- Reward performance peaks when representations from middle-to-late layers are combined.
- Larger generative backbones produce stronger downstream reward signals.
- Direct latent scoring yields 1.65x faster inference than HPSv3 at comparable memory cost.
Where Pith is reading between the lines
- The same generative pretraining that produces images may already embed signals useful for judging image quality.
- Reward models could be derived from any sufficiently large pretrained diffusion backbone without separate generative training.
- Policy optimization loops that already run diffusion models could reuse internal activations for reward computation.
- Scaling trends observed here suggest further gains if future generative models continue to grow in capacity.
Load-bearing premise
Representations learned for image generation remain sufficiently aligned with human preference signals when the backbone is applied to near-clean latents without retraining the core generative weights.
What would settle it
An experiment that trains DiT-Reward and HPSv3 on identical data mixtures and finds DiT-Reward scoring no higher than 80% on HPDv2 or 72% on HPDv3 would falsify the claim of superior transferable representations.
Figures



read the original abstract
Can representations learned for image generation also support the evaluation of generated images? We study text-to-image reward prediction as a downstream task of generative representation learning. To this end, we introduce DiT-Reward, which converts a pretrained text-to-image Diffusion Transformer into a reward model by processing near-clean image latents and aggregating text-conditioned image representations across transformer layers. Under the same training data mixture as HPSv3, DiT-Reward outperforms HPSv3 on all four evaluated preference benchmarks, reaching 85.6% on HPDv2 and 77.6% on HPDv3. When the generative backbone is frozen, a lightweight learned head can still extract meaningful preference predictions from its representations. Probing across depth further reveals that downstream reward performance is strongest in the middle-to-late layers and benefits from combining representations across different stages. We also observe consistent positive scaling with generative backbone capacity. Finally, when used to optimize Stable Diffusion 3.5 Large with Flow-GRPO, DiT-Reward outperforms HPSv3 along the matched training trajectory, with particularly clear gains in realism. Direct latent scoring also achieves a 1.65x inference speedup over HPSv3 with comparable peak memory. These results show that pretrained generative DiTs provide transferable representations for reward modeling and policy optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
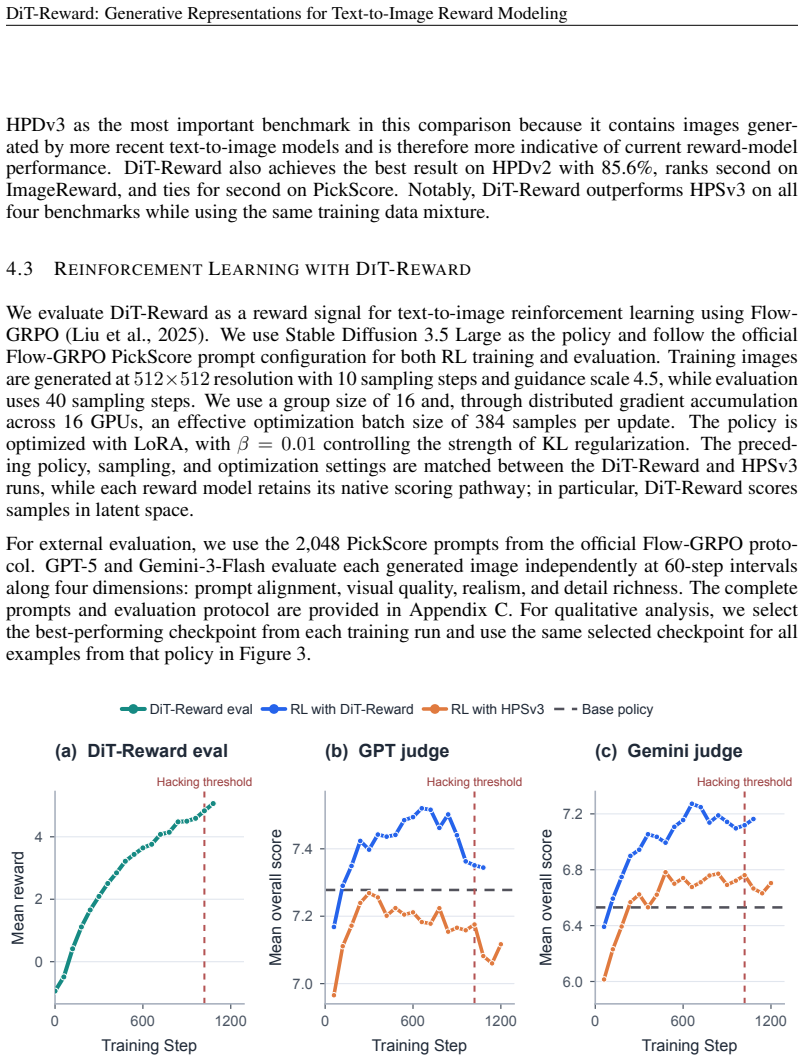
Summary. The paper introduces DiT-Reward, which repurposes a pretrained text-to-image Diffusion Transformer as a reward model by feeding near-clean image latents and aggregating text-conditioned representations across transformer layers. Under matched training data with HPSv3, it reports outperformance on four preference benchmarks (e.g., 85.6% on HPDv2, 77.6% on HPDv3), positive scaling with generative backbone capacity, stronger performance from middle-to-late layers, and improved results when optimizing Stable Diffusion 3.5 Large via Flow-GRPO, plus a 1.65x inference speedup from direct latent scoring.
Significance. If the empirical results hold, the work demonstrates that frozen generative DiT representations can transfer effectively to preference prediction and policy optimization without retraining the core weights. The matched-data comparison, layer-wise probing, capacity scaling, and downstream optimization gains provide concrete evidence for the utility of generative pretraining in reward modeling, which could reduce the cost of building reward models for text-to-image systems.
major comments (1)
- [Abstract / experimental results] Abstract and experimental results: The reported benchmark accuracies (85.6% on HPDv2, 77.6% on HPDv3 and similar for the other two) are presented without error bars, standard deviations across runs, or explicit confirmation that the training mixture, optimizer, and evaluation protocol match those of HPSv3 exactly; this information is load-bearing for the central claim of consistent outperformance.
minor comments (2)
- [Abstract] The abstract refers to 'all four evaluated preference benchmarks' without naming them; the main text should list the exact benchmarks (HPDv2, HPDv3, and the remaining two) at first mention.
- [Methods] The description of aggregating representations across layers would benefit from an explicit equation or pseudocode in the methods section to clarify the aggregation operator and which layers are combined.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our experimental claims. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract and experimental results: The reported benchmark accuracies (85.6% on HPDv2, 77.6% on HPDv3 and similar for the other two) are presented without error bars, standard deviations across runs, or explicit confirmation that the training mixture, optimizer, and evaluation protocol match those of HPSv3 exactly; this information is load-bearing for the central claim of consistent outperformance.
Authors: We agree that explicit confirmation and variability reporting would strengthen the central claim. In the revised manuscript we will insert a new paragraph in Section 4 (Experimental Setup) that explicitly states the training data mixture, optimizer settings (including learning rate, batch size, and scheduler), number of training steps, and evaluation protocol are identical to those used for HPSv3, with direct citations to the HPSv3 paper and code repository. Regarding error bars, all reported numbers are from single training runs; the substantial compute required for large-scale preference tuning precluded multiple random seeds. We will add a clarifying sentence in the results section noting this limitation while highlighting that outperformance holds consistently across four independent benchmarks. We view this as a partial revision because we can fully address the matching-protocol concern but cannot retroactively supply standard deviations without new experiments. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's central claims consist of empirical performance comparisons on external preference benchmarks (HPDv2, HPDv3, etc.) under matched training data with HPSv3, plus observational results on layer probing, scaling with backbone capacity, and downstream optimization gains. The method freezes the generative backbone and trains only a lightweight head on near-clean latents, with all reported metrics derived from direct evaluation rather than any internal derivation, prediction, or self-referential fitting that reduces to the paper's own inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify the core results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xu, Jiazheng and Liu, Xiao and Wu, Yuchen and Tong, Yuxuan and Li, Qinkai and Ding, Ming and Tang, Jie and Dong, Yuxiao , booktitle=
-
[2]
Advances in Neural Information Processing Systems , year=
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , author=. Advances in Neural Information Processing Systems , year=
-
[3]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Human Preference Score: Better Aligning Text-to-Image Models with Human Preference , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[5]
Ma, Yuhang and Shui, Yunhao and Wu, Xiaoshi and Sun, Keqiang and Li, Hongsheng , booktitle=
-
[6]
Xu, Jiazheng and Huang, Yu and Cheng, Jiale and Yang, Yuanming and Xu, Jiajun and Wang, Yuan and Duan, Wenbo and Yang, Shen and Jin, Qunlin and Li, Shurun and Teng, Jiayan and Yang, Zhuoyi and Zheng, Wendi and Liu, Xiao and Zhang, Dan and Ding, Ming and Zhang, Xiaohan and Huang, Shiyu and Gu, Xiaotao and Huang, Minlie and Tang, Jie and Dong, Yuxiao , booktitle=
-
[7]
He, Xuan and Jiang, Dongfu and Zhang, Ge and Ku, Max and Soni, Achint and Siu, Sherman and Chen, Haonan and Chandra, Abhranil and Jiang, Ziyan and Arulraj, Aaran and Wang, Kai and Do, Quy Duc and Ni, Yuansheng and Lyu, Bohan and Narsupalli, Yaswanth and Fan, Rongqi and Lyu, Zhiheng and Lin, Bill Yuchen and Chen, Wenhu , booktitle=
-
[8]
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and others , booktitle=
-
[9]
Wang, Yaohui and Chen, Xinyuan and Ma, Xin and Zhou, Shangchen and Huang, Ziqi and Wang, Yi and Yang, Ceyuan and He, Yinan and Yu, Jiashuo and Yang, Peiqing and others , booktitle=
-
[10]
Li, Baiqi and Lin, Zhiqiu and Pathak, Deepak and Li, Jiayao and Fei, Yixin and Wu, Kewen and Ling, Tiffany and Xia, Xide and Zhang, Pengchuan and Neubig, Graham and Ramanan, Deva , journal=
-
[11]
, booktitle=
Hu, Yushi and Liu, Benlin and Kasai, Jungo and Wang, Yizhong and Ostendorf, Mari and Krishna, Ranjay and Smith, Noah A. , booktitle=
-
[12]
Li, Linjie and Gan, Zhe and Lin, Kevin and Lin, Chung-Ching and Liu, Zicheng and Liu, Ce and Wang, Lijuan , journal=
-
[13]
Huang, Kaiyi and Sun, Kaiyue and Xie, Enze and Li, Zhenguo and Liu, Xihui , booktitle=
-
[14]
Advances in Neural Information Processing Systems , volume=
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Transactions on Machine Learning Research , year=
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation , author=. Transactions on Machine Learning Research , year=
-
[16]
Hessel, Jack and Holtzman, Ari and Forbes, Maxwell and Bras, Ronan Le and Choi, Yejin , booktitle=
-
[17]
International Conference on Machine Learning , pages=
Learning Transferable Visual Models From Natural Language Supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[18]
2022 , organization=
Li, Junnan and Li, Dongxu and Xiong, Caiming and Hoi, Steven , booktitle=. 2022 , organization=
2022
-
[19]
2023 , organization=
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle=. 2023 , organization=
2023
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning Multi-Dimensional Human Preference for Text-to-Image Generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
Advances in Neural Information Processing Systems , volume=
Visual Instruction Tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Bai, Jinze and Bai, Shuai and Chu, Yunfei and Cui, Zeyu and Dang, Kai and Deng, Xiaodong and Fan, Yang and Ge, Wenbin and Han, Yu and Huang, Fei and others , journal=
-
[23]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A Family of Highly Capable Multimodal Models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
International Conference on Learning Representations , year=
Training Diffusion Models with Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[25]
Fan, Ying and Watkins, Olivia and Du, Yuqing and Liu, Hao and Ryu, Moonkyung and Boutilier, Craig and Abbeel, Pieter and Ghavamzadeh, Mohammad and Lee, Kangwook and Lee, Kimin , booktitle=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Diffusion Model Alignment Using Direct Preference Optimization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[27]
Liu, Jie and Liu, Gongye and Liang, Jiajun and Li, Yangguang and Liu, Jiaheng and Wang, Xintao and Wan, Pengfei and Zhang, Di and Ouyang, Wanli , booktitle=. Flow-
-
[29]
ACM Transactions on Graphics , volume=
Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models , author=. ACM Transactions on Graphics , volume=
-
[30]
European Conference on Computer Vision , pages=
Compositional Visual Generation with Composable Diffusion Models , author=. European Conference on Computer Vision , pages=
-
[31]
Mou, Chong and Wang, Xintao and Xie, Liangbin and Wu, Yanze and Zhang, Jian and Qi, Zhongang and Shan, Ying and Qie, Xiaohu , booktitle=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Adding Conditional Control to Text-to-Image Diffusion Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Multi-Concept Customization of Text-to-Image Diffusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
Learning Profitable
He, Huiguo and Wang, Tianfu and Yang, Huan and Fu, Jianlong and Yuan, Nicholas Jing and Yin, Jian and Chao, Hongyang and Zhang, Qi , booktitle=. Learning Profitable
-
[35]
Wu, Jie and Gao, Yu and Ye, Zilyu and Li, Ming and Li, Liang and Guo, Hanzhong and Liu, Jie and Xue, Zeyue and Hou, Xiaoxia and Liu, Wei and Zeng, Yan and Huang, Weilin , journal=
-
[36]
, booktitle=
Zhu, Huaisheng and Xiao, Teng and Honavar, Vasant G. , booktitle=
-
[37]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Scalable Ranked Preference Optimization for Text-to-Image Generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[38]
Transactions on Machine Learning Research , year=
A Simple and Effective Reinforcement Learning Method for Text-to-Image Diffusion Fine-Tuning , author=. Transactions on Machine Learning Research , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A
Lambert, Nathan and Pyatkin, Valentina and Morrison, Jacob and Miranda, Lester James V. and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh , booktitle=
-
[42]
Advances in Neural Information Processing Systems , volume=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
Learning to Summarize with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Fine-Tuning Language Models from Human Preferences
Fine-Tuning Language Models from Human Preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[45]
arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Constitutional
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and others , journal=. Constitutional
-
[51]
Lee, Harrison and Phatale, Samrat and Mansoor, Hassan and Lu, Kellie Ren and Mesnard, Thomas and Bishop, Colton and Carbune, Victor and Rastogi, Abhinav and Prakash, Sushant , journal=
-
[52]
Advances in Neural Information Processing Systems , volume=
Emergent Correspondence from Image Diffusion , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Advances in Neural Information Processing Systems , volume=
Unsupervised Semantic Correspondence Using Stable Diffusion , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
European Conference on Computer Vision , year=
Three Things We Need to Know About Transferring Stable Diffusion to Visual Dense Prediction Tasks , author=. European Conference on Computer Vision , year=
-
[55]
Stracke, Nick and Baumann, Stefan Andreas and Bauer, Kolja and Fundel, Frank and Ommer, Bjorn , booktitle=
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[57]
Transactions on Machine Learning Research , year=
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research , year=
-
[58]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Emerging Properties in Self-Supervised Vision Transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[61]
International Conference on Learning Representations , year=
An Image is Worth One Word: Personalizing Text-to-Image Generation Using Textual Inversion , author=. International Conference on Learning Representations , year=
-
[62]
Advances in Neural Information Processing Systems , volume=
Elucidating the Design Space of Diffusion-Based Generative Models , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
Classifier-Free Diffusion Guidance
Classifier-Free Diffusion Guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Null-Text Inversion for Editing Real Images Using Guided Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[65]
International Conference on Learning Representations , year=
Prompt-to-Prompt Image Editing with Cross Attention Control , author=. International Conference on Learning Representations , year=
-
[66]
Advances in Neural Information Processing Systems , volume=
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
International Conference on Learning Representations , year=
Diffusion Models Already Have a Semantic Latent Space , author=. International Conference on Learning Representations , year=
-
[68]
arXiv preprint arXiv:2601.16208 , year=
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders , author=. arXiv preprint arXiv:2601.16208 , year=
-
[69]
International Conference on Machine Learning , pages=
Deep Unsupervised Learning Using Nonequilibrium Thermodynamics , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[70]
Advances in Neural Information Processing Systems , volume=
Generative Modeling by Estimating Gradients of the Data Distribution , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Advances in Neural Information Processing Systems , volume=
Denoising Diffusion Probabilistic Models , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
International Conference on Learning Representations , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations , year=
-
[73]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[74]
Diffusion Models Beat
Dhariwal, Prafulla and Nichol, Alexander Quinn , booktitle=. Diffusion Models Beat
-
[75]
2022 , organization=
Nichol, Alex and Dhariwal, Prafulla and Ramesh, Aditya and Shyam, Pranav and Mishkin, Pamela and McGrew, Bob and Sutskever, Ilya and Chen, Mark , booktitle=. 2022 , organization=
2022
-
[76]
Hierarchical Text-Conditional Image Generation with
Ramesh, Aditya and Dhariwal, Prafulla and Nichol, Alex and Chu, Casey and Chen, Mark , journal=. Hierarchical Text-Conditional Image Generation with
-
[78]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Scalable Diffusion Models with Transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[79]
All Are Worth Words: A
Bao, Fan and Nie, Shen and Xue, Kaiwen and Cao, Yue and Li, Chongxuan and Su, Hang and Zhu, Jun , booktitle=. All Are Worth Words: A
-
[80]
International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. International Conference on Learning Representations , year=
-
[81]
International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. International Conference on Learning Representations , year=
-
[82]
and Boffi, Nicholas M
Ma, Nanye and Goldstein, Mark and Albergo, Michael S. and Boffi, Nicholas M. and Vanden-Eijnden, Eric and Xie, Saining , booktitle=
-
[83]
International Conference on Machine Learning , year=
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author=. International Conference on Machine Learning , year=
-
[84]
Introducing Stable Diffusion 3.5 , author=
-
[85]
International Conference on Learning Representations , year=
PixArt- : Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis , author=. International Conference on Learning Representations , year=
-
[86]
European Conference on Computer Vision , year=
PixArt- : Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation , author=. European Conference on Computer Vision , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.