AI Exposure Scores: what they measure, what they miss, and what comes next
Pith reviewed 2026-06-26 08:15 UTC · model grok-4.3
The pith
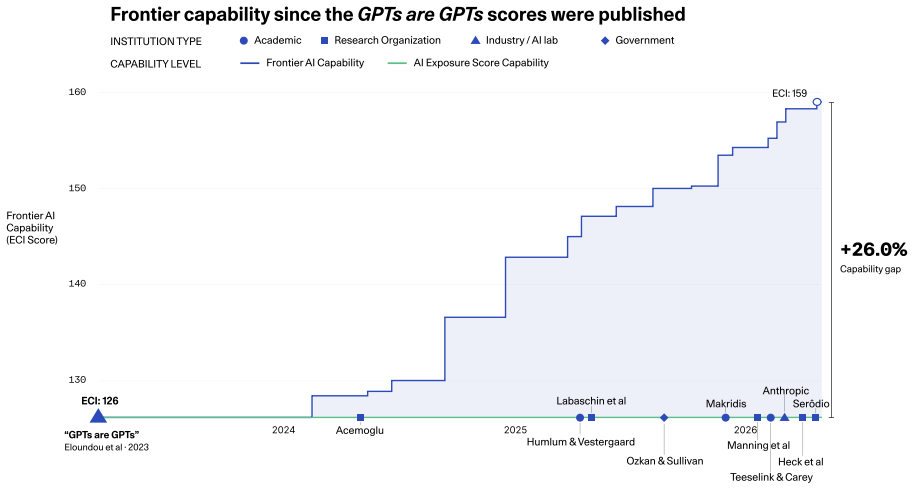
Static 2023 AI exposure scores continue to inform policy on job impacts even as their built-in limits on time, place, and task definitions spread into those analyses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Exposure scores define exposure as the share of occupational tasks a large language model can assist with. As these static scores travel from their 2023 production context into policy analyses, their temporal, geographic, and ontological limitations compound, creating a structural mismatch with policy questions and a coordination gap in which policy-relevant work continues to reference the original scores without engaging methodological updates that would answer those questions more reliably.
What carries the argument
The GPTs are GPTs exposure scores, which calculate the share of tasks assistable by LLMs, and the pattern of their diffusion into policy analyses without the original limitations attached.
If this is right
- Dynamic and benchmark-based measures can address the temporal mismatch between fixed 2023 scores and changing model capabilities.
- Ensemble methods and task-framework extensions can reduce the ontological limits of single-model task-share calculations.
- Worker-centered metrics and adoption-usage data can bring geographic and real-world diffusion factors into exposure estimates.
- Policymakers must widen their evidence base beyond static scores, engage workers as epistemic partners, and move from prediction to preparedness.
- Researchers must build data infrastructure, adopt participatory methods, and write outputs that policymakers can directly use.
Where Pith is reading between the lines
- If policy papers continue citing the static scores at the current rate, the coordination gap will keep producing analyses that treat exposure as fixed rather than conditional on adoption speed and local labor markets.
- One testable extension is to track whether newer dynamic measures appear in the same policy venues that still rely on the 2023 scores and whether that changes the conclusions drawn about specific occupations.
- The call for ex-post frameworks suggests that retrospective evaluation of earlier exposure predictions against actual employment data could become a standing requirement for future policy use of any AI impact metric.
Load-bearing premise
That the original limitations named by Eloundou et al. (2023) are not traveling with the scores as they diffuse into policy-facing analyses.
What would settle it
A systematic count, across recent policy reports and papers that cite the 2023 scores, of how many note the temporal, geographic, or task-definition limits or reference any of the five families of updated measures.
Figures


read the original abstract
A set of exposure scores calculated in 2023 has become a central empirical input to the future of work debate. Produced by Eloundou et al. (2023) and referred to here as the GPTs are GPTs scores, they define exposure as the share of occupational tasks a large language model can assist with. This work is a genuine methodological contribution, but as the scores travel from the time and place they were produced, the limitations the authors named do not always travel with them. Two gaps have widened as a result. The first is structural, between what static exposure scores measure and what policy questions actually require. Taking the diffusion of these scores as a case study, we show how their temporal, geographic, and ontological limitations compound in policy-facing analyses, and we survey five families of research responding to these limits: dynamic and benchmark-based measures, ensemble methods, task-framework extensions, worker-centered metrics, and adoption and usage data. The second gap is the one we argue needs more attention: the coordination between researchers and policymakers. The policy-relevant work which ask who is harmed, who benefits, how, and when, continues to reference the static GPTs are GPTs scores without engagement with the methodological updates that would let these questions be answered more reliably. We then ask what additional steps towards navigating uncertainty remain: ex-post frameworks and the deliberate, political work of reimagining what futures are worthy of building towards are. Closing the research-policy gap is a shared task: policymakers must widen their evidence base, engage workers as epistemic partners, and shift from prediction to preparedness; researchers must build data infrastructure, adopt participatory methods, and write with policymakers in mind. Better measurement matters, but it will not close the second gap alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the 2023 GPTs-are-GPTs exposure scores from Eloundou et al. have become central to future-of-work debates but that their named limitations (temporal, geographic, ontological) do not always accompany the scores as they diffuse into policy analyses. It identifies a structural gap between what static scores measure and what policy questions require, surveys five families of responding research (dynamic/benchmark-based measures, ensemble methods, task-framework extensions, worker-centered metrics, adoption/usage data), and argues for greater attention to a second gap in researcher-policymaker coordination. The manuscript concludes that policy work still relies on the static scores without engaging updates, and calls for ex-post frameworks, participatory methods, data infrastructure, and a shift from prediction to preparedness.
Significance. If the observations on diffusion and non-engagement hold, the paper would usefully surface how methodological limitations in AI exposure metrics can propagate into policy contexts and would usefully catalog families of corrective research. Its emphasis on coordination gaps and concrete recommendations for both researchers and policymakers could help orient future work toward more reliable inputs for questions of harm, benefit, timing, and distribution. The contribution is primarily synthetic and normative rather than empirical.
major comments (2)
- [Abstract] Abstract and central argument: the claim that 'the policy-relevant work which ask who is harmed, who benefits, how, and when, continues to reference the static GPTs are GPTs scores without engagement with the methodological updates' is treated as observable from usage patterns, yet the manuscript supplies no systematic citation analysis, usage statistics, or quantified diffusion evidence to establish the frequency or persistence of non-engagement. This assertion is load-bearing for the coordination-gap diagnosis.
- [Abstract] Abstract: the statement that 'we show how their temporal, geographic, and ontological limitations compound in policy-facing analyses' is presented without the systematic evidence, data, or detailed case studies that would substantiate the compounding effect; the soundness assessment notes the absence of such support.
minor comments (1)
- The five families of research are introduced at a high level; adding one or two concrete examples or citations per family would improve clarity without altering the qualitative character of the survey.
Simulated Author's Rebuttal
We thank the referee for these precise observations on the abstract. The manuscript is a synthetic review that draws on observed patterns in the literature rather than original empirical quantification of diffusion or compounding effects. We agree that the current phrasing overstates the evidentiary basis and will revise the abstract and related claims to reflect this more accurately.
read point-by-point responses
-
Referee: [Abstract] Abstract and central argument: the claim that 'the policy-relevant work which ask who is harmed, who benefits, how, and when, continues to reference the static GPTs are GPTs scores without engagement with the methodological updates' is treated as observable from usage patterns, yet the manuscript supplies no systematic citation analysis, usage statistics, or quantified diffusion evidence to establish the frequency or persistence of non-engagement. This assertion is load-bearing for the coordination-gap diagnosis.
Authors: We accept this critique. The manuscript presents the non-engagement pattern as an observed trend supported by illustrative references rather than a quantified analysis. We will revise the abstract to describe it as an observed pattern in policy-relevant work and add a sentence noting that systematic citation studies would be valuable future work. This adjustment preserves the coordination-gap argument while making its evidentiary status explicit. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'we show how their temporal, geographic, and ontological limitations compound in policy-facing analyses' is presented without the systematic evidence, data, or detailed case studies that would substantiate the compounding effect; the soundness assessment notes the absence of such support.
Authors: We agree that the verb 'show' implies a stronger evidentiary claim than the manuscript delivers. The text illustrates the compounding through examples drawn from existing policy analyses and the surveyed research families, but does not contain original systematic data or case studies. We will change the abstract language to 'illustrate' or 'discuss' and ensure the body text clarifies the synthetic basis of this section. revision: yes
Circularity Check
No circularity: qualitative survey with no derivations or self-referential reductions
full rationale
The paper is a qualitative survey and critique of AI exposure scores. It contains no equations, fitted parameters, derivations, or quantitative predictions. The central claim about persistent non-engagement in policy work is an observational argument about diffusion patterns and does not reduce to any self-definition, fitted input renamed as prediction, or load-bearing self-citation chain. No uniqueness theorems, ansatzes, or renamings of known results are invoked in a circular manner. The paper is self-contained as an argumentative review against external benchmarks of usage.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ISSN 2574-0768. doi: 10.1257/pandp.20181019. Erik Brynjolfsson, Daniel Rock, and Chad Syverson. The Productivity J-Curve: How Intangibles Complement General Purpose Technologies. American Economic Journal: Macroeconomics , 13 (1):333–372, January
-
[2]
ISSN 1945-7707. doi: 10.1257/mac.20180386. Mariarosaria Comunale and Andrea Manera. The Economic Impacts and the Regulation of AI: A Review of the Academic Literature and Policy Actions, March
-
[3]
Tyna Eloundou, Sam Manning, Pamela Mishkin, and Daniel Rock
doi: 10.5281/zenodo.17382120. Tyna Eloundou, Sam Manning, Pamela Mishkin, and Daniel Rock. GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models, August
-
[4]
ISSN 2574-0768. doi: 10.1257/pandp.20181021. Francesco Filippucci, Peter Gal, Katharina Laengle, and Matthias Schief. Macroeconomic produc- tivity gains from Artificial Intelligence in G7 economies. OECD Artificial Intelligence Papers , June
-
[5]
15 Morgan R Frank, Yong-Yeol Ahn, and Esteban Moro
doi: 10.1787/a5319ab5-en. 15 Morgan R Frank, Yong-Yeol Ahn, and Esteban Moro. AI exposure predicts unemployment risk: A new approach to technology-driven job loss. PNAS Nexus , 4(4):pgaf107, April
-
[6]
doi: 10.1093/pnasnexus/pgaf107
ISSN 2752-6542. doi: 10.1093/pnasnexus/pgaf107. Carl Benedikt Frey and Michael A. Osborne. The future of employment: How susceptible are jobs to computerisation? Technological Forecasting and Social Change , 114:254–280, January
-
[7]
doi: 10.1016/j.techfore.2016.08.019
ISSN 0040-1625. doi: 10.1016/j.techfore.2016.08.019. Justin Heck, Mark Muro, Shriya Methkupally, and Joseph Siegmund. How AI may reshape ca- reer pathways to better jobs. https://www.brookings.edu/articles/how-ai-may-reshape-career- pathways-to-better-jobs/, February
-
[8]
doi: 10.1257/pandp.20251045. Benjamin Lange, Geoff Keeling, Kyle Pedersen, Carmen Heringer, Susan B. Rubin, Ben Zevenbergen, and Amanda McCroskery. Epistemic Trust as a Mechanism for Ethics In- tegration: Failure Modes and Design Principles from 70 Moral Imagination Workshops. https://arxiv.org/abs/2604.11281v1, April
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1257/pandp.20251045
-
[9]
Economic Measurement Research Institute
National Bureau of Economic Research. Economic Measurement Research Institute. https://www.nber.org/emri. National Center for O*NET Development. O*NET OnLine. www.onetonline.org/. Serdar Ozkan and Nicholas Sullivan. Is AI Contributing to Rising Unemployment? Evi- dence from Occupational Variation. https://www.stlouisfed.org/on-the-economy/2025/aug/is- ai-...
2025
-
[10]
America Isn’t Ready for What AI Will Do to Jobs
Josh Tyrangiel. America Isn’t Ready for What AI Will Do to Jobs. https://www.theatlantic.com/magazine/2026/03/ai-economy-labor-market- transformation/685731/, February
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.