Legal Reasoning Is Not Lawyering: Rethinking Legal Benchmarks for Pro Se Access to Justice
Pith reviewed 2026-06-26 22:24 UTC · model grok-4.3
The pith
Legal AI benchmarks measure performance only on expert-preprocessed inputs rather than the raw prompts typical of people without lawyers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
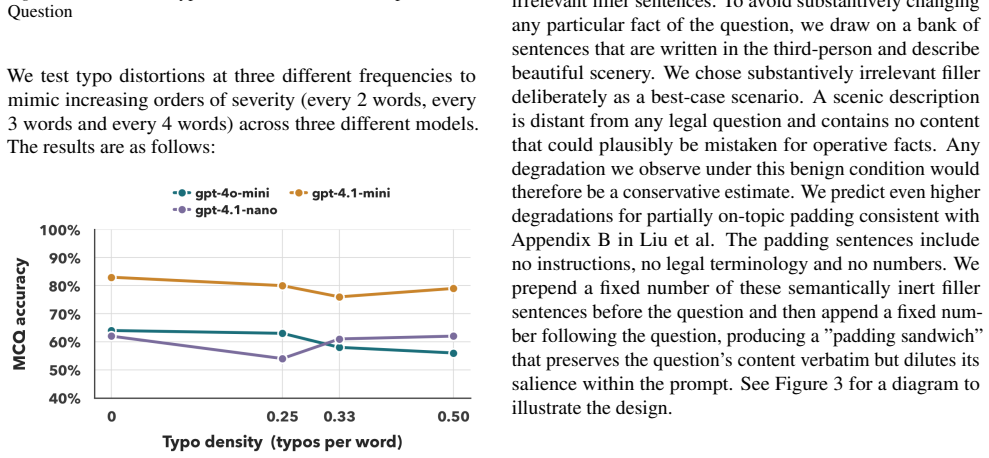
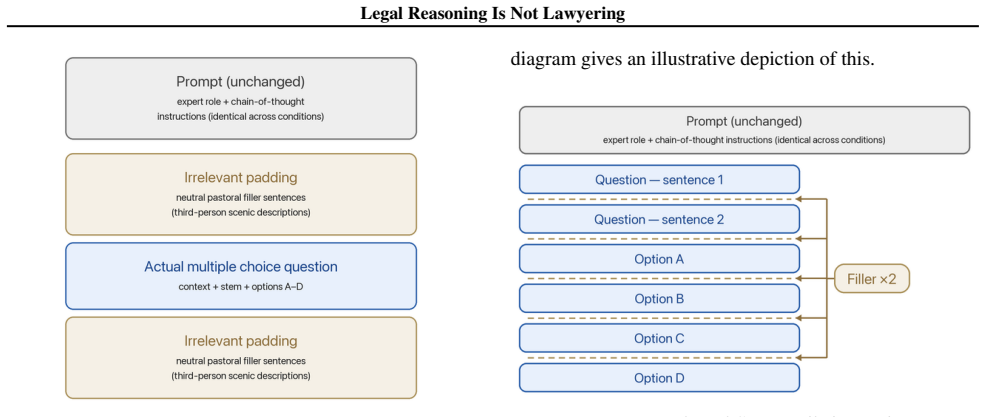
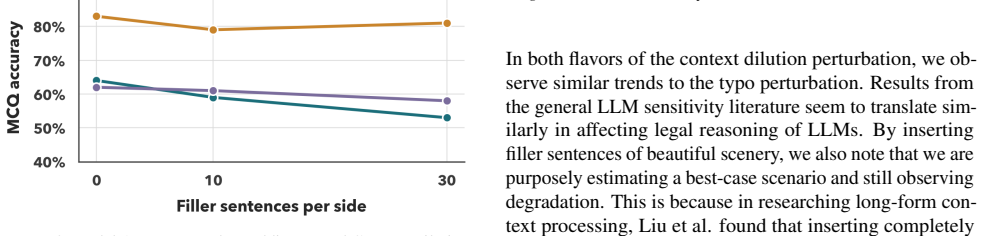
Benchmarks that evaluate legal reasoning on inputs preprocessed by legal experts measure only the upper bound of model performance, whereas access to justice for pro se litigants depends on the lower bound of performance under inputs containing noisy narratives, buried facts, omissions, folk-legal assumptions, and surface-level errors; these conditions align with known LLM degradation factors such as long-context sensitivity, underspecification, hallucination, and typographical perturbations, as shown by a perturbation experiment on a legal benchmark.
What carries the argument
The upper-bound versus lower-bound distinction in legal AI evaluation, where the upper bound arises from expert-preprocessed inputs and the lower bound from pro se input degradations.
If this is right
- If model development continues to rely only on upper-bound benchmarks, the performance gap for actual pro se users may stay hidden or grow larger.
- Access-to-justice claims about large language models will lack empirical grounding until benchmarks directly test robustness to pro se-like inputs.
- Legal AI systems may fail to deliver benefits for self-represented individuals without explicit focus on handling unprocessed user inputs.
- New benchmark designs must incorporate pro se input characteristics to allow claims about improved access to justice to be tested.
Where Pith is reading between the lines
- Creating test sets by systematically adding common pro se errors to existing legal cases could provide a practical way to measure the lower bound.
- The same upper-bound versus lower-bound distinction could apply to AI tools intended for non-experts in other technical domains such as medical or financial advice.
- Prioritizing training data that includes variable-quality user text might close the observed gap more directly than scaling model size alone.
Load-bearing premise
That degradations caused by pro se inputs such as noise and omissions produce effects on models comparable to those documented for long-context sensitivity, hallucination, and typographical perturbations in general machine learning research.
What would settle it
A controlled test finding no meaningful performance drop when legal benchmark cases are altered to add noisy narratives, buried facts, omissions, and typographical errors typical of pro se inputs.
Figures


read the original abstract
Legal AI benchmark research frequently invokes the assumption that large language models can improve access to justice, including for people who cannot access lawyers in order to understand and exercise their legal rights. We argue that current benchmarks are not equipped to support this assumption because they evaluate legal reasoning over inputs that have already been preprocessed by legal experts, which measures the upper bound of model performance. Access to justice depends on a lower bound: how models perform when inputs come from pro se litigants, whose prompts may contain noisy narratives, buried facts, omissions, folk-legal assumptions, and surface-level errors. These degradations are comparable to conditions under which LLMs are known to degrade in the general machine learning literature, including long-context sensitivity, underspecification, hallucination, and typographical perturbations. We connect evidence from pro se literature with this body of machine learning research and present a small perturbation experiment on LEXam, a legal benchmark, to illustrate the gap between these two bounds. If model development continues to focus on benchmarks that measure only the upper bound, this gap may remain hidden or even widen. We conclude by calling for legal benchmarks that directly measure robustness under pro se-like inputs so that access-to-justice claims about legal AI can become empirically testable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that legal AI benchmarks evaluate LLMs on expert-preprocessed inputs (upper bound of performance) but access-to-justice applications require robustness on raw pro se litigant inputs containing noise, buried facts, omissions, folk-legal assumptions, and errors (lower bound). It connects pro se literature to documented LLM failure modes (long-context sensitivity, underspecification, hallucination, typographical perturbations), presents a small illustrative perturbation experiment on LEXam to show the gap, and calls for new benchmarks that directly test pro se-like conditions so that access-to-justice claims become empirically testable.
Significance. If the upper/lower-bound distinction holds, the work is significant for identifying a structural mismatch in how legal benchmarks are constructed relative to real-world pro se use cases. It explicitly links pro se input characteristics to general ML degradation conditions and supplies an illustrative experiment as a concrete starting point rather than a quantitative proof of effect size. This framing could productively redirect benchmark development toward falsifiable robustness tests.
minor comments (3)
- [Abstract] Abstract: the phrase 'a small perturbation experiment on LEXam' is used without defining LEXam or briefly characterizing the perturbation types; a one-sentence gloss would aid readers who encounter the paper before the methods section.
- The mapping from pro se input traits to specific LLM failure modes is presented as comparable; adding a short table or enumerated list that pairs each pro se characteristic with the corresponding ML literature citation would improve traceability without altering the argument.
- [Conclusion] The conclusion calls for 'legal benchmarks that directly measure robustness under pro se-like inputs'; specifying one or two minimal design requirements (e.g., inclusion of unedited narrative prompts, omission of key facts) would make the recommendation more actionable.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of our core argument, and the recommendation for minor revision. We are pleased that the distinction between upper-bound performance on expert-preprocessed inputs and the lower-bound robustness needed for pro se inputs is viewed as significant for redirecting benchmark development.
Circularity Check
No significant circularity
full rationale
The paper advances its central claim by citing independent pro se literature on input characteristics and general ML literature on LLM failure modes (long-context sensitivity, hallucination, etc.), then illustrates the gap with a perturbation experiment on the external LEXam benchmark. No equations, parameter fitting, self-definitional mappings, or load-bearing self-citations appear; the upper-bound versus lower-bound distinction is argued from external evidence without reducing to the paper's own outputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and Re, Christopher and Chilton, Adam and Chohlas-Wood, Alex and Peters, Austin and Waldon, Brandon and Rockmore, Daniel N. and Zambrano, Diego and Talisman, Dmitry and Hoque, Enamul and Surani, Faiz and Fagan, Frank and Sarfaty, Galit and Dickinson, Gillian and Porat, Hadar and Hegland, Jason and Wu, Jessic...
-
[2]
arXiv preprint arXiv:2505.12864 , year=
Fan, Angela and Gonsalves, Timothy and Ney, Mathias and Sukharevsky, Alex and Samuel, Ranajoy and Greer, Morgan and Guldimann, Peter and Chaykowski, Kathleen and Lawrence, Mark and Yingling, David and Catanzaro, Bryan and Resnik, Philip and Mehta, Sameep and Fraiberger, Samuel P. and Choi, Jonathan H. , year =. 2505.12864 , archivePrefix =
-
[3]
Pipitone, Nicholas and Alami, Ghita Houir , year =. 2408.10343 , archivePrefix =
-
[4]
Levy, Andrew Hammond , journal =
-
[5]
and Cantone, Jason A
Stienstra, Donna and Bataillon, Jared J. and Cantone, Jason A. , institution =. 2011 , url =
2011
-
[6]
2015 , url =
Hannaford-Agor, Paula and Graves, Scott and Miller, Shelley Spacek , institution =. 2015 , url =
2015
-
[7]
and Law, Stephanie and Ng, Lauren and Shanahan, Colleen F
Engstrom, David Freeman and Hagan, Margaret and Ho, Daniel E. and Law, Stephanie and Ng, Lauren and Shanahan, Colleen F. , year =
-
[8]
Toy-Cronin, Bridgette and McLachlan, Saskia and Buckley, Jenni and Hunter, Ruth and McLay, Geoff , journal =
-
[9]
and Conley, John M
O'Barr, William M. and Conley, John M. , journal =
-
[10]
and O'Barr, William M
Conley, John M. and O'Barr, William M. , publisher =
-
[11]
2026 , month = may, url =
2026
-
[12]
2026 , month = apr, url =
Nerkar, Santul , howpublished =. 2026 , month = apr, url =
2026
-
[13]
and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , journal =
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , journal =. 2024 , doi =
2024
-
[14]
2025 , eprint =
Yang, Chenyang and Shi, Yike and Ma, Qianou and Liu, Michael Xieyang and K. 2025 , eprint =
2025
- [15]
-
[16]
, journal =
Dahl, Matthew and Magesh, Varun and Suzgun, Mirac and Ho, Daniel E. , journal =. 2024 , doi =
2024
-
[17]
Zhu, Kaijie and Wang, Jindong and Zhou, Jiaheng and Wang, Zichen and Chen, Hao and Wang, Yidong and Yang, Linyi and Ye, Wei and Zhang, Yue and Gong, Neil Zhenqiang and Xie, Xing , year =. 2306.04528 , archivePrefix =
-
[18]
Dobariya, Om and Kumar, Akhil , year =. 2510.04950 , archivePrefix =
-
[19]
Joren, Hailey and Zhang, Jianyi and Ferng, Chun-Sung and Juan, Da-Cheng and Taly, Ankur and Rashtchian, Cyrus , booktitle =. 2025 , url =. 2411.06037 , archivePrefix =
-
[21]
Budzinski, Andrew , journal =
-
[22]
Administrative Office of the U.S. Courts . Pro Se Case Filings Have Increased in U.S. District Courts Since 2000 , 2021. URL https://www.uscourts.gov/data-news/reports/analysis-reports/pro-se-case-filings-have-increased-us-district-courts-2000
2000
-
[23]
Alzahrani, N., Alyahya, H., Alnumay, Y., AlRashed, S., Alsubaie, S., Almushayqih, Y., Mirza, F., Alotaibi, N., Al-Twairesh, N., Alowisheq, A., Bari, M. S., and Khan, H. When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vo...
-
[24]
Overhauling Rules of Evidence in Pro Se Courts
Budzinski, A. Overhauling Rules of Evidence in Pro Se Courts . University of Richmond Law Review, 56, 2022
2022
-
[25]
Conley, J. M. and O'Barr, W. M. Rules versus Relationships: The Ethnography of Legal Discourse . University of Chicago Press, 1990
1990
-
[26]
Dahl, M., Magesh, V., Suzgun, M., and Ho, D. E. Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models . Journal of Legal Analysis, 16 0 (1): 0 64--93, 2024. doi:10.1093/jla/laae003
-
[27]
and Kumar, A
Dobariya, O. and Kumar, A. Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy , 2025
2025
-
[28]
F., Hagan, M., Ho, D
Engstrom, D. F., Hagan, M., Ho, D. E., Law, S., Ng, L., and Shanahan, C. F. Making the A2J Crisis Count: Data, Reform, and the Eviction Machine , 2024. URL https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4286971
2024
-
[29]
P., and Choi, J
Fan, A., Gonsalves, T., Ney, M., Sukharevsky, A., Samuel, R., Greer, M., Guldimann, P., Chaykowski, K., Lawrence, M., Yingling, D., Catanzaro, B., Resnik, P., Mehta, S., Fraiberger, S. P., and Choi, J. H. LEXam : Benchmarking Legal Reasoning on 340 Law Exams , 2025
2025
-
[30]
Employer Playbook for Attacking AI Use in Pro Se Litigation: A Roundup of Recent Court Sanctions Against ChatGPT Plaintiffs , May 2026
Fisher Phillips . Employer Playbook for Attacking AI Use in Pro Se Litigation: A Roundup of Recent Court Sanctions Against ChatGPT Plaintiffs , May 2026. URL https://www.fisherphillips.com/en/insights/insights/employer-playbook-for-attacking-ai-use-in-pro-se-litigation
2026
-
[31]
E., Re, C., Chilton, A., Chohlas-Wood, A., Peters, A., Waldon, B., Rockmore, D
Guha, N., Nyarko, J., Ho, D. E., Re, C., Chilton, A., Chohlas-Wood, A., Peters, A., Waldon, B., Rockmore, D. N., Zambrano, D., Talisman, D., Hoque, E., Surani, F., Fagan, F., Sarfaty, G., Dickinson, G., Porat, H., Hegland, J., Wu, J., Nudell, J., Niklaus, J., Nay, J. J., Choi, J. H., Tobia, K., Hagan, M., Ma, M., Livermore, M. A., Rasumov-Rahe, N., Holzen...
2023
-
[32]
Hannaford-Agor, P., Graves, S., and Miller, S. S. The Landscape of Civil Litigation in State Courts , 2015. URL https://www.ncsc.org/__data/assets/pdf_file/0020/13376/civiljusticereport-2015.pdf
2015
-
[33]
Sufficient Context: A New Lens on Retrieval Augmented Generation Systems
Joren, H., Zhang, J., Ferng, C.-S., Juan, D.-C., Taly, A., and Rashtchian, C. Sufficient Context: A New Lens on Retrieval Augmented Generation Systems . In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=Jjr2Odj8DJ
2025
-
[34]
Kirichenko, P., Ibrahim, M., Chaudhuri, K., and Bell, S. J. AbstentionBench : Reasoning LLM s Fail on Unanswerable Questions , 2025
2025
-
[35]
The Justice Gap: The Unmet Civil Legal Needs of Low-Income Americans , 2022
Legal Services Corporation . The Justice Gap: The Unmet Civil Legal Needs of Low-Income Americans , 2022. URL https://justicegap.lsc.gov/
2022
-
[36]
Levy, A. H. Empirical Patterns of Pro Se Litigation in Federal District Courts . University of Chicago Law Review, 85 0 (7): 0 1819--1871, 2018
2018
-
[37]
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., and Liang, P. Lost in the Middle: How Language Models Use Long Contexts . Transactions of the Association for Computational Linguistics, 12: 0 157--173, 2024. doi:10.1162/tacl_a_00638
-
[38]
Nerkar, S. A.I. ``Hallucinations'' Created Errors in Court Filing, Top Law Firm Says . The New York Times, April 2026. URL https://www.nytimes.com/2026/04/21/nyregion/sullivan-cromwell-ai-hallucination.html
2026
-
[39]
O'Barr, W. M. and Conley, J. M. Litigant Satisfaction versus Legal Adequacy in Small Claims Court Narratives . Law & Society Review, 19 0 (4): 0 661--701, 1985
1985
-
[40]
and Alami, G
Pipitone, N. and Alami, G. H. LegalBench-RAG : A Benchmark for Retrieval-Augmented Generation in the Legal Domain , 2024
2024
-
[41]
J., and Cantone, J
Stienstra, D., Bataillon, J. J., and Cantone, J. A. Assistance to Pro Se Litigants in U.S. District Courts: A Report on Surveys of Clerks of Court and Chief Judges , 2011. URL https://www.fjc.gov/sites/default/files/2012/ProSeUSDC.pdf
2011
-
[42]
Report to the Chief Judge of the State of New York , 2010
Task Force to Expand Access to Civil Legal Services in New York . Report to the Chief Judge of the State of New York , 2010. URL https://ww2.nycourts.gov/sites/default/files/document/files/2018-04/CLS-TaskForceREPORT.pdf
2010
-
[43]
Tightening the Justice Gap: How to Use AI to Improve Access to Justice
Toy-Cronin, B., McLachlan, S., Buckley, J., Hunter, R., and McLay, G. Tightening the Justice Gap: How to Use AI to Improve Access to Justice . Journal of Dispute Resolution, 2022 0 (1): 0 79--110, 2022
2022
-
[44]
X., K \"a stner, C., and Wu, T
Yang, C., Shi, Y., Ma, Q., Liu, M. X., K \"a stner, C., and Wu, T. What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts , 2025
2025
-
[45]
Z., and Xie, X
Zhu, K., Wang, J., Zhou, J., Wang, Z., Chen, H., Wang, Y., Yang, L., Ye, W., Zhang, Y., Gong, N. Z., and Xie, X. PromptRobust : Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts , 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.