Neuro-Symbolic Drive: Rule-Grounded Faithful Reasoning for Driving VLAs
Pith reviewed 2026-06-26 07:57 UTC · model grok-4.3
The pith
Supervising driving VLAs with serialized reasoning traces from rule-based planners ensures the generated reasoning is structurally coupled to the planned motion by construction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Neuro-Symbolic Drive is a framework that supervises driving VLAs with rule-grounded reasoning traces extracted directly from classical rule-based planners. Rule-based planners function as executable reasoning engines that reason about safety constraints, search maneuvers, and select trajectories. By instrumenting these planners in simulation to capture the internal decision trace at each rule-evaluation step and serializing it into structured text, the approach pairs the trace with the trajectory for fine-tuning. Because the traces derive directly from the planner states that determine the action, the reasoning is structurally coupled to motion generation by construction rather than post-hoc
What carries the argument
Serialized rule-grounded reasoning traces captured from the internal decision steps of classical rule-based planners
If this is right
- Detailed rule-grounded reasoning reduces ADE@3s from 0.47 to 0.26 and miss rate from 8.30% to 6.40% under three-camera perception.
- Comparable reductions occur under eight-camera perception, with ADE dropping from 0.54 to 0.26 and miss rate from 10.13% to 5.99%.
- The framework converts neuro-symbolic planning logic into structured supervision for VLAs.
- It supplies a construction that ties reasoning to motion generation without separate post-hoc alignment.
Where Pith is reading between the lines
- The method could extend to other control domains that already possess classical rule-based planners as sources of supervision.
- Because the benchmark is simulator-generated, real-world transfer would require either equivalent trace capture from deployed planners or domain adaptation techniques.
Load-bearing premise
The internal decision traces captured from rule-based planners during simulation can be serialized into structured text that, when used as supervision, will cause the fine-tuned VLA to produce causally connected reasoning in new perception inputs.
What would settle it
Running the fine-tuned VLA on new perception inputs and checking whether its generated reasoning steps match the rule evaluations that the original planner would perform on the same inputs; systematic divergence between reasoning and planner logic would falsify the structural coupling claim.
Figures

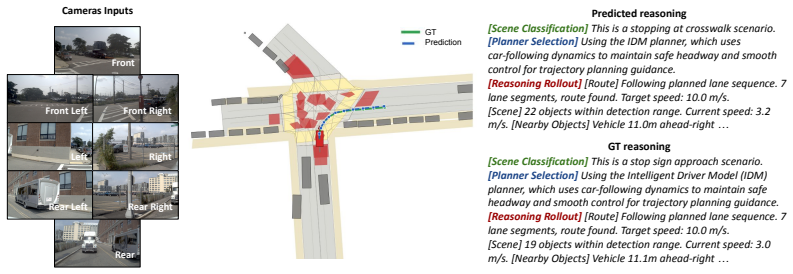
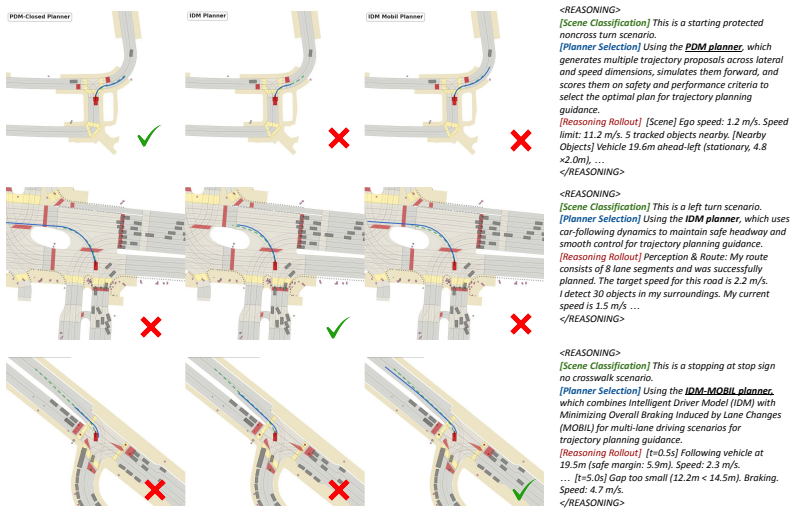
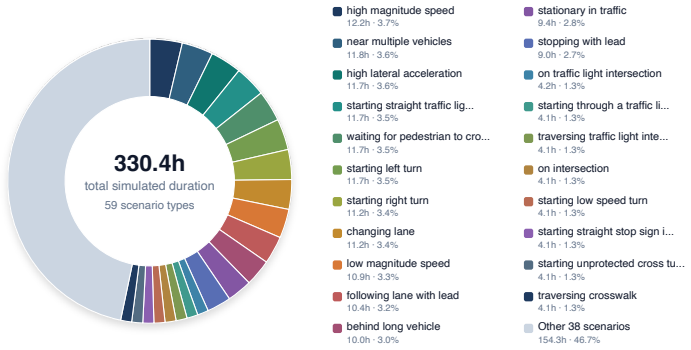
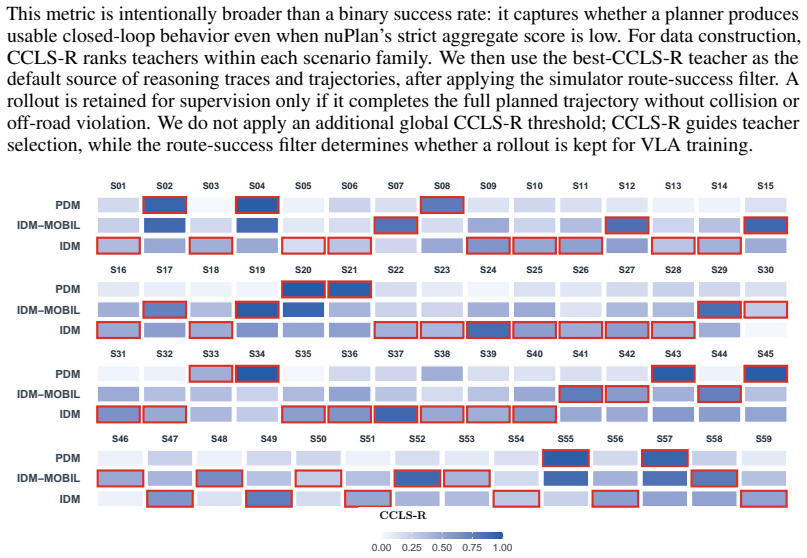
read the original abstract
Driving VLA models incorporating Chain-of-Thought (CoT) reasoning are attractive because they leverage pretrained VLM representations and expose intermediate decisions in natural language, yet current rationales often lack the step-by-step decision semantics needed to keep the rationale causally connected to the planned motion. We introduce Neuro-Symbolic Drive, a neuro-symbolic driving framework that supervises a driving VLA with rule-grounded reasoning traces extracted directly from classical rule-based planners. Our key observation is that rule-based planners are symbolic AI systems that already function as executable reasoning engines: they reason about active safety constraints, search over candidate maneuvers, and select a final trajectory. We instrument these planners in simulation to capture both the executed trajectory and the internal decision trace at each rule-evaluation step. Each trace is serialized into structured rule-grounded reasoning and paired with the trajectory to fine-tune Qwen3.5-4B as a driving VLA. Because these traces are derived directly from the planner states that determine the action, they ensure reasoning is structurally coupled to motion generation by construction, rather than by post-hoc alignment. On our simulator-generated benchmark, detailed rule-grounded reasoning reduces ADE@3s from 0.47 to 0.26 and miss rate from 8.30% to 6.40% under three-camera perception, and from 0.54 to 0.26 and 10.13% to 5.99% under eight-camera perception. Neuro-Symbolic Drive thus converts neuro-symbolic planning logic into structured supervision. Code base: https://github.com/XiangboGaoBarry/Neural-Symbolic-Drive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neuro-Symbolic Drive, a framework that instruments classical rule-based planners in simulation to extract internal decision traces, serializes them into structured rule-grounded reasoning, and uses the resulting (trace, trajectory) pairs to fine-tune Qwen3.5-4B as a driving VLA. It claims that because the traces originate directly from the planner states that determine the action, the resulting model produces reasoning that is structurally coupled to motion generation by construction. Quantitative results on a simulator benchmark show reductions in ADE@3s (0.47→0.26) and miss rate (8.30%→6.40%) under three-camera perception and similar gains under eight-camera perception.
Significance. If the central claim of inference-time causal coupling holds and the gains are attributable to the rule-grounded supervision rather than generic imitation, the work offers a practical route to more interpretable VLAs by repurposing existing symbolic planners as supervision sources. The release of the code base is a clear positive. The significance is tempered by the fact that the reported improvements could arise from better trajectory imitation alone, without the generated natural-language traces remaining causally linked to the chosen motion at test time.
major comments (3)
- [Abstract / §3] Abstract and §3 (method): The claim that traces 'derived directly from the planner states that determine the action' ensure reasoning is 'structurally coupled to motion generation by construction' holds only inside the data-generation pipeline. After fine-tuning, the model is a standard autoregressive VLA; no architectural constraint or loss term enforces that the reasoning tokens emitted at inference time are the decisions that would have produced the output trajectory under the original symbolic rules. This is load-bearing for the 'faithful reasoning' contribution.
- [Results] Results section (quantitative evaluation): The reported ADE@3s and miss-rate improvements are presented without ablations that isolate the contribution of the rule-grounded trace supervision versus other factors (e.g., increased data volume, different fine-tuning hyperparameters, or simply better imitation of planner trajectories). Without such controls it is impossible to attribute the gains to the claimed mechanism.
- [§4] Benchmark construction (implied in §4): The paper states gains on 'our simulator-generated benchmark' but provides no details on trace extraction fidelity, how perception inputs are paired with traces, statistical significance of the reported deltas, or whether the test distribution matches the training distribution of planner states. These details are required to assess whether the coupling claim generalizes.
minor comments (2)
- [§3] Notation for the serialized traces is introduced without an explicit example showing the mapping from planner internal state to the structured text format used as supervision.
- [Abstract] The abstract mentions 'three-camera' and 'eight-camera' perception but does not clarify whether these are the only input modalities or how the VLA processes multi-view images.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commit to revisions that strengthen the presentation of our claims without overstating the results.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method): The claim that traces 'derived directly from the planner states that determine the action' ensure reasoning is 'structurally coupled to motion generation by construction' holds only inside the data-generation pipeline. After fine-tuning, the model is a standard autoregressive VLA; no architectural constraint or loss term enforces that the reasoning tokens emitted at inference time are the decisions that would have produced the output trajectory under the original symbolic rules. This is load-bearing for the 'faithful reasoning' contribution.
Authors: We agree that the structural coupling is realized through the data-generation pipeline, where traces are extracted directly from the planner states that produce the trajectory. At inference the model remains a standard autoregressive VLA with no runtime enforcement. Our phrasing 'by construction' was intended to highlight the direct provenance of the supervision signal rather than an architectural guarantee. We will revise the abstract and §3 to make this distinction explicit, stating that faithfulness is induced via training on planner-derived (trace, trajectory) pairs and is not guaranteed at test time. This addresses the load-bearing concern by tempering the claim. revision: yes
-
Referee: [Results] Results section (quantitative evaluation): The reported ADE@3s and miss-rate improvements are presented without ablations that isolate the contribution of the rule-grounded trace supervision versus other factors (e.g., increased data volume, different fine-tuning hyperparameters, or simply better imitation of planner trajectories). Without such controls it is impossible to attribute the gains to the claimed mechanism.
Authors: The referee is correct that the current results do not isolate the contribution of the rule-grounded traces from other factors such as data volume or hyperparameter choices. We will add an ablation that fine-tunes the same base model on planner trajectories without the serialized reasoning traces, thereby controlling for imitation alone. The new experiment will be reported in the revised results section to better support attribution to the rule-grounded supervision. revision: yes
-
Referee: [§4] Benchmark construction (implied in §4): The paper states gains on 'our simulator-generated benchmark' but provides no details on trace extraction fidelity, how perception inputs are paired with traces, statistical significance of the reported deltas, or whether the test distribution matches the training distribution of planner states. These details are required to assess whether the coupling claim generalizes.
Authors: We will expand §4 with the requested details: trace extraction fidelity (how planner internal states are serialized without information loss), the precise pairing of multi-camera inputs with traces, and confirmation that test planner states are sampled from the same distribution as training. We will also add statistical significance measures (e.g., standard error across runs) for the reported ADE and miss-rate deltas. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's key step extracts decision traces from external classical rule-based planners (instrumented in simulation) and uses them as supervision to fine-tune the VLA. This data-generation pipeline is independent of the VLA's own outputs or parameters. The claim that traces 'ensure reasoning is structurally coupled to motion generation by construction' refers only to the origin of the training pairs and does not reduce any derived quantity to a fitted input or self-citation. No equations, self-citations, or ansatzes are invoked that would make the central result equivalent to its inputs by definition. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rule-based planners function as executable reasoning engines whose internal states can be captured and serialized into structured reasoning traces that remain causally linked to the executed trajectory.
Reference graph
Works this paper leans on
-
[1]
Quad: Query-based interpretable neural motion planning for autonomous driving
Sourav Biswas, Sergio Casas, Quinlan Sykora, Ben Agro, Abbas Sadat, and Raquel Urtasun. Quad: Query-based interpretable neural motion planning for autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 14236–14243. IEEE, 2024
2024
-
[2]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InCVPR, 2020
2020
-
[3]
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles.arXiv preprint arXiv:2106.11810, 2021
Pith/arXiv arXiv 2021
-
[4]
Mp3: A unified model to map, perceive, predict and plan
Sergio Casas, Abbas Sadat, and Raquel Urtasun. Mp3: A unified model to map, perceive, predict and plan. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14403–14412, 2021
2021
-
[5]
Long Chen, Oleg Sinavski, Jan Hünermann, Alice Karnsund, Andrew James Willmott, Danny Birch, Daniel Maund, and Jamie Shotton. Driving with llms: Fusing object-level vector modality for explainable autonomous driving.arXiv preprint arXiv:2310.01957, 2023
arXiv 2023
-
[6]
Panchal, Amr Abdelraouf, et al
Can Cui, Yunsheng Ma, Zichong Yang, Yupeng Zhou, Peiran Liu, Juanwu Lu, Lingxi Li, Yaobin Chen, Jitesh H. Panchal, Amr Abdelraouf, et al. Large language models for autonomous driving (llm4ad): Concept, benchmark, experiments, and challenges.arXiv preprint arXiv:2410.15281, 2024
arXiv 2024
-
[7]
Parting with miscon- ceptions about learning-based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with miscon- ceptions about learning-based vehicle motion planning. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 1268–1281. PMLR, 2023
2023
-
[8]
Causal confusion in imitation learning
Pim de Haan, Dinesh Jayaraman, and Sergey Levine. Causal confusion in imitation learning. In Advances in Neural Information Processing Systems, volume 32, 2019
2019
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 645:633–638, 2025. doi: 10.1038/s41586-025-09422-z. arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2025
-
[10]
Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24823–24834, 2025
2025
-
[11]
Xiangbo Gao, Tzu-Hsiang Lin, Ruojing Song, Yuheng Wu, Kuan-Ru Huang, Zicheng Jin, Fangzhou Lin, Shinan Liu, and Zhengzhong Tu. Safecoop: Unravelling full stack safety in agentic collaborative driving.arXiv preprint arXiv:2510.18123, 2025
arXiv 2025
-
[12]
Automated vehicles should be connected with natural language.arXiv preprint arXiv:2507.01059, 2025
Xiangbo Gao, Keshu Wu, Hao Zhang, Kexin Tian, Yang Zhou, and Zhengzhong Tu. Automated vehicles should be connected with natural language.arXiv preprint arXiv:2507.01059, 2025. 10
arXiv 2025
-
[13]
Langcoop: Collaborative driving with language
Xiangbo Gao, Yuheng Wu, Rujia Wang, Chenxi Liu, Yang Zhou, and Zhengzhong Tu. Langcoop: Collaborative driving with language. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4226–4237, 2025
2025
-
[14]
Anurag Ghosh, Srinivasa Narasimhan, Manmohan Chandraker, and Francesco Pittaluga. Rad-lad: Rule and language grounded autonomous driving in real-time.arXiv preprint arXiv:2603.28522, 2026
arXiv 2026
-
[15]
Drama-x: A fine-grained intent prediction and risk reasoning benchmark for driving
Mihir Godbole, Xiangbo Gao, and Zhengzhong Tu. Drama-x: A fine-grained intent prediction and risk reasoning benchmark for driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 815–820, 2025
2025
-
[16]
Marcel Hallgarten, Julian Zapata, Martin Stoll, Katrin Renz, and Andreas Zell. Can vehicle motion planning generalize to realistic long-tail scenarios? In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5388–5395, 2024. doi: 10.1109/ IROS58592.2024.10803052
arXiv 2024
-
[17]
Patel, and Fatih Porikli
Deepti Hegde, Rajeev Yasarla, Hong Cai, Shizhong Han, Apratim Bhattacharyya, Shweta Mahajan, Litian Liu, Risheek Garrepalli, Vishal M. Patel, and Fatih Porikli. Distilling multi- modal large language models for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27575–27585, 2025
2025
-
[18]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InCVPR, 2023
2023
-
[19]
Drivlme: Enhancing llm-based autonomous driving agents with embodied and social experiences
Yidong Huang, Jacob Sansom, Ziqiao Ma, Felix Gervits, and Joyce Chai. Drivlme: Enhancing llm-based autonomous driving agents with embodied and social experiences. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3153–3160. IEEE, 2024
2024
-
[20]
Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
Pith/arXiv arXiv 2024
-
[21]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InICCV, 2023
2023
-
[22]
Bo Jiang, Shaoyu Chen, Bencheng Liao, Xingyu Zhang, Wei Yin, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Senna: Bridging large vision-language models and end-to-end autonomous driving.arXiv preprint arXiv:2410.22313, 2024
Pith/arXiv arXiv 2024
-
[23]
Towards learning-based planning: The nuplan benchmark for real-world autonomous driving
Napat Karnchanachari, Dimitris Geromichalos, Kok Seang Tan, Nanxiang Li, Christopher Eriksen, Shakiba Yaghoubi, Noushin Mehdipour, Gianmarco Bernasconi, Whye Kit Fong, Yiluan Guo, et al. Towards learning-based planning: The nuplan benchmark for real-world autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 629...
2024
-
[24]
Joonkyung Kim, Wenxi Chen, Davood Soleymanzadeh, Yi Ding, Xiangbo Gao, Zhengzhong Tu, Ruqi Zhang, Fan Fei, Sushant Veer, Yiwei Lyu, et al. Modular safety guardrails are necessary for foundation-model-enabled robots in the real world.arXiv preprint arXiv:2602.04056, 2026
arXiv 2026
-
[25]
Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
Pith/arXiv arXiv 2023
-
[26]
Yue Li, Meng Tian, Dechang Zhu, Jiangtong Zhu, Zhenyu Lin, Zhiwei Xiong, and Xinhai Zhao. Drive-r1: Bridging reasoning and planning in vlms for autonomous driving with reinforcement learning.arXiv preprint arXiv:2506.18234, 2025
arXiv 2025
-
[27]
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, Yu-Gang Jiang, and José M. Álvarez. Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024. 11
Pith/arXiv arXiv 2024
-
[28]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=v8L0pN6EOi
2024
-
[29]
Lampilot: An open benchmark dataset for autonomous driving with language model programs
Yunsheng Ma, Can Cui, Xu Cao, Wenqian Ye, Peiran Liu, Juanwu Lu, Amr Abdelraouf, Rohit Gupta, Kyungtae Han, Aniket Bera, et al. Lampilot: An open benchmark dataset for autonomous driving with language model programs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15141–15151, 2024
2024
-
[30]
Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving
Ming Nie, Renyuan Peng, Chunwei Wang, Xinyue Cai, Jianhua Han, Hang Xu, and Li Zhang. Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving. In European Conference on Computer Vision, pages 292–308. Springer, 2024
2024
-
[31]
Introducing openai o1.https://openai.com/o1/, 2024
OpenAI. Introducing openai o1.https://openai.com/o1/, 2024
2024
-
[32]
Simlingo: Vision-only closed- loop autonomous driving with language-action alignment
Katrin Renz, Long Chen, Elahe Arani, and Oleg Sinavski. Simlingo: Vision-only closed- loop autonomous driving with language-action alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11993–12003, 2025
2025
-
[33]
Hao Sha, Yao Mu, Yuxuan Jiang, Li Chen, Chenfeng Xu, Ping Luo, Shengbo Eben Li, Masayoshi Tomizuka, Wei Zhan, and Mingyu Ding. Languagempc: Large language mod- els as decision makers for autonomous driving.arXiv preprint arXiv:2310.03026, 2023
arXiv 2023
-
[34]
Waslander, Yu Liu, and Hong- sheng Li
Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L. Waslander, Yu Liu, and Hong- sheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15120–15130, 2024
2024
-
[35]
Visual program distillation with template-based augmentation
Michal Shlapentokh-Rothman, Yu-Xiong Wang, and Derek Hoiem. Visual program distillation with template-based augmentation. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025
2025
-
[36]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean Conference on Computer Vision, pages 256–274. Springer, 2024
2024
-
[37]
Xurui Song, Shuo Huai, Jingjing Jiang, Jiayi Kong, and Jun Luo. More than meets the eye? uncovering the reasoning-planning disconnect in training vision-language driving models.arXiv preprint arXiv:2510.04532, 2025
arXiv 2025
-
[38]
Jiacheng Tang, Zhiyuan Zhou, Zhuolin He, Jia Zhang, Kai Zhang, and Jian Pu. Causal- vad: De-confounding end-to-end autonomous driving via causal intervention.arXiv preprint arXiv:2603.18561, 2026
Pith/arXiv arXiv 2026
-
[39]
Ximeng Tao, Pardis Taghavi, Dimitar Filev, Reza Langari, and Gaurav Pandey. Navidrivevlm: Decoupling high-level reasoning and motion planning for autonomous driving.arXiv preprint arXiv:2603.07901, 2026
arXiv 2026
-
[40]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[41]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[42]
Drivevlm: The convergence of autonomous driving and large vision-language models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, XianPeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 4698–4726. PMLR, 2025
2025
-
[43]
Modeling lane-changing decisions with mobil
Martin Treiber and Arne Kesting. Modeling lane-changing decisions with mobil. In Cécile Appert-Rolland, François Chevoir, Philippe Gondret, Sylvain Lassarre, Jean-Patrick Lebacque, and Michael Schreckenberg, editors,Traffic and Granular Flow ’07, pages 211–221, Berlin, Heidelberg, 2009. Springer Berlin Heidelberg. ISBN 978-3-540-77074-9. 12
2009
-
[44]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[45]
Learning interpretable end- to-end vision-based motion planning for autonomous driving with optical flow distillation
Hengli Wang, Peide Cai, Yuxiang Sun, Lujia Wang, and Ming Liu. Learning interpretable end- to-end vision-based motion planning for autonomous driving with optical flow distillation. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13731–13737. IEEE, 2021
2021
-
[46]
Tianqi Wang, Enze Xie, Ruihang Chu, Zhenguo Li, and Ping Luo. Drivecot: Integrating chain-of-thought reasoning with end-to-end driving.arXiv preprint arXiv:2403.16996, 2024
arXiv 2024
-
[47]
Wenhai Wang, Jiangwei Xie, Chuanyang Hu, Haoming Zou, Jianan Fan, Wenwen Tong, Yang Wen, Silei Wu, Hanming Deng, Zhiqi Li, et al. Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving.arXiv preprint arXiv:2312.09245, 2023
arXiv 2023
-
[48]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Dia- mond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
Pith/arXiv arXiv 2025
-
[49]
Yuping Wang, Shuo Xing, Cui Can, Renjie Li, Hongyuan Hua, Kexin Tian, Zhaobin Mo, Xiangbo Gao, Keshu Wu, Sulong Zhou, et al. Generative ai for autonomous driving: Frontiers and opportunities.arXiv preprint arXiv:2505.08854, 2025
arXiv 2025
-
[50]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022
2022
-
[51]
Shuo Xing, Hongyuan Hua, Xiangbo Gao, Shenzhe Zhu, Renjie Li, Kexin Tian, Xiaopeng Li, Heng Huang, Tianbao Yang, Zhangyang Wang, et al. Autotrust: Benchmarking trustworthiness in large vision language models for autonomous driving.arXiv preprint arXiv:2412.15206, 2024
arXiv 2024
-
[52]
Openemma: Open-source multimodal model for end-to-end autonomous driving
Shuo Xing, Chengyuan Qian, Yuping Wang, Hongyuan Hua, Kexin Tian, Yang Zhou, and Zhengzhong Tu. Openemma: Open-source multimodal model for end-to-end autonomous driving. InProceedings of the Winter Conference on Applications of Computer Vision, pages 1001–1009, 2025
2025
-
[53]
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kenneth K. Y . Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.arXiv preprint arXiv:2310.01412, 2023
arXiv 2023
-
[54]
Zhenjie Yang, Xiaosong Jia, Hongyang Li, and Junchi Yan. Llm4drive: A survey of large language models for autonomous driving.arXiv preprint arXiv:2311.01043, 2023
arXiv 2023
-
[55]
AutoDrive- P3: Unified chain of perception–prediction–planning thought via reinforcement fine-tuning
Yuqi Ye, Zijian Zhang, Junhong Lin, Shangkun Sun, Changhao Peng, and Wei Gao. AutoDrive- P3: Unified chain of perception–prediction–planning thought via reinforcement fine-tuning. In International Conference on Learning Representations, 2026
2026
-
[56]
Rag-driver: Generalisable driving explanations with retrieval-augmented in-context learning in multi-modal large language model
Jianhao Yuan, Shuyang Sun, Daniel Omeiza, Bo Zhao, Paul Newman, Lars Kunze, and Matthew Gadd. Rag-driver: Generalisable driving explanations with retrieval-augmented in-context learning in multi-modal large language model. InRobotics: Science and Systems, 2024
2024
-
[57]
End-to-end interpretable neural motion planner
Wenyuan Zeng, Wenjie Luo, Simon Suo, Abbas Sadat, Bin Yang, Sergio Casas, and Raquel Urtasun. End-to-end interpretable neural motion planner. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8660–8669, 2019
2019
-
[58]
Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma
Zewei Zhou, Tianhui Cai, Seth Z. Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning. InAdvances in Neural Information Processing Systems, 2025. 13 A Appendix A.1 Trace Schema and Teacher-Specific Signals Table 3 summarizes t...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.