DriveStack-VLA: Render-Teacher Alignment for BEV-Based DeepStack Vision-Language-Action Model
Pith reviewed 2026-06-26 01:37 UTC · model grok-4.3
The pith
DriveStack-VLA adds bird's-eye-view injection and render-teacher alignment to give VLA driving models metric geometry and better perceptual focus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
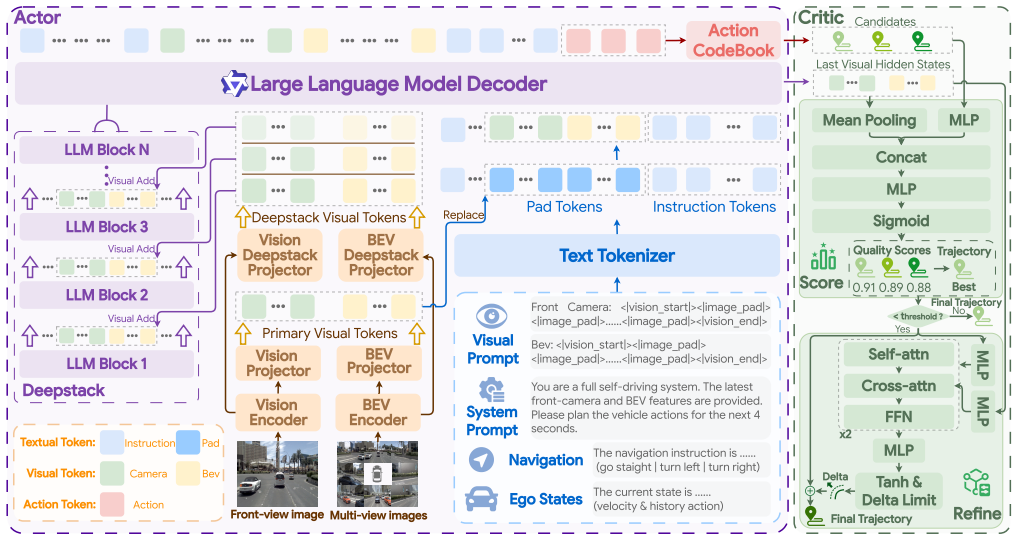
DriveStack-VLA strengthens the spatial intelligence of VLA driving policies by injecting BEV representations into the LLM decoder through a DeepStack-style connection, aligning perceptual focus of real and rasterized images via Render-Teacher Alignment, and using head-based self-critique to rank and refine trajectories, yielding the stated benchmark scores.
What carries the argument
Dual visual modeling via BEV injection into the LLM decoder plus Render-Teacher Alignment that aligns real-image and rasterized-image perceptual focus, augmented by head-based self-critique for trajectory selection.
If this is right
- VLA policies gain explicit access to top-down scene structure for motion planning.
- Perceptual coverage improves on safety-critical cues that expert demonstrations may under-represent.
- Trajectory selection becomes conditional on a learned ranking rather than language priors alone.
- The model can follow language guidance while respecting metric constraints that pure perspective grounding misses.
Where Pith is reading between the lines
- The same dual-visual approach might transfer to other embodied tasks that need both language grounding and metric spatial reasoning.
- If render-teacher alignment proves stable, it could reduce the volume of expert driving data required for training.
- Closed-loop gains on Bench2Drive suggest the method may scale to longer-horizon planning once the self-critique head is extended to temporal consistency.
Load-bearing premise
That adding BEV injection, render-teacher alignment, and self-critique will overcome the perspective-image grounding and missing metric geometry that limit existing VLA driving models.
What would settle it
An experiment in which DriveStack-VLA shows no improvement over a plain VLM baseline on scenes that specifically require metric geometry or top-down structure, or where the alignment produces mismatched attention maps between real and rasterized views.
Figures



read the original abstract
Vision-Language-Action driving models convert a pretrained Vision-Language Model into a driving policy, allowing them to use world knowledge and follow language guidances. However, existing VLA driving models still lack driving-oriented spatial intelligence: their policies are mainly grounded on perspective image tokens and language priors, while precise motion planning requires metric geometry, top-down scene structure, and attention to safety-critical perceptual cues. This limitation makes current models vulnerable to weak visual geometry modeling and perceptual coverage in expert demonstrations. In this paper, we present DriveStack-VLA, a framework built upon a large VLM backbone. To strengthen the spatial grounding of VLA driving, we develop dual visual modeling components. We inject a Bird-Eye-View representation into the Large Language Model decoder through a DeepStack-style connection, and propose Render-Teacher Alignment to align the perceptual focus of real images with that of rasterized images. Furthermore, to bridge the gap in multimodal trajectory selection, we introduce a head-based self-critique module that ranks sampled trajectories and conditionally refines the best one. DriveStack-VLA achieves 91.6 PDMS on NAVSIMv1, 91.0 EPDMS on NAVSIMv2 (with the human penalty filter enabled), and a driving score of 79.49 with a success rate of 56.36\% on the closed-loop Bench2Drive. More visualizations are available on our project page: https://anonymous.4open.science/w/drivestack-vla/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing VLA driving models lack driving-oriented spatial intelligence due to grounding on perspective image tokens and language priors rather than metric geometry and top-down structure. DriveStack-VLA addresses this via dual visual modeling: BEV injection into the LLM decoder through a DeepStack-style connection, Render-Teacher Alignment to match perceptual focus between real and rasterized images, and a head-based self-critique module for ranking and refining sampled trajectories. It reports 91.6 PDMS on NAVSIMv1, 91.0 EPDMS on NAVSIMv2 (human penalty filter), and 79.49 driving score / 56.36% success rate on closed-loop Bench2Drive.
Significance. If the performance claims hold after verification, the work would demonstrate a concrete way to inject metric scene structure and perceptual alignment into VLM-based driving policies, potentially improving robustness on safety-critical cues. The combination of BEV injection, Render-Teacher Alignment, and self-critique is a targeted response to stated limitations in current VLA models and could influence subsequent architectures that seek to retain VLM world knowledge while adding geometric grounding.
major comments (1)
- [Abstract] Abstract: the central performance claims (91.6 PDMS, 91.0 EPDMS, 79.49 driving score) are presented without any accompanying ablation studies, error bars, dataset split details, or training hyperparameter information, making it impossible to assess whether the reported gains are attributable to the proposed dual visual modeling and self-critique components or to other factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below, providing clarification on where supporting details appear in the full paper while agreeing to strengthen the abstract for better accessibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (91.6 PDMS, 91.0 EPDMS, 79.49 driving score) are presented without any accompanying ablation studies, error bars, dataset split details, or training hyperparameter information, making it impossible to assess whether the reported gains are attributable to the proposed dual visual modeling and self-critique components or to other factors.
Authors: We acknowledge that the abstract presents the performance numbers concisely without ablations or hyperparameters, which is typical due to length limits. The full manuscript addresses this: ablation studies isolating each component (BEV injection, Render-Teacher Alignment, self-critique) appear in Section 4.3 with quantitative breakdowns; error bars from multiple random seeds are included in the main results tables; dataset splits, preprocessing, and evaluation protocols are specified in Section 3; and training hyperparameters are provided in Appendix A. These elements demonstrate that gains are attributable to the proposed dual visual modeling and self-critique rather than extraneous factors. To improve standalone readability of the abstract, we will add a short clause referencing the ablation-supported contributions. revision: yes
Circularity Check
No significant circularity; derivation is empirical and self-contained
full rationale
The provided abstract and high-level description contain no equations, parameter-fitting steps, or derivation chain. The framework is described as injecting BEV via DeepStack-style connection and adding Render-Teacher Alignment plus self-critique, with performance reported on external benchmarks (NAVSIM, Bench2Drive). No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations are visible. The central claims rest on experimental outcomes rather than internal equivalence to inputs. This is the expected outcome for an empirical ML paper at abstract level; full text would be needed for deeper inspection but none is exhibited here.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Render-Teacher Alignment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Orion: A holistic end-to-end au- tonomous driving framework by vision-language instructed action generation,
H. Fu, D. Zhang, Z. Zhao, J. Cui, D. Liang, C. Zhang, D. Zhang, H. Xie, B. Wang, and X. Bai, “Orion: A holistic end-to-end au- tonomous driving framework by vision-language instructed action generation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 24 823–24 834
2025
-
[2]
Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving,
S. Zeng, X. Chang, M. Xie, X. Liu, Y . Bai, Z. Pan, M. Xu, X. Wei, and N. Guo, “Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving,”arXiv preprint arXiv:2505.17685, 2025
Pith/arXiv arXiv 2025
-
[3]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., “Language models are few-shot learners,”Advances in neural information pro- cessing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[4]
Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi,et al., “Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[5]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[6]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge,et al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[7]
Recogdrive: A reinforced cog- nitive framework for end-to-end autonomous driving,
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang,et al., “Recogdrive: A reinforced cog- nitive framework for end-to-end autonomous driving,”arXiv preprint arXiv:2506.08052, 2025
Pith/arXiv arXiv 2025
-
[8]
Z. Zhou, T. Cai, S. Z. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma, “Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning,”arXiv preprint arXiv:2506.13757, 2025
Pith/arXiv arXiv 2025
-
[9]
M. Xu, J. Cui, F. Cai, H. Shang, Z. Zhu, S. Luan, Y . Xu, N. Zhang, Y . Li, J. Cai,et al., “Wam-diff: A masked diffusion vla framework with moe and online reinforcement learning for autonomous driving,” arXiv preprint arXiv:2512.11872, 2025
arXiv 2025
-
[10]
Sgdrive: Scene-to-goal hierarchical world cognition for autonomous driving,
J. Li, J. Wu, D. Hu, X. Huang, B. Sun, Z. Hao, X. Lang, X. Zhu, and L. Zhang, “Sgdrive: Scene-to-goal hierarchical world cognition for autonomous driving,”arXiv preprint arXiv:2601.05640, 2026
arXiv 2026
-
[11]
Drivelm: Driving with graph visual question answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual question answering,” inEuropean conference on computer vision. Springer, 2024, pp. 256–274
2024
-
[12]
Rap: 3d rasterization augmented end-to-end planning,
L. Feng, Y . Gao, E. Zablocki, Q. Li, W. Li, S. Liu, M. Cord, and A. Alahi, “Rap: 3d rasterization augmented end-to-end planning,” arXiv preprint arXiv:2510.04333, 2025
arXiv 2025
-
[13]
Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms,
L. Meng, J. Yang, R. Tian, X. Dai, Z. Wu, J. Gao, and Y .-G. Jiang, “Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms,”Advances in Neural Information Processing Systems, vol. 37, pp. 23 464–23 487, 2024
2024
-
[14]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[15]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, G. Drettakis,et al., “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[16]
Domain-adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Lavi- olette, M. March, and V . Lempitsky, “Domain-adversarial training of neural networks,”Journal of machine learning research, vol. 17, no. 59, pp. 1–35, 2016
2016
-
[17]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu,et al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[18]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone,et al., “Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 28 706– 28 719, 2024
2024
-
[19]
Pseudo-simulation for autonomous driving,
W. Cao, M. Hallgarten, T. Li, D. Dauner, X. Gu, C. Wang, Y . Miron, M. Aiello, H. Li, I. Gilitschenski,et al., “Pseudo-simulation for autonomous driving,”arXiv preprint arXiv:2506.04218, 2025
arXiv 2025
-
[20]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving,
X. Jia, Z. Yang, Q. Li, Z. Zhang, and J. Yan, “Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving,”Advances in Neural Information Processing Systems, vol. 37, pp. 819–844, 2024
2024
-
[21]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022
2022
-
[22]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang,et al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[23]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8340–8350
2023
-
[24]
Sparsedrive: End-to-end autonomous driving via sparse scene representation,
W. Sun, X. Lin, Y . Shi, C. Zhang, H. Wu, and S. Zheng, “Sparsedrive: End-to-end autonomous driving via sparse scene representation,” in 2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 8795–8801
2025
-
[25]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang,et al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 037–12 047
2025
-
[26]
Goalflow: Goal-driven flow matching for multimodal trajec- tories generation in end-to-end autonomous driving,
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin, “Goalflow: Goal-driven flow matching for multimodal trajec- tories generation in end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1602–1611
2025
-
[27]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyals,et al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[28]
Bev- former: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bev- former: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2020–2036, 2024
2020
-
[29]
S. Zagoruyko and N. Komodakis, “Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer,”arXiv preprint arXiv:1612.03928, 2016
Pith/arXiv arXiv 2016
-
[30]
Para- drive: Parallelized architecture for real-time autonomous driving,
X. Weng, B. Ivanovic, Y . Wang, Y . Wang, and M. Pavone, “Para- drive: Parallelized architecture for real-time autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 449–15 458
2024
-
[31]
End-to-end driving with online trajectory evaluation via bev world model,
Y . Li, Y . Wang, Y . Liu, J. He, L. Fan, and Z. Zhang, “End-to-end driving with online trajectory evaluation via bev world model,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 27 137–27 146
2025
-
[32]
Qwen2.5-vl technical report,
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,”
-
[33]
Available: https://arxiv.org/abs/2502.13923
[Online]. Available: https://arxiv.org/abs/2502.13923
-
[34]
$autodrive\text{-}pˆ3$: Unified chain of percep- tion–prediction–planning thought via reinforcement fine-tuning,
Y . Ye, Z. Zhang, J. Lin, S. Sun, C. Peng, and W. Gao, “$autodrive\text{-}pˆ3$: Unified chain of percep- tion–prediction–planning thought via reinforcement fine-tuning,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/ forum?id=CMU8GxwpUL
2026
-
[35]
Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes,
J.-T. Zhai, Z. Feng, J. Du, Y . Mao, J.-J. Liu, Z. Tan, Y . Zhang, X. Ye, and J. Wang, “Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes,”arXiv preprint arXiv:2305.10430, 2023
Pith/arXiv arXiv 2023
-
[36]
Carla: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “Carla: An open urban driving simulator,” inConference on robot learning. PMLR, 2017, pp. 1–16
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.