A Benchmark for Hallucination Detection in VLMs for Gastrointestinal Endoscopy
Pith reviewed 2026-06-26 01:52 UTC · model grok-4.3
The pith
White-box method ReXTrust outperforms alternatives at detecting hallucinations in GI endoscopy VLMs
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
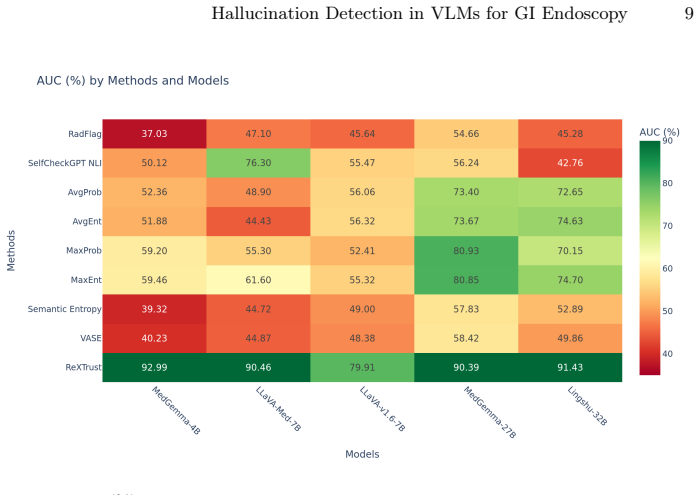
ReXTrust, a white-box method, achieves the highest AUC across all five models, outperforming the strongest alternative method on each VLM by a statistically significant margin (paired permutation test, p < 0.001 in all cases), reaching a peak AUC of 93.0 on MedGemma-4B. White-box hidden-state access provides a consistent advantage of 19.5 AUC points on average. Among non-white-box methods, token-level gray-box statistics (MaxEnt, MaxProb) are the strongest alternatives. The work further identifies confident confabulation as a systemic failure for both consistency and uncertainty-based methods.
What carries the argument
ReXTrust, a white-box hallucination detector that uses access to internal hidden states of the VLM
If this is right
- White-box hidden-state access should be prioritized when reliable hallucination detection is required for medical VLMs.
- Token-level probability and entropy statistics serve as the best practical fallback when internal states are unavailable.
- Confident confabulation limits the reliability of black-box and clustering-based detectors on this task.
- Performance gaps between methods widen on weaker base models such as LLaVA-v1.6-7B.
- The Gut-VLM dataset supplies a targeted benchmark for evaluating hallucination detectors in gastrointestinal endoscopy.
Where Pith is reading between the lines
- White-box advantages observed here may extend to other clinical VLM applications such as radiology or pathology.
- Integrating ReXTrust-style detectors into clinical workflows could reduce the risk of acting on hallucinated outputs during endoscopy procedures.
- New detection techniques may be needed to handle confident confabulation cases that current methods miss.
- The benchmark could be extended to video-based endoscopy sequences to test temporal consistency of detections.
Load-bearing premise
The Gut-VLM test VQA pairs carry reliable ground-truth labels for hallucinations and the five VLMs plus nine detection methods were implemented without systematic bias.
What would settle it
Re-labeling a random subset of the 4,392 Gut-VLM pairs by independent clinicians and re-computing all AUCs to check whether the reported ranking of ReXTrust versus the other eight methods reverses.
Figures



read the original abstract
Vision-language models (VLMs) are prone to hallucination, which remains a major barrier to their safe deployment in clinical practice. To date, most hallucination detection methods have been evaluated on radiology benchmarks such as MIMIC-CXR and VQA-RAD, while gastrointestinal (GI) endoscopy remains largely underexplored. In this paper, we benchmark nine hallucination detection methods on the Gut-VLM dataset, a GI diagnostic Visual Question Answering (VQA) dataset with 4,392 test VQA pairs, across five VLMs (MedGemma-4B, MedGemma-27B, LLaVA-Med-7B, LLaVA-v1.6-7B, and Lingshu-32B). The methods span three categories: black-box methods (RadFlag, SelfCheckGPT-NLI), gray-box methods (AvgProb, AvgEnt, MaxProb, MaxEnt, Semantic Entropy, and VASE), and a white-box method (ReXTrust). Our results show that ReXTrust, a white-box method, achieves the highest AUC across all five models, outperforming the strongest alternative method on each VLM by a statistically significant margin (paired permutation test, p < 0.001 in all cases), reaching a peak AUC of 93.0 on MedGemma-4B. White-box hidden-state access provides a consistent advantage of 19.5 AUC points on average (range: 9.5--33.5), with ReXTrust maintaining strong performance even on LLaVA-v1.6-7B (AUC 79.9), where black-box methods and clustering-based gray-box methods collapse to near-chance performance. Among non-white-box methods, token-level gray-box statistics (MaxEnt, MaxProb) are the strongest alternatives, outperforming both clustering-based gray-box methods (Semantic Entropy, VASE) and black-box approaches on average. We further identify confident confabulation, a failure mode in which models hallucinate with high inter-sample consistency or high token-level probability, as a systemic failure for both consistency and uncertainty-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks nine hallucination detection methods (black-box: RadFlag, SelfCheckGPT-NLI; gray-box: AvgProb, AvgEnt, MaxProb, MaxEnt, Semantic Entropy, VASE; white-box: ReXTrust) on the Gut-VLM GI endoscopy VQA dataset (4,392 test pairs) across five VLMs (MedGemma-4B/27B, LLaVA-Med-7B, LLaVA-v1.6-7B, Lingshu-32B). It claims ReXTrust attains the highest AUC on all models (peak 93.0 on MedGemma-4B), outperforming the strongest non-white-box alternative on each VLM by a statistically significant margin via paired permutation tests (p < 0.001), with white-box access conferring a 19.5 AUC point average advantage (range 9.5–33.5). Token-level gray-box statistics outperform clustering-based gray-box and black-box methods on average, and the work identifies 'confident confabulation' as a systemic failure mode for consistency- and uncertainty-based detectors.
Significance. If the ground-truth labels are shown to be reliable, the results would be significant by delivering the first systematic hallucination-detection benchmark in the clinically important but underexplored GI endoscopy domain. The consistent, statistically tested superiority of white-box hidden-state methods and the identification of confident confabulation supply concrete guidance for detector selection in safety-critical settings. The multi-VLM evaluation and introduction of the Gut-VLM test set enhance reproducibility and domain coverage.
major comments (1)
- [Dataset section] Dataset section (description of Gut-VLM construction): The protocol for producing ground-truth hallucination labels on the 4,392 test VQA pairs is not described. No information is supplied on annotator qualifications, number of annotators, inter-rater agreement, or the operational definition of hallucination in the GI context. Because the reported AUC values, 19.5-point advantage, and p < 0.001 claims rest directly on label accuracy, this omission is load-bearing for the central empirical claims.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the importance of transparent dataset construction details. We agree that the current manuscript lacks sufficient description of the ground-truth labeling protocol for Gut-VLM, which is critical for supporting the reported AUC results and statistical claims. We will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Dataset section] Dataset section (description of Gut-VLM construction): The protocol for producing ground-truth hallucination labels on the 4,392 test VQA pairs is not described. No information is supplied on annotator qualifications, number of annotators, inter-rater agreement, or the operational definition of hallucination in the GI context. Because the reported AUC values, 19.5-point advantage, and p < 0.001 claims rest directly on label accuracy, this omission is load-bearing for the central empirical claims.
Authors: We acknowledge that the Dataset section in the submitted manuscript does not provide the requested details on how the 4,392 ground-truth hallucination labels were generated. This information is necessary to allow readers to assess label reliability. In the revised version, we will expand the Dataset section with: the operational definition of hallucination applied in the GI endoscopy VQA setting; the number of annotators and their qualifications (e.g., clinical expertise in gastroenterology); the full annotation protocol; and quantitative inter-rater agreement statistics. These additions will directly support the validity of the benchmark results and the statistical comparisons. revision: yes
Circularity Check
Pure empirical benchmark; no derivations or self-referential predictions
full rationale
The paper is a direct empirical comparison of nine hallucination detection methods (black-box, gray-box, white-box) on the Gut-VLM VQA dataset across five VLMs, reporting AUC values, paired permutation tests, and average advantages. No equations, fitted parameters presented as predictions, ansatzes, or derivation chains appear in the abstract or described content. Central claims rest on implementation and evaluation of external methods against ground-truth labels rather than any self-definition or self-citation reduction. This is the most common honest finding for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arnold, M., Abnet, C.C., Neale, R.E., Vignat, J., Giovannucci, E.L., McGlynn, K.A., Bray, F.: Global burden of 5 major types of gastrointestinal cancer. Gastroenterology (2020). https://doi.org/10.1053/j.gastro.2020.02.068 14 A. Lawal et al
-
[2]
The Internal State of an LLM Knows When It's Lying
Azaria, A., Mitchell, T.M.: The internal state of an llm knows when its lying. ArXiv abs/2304.13734(2023). https://doi.org/10.18653/v1/2023.findings-emnlp.68
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.findings-emnlp.68 2023
-
[3]
Detecting hallucinations in large language models using semantic entropy , volume =
Farquhar, S., Kossen, J., Kuhn, L., Gal, Y.: Detecting halluci- nations in large language models using semantic entropy. Nature 630(8017), 625–630 (2024). https://doi.org/10.1038/s41586-024-07421-0, https://www.nature.com/articles/s41586-024-07421-0
-
[4]
In: 2024 7th International Conference on Universal Village (UV)
Gu, C., Zhang, W., Huang, Z., et al.: Lens: Layers of evaluation of hallucination in genai systems. In: 2024 7th International Conference on Universal Village (UV). pp. 1–85 (2024). https://doi.org/10.1109/UV63228.2024.11189150
-
[5]
In: Wu, J., Zhu, J., Xu, M., Jin, Y
Hardy, R., Kim, S.E., Ro, D.H., Rajpurkar, P.: Rextrust: A model for fine-grained hallucination detection in ai-generated radiology reports. In: Wu, J., Zhu, J., Xu, M., Jin, Y. (eds.) Proceedings of The First AAAI Bridge Program on AI for Medicine and Healthcare. Proceedings of Machine Learning Research, vol. 281, pp. 173–182. PMLR (25 Feb 2025), https:/...
2025
-
[6]
He, P., Gao, J., Chen, W.: Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing. In: Proceedings of the 11th International Conference on Learning Representations (ICLR) (2023), https://arxiv.org/abs/2111.09543, arXiv:2111.09543
Pith/arXiv arXiv 2023
-
[7]
arXiv preprintarXiv:2003.10286(2020), https://arxiv.org/abs/2003.10286
He, X., Zhang, Y., Mou, L., Xing, E., Xie, P.: Pathvqa: 30000+ questions for medical visual question answering. arXiv preprintarXiv:2003.10286(2020), https://arxiv.org/abs/2003.10286
Pith/arXiv arXiv 2003
-
[8]
arXiv preprintarXiv:1901.07042 (2019), https://arxiv.org/abs/1901.07042
Johnson, A.E.W., Pollard, T.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Peng, Y., Lu, Z., Mark, R.G., Berkowitz, S.J., Horng, S.: Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs. arXiv preprintarXiv:1901.07042 (2019), https://arxiv.org/abs/1901.07042
Pith/arXiv arXiv 1901
-
[9]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Khanal, B., Pokhrel, S., Bhandari, S., et al.: Hallucination-aware multimodal benchmark for gastrointestinal image analysis with large vision-language models. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 235–245. Springer (2025)
2025
-
[10]
Scientific Data5, 180251 (2018).https://doi.org/10.1038/sdata.2018.251
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific Data5(1), 180251 (2018). https://doi.org/10.1038/sdata.2018.251, https://www.nature.com/articles/sdata2018251
-
[11]
arXiv preprintarXiv:2306.00890(2023), https://arxiv.org/abs/2306.00890
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assis- tant for biomedicine in one day. arXiv preprintarXiv:2306.00890(2023), https://arxiv.org/abs/2306.00890
Pith/arXiv arXiv 2023
-
[12]
In: Findings of the Association for Com- putational Linguistics: EMNLP 2024
Li,Q.,Geng,J.,Lyu,C.,Zhu,D.,Panov,M.,Karray,F.:Reference-freehallucination detection for large vision-language models. In: Findings of the Association for Com- putational Linguistics: EMNLP 2024. pp. 4542–4551. Association for Computational Linguistics,Miami,Florida,USA(2024).https://doi.org/10.18653/v1/2024.findings- emnlp.262, https://aclanthology.org/2...
-
[13]
Novel Pathways ink-Contact Geometry
Liao, Z., Hu, S., Zou, K., Fu, H., Zhen, L., Xia, Y.: Vision-amplified semantic entropy for hallucination detection in medical visual question answering. In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2025. Lecture Notes in Computer Science, vol. 15964. Springer (2025). https://doi.org/10.1007/978-3-032- 04971-1_63
-
[14]
In: Hallucination Detection in VLMs for GI Endoscopy 15 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI)
Liu, B., Zhan, L., Xu, L., Ma, L., Yang, Y., Wu, X.: Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In: Hallucination Detection in VLMs for GI Endoscopy 15 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI). pp. 1650–
2021
-
[15]
URLhttps://doi.org/10.1109/ ISBI48211.2021.9434010
IEEE, Nice, France (2021). https://doi.org/10.1109/ISBI48211.2021.9434010, https://ieeexplore.ieee.org/document/9434010
-
[16]
In: Advances in Neural Information Processing Systems (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: Advances in Neural Information Processing Systems (2023)
2023
-
[17]
Manakul, P., Liusie, A., Gales, M.: Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. In: Proceed- ings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing. pp. 9004–9017. Association for Computational Lin- guistics, Singapore (2023). https://doi.org/10.18653/v1/2023.emnlp-main.557...
-
[18]
Mota, J., Almeida, M.J., Mendes, F., et al.: A comprehensive review of artificial intelligence and colon capsule endoscopy: Opportunities and challenges. Diagnostics 14(2024). https://doi.org/10.3390/diagnostics14182072
-
[19]
Chaudhari, and Jean-Benoit Delbrouck
Ostmeier, S., Xu, J., Chen, Z., Varma, M., Blankemeier, L., Blueth- gen, C., Michalson, A.E., Moseley, M., Langlotz, C., Chaudhari, A.S., Delbrouck, J.: Green: Generative radiology report evaluation and error notation. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 374–390. Association for Computational Linguistics, Mi- ami...
-
[20]
Proceedings of the 8th ACM on Multimedia Systems Conference , pages =
Pogorelov, K., Randel, K.R., Griwodz, C., et al.: Kvasir: A multi-class image- dataset for computer aided gastrointestinal disease detection. In: Proceed- ings of the 8th ACM Multimedia Systems Conference. ACM, Taiwan (2017). https://doi.org/10.1145/3083187.3083212
-
[21]
Sawczyn, A., Binkowski, J., Janiak, D., Gabrys, B., Kajdanowicz, T.: Factselfcheck: Fact-level black-box hallucination detection for llms (2025), https://arxiv.org/abs/2503.17229
arXiv 2025
-
[22]
arXiv preprintarXiv:2507.05201(2025), https://arxiv.org/abs/2507.05201
Sellergren, A., Kazemzadeh, S., Jaroensri, T., et al.: Medgemma technical report. arXiv preprintarXiv:2507.05201(2025), https://arxiv.org/abs/2507.05201
Pith/arXiv arXiv 2025
-
[23]
ACM Computing Surveys57(4), 1– 42 (2025)
Shorinwa, O., Mei, Z., Lidard, J., Ren, A.Z., Majumdar, A.: A survey on uncertainty quantification of large language models: Taxonomy, open re- search challenges, and future directions. ACM Computing Surveys57(4), 1– 42 (2025). https://doi.org/10.1145/3744238, https://doi.org/10.1145/3744238, arXiv:2412.05563
-
[24]
arXiv preprint arXiv:2506.07044 (2025)
Xu, W., Chan, H.P., et al.: Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044 (2025)
Pith/arXiv arXiv 2025
-
[25]
In: Proceedings of the 4th Machine Learning for Health Symposium
Zhang, S., Sambara, S., Banerjee, O., Acosta, J.N., Fahrner, L.J., Rajpurkar, P.: Radflag: A black-box hallucination detection method for medical vision language models. In: Proceedings of the 4th Machine Learning for Health Symposium. Proceedings of Machine Learning Research, vol. 259, pp. 1087–1103. PMLR (15–16 Dec 2025), https://proceedings.mlr.press/v...
2025
-
[26]
Proceedings of the 33rd ACM International Conference on Multimedia (2024)
Zhang, Y., Xie, R., Sun, X., et al.: Dhcp: Detecting hallucinations by cross-modal attention pattern in large vision-language models. Proceedings of the 33rd ACM International Conference on Multimedia (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.