Data Scale, Not Latency, Shapes Cross-Lingual Encoder Transfer in Streaming ASR
Pith reviewed 2026-06-26 00:14 UTC · model grok-4.3
The pith
Multilingual encoder initialization for streaming ASR provides a shrinking advantage that depends on target data volume rather than latency constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
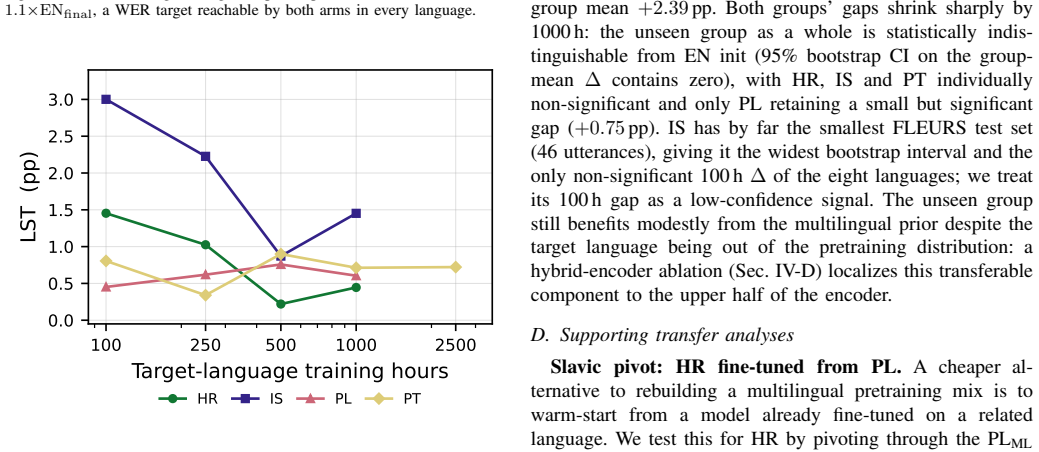
Multilingual initialization is a data-limited advantage, not a latency-limited one. On FLEURS at 160 ms the mean EN-ML WER gap falls from +4.21 percentage points at 100 h to +0.20 pp at 2500 h; a power-law fit summarizes this decay, with each doubling of target-language data roughly halving the remaining advantage. Across the three streaming tiers, the across-language mean EN-ML gap is approximately stable at each scale from 100 to 1000 h, and is near zero by 2500 h. 4-bit weight-only encoder quantization at the matched 560 ms streaming tier reduces the encoder footprint by about 3x, with an average FLEURS WER increase of about 0.5 pp.
What carries the argument
Controlled sweep of a 0.6 B-parameter cache-aware FastConformer transducer across target-language data scales, streaming tiers, and quantization.
If this is right
- Multilingual initialization should be chosen when target data is limited to a few hundred hours.
- At 2500 hours the initialization choice becomes effectively irrelevant for word error rate.
- Streaming latency settings can be selected without regard to whether the encoder started multilingual or English-only.
- 4-bit weight-only quantization can be applied independently to shrink the model while accepting a small accuracy cost.
Where Pith is reading between the lines
- The same data-scale dependence could appear in adaptation for other sequence tasks if data volume dominates over pretraining differences.
- Engineering effort at large scale might shift from multilingual pretraining toward targeted data collection for each language.
- The orthogonality of latency, quantization, and initialization choices simplifies modular deployment pipelines for streaming models.
Load-bearing premise
Target-language data volume is the main driver of the initialization gap, without strong interactions from language similarity, acoustics, or test-set difficulty.
What would settle it
A replication in which the mean EN-ML WER gap stays large at 2500 hours or changes markedly across streaming tiers at fixed data scale would falsify the central claim.
Figures


read the original abstract
Adapting a streaming speech recognition model to a new language requires choosing between two plausible warm starts: a multilingual (ML) encoder or an English-only (EN) encoder. The common intuition is that the multilingual encoder should help most at low data, but it is unclear how long that advantage persists, whether tight streaming latency amplifies it, and whether it survives deployment quantization. We answer these questions with a controlled sweep of a 0.6 B-parameter cache-aware FastConformer transducer across eight European languages, up to five target-language data scales (100 h to 2500 h), three streaming tiers plus offline decoding, and up to four public test sets. The main result is that multilingual initialization is a data-limited advantage, not a latency-limited one. On FLEURS at 160 ms, the mean EN-ML word error rate (WER) gap falls from +4.21 percentage points (pp) at 100 h to +0.20 pp at 2500 h; a power-law fit summarizes this decay, with each doubling of target-language data roughly halving the remaining advantage. Across the three streaming tiers, the across-language mean EN-ML gap is approximately stable at each scale from 100 to 1000 h, and is near zero by 2500 h. Finally, 4-bit weight-only encoder quantization at the matched 560 ms streaming tier reduces the encoder footprint by about 3x, with an average FLEURS WER increase of about 0.5 pp. The resulting guideline is simple: use multilingual initialization in low-data regimes, treat the choice as effectively irrelevant at large data, and make latency and quantization decisions independently.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled empirical study of cross-lingual encoder transfer for streaming ASR using a 0.6B-parameter cache-aware FastConformer transducer. Across eight European languages, five target data scales (100 h to 2500 h), three streaming latency tiers plus offline, and multiple test sets, it reports that the EN-ML WER gap decays with target-language data volume (e.g., mean gap on FLEURS at 160 ms falls from +4.21 pp at 100 h to +0.20 pp at 2500 h) according to a power-law summary, while the gap remains approximately stable across streaming tiers at each fixed scale and approaches zero at large scale. It further shows that 4-bit weight-only quantization at matched latency reduces encoder size ~3x with ~0.5 pp average WER increase, yielding the guideline to use ML initialization only in low-data regimes and to treat latency/quantization choices independently.
Significance. If the empirical pattern holds, the work supplies a practical, data-scale-based decision rule for multilingual vs. monolingual warm-start selection in streaming ASR adaptation. The controlled separation of data-volume effects from latency effects, together with the quantization result, offers a falsifiable guideline that can inform low-resource deployment without requiring new theoretical machinery.
major comments (2)
- [Abstract / Methods] Abstract and Methods summary: the claim that data volume is the dominant driver (and that language similarity/acoustic conditions/test-set difficulty do not systematically interact with initialization) is load-bearing for the data-vs-latency distinction, yet the provided description gives no per-language breakdowns, similarity controls, or ablation confirming the trend is unaltered by these factors.
- [Results] Results (power-law and tier-stability claims): error bars, standard deviations across languages or runs, exact data-exclusion rules, and the fitted power-law coefficient or goodness-of-fit are not reported; without them the quantitative decay and cross-tier stability cannot be verified as robust rather than post-hoc.
minor comments (1)
- [Abstract] Abstract: the power-law description ('each doubling roughly halving the advantage') is qualitative; stating the fitted exponent or R² would make the summary more precise and reproducible.
Simulated Author's Rebuttal
We thank the referee for the careful review and the minor revision recommendation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods summary: the claim that data volume is the dominant driver (and that language similarity/acoustic conditions/test-set difficulty do not systematically interact with initialization) is load-bearing for the data-vs-latency distinction, yet the provided description gives no per-language breakdowns, similarity controls, or ablation confirming the trend is unaltered by these factors.
Authors: The main claims rely on cross-language means, which already show consistent decay independent of latency tier. To directly address potential interactions with language similarity or test-set factors, the revision will add per-language WER breakdowns and note any deviations from the mean trend. No explicit similarity controls were performed, as all languages are European, but the uniformity of the data-scale effect across scales supports treating data volume as dominant. revision: yes
-
Referee: [Results] Results (power-law and tier-stability claims): error bars, standard deviations across languages or runs, exact data-exclusion rules, and the fitted power-law coefficient or goodness-of-fit are not reported; without them the quantitative decay and cross-tier stability cannot be verified as robust rather than post-hoc.
Authors: We agree these details are needed for verification. The revision will add standard deviations across languages to the mean gaps, error bars to figures, explicit data-exclusion criteria, and the fitted power-law coefficient with goodness-of-fit (e.g., R²). revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports results from a controlled empirical sweep of a 0.6B FastConformer transducer across eight languages, five data scales, three streaming tiers, and multiple public test sets. All load-bearing claims (EN-ML WER gap decay with scale, stability across tiers at fixed scale) are direct quantitative observations from measured word error rates; the power-law fit is explicitly described as a summary of the observed decay rather than a derivation. No equations, self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the reported methodology or results. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- power-law decay coefficient
axioms (1)
- domain assumption Target-language data volume is the primary variable controlling the EN-ML initialization gap after controlling for model architecture and training procedure.
Reference graph
Works this paper leans on
-
[1]
Conformer: Convolution- augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, et al., “Conformer: Convolution- augmented transformer for speech recognition,” inProc. Interspeech, 2020, pp. 5036–5040
2020
-
[2]
Fast Conformer with lin- early scalable attention for efficient speech recognition,
D. Rekesh, N. R. Koluguri, S. Kriman, et al., “Fast Conformer with lin- early scalable attention for efficient speech recognition,” inProc. ASRU, 2023, pp. 1–8
2023
-
[3]
Stateful conformer with cache-based inference for streaming automatic speech recognition,
V . Noroozi, S. Majumdar, A. Kumar, et al., “Stateful conformer with cache-based inference for streaming automatic speech recognition,” in Proc. ICASSP, 2024, pp. 12041–12045
2024
-
[4]
Transfer learning approaches for streaming end-to-end speech recognition system,
V . Joshi, R. Zhao, R. R. Mehta, K. Kumar, and J. Li, “Transfer learning approaches for streaming end-to-end speech recognition system,” in Proc. Interspeech, 2020, pp. 2152–2156
2020
-
[5]
Towards scalable efficient on-device ASR with transfer learning,
L. Pandey, K. Li, J. Guo, D. Paul, A. Guo, J. Mahadeokar, and X. Zhang, “Towards scalable efficient on-device ASR with transfer learning,” arXiv:2407.16664, 2024
-
[6]
Un- supervised cross-lingual representation learning for speech recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Un- supervised cross-lingual representation learning for speech recognition,” inProc. Interspeech, 2021, pp. 2426–2430
2021
-
[7]
Google USM: Scaling automatic speech recognition beyond 100 languages,
Y . Zhang, W. Han, J. Qin, et al., “Google USM: Scaling automatic speech recognition beyond 100 languages,” arXiv:2303.01037, 2023
-
[8]
Sequence Transduction with Recurrent Neural Networks
A. Graves, “Sequence transduction with recurrent neural networks,” arXiv:1211.3711, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[9]
Large-scale multilingual speech recognition with a streaming end-to-end model,
A. Kannan, A. Datta, T. Sainath, et al., “Large-scale multilingual speech recognition with a streaming end-to-end model,” inProc. Interspeech, 2019, pp. 2130–2134
2019
-
[10]
Scaling end-to-end models for large-scale multilingual ASR,
B. Li, R. Pang, T. N. Sainath, et al., “Scaling end-to-end models for large-scale multilingual ASR,” inProc. ASRU, 2021, pp. 1011–1018
2021
-
[11]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, et al., “Scaling speech technology to 1,000+ languages,”J. Mach. Learn. Res., vol. 25, no. 97, pp. 1–52, 2024
2024
-
[12]
OWLS: Scaling laws for multilingual speech recognition and translation models,
W. Chen, J. Tian, Y . Peng, B. Yan, C.-H. H. Yang, and S. Watanabe, “OWLS: Scaling laws for multilingual speech recognition and translation models,” inProc. ICML, 2025, pp. 9121–9145
2025
-
[13]
Scaling laws for acoustic models,
J. Droppo and O. Elibol, “Scaling laws for acoustic models,” in Proc. Interspeech, 2021, pp. 2576–2580
2021
-
[14]
D. Hernandez, J. Kaplan, T. Henighan, and S. McCandlish, “Scaling laws for transfer,” arXiv:2102.01293, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Cascaded encoders for unifying streaming and non-streaming ASR,
A. Narayanan, T. N. Sainath, R. Pang, et al., “Cascaded encoders for unifying streaming and non-streaming ASR,” inProc. ICASSP, 2021, pp. 5629–5633
2021
-
[16]
Nemo: a toolkit for building ai applications using neural modules,
O. Kuchaiev, J. Li, H. Nguyen, et al., “NeMo: A toolkit for building AI applications using neural modules,” arXiv:1909.09577, 2019
-
[17]
Nemotron-Speech-Streaming-En-0.6B,
NVIDIA, “Nemotron-Speech-Streaming-En-0.6B,” Hugging Face model card. [Online]. Available: https://huggingface.co/nvidia/ nemotron-speech-streaming-en-0.6b, accessed Jun. 11, 2026
2026
-
[18]
Neural machine translation of rare words with subword units,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” inProc. ACL, 2016, pp. 1715–1725
2016
-
[19]
Parakeet-TDT-0.6B-v3,
NVIDIA, “Parakeet-TDT-0.6B-v3,” Hugging Face model card. [Online]. Available: https://huggingface.co/nvidia/parakeet-tdt-0.6b-v3, accessed Jun. 11, 2026
2026
-
[20]
Common V oice: A massively- multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, et al., “Common V oice: A massively- multilingual speech corpus,” inProc. LREC, 2020, pp. 4218–4222
2020
-
[21]
MLS: A large-scale multilingual dataset for speech research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A large-scale multilingual dataset for speech research,” inProc. Inter- speech, 2020, pp. 2757–2761
2020
-
[22]
V oxPopuli: A large-scale multilin- gual speech corpus for representation learning, semi-supervised learning and interpretation,
C. Wang, A. Riviere, A. Lee, et al., “V oxPopuli: A large-scale multilin- gual speech corpus for representation learning, semi-supervised learning and interpretation,” inProc. ACL-IJCNLP, 2021, pp. 993–1003
2021
-
[23]
CML-TTS: A multilingual dataset for speech synthesis in low-resource languages,
F. S. Oliveira, E. Casanova, A. C ˆandido J ´unior, A. S. Soares, and A. R. Galv ˜ao Filho, “CML-TTS: A multilingual dataset for speech synthesis in low-resource languages,” inText, Speech, and Dialogue, 2023, pp. 188–199
2023
-
[24]
Granary: Speech recognition and translation dataset in 25 European languages,
N. Rao Koluguri, M. Sekoyan, G. Zelenfroynd, et al., “Granary: Speech recognition and translation dataset in 25 European languages,” in Proc. Interspeech, 2025, pp. 3923–3927
2025
-
[25]
ParlaSpeech- HR: A freely available ASR dataset for Croatian bootstrapped from the ParlaMint corpus,
N. Ljube ˇsi´c, D. Kor ˇzinek, P. Rupnik, and I.-P. Jazbec, “ParlaSpeech- HR: A freely available ASR dataset for Croatian bootstrapped from the ParlaMint corpus,” inProc. Workshop ParlaCLARIN III at LREC, 2022, pp. 111–116
2022
-
[26]
Building an ASR corpus using Althingi’s parliamentary speeches,
I. R. Helgad ´ottir, R. Kjaran, A. B. Nikulasdottir, and J. Gudnason, “Building an ASR corpus using Althingi’s parliamentary speeches,” in Proc. Interspeech, 2017, pp. 2163–2167
2017
-
[27]
Samr ´omur: Crowd-sourcing data collection for Icelandic speech recognition,
D. E. Mollberg, ´O. H. J ´onsson, S. Thorsteinsd ´ottir, S. Steingr ´ımsson, E. H. Magn ´usd´ottir, and J. Gudnason, “Samr ´omur: Crowd-sourcing data collection for Icelandic speech recognition,” inProc. LREC, 2020, pp. 3463–3467
2020
-
[28]
M´alr´omur: A manually verified corpus of recorded Icelandic speech,
S. Steingr ´ımsson, J. Gudnason, S. Helgad ´ottir, and E. R ¨ognvaldsson, “M´alr´omur: A manually verified corpus of recorded Icelandic speech,” inProc. NODALIDA, 2017, pp. 237–240
2017
-
[29]
FLEURS: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, et al., “FLEURS: Few-shot learning evaluation of universal representations of speech,” inProc. SLT, 2023, pp. 798–805
2023
-
[30]
Open ASR Leaderboard
Hugging Face, “Open ASR Leaderboard.” [Online]. Available: https: //github.com/huggingface/open asr leaderboard, accessed Jun. 12, 2026
2026
-
[31]
Bootstrap estimates for confidence intervals in ASR performance evaluation,
M. Bisani and H. Ney, “Bootstrap estimates for confidence intervals in ASR performance evaluation,” inProc. ICASSP, 2004, vol. 1, pp. I-409– I-412
2004
-
[32]
FastEmit: Low-latency streaming ASR with sequence-level emission regularization,
J. Yu, C.-C. Chiu, B. Li, et al., “FastEmit: Low-latency streaming ASR with sequence-level emission regularization,” inProc. ICASSP, 2021, pp. 6004–6008
2021
-
[33]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. ICLR, 2019
2019
-
[34]
SpecAugment: A simple data augmentation method for automatic speech recognition,
D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le, “SpecAugment: A simple data augmentation method for automatic speech recognition,” inProc. Interspeech, 2019, pp. 2613– 2617
2019
-
[35]
Nemotron-3.5-ASR-Streaming-0.6B,
NVIDIA, “Nemotron-3.5-ASR-Streaming-0.6B,” Hugging Face model card. [Online]. Available: https://huggingface.co/nvidia/nemotron-3. 5-asr-streaming-0.6b, accessed Jun. 12, 2026
2026
-
[36]
Layer-wise analysis of a self- supervised speech representation model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self- supervised speech representation model,” inProc. ASRU, 2021, pp. 914– 921
2021
-
[37]
SUPERB: Speech pro- cessing universal performance benchmark,
S.-w. Yang, P.-H. Chi, Y .-S. Chuang, et al., “SUPERB: Speech pro- cessing universal performance benchmark,” inProc. Interspeech, 2021, pp. 1194–1198
2021
-
[38]
ONNX Runtime: cross-platform accelerated machine learn- ing
Microsoft, “ONNX Runtime: cross-platform accelerated machine learn- ing.” [Online]. Available: https://onnxruntime.ai, accessed Jun. 12, 2026
2026
-
[39]
N. Banfic, D. Fan, et al., “Pushing the limits of on-device streaming ASR: A compact, high-accuracy English model for low-latency infer- ence,” arXiv:2604.14493, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
onnxruntime-genai: Generative AI extensions for ONNX Runtime
Microsoft, “onnxruntime-genai: Generative AI extensions for ONNX Runtime.” [Online]. Available: https://github.com/microsoft/ onnxruntime-genai, accessed Jun. 12, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.