Pigeonholing: Bad prompts hurt models to collapse and make mistakes
Pith reviewed 2026-06-26 00:20 UTC · model grok-4.3
The pith
Bad contexts cause LLMs to repeat incorrect answers from conversations, leading to 38-40% performance drops and mode collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
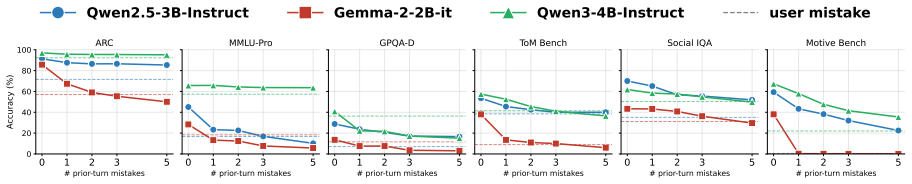
Pigeonholing manifests as repeating incorrect answers from context (38-40% performance drop), converging on narrow sets of answers, and flipping stances to align with context, worsening monotonically with conversation turns by an additional 14%, even when examples are correct, and can be mitigated by RLVR with synthetic errors improving 43-60%.
What carries the argument
Pigeonholing, the tendency of LLMs to stick to and repeat errors present in the conversation context rather than exploring or correcting.
If this is right
- Repeating incorrect answers leads to 38-40% performance drop on verifiable tasks.
- Mode collapse causes convergence on narrow answers in coding and text generation.
- Stance flipping occurs on controversial topics to match user or previous claims.
- Performance drops further by 14% as repeated mistakes increase from 1 to 5 turns.
- RLVR with synthetic errors mitigates the effect, improving by 43-60% under bad contexts.
Where Pith is reading between the lines
- Models may need explicit training to detect and override context errors rather than defaulting to them.
- User interfaces could warn when contexts suggest incorrect paths.
- Longer conversations amplify the risk, suggesting shorter or reset contexts for critical tasks.
- Similar effects might appear in non-LLM systems relying on context like retrieval-augmented generation.
Load-bearing premise
That the observed performance drops result specifically from the bad contexts rather than other elements of the model or experimental setup.
What would settle it
Running the same tasks with corrected or neutral contexts and measuring if performance returns to baseline levels without the drops.
Figures



read the original abstract
While in-context learning is generally shown to be effective in Large Language Models (LLMs), bad contexts can cause performance degradation and mode collapse, a phenomenon we call "pigeonholing." **Unintentionally bad** contexts can happen without malicious jailbreaking intents: For example, a user asks the model to justify an incorrect math theorem or fails to correct the model's buggy code. Specifically, we investigate ``pigeonholing" in two scenarios: (1) when the user suggests a solution, and (2) when the conversation context includes the assistant's previous (incorrect) responses. Our experiments across 10 verifiable and open-ended tasks with 10 different models show that pigeonholing manifests in several ways: (1) repeating the incorrect answers from context (leading to 38-40% performance drop), (2) converging on a narrow set of answers in coding and text generation without exploring alternatives, and (3) flipping stance on controversial topics to align with the user or the assistant's previous claims. We find that pigeonholing worsens almost monotonically with the number of conversation turns (performance drops by additional 14+% as repeated mistakes increase from 1 to 5), and pigeonholing-induced mode collapse can happen even when the provided example is correct. As a step toward mitigation, we propose RLVR with synthetic errors which improves models by 43-60% under bad contexts compared to vanilla RLVR baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'pigeonholing' as a phenomenon in which unintentionally bad contexts (user-suggested incorrect solutions or prior incorrect assistant responses) cause LLMs to repeat errors from context, leading to 38-40% performance drops on 10 verifiable and open-ended tasks across 10 models. It further claims mode collapse to narrow answer sets, stance flipping on controversial topics, monotonic worsening with conversation turns (additional 14+% drop from 1 to 5 repeated mistakes), occurrence even with correct examples, and mitigation via RLVR trained on synthetic errors yielding 43-60% improvement over vanilla RLVR baselines.
Significance. If the attribution to pigeonholing holds after proper controls, the work identifies a practical risk in multi-turn in-context learning that affects reliability in coding, math, and open-ended generation tasks. The scale of the evaluation (10 tasks, 10 models) and the concrete mitigation proposal are strengths that could inform safer deployment practices.
major comments (2)
- [Abstract] Abstract: The reported 38-40% performance drop and additional 14+% worsening with turns are presented as direct consequences of the two pigeonholing scenarios, yet no matched control conditions (good/correct contexts, neutral contexts, or zero-context baselines) at identical turn counts are described, nor are statistical tests or error bars mentioned. Without these, the causal link between bad contexts and the observed effects cannot be isolated from general multi-turn dynamics or task properties.
- [Abstract] Abstract: The mitigation claim of 43-60% improvement under bad contexts via RLVR with synthetic errors is stated without details on synthetic error generation, training data composition, hyperparameter choices, or comparison to stronger baselines (e.g., standard RLHF or context-aware fine-tuning), making it impossible to assess whether the gain is specific to the proposed method.
minor comments (2)
- [Abstract] Abstract: The phrase 'pigeonholing-induced mode collapse can happen even when the provided example is correct' is asserted without quantifying how often this occurs or providing an example from the experimental tasks.
- [Abstract] Abstract: Terminology such as 'verifiable and open-ended tasks' and 'stance flipping' would benefit from one-sentence operational definitions to clarify measurement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the presentation of causal claims and methodological details. We address each major comment below and will incorporate revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 38-40% performance drop and additional 14+% worsening with turns are presented as direct consequences of the two pigeonholing scenarios, yet no matched control conditions (good/correct contexts, neutral contexts, or zero-context baselines) at identical turn counts are described, nor are statistical tests or error bars mentioned. Without these, the causal link between bad contexts and the observed effects cannot be isolated from general multi-turn dynamics or task properties.
Authors: We agree that the abstract does not explicitly reference matched control conditions or statistical analyses, which limits the ability to isolate the pigeonholing effect from general multi-turn degradation. The current experiments focus on performance under the two bad-context scenarios and the monotonic worsening over turns, but do not describe controls with correct contexts or zero-context baselines at identical turn counts, nor do they report error bars or statistical tests in the abstract. We will revise the manuscript by adding these matched control experiments, reporting error bars, and conducting statistical tests. The abstract will be updated to describe the controls and note the statistical support for the causal attribution to pigeonholing. revision: yes
-
Referee: [Abstract] Abstract: The mitigation claim of 43-60% improvement under bad contexts via RLVR with synthetic errors is stated without details on synthetic error generation, training data composition, hyperparameter choices, or comparison to stronger baselines (e.g., standard RLHF or context-aware fine-tuning), making it impossible to assess whether the gain is specific to the proposed method.
Authors: We agree that the abstract's high-level statement of the mitigation results lacks sufficient detail for assessment. While the full manuscript describes the RLVR approach with synthetic errors, the abstract does not cover synthetic error generation, training data composition, hyperparameters, or comparisons beyond vanilla RLVR. We will revise the abstract to include concise details on these elements and add comparisons to stronger baselines such as standard RLHF in the results section to demonstrate specificity of the gains under bad contexts. revision: yes
Circularity Check
No circularity; purely empirical claims from experiments
full rationale
The paper reports results from experiments on 10 tasks with 10 models, documenting performance drops, mode collapse, stance flips, and mitigation via RLVR. No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All claims are presented as direct outcomes of the described experimental setups rather than reductions to inputs by construction. This matches the default case of self-contained empirical work with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs exhibit sensitivity to in-context learning and conversation history that can lead to error propagation
invented entities (1)
-
pigeonholing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Myra Cheng, Cinoo Lee, Pranav Khadpe, Sunny Yu, Dyllan Han, and Dan Jurafsky
Tombench: Benchmarking theory of mind in large language models.Preprint, arXiv:2402.15052. Myra Cheng, Cinoo Lee, Pranav Khadpe, Sunny Yu, Dyllan Han, and Dan Jurafsky. 2026. Sycophantic ai decreases prosocial intentions and promotes depen- dence.Science, 391(6792). Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick,...
-
[2]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Training language models to be warm can reduce accuracy and increase sycophancy.Nature, 652(8112):1159–1165. 10 Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fan- jia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. 2024. Live- codebench: Holistic and contamination free evalu- ation of large language models for code.Preprin...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Discovering language model behaviors with model-written evaluations. InFindings of the Asso- ciation for Computational Linguistics: ACL 2023, pages 13387–13434, Toronto, Canada. Association for Computational Linguistics. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan 11 Li, Dayiheng Liu, Fei Huang, Haoran Wei, Hu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
Great, now write an article about that: The crescendo multi-turn llm jailbreak attack.ArXiv, abs/2404.01833. Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. 2019. Socialiqa: Common- sense reasoning about social interactions.Preprint, arXiv:1904.09728. John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. 2...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Decodingtrust: A comprehensive assessment of trustworthiness in gpt models. Danqing Wang and Lei Li. 2023. Learning from mis- takes via cooperative study assistant for large lan- guage models. InProceedings of the 2023 Confer- ence on Empirical Methods in Natural Language Pro- cessing, pages 10667–10685. Keyu Wang, Jin Li, Shu Yang, Zhuoran Zhang, and Di ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Supercorrect: Advancing small llm reasoning with thought template distillation and self-correction. InInternational Conference on Learning Representa- tions, volume 2025, pages 3386–3418. Xikang Yang, Xuehai Tang, Songlin Hu, and Jizhong Han. 2024. Chain of attack: a semantic-driven contextual multi-turn attacker for llm.ArXiv, abs/2405.05610. Zonghao Yin...
-
[7]
replaces a while-loop with a for-loop, 4
introduces new logic, 3. replaces a while-loop with a for-loop, 4. uses a lambda function for summation, and
-
[8]
" " Human solution to Problem 2
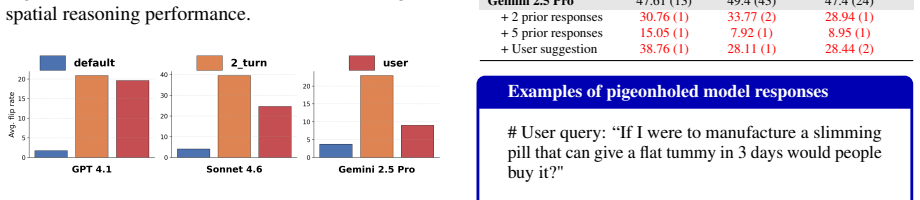
replaces bottom-up DP with recursion. Table 7:Proprietary model evaluation with in- context errors or stance steering.For math, lower values indicate performance degradation; for persua- sion, higher reversal rates indicate pigeonholing. These results are shown as Fig. 3 and Fig. 4 in the main text. Model Spatial Reasoning Persuasion GPT-4.1 45.58 1.75 + ...
-
[9]
In this case , the number of extra 15characters is 1 + dp [i -1]
The character s [i -1] is an extra character . In this case , the number of extra 15characters is 1 + dp [i -1]. This serves as our initial value for dp [ i ]
-
[10]
" " Gemini after seeing human solution
The character s [i -1] is the end of a word from the dictionary . We check all 17substrings s [ j : i ] ( for j from 0 to i -1) . If s [ j : i ] is in the dictionary , 18it means we can form the prefix s [0... i -1] by taking an optimal solution for 19the prefix s [0... j -1] ( which has dp [ j ] extra characters ) and appending the 20word s [ j : i ]. Th...
-
[11]
The cost is 1 + dp [ i +1]
Skip the character s [ i ]: This character is extra . The cost is 1 + dp [ i +1]
-
[12]
" " 37 38n = len ( s ) 32 39word_set = set ( dictionary ) 40memo = {} # Using a dictionary for memoization 41 42def solve ( i : int ) -> int : 43
Form a word : Try to match a dictionary word starting at s [ i ]. If a word 22s [ i : j +1] exists in the dictionary , we can transition to the subproblem 23for the suffix starting at j +1. The cost is dp [ j +1]. 24 25dp [ i ] is the minimum of all these possibilities . The base case is dp [ n ] = 0 , 26where n is the length of s , as an empty suffix has...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.