AVOC: Enhancing Hour-Level Audio-Video Understanding in Omni-Modal LLMs via Retrieval-Inspired Token Compression
Pith reviewed 2026-06-26 00:15 UTC · model grok-4.3
The pith
AVOC reframes token compression as top-K retrieval using relevance, importance and diversity to let omni-modal LLMs handle hour-long audio-video inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
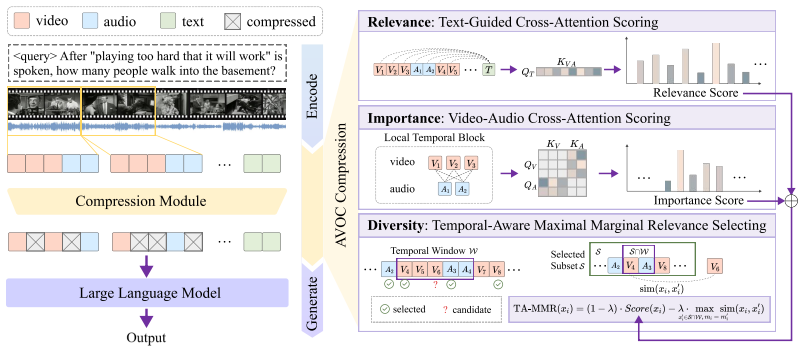
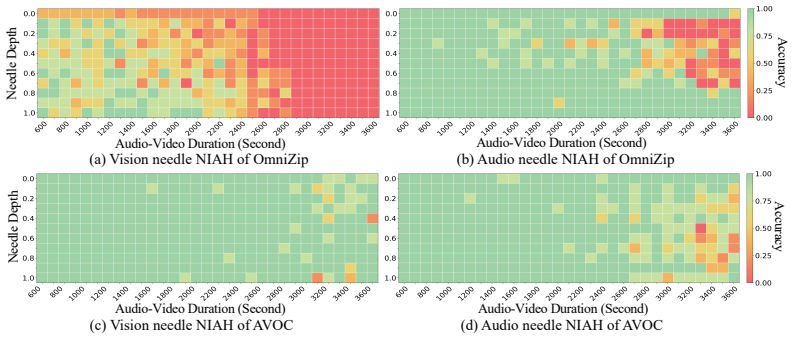
AVOC places a learnable token compression module between the modality encoders and the LLM backbone and recasts multimodal compression as a top-K retrieval problem. The module selects a compact token subset by jointly applying three mechanisms drawn from information retrieval—relevance scoring to the query, importance scoring within the input stream, and diversity enforcement across the selected set—each instantiated for audio-video features. This pipeline is shown to deliver state-of-the-art accuracy on long-form audio-video benchmarks and to preserve performance on needle-in-a-haystack tests at durations reaching one hour.
What carries the argument
The retrieval-style token compression module that scores and selects tokens according to query relevance, input importance, and selection diversity.
If this is right
- The same compression pipeline supports audio-video inputs up to one hour while keeping accuracy on needle-in-a-haystack retrieval tasks.
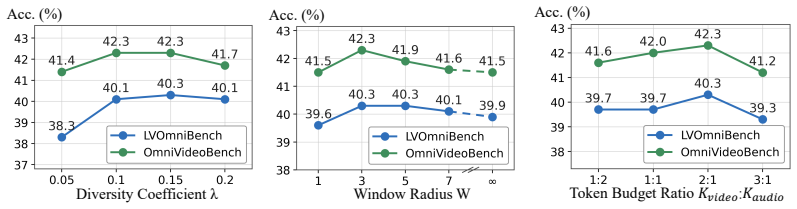
- The method produces higher average accuracy than prior models on the OmniVideoBench and LVOmniBench long-form benchmarks.
- Redundancy is reduced without requiring changes to the underlying LLM context window or architecture.
- The three-criterion selection can be inserted as a modular component between any modality encoder and LLM backbone.
Where Pith is reading between the lines
- The same relevance-importance-diversity logic might apply to compressing long text or image sequences in other multimodal settings.
- Dynamic adjustment of the selection budget according to input length could further reduce compute on shorter clips.
- The approach implicitly assumes that query-specific selection is always preferable to task-agnostic compression; this could be tested by comparing against fixed compression baselines on open-ended queries.
- If the criteria prove sufficient, they might serve as a general template for designing compression modules in future omni-modal models.
Load-bearing premise
A learnable module can reliably pick a small subset of tokens that still contains everything needed to answer an arbitrary query even when the original input lasts an hour.
What would settle it
A controlled test on one-hour audio-video clips in which the model systematically fails to answer queries whose critical evidence was discarded by the compression module.
Figures


read the original abstract
Multimodal Large Language Models have achieved remarkable progress in short-form audio-video understanding, yet long-form audio-video comprehension remains challenged by limited context windows and severe information redundancy. To address these bottlenecks, we propose AVOC, a framework for long-form audio-video understanding in Omni-modal Large Language Models. AVOC introduces a learnable token compression module between the modality encoders and the LLM backbone. We reframe multimodal token compression as a top-$K$ retrieval problem: given a fixed context budget, the module must retrieve a compact subset of tokens that best supports answering the user query. We draw inspiration from three classical Information Retrieval criteria for selecting informative units from a large candidate pool: relevance, importance, and diversity. AVOC instantiates each criterion as a tailored mechanism for audio-video understanding, and integrates them into a unified retrieval-style compression pipeline. Experiments show that AVOC achieves state-of-the-art performance on long-form audio-video benchmarks, surpassing the second-best model by 4.9 and 5.5 points in average accuracy on OmniVideoBench and LVOmniBench, respectively. Moreover, AVOC maintains robust performance on Audio-Video Needle-in-a-Haystack task at durations up to one hour.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AVOC, a learnable token compression module inserted between modality encoders and the LLM backbone for omni-modal models. It reframes compression as a top-K retrieval task drawing on classical IR criteria (relevance, importance, diversity) instantiated for audio-video tokens, and reports that this yields state-of-the-art results on long-form benchmarks: +4.9 points average accuracy on OmniVideoBench and +5.5 points on LVOmniBench over the second-best model, plus maintained performance on Audio-Video Needle-in-a-Haystack tasks up to one-hour duration.
Significance. If the compression module reliably retains query-critical information at hour scale, the result would be a meaningful step toward practical long-context multimodal LLMs. The retrieval framing and the explicit needle-in-a-haystack evaluation at extreme durations are clear strengths that provide a falsifiable test of long-form robustness.
major comments (2)
- [§5.2] §5.2 (Audio-Video Needle-in-a-Haystack results): the reported robustness at one-hour duration is measured only under the model's own learned selection policy; no oracle, random, or alternative-selection baselines are provided to test whether query-critical tokens are systematically discarded, leaving the central assumption that the relevance+importance+diversity criteria preserve necessary information unverified.
- [§4] §4 (experimental setup): the SOTA margins on OmniVideoBench and LVOmniBench are presented without ablation tables isolating the contribution of each IR criterion or without error analysis across query types, so it is impossible to determine whether the gains reflect general hour-scale fidelity or benchmark-specific retention patterns.
minor comments (1)
- [§3] Notation for the three selection scores (relevance, importance, diversity) is introduced in §3 but not consistently subscripted in later equations, making it difficult to trace how they are combined into the final top-K mask.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate additional experiments to strengthen the validation of our claims.
read point-by-point responses
-
Referee: [§5.2] §5.2 (Audio-Video Needle-in-a-Haystack results): the reported robustness at one-hour duration is measured only under the model's own learned selection policy; no oracle, random, or alternative-selection baselines are provided to test whether query-critical tokens are systematically discarded, leaving the central assumption that the relevance+importance+diversity criteria preserve necessary information unverified.
Authors: We agree that additional baselines would provide stronger verification of the selection policy. The needle-in-a-haystack task evaluates end-to-end retention under our criteria, but we acknowledge the value of explicit comparisons. In the revised manuscript we will add random-selection and oracle upper-bound baselines on the Audio-Video Needle-in-a-Haystack task to directly test whether critical tokens are preserved. revision: yes
-
Referee: [§4] §4 (experimental setup): the SOTA margins on OmniVideoBench and LVOmniBench are presented without ablation tables isolating the contribution of each IR criterion or without error analysis across query types, so it is impossible to determine whether the gains reflect general hour-scale fidelity or benchmark-specific retention patterns.
Authors: We appreciate the request for finer-grained analysis. The reported results reflect the full AVOC pipeline; however, to isolate effects we will add ablation tables removing or varying each IR criterion (relevance, importance, diversity) individually, together with per-query-type error breakdowns on both benchmarks. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces AVOC as an empirical framework with a learnable top-K token compression module inspired by classical IR criteria (relevance, importance, diversity), but contains no equations, first-principles derivations, or predictions that reduce by construction to fitted parameters or self-citations. Performance claims are benchmark results (OmniVideoBench, LVOmniBench, Needle-in-a-Haystack), not quantities defined in terms of the method itself. No load-bearing self-citation chains or ansatzes smuggled via prior work appear in the provided text; the approach is self-contained as a proposed architecture evaluated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marks, Chiori Hori, Peter Anderson, Stefan Lee, and Devi Parikh
Huda AlAmri, Vincent Cartillier, Abhishek Das, Jue Wang, Anoop Cherian, Irfan Essa, Dhruv Batra, Tim K. Marks, Chiori Hori, Peter Anderson, Stefan Lee, and Devi Parikh. Audio visual scene-aware dialog. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 7558–7567. Computer Vision Foundation...
2019
-
[2]
The use of mmr, diversity-based reranking for reordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of mmr, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, pages 335–336, 1998
1998
-
[3]
Jianghan Chao, Jianzhang Gao, Wenhui Tan, Yuchong Sun, Ruihua Song, and Liyun Ru. Jointavbench: A benchmark for joint audio-visual reasoning evaluation.arXiv preprint arXiv:2512.12772, 2025
Pith/arXiv arXiv 2025
-
[4]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - ECCV 2024 - 18th European Conf...
2024
-
[5]
Yijing Chen, Yihan Wu, Kaisi Guan, Yuchen Ren, Yuyue Wang, Ruihua Song, and Liyun Ru. Chronusomni: Improving time awareness of omni large language models.arXiv preprint arXiv:2512.09841, 2025
arXiv 2025
-
[6]
Scaling rl to long videos
Yukang Chen, Wei Huang, Baifeng Shi, Qinghao Hu, Hanrong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, Sifei Liu, Hongxu Yin, Yao Lu, and Song Han. Scaling rl to long videos. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[7]
Longvila: Scaling long-context visual language models for long videos
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, Yihui He, Hongxu Yin, Pavlo Molchanov, Jan Kautz, Linxi Fan, Yuke Zhu, Yao Lu, and Song Han. Longvila: Scaling long-context visual language models for long videos. InThe Thirteenth International Conference on Learning Representations,...
2025
-
[8]
OpenReview.net, 2025
2025
-
[9]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
Pith/arXiv arXiv 2024
-
[10]
Charles L. A. Clarke, Maheedhar Kolla, Gordon V . Cormack, Olga Vechtomova, Azin Ashkan, Stefan Büttcher, and Ian MacKinnon. Novelty and diversity in information retrieval evaluation. In Sung-Hyon Myaeng, Douglas W. Oard, Fabrizio Sebastiani, Tat-Seng Chua, and Mun-Kew Leong, editors,Proceedings of the 31st Annual International ACM SIGIR Conference on Res...
2008
-
[11]
Minicpm-o 4.5: Towards real-time full-duplex omni-modal interaction
Junbo Cui, Bokai Xu, Chongyi Wang, Tianyu Yu, Weiyue Sun, Yingjing Xu, Tianran Wang, Zhihui He, Wenshuo Ma, Tianchi Cai, et al. Minicpm-o 4.5: Towards real-time full-duplex omni-modal interaction. arXiv preprint arXiv:2604.27393, 2026
Pith/arXiv arXiv 2026
-
[12]
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, Yuanxing Zhang, Jiaheng Liu, Qiang Liu, Pengfei Wan, and Liang Wang. Omnisift: Modality-asymmetric token compression for efficient omni-modal large language models.CoRR, abs/2602.04804, 2026
Pith/arXiv arXiv 2026
-
[13]
Finevideo.https: //huggingface.co/datasets/HuggingFaceFV/finevideo, 2024
Miquel Farré, Andi Marafioti, Lewis Tunstall, Leandro V on Werra, and Thomas Wolf. Finevideo.https: //huggingface.co/datasets/HuggingFaceFV/finevideo, 2024
2024
-
[14]
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms.arXiv preprint arXiv:2502.04326, 2025
Pith/arXiv arXiv 2025
-
[15]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017
2017
-
[16]
Chat-univi: Unified visual representation empowers large language models with image and video understanding
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 13700–13710. IEEE, 2024. 10
2024
-
[17]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-...
2020
-
[18]
Caorui Li, Yu Chen, Yiyan Ji, Jin Xu, Zhenyu Cui, Shihao Li, Yuanxing Zhang, Wentao Wang, Zhenghao Song, Dingling Zhang, et al. Omnivideobench: Towards audio-visual understanding evaluation for omni mllms.arXiv preprint arXiv:2510.10689, 2025
arXiv 2025
-
[19]
Learning to answer questions in dynamic audio-visual scenarios
Guangyao Li, Yake Wei, Yapeng Tian, Chenliang Xu, Ji-Rong Wen, and Di Hu. Learning to answer questions in dynamic audio-visual scenarios. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19108–19118, 2022
2022
-
[20]
Videochat-flash: Hierarchical compression for long-context video modeling.CoRR, abs/2501.00574, 2025
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, and Limin Wang. Videochat-flash: Hierarchical compression for long-context video modeling.CoRR, abs/2501.00574, 2025
Pith/arXiv arXiv 2025
-
[21]
Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025
Yadong Li, Jun Liu, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Guosheng Dong, Da Pan, et al. Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025
arXiv 2025
-
[22]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XLVI, Lecture Notes in Computer...
2024
-
[23]
Omnibench: Towards the future of universal omni-language models.CoRR, abs/2409.15272, 2024
Yizhi Li, Ge Zhang, Yinghao Ma, Ruibin Yuan, Kang Zhu, Hangyu Guo, Yiming Liang, Jiaheng Liu, Jian Yang, Siwei Wu, Xingwei Qu, Jinjie Shi, Xinyue Zhang, Zhenzhu Yang, Xiangzhou Wang, Zhaoxiang Zhang, Zachary Liu, Emmanouil Benetos, Wenhao Huang, and Chenghua Lin. Omnibench: Towards the future of universal omni-language models.CoRR, abs/2409.15272, 2024
arXiv 2024
-
[24]
World model on million-length video and language with blockwise ringattention
Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with blockwise ringattention. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025
2025
-
[25]
Zuyan Liu, Yuhao Dong, Jiahui Wang, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao. Ola: Pushing the frontiers of omni-modal language model with progressive modality alignment.CoRR, abs/2502.04328, 2025
arXiv 2025
-
[26]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Abdul Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, ...
2024
-
[27]
The pagerank citation ranking: Bring order to the web
Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The pagerank citation ranking: Bring order to the web. InProc. of the 7th International World Wide Web Conf.–1998, 1999
1998
-
[28]
Robertson and Hugo Zaragoza
Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389, 2009
2009
-
[29]
How2: A large-scale dataset for multimodal language understanding.CoRR, abs/1811.00347, 2018
Ramon Sanabria, Ozan Caglayan, Shruti Palaskar, et al. How2: A large-scale dataset for multimodal language understanding.CoRR, abs/1811.00347, 2018
Pith/arXiv arXiv 2018
-
[30]
Kele Shao, Keda Tao, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. When tokens talk too much: A survey of multimodal long-context token compression across images, videos, and audios.CoRR, abs/2507.20198, 2025
arXiv 2025
-
[31]
Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, Zhuang Liu, Hu Xu, Hyunwoo J. Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra. Longvu: Spatiotemporal adaptive compression for long video-language understanding. In Aarti Sing...
2025
-
[32]
Video-xl: Extra-long vision language model for hour-scale video understanding
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-xl: Extra-long vision language model for hour-scale video understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 26160–26169. Computer Vision Foundation / IEEE, 2025
2025
-
[33]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, Yan Lu, Jenq-Neng Hwang, and Gaoang Wang. Moviechat: From dense token to sparse memory for long video understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, p...
2024
-
[34]
Wenhui Tan, Xiaoyi Yu, Jiaze Li, Yijing Chen, Jianzhong Ju, Zhenbo Luo, Ruihua Song, and Jian Luan. Msjoe: Jointly evolving mllm and sampler for efficient long-form video understanding.arXiv preprint arXiv:2602.22932, 2026
arXiv 2026
-
[35]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-salmonn 2: Caption-enhanced audio-visual large language models.arXiv preprint arXiv:2506.15220, 2025
arXiv 2025
-
[36]
Keda Tao, Kele Shao, Bohan Yu, Weiqiang Wang, Jian Liu, and Huan Wang. Omnizip: Audio-guided dynamic token compression for fast omnimodal large language models.CoRR, abs/2511.14582, 2025
Pith/arXiv arXiv 2025
-
[37]
Lvomnibench: Pioneering long audio-video understanding evaluation for omnimodal llms
Keda Tao, Yuhua Zheng, Jia Xu, Wenjie Du, Kele Shao, Hesong Wang, Xueyi Chen, Xin Jin, Junhan Zhu, Bohan Yu, et al. Lvomnibench: Pioneering long audio-video understanding evaluation for omnimodal llms. arXiv preprint arXiv:2603.19217, 2026
arXiv 2026
-
[38]
Qwen3-omni technical report.CoRR, abs/2509.17765, 2025
Qwen Team. Qwen3-omni technical report.CoRR, abs/2509.17765, 2025
Pith/arXiv arXiv 2025
-
[39]
Visual context window extension: A new perspective for long video understanding
Hongchen Wei and Zhenzhong Chen. Visual context window extension: A new perspective for long video understanding. In Cathal Gurrin, Klaus Schoeffmann, Min Zhang, Luca Rossetto, Stevan Rudinac, Duc-Tien Dang-Nguyen, Wen-Huang Cheng, Phoebe Chen, and Jenny Benois-Pineau, editors,Proceedings of the 33rd ACM International Conference on Multimedia, MM 2025, Du...
2025
-
[40]
Longvlm: Efficient long video understanding via large language models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang. Longvlm: Efficient long video understanding via large language models. In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, ...
2024
-
[41]
Qwen2.5-omni technical report.CoRR, abs/2503.20215, 2025
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report.CoRR, abs/2503.20215, 2025
Pith/arXiv arXiv 2025
-
[42]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
2025
-
[43]
Hanrong Ye, Chao-Han Huck Yang, Arushi Goel, Wei Huang, Ligeng Zhu, Yuanhang Su, Sean Lin, An-Chieh Cheng, Zhen Wan, Jinchuan Tian, Yuming Lou, Dong Yang, Zhijian Liu, Yukang Chen, Ambrish Dantrey, Ehsan Jahangiri, Sreyan Ghosh, Daguang Xu, Ehsan Hosseini-Asl, Danial Mohseni-Taheri, Vidya Murali, Sifei Liu, Yao Lu, Oluwatobi Olabiyi, Yu-Chiang Frank Wang,...
arXiv 2025
-
[44]
Vscan: Rethinking visual token reduction for efficient large vision-language models.Trans
Ce Zhang, Kaixin Ma, Tianqing Fang, Wenhao Yu, Hongming Zhang, Zhisong Zhang, Haitao Mi, and Dong Yu. Vscan: Rethinking visual token reduction for efficient large vision-language models.Trans. Mach. Learn. Res., 2026, 2026
2026
-
[45]
Long context transfer from language to vision.Trans
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.Trans. Mach. Learn. Res., 2025, 2025
2025
-
[46]
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20857–20867, 2025. 12
2025
-
[47]
Jiaxing Zhao, Qize Yang, Yixing Peng, Detao Bai, Shimin Yao, Boyuan Sun, Xiang Chen, Shenghao Fu, Xihan Wei, Liefeng Bo, et al. Humanomni: A large vision-speech language model for human-centric video understanding.arXiv preprint arXiv:2501.15111, 2025
arXiv 2025
-
[48]
Ziwei Zhou, Rui Wang, Zuxuan Wu, and Yu-Gang Jiang. Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities.arXiv preprint arXiv:2505.17862, 2025. 13 A Additional Details and Results on Audio-Video Needle-in-a-Haystack A.1 Evaluation Setting Details. We provide additional details on the construction and evaluation protocol of ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.