ZONOS2 Technical Report
Pith reviewed 2026-06-25 22:35 UTC · model grok-4.3
The pith
ZONOS2 8B reaches state-of-the-art naturalness, prosody, and voice cloning fidelity in text-to-speech through scaling and data expansion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
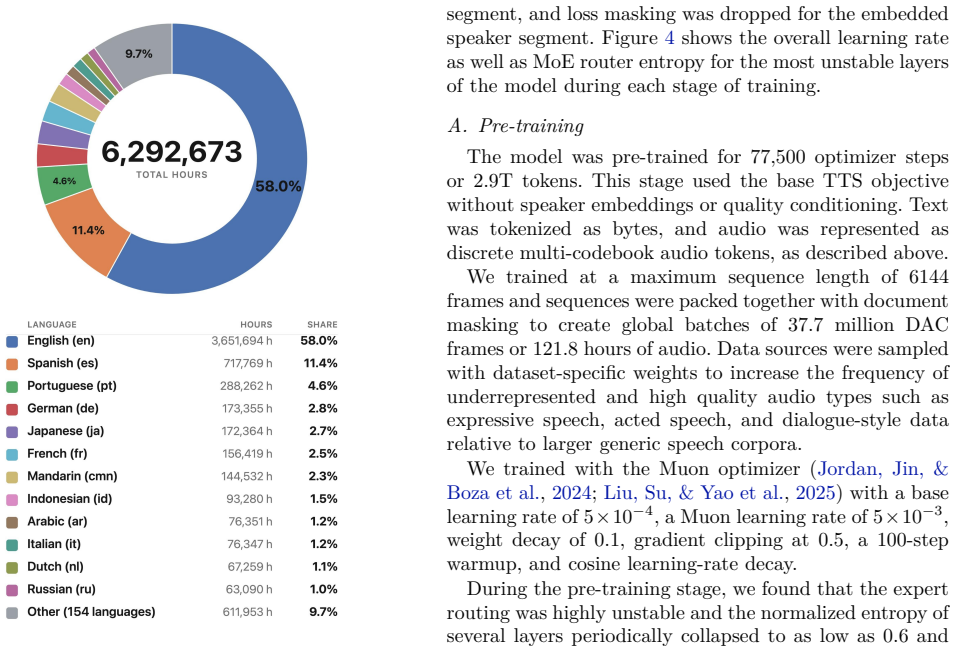
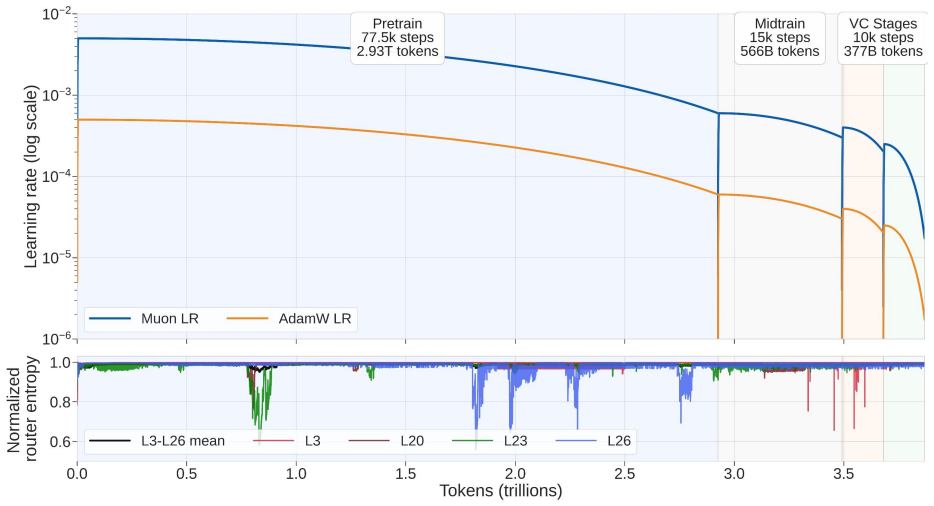
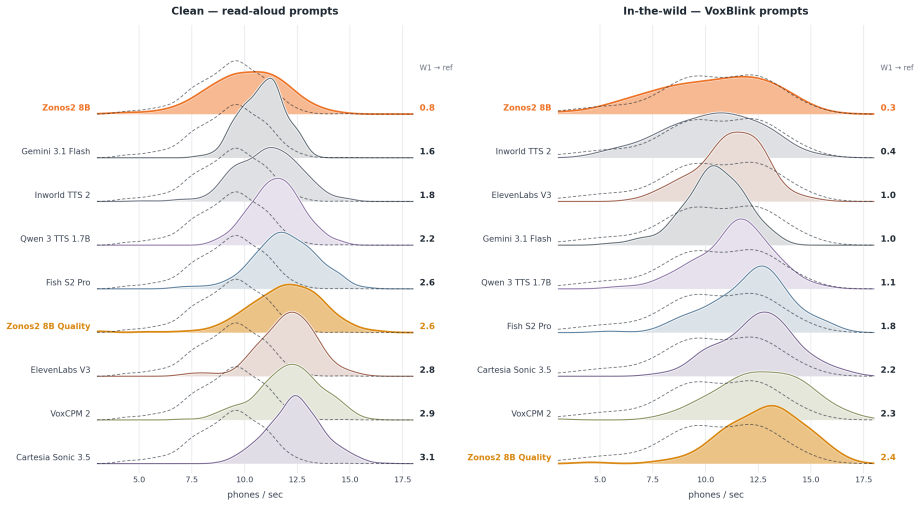
ZONOS2 8B achieves state-of-the-art naturalness, prosody, and voice cloning fidelity. We improve upon Zonos-v0.1 across scale, data, and training recipe. We scale the model from 1.6B to 8B total parameters (900M active) with a novel mixture-of-experts (MoE) backbone, improving inference latency and throughput. We expand our training corpus from 200K to over 6M hours using a new data processing pipeline, and we simplify our post-training and conditioning recipes to improve naturalness and voice cloning fidelity. We evaluate ZONOS2 8B on quality, speaker similarity, WER, and ZTTS1-Eval, our novel TTS benchmark, where it performs competitively with state-of-the-art systems while maintaining goo
What carries the argument
Mixture-of-experts backbone that activates only 900M parameters out of 8B total during inference, paired with an expanded data pipeline and simplified conditioning recipes.
If this is right
- Mixture-of-experts design reduces active parameters and improves throughput compared with dense models of similar total size.
- Expanded data volume and simplified recipes produce measurable lifts in prosody and speaker fidelity on the reported benchmarks.
- The model remains competitive on word error rate and speaker similarity while supporting streaming inference.
- Open release of weights allows direct replication and extension by other researchers.
Where Pith is reading between the lines
- The same scaling pattern may transfer to other audio generation tasks that benefit from large parameter counts and diverse training data.
- Simplified conditioning could lower the engineering effort needed to adapt the model to new speakers or domains.
- If the new ZTTS1-Eval benchmark proves reliable, it may serve as a reference point for future TTS comparisons.
Load-bearing premise
The reported gains in naturalness and fidelity come from the described scaling, data pipeline, and simplified recipes rather than from undisclosed choices in evaluation or benchmark construction.
What would settle it
An independent evaluation on public TTS test sets that shows ZONOS2 8B does not exceed prior models in naturalness or cloning fidelity when run under identical conditions and prompts.
Figures



read the original abstract
We present ZONOS2 8B, our latest TTS model, which achieves state-of-the-art naturalness, prosody, and voice cloning fidelity. We improve upon Zonos-v0.1 across scale, data, and training recipe. We scale the model from 1.6B to 8B total parameters (900M active) with a novel mixture-of-experts (MoE) backbone, improving inference latency and throughput. We expand our training corpus from 200K to over 6M hours using a new data processing pipeline, and we simplify our post-training and conditioning recipes to improve naturalness and voice cloning fidelity. We evaluate ZONOS2 8B on quality, speaker similarity, WER, and ZTTS1-Eval, our novel TTS benchmark, where it performs competitively with state-of-the-art systems while maintaining good streaming latency. We release our model weights and example inference code under an Apache 2.0 license on GitHub and Hugging Face.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ZONOS2 8B, an 8B-parameter (900M active) mixture-of-experts TTS model that scales from a prior 1.6B version via a novel MoE backbone, expands training data from 200K to over 6M hours with a new processing pipeline, and simplifies post-training and conditioning recipes. It claims state-of-the-art naturalness, prosody, and voice cloning fidelity while performing competitively with SOTA systems on quality, speaker similarity, WER, and the novel ZTTS1-Eval benchmark, with maintained streaming latency; model weights and inference code are released under Apache 2.0.
Significance. If the performance claims hold with supporting evidence, the work would be significant for demonstrating scalable benefits of MoE architectures and large-scale data pipelines in TTS, particularly for naturalness and fidelity, while the open release and new benchmark could enable community progress and standardized evaluation.
major comments (2)
- [Abstract] Abstract: No quantitative results, tables, figures, error bars, or baseline comparisons are provided to support the SOTA claims on naturalness, prosody, and fidelity or the competitive performance on other metrics.
- [Abstract] Abstract: No details are given on the construction or validation of the novel ZTTS1-Eval benchmark, the specific evaluation protocols, or how improvements are attributed to the MoE scaling, data expansion, or recipe changes versus other factors.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on the abstract. We agree that strengthening the abstract with quantitative highlights and benchmark details will improve clarity, and we will revise accordingly while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: No quantitative results, tables, figures, error bars, or baseline comparisons are provided to support the SOTA claims on naturalness, prosody, and fidelity or the competitive performance on other metrics.
Authors: We agree the current abstract is high-level and lacks specific numbers. In the revision, we will add key quantitative results (e.g., naturalness and speaker similarity scores relative to baselines, WER, and ZTTS1-Eval performance) drawn from the full evaluation sections to better substantiate the claims, along with brief mention of error bars where applicable. revision: yes
-
Referee: [Abstract] Abstract: No details are given on the construction or validation of the novel ZTTS1-Eval benchmark, the specific evaluation protocols, or how improvements are attributed to the MoE scaling, data expansion, or recipe changes versus other factors.
Authors: We will expand the abstract to include a concise description of ZTTS1-Eval (its construction from diverse sources, validation protocol, and metrics), evaluation setup, and a high-level attribution of gains to the MoE architecture, 6M-hour data scale, and simplified recipes, cross-referencing the detailed sections in the body. revision: yes
Circularity Check
No significant circularity detected
full rationale
The ZONOS2 technical report describes an empirical TTS model scaling effort (1.6B to 8B MoE parameters, 200K to 6M hours data, simplified recipes) and reports competitive benchmark results on quality, speaker similarity, WER, and a new ZTTS1-Eval benchmark. No mathematical derivations, fitted-parameter predictions, self-definitional equations, or load-bearing self-citations appear in the text. Performance numbers are presented as direct empirical outcomes rather than outputs derived from the model's own inputs by construction, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
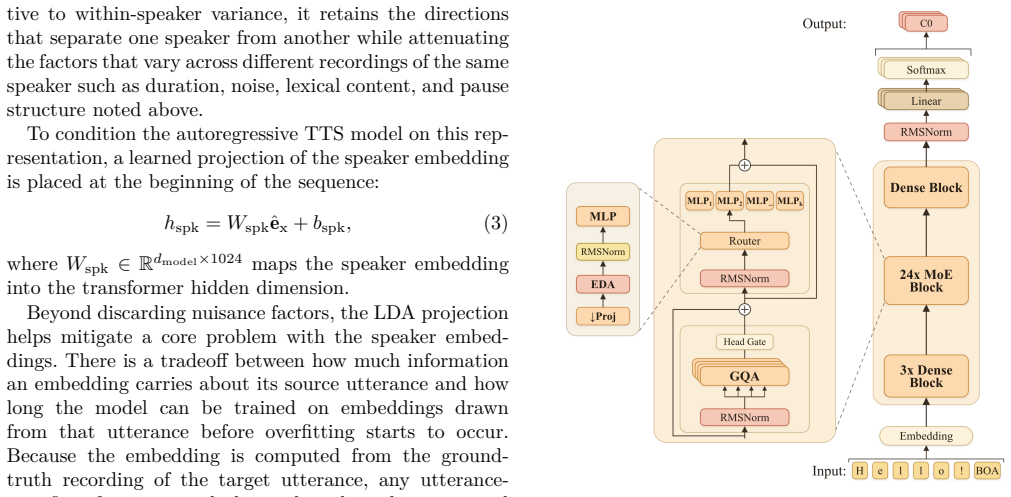
-
[1]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[2]
arXiv preprint arXiv:2512.13961 , pages=
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , pages=
-
[3]
doi:10.21437/Interspeech.2020-2650 , year =
Desplanques, Brecht and Thienpondt, Jenthe and Demuynck, Kris , booktitle =. doi:10.21437/Interspeech.2020-2650 , year =
-
[4]
ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Universal phone recognition with a multilingual allophone system , author=. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2020 , organization=
2020
-
[5]
2022 , eprint=
High Fidelity Neural Audio Compression , author=. 2022 , eprint=
2022
-
[6]
arXiv preprint arXiv:2505.17589 , year=
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training , author=. arXiv preprint arXiv:2505.17589 , year=
-
[7]
2025 , eprint=
CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction , author=. 2025 , eprint=
2025
-
[8]
2026 , eprint =
Maximum Likelihood Reinforcement Learning , author =. 2026 , eprint =
2026
-
[9]
Hugging Face repository , howpublished =
CodeForces , author=. Hugging Face repository , howpublished =. 2025 , publisher =
2025
-
[10]
2025 , eprint=
CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis , author=. 2025 , eprint=
2025
-
[11]
arXiv preprint arXiv:2402.00838 , year=
Olmo: Accelerating the science of language models , author=. arXiv preprint arXiv:2402.00838 , year=
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
arXiv preprint arXiv:2406.03476 , year=
Does your data spark joy? Performance gains from domain upsampling at the end of training , author=. arXiv preprint arXiv:2406.03476 , year=
-
[14]
arXiv preprint arXiv:2406.07887 , year=
An Empirical Study of Mamba-based Language Models , author=. arXiv preprint arXiv:2406.07887 , year=
-
[15]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[16]
arXiv preprint arXiv:2312.00752 , year=
Mamba: Linear-time sequence modeling with selective state spaces , author=. arXiv preprint arXiv:2312.00752 , year=
-
[17]
arXiv preprint arXiv:2402.01771 , year=
BlackMamba: Mixture of Experts for State-Space Models , author=. arXiv preprint arXiv:2402.01771 , year=
-
[18]
https://huggingface.co/Zyphra/Mamba-370M , year=
Zyphra , title=. https://huggingface.co/Zyphra/Mamba-370M , year=
-
[19]
https://huggingface.co/datasets/BAAI/Infinity-Instruct , year=
BAAI , title=. https://huggingface.co/datasets/BAAI/Infinity-Instruct , year=
-
[20]
https://huggingface.co/datasets/Intel/orca\_dpo\_pairs , year=
BAAI , title=. https://huggingface.co/datasets/Intel/orca\_dpo\_pairs , year=
-
[21]
HuggingFace repository , howpublished =
OpenOrca: An Open Dataset of GPT Augmented FLAN Reasoning Traces , author =. HuggingFace repository , howpublished =. 2023 , publisher =
2023
-
[22]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[23]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[24]
2026 , eprint=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
2026
-
[25]
arXiv preprint arXiv:2312.06550 , year=
Llm360: Towards fully transparent open-source llms , author=. arXiv preprint arXiv:2312.06550 , year=
-
[26]
arXiv preprint arXiv:2404.06395 , year=
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies , author=. arXiv preprint arXiv:2404.06395 , year=
-
[27]
arXiv preprint arXiv:2402.16819 , year=
Nemotron-4 15B Technical Report , author=. arXiv preprint arXiv:2402.16819 , year=
-
[28]
arXiv preprint arXiv:2404.07413 , year=
JetMoE: Reaching Llama2 Performance with 0.1 M Dollars , author=. arXiv preprint arXiv:2404.07413 , year=
-
[29]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[30]
arXiv preprint arXiv:2403.08295 , year=
Gemma: Open models based on gemini research and technology , author=. arXiv preprint arXiv:2403.08295 , year=
-
[31]
2024 , eprint=
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
2024
-
[32]
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. CoRR , volume =. 2020 , url =. 2010.11929 , timestamp =
Pith/arXiv arXiv 2020
-
[33]
MiniMax and others , journal =
-
[34]
2025 , eprint=
TTSDS2: Resources and Benchmark for Evaluating Human-Quality Text to Speech Systems , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
Multi-Sampling-Frequency Naturalness MOS Prediction Using Self-Supervised Learning Model with Sampling-Frequency-Independent Layer , author=. 2025 , eprint=
2025
-
[36]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , journal =. 2020 , url =. 2005.14165 , timestamp =
Pith/arXiv arXiv 2020
-
[37]
2021 , eprint=
SoundStream: An End-to-End Neural Audio Codec , author=. 2021 , eprint=
2021
-
[38]
2024 , eprint=
Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis , author=. 2024 , eprint=
2024
-
[39]
2022 , eprint=
Training Compute-Optimal Large Language Models , author=. 2022 , eprint=
2022
-
[40]
Signal Transduction and Targeted Therapy , year=
Yang, Zhenyu and Zeng, Xiaoxi and Zhao, Yi and Chen, Runsheng , title=. Signal Transduction and Targeted Therapy , year=. doi:10.1038/s41392-023-01381-z , url=
-
[41]
2022 , eprint=
Scaling Language Models: Methods, Analysis & Insights from Training Gopher , author=. 2022 , eprint=
2022
-
[42]
2024 , eprint=
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models , author=. 2024 , eprint=
2024
-
[43]
2024 , eprint=
Gated Linear Attention Transformers with Hardware-Efficient Training , author=. 2024 , eprint=
2024
-
[44]
2020 , eprint=
GLU Variants Improve Transformer , author=. 2020 , eprint=
2020
-
[45]
2025 , eprint=
Granary: Speech Recognition and Translation Dataset in 25 European Languages , author=. 2025 , eprint=
2025
-
[46]
2022 , eprint=
UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022 , author=. 2022 , eprint=
2022
-
[47]
2024 , eprint=
DenseFormer: Enhancing Information Flow in Transformers via Depth Weighted Averaging , author=. 2024 , eprint=
2024
-
[48]
2019 , eprint=
Root Mean Square Layer Normalization , author=. 2019 , eprint=
2019
-
[49]
2019 , eprint=
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks , author=. 2019 , eprint=
2019
-
[50]
2023 , eprint=
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , author=. 2023 , eprint=
2023
-
[51]
2022 , eprint=
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , author=. 2022 , eprint=
2022
-
[52]
2024 , eprint=
Mixtral of Experts , author=. 2024 , eprint=
2024
-
[53]
2014 , eprint=
Learning Factored Representations in a Deep Mixture of Experts , author=. 2014 , eprint=
2014
-
[54]
2026 , eprint=
Qwen3-ASR Technical Report , author=. 2026 , eprint=
2026
-
[55]
2023 , eprint=
High-Fidelity Audio Compression with Improved RVQGAN , author=. 2023 , eprint=
2023
-
[56]
2026 , eprint=
Qwen3-TTS Technical Report , author=. 2026 , eprint=
2026
-
[57]
2024 , eprint=
Simple and Controllable Music Generation , author=. 2024 , eprint=
2024
-
[58]
2026 , eprint=
Fish Audio S2 Technical Report , author=. 2026 , eprint=
2026
-
[59]
2024 , eprint=
TTSDS -- Text-to-Speech Distribution Score , author=. 2024 , eprint=
2024
-
[60]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
Chen, Sanyuan and Wang, Chengyi and Chen, Zhengyang and Wu, Yu and Liu, Shujie and Chen, Zhuo and Li, Jinyu and Kanda, Naoyuki and Yoshioka, Takuya and Xiao, Xiong and Wu, Jian and Zhou, Long and Ren, Shuo and Qian, Yanmin and Qian, Yao and Wu, Jian and Zeng, Michael and Yu, Xiangzhan and Wei, Furu , year=. WavLM: Large-Scale Self-Supervised Pre-Training ...
-
[61]
2026 , eprint=
VoxCPM2 Technical Report , author=. 2026 , eprint=
2026
-
[62]
2023 , eprint=
Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition , author=. 2023 , eprint=
2023
-
[63]
2021 , eprint=
DiDiSpeech: A Large Scale Mandarin Speech Corpus , author=. 2021 , eprint=
2021
-
[64]
2022 , eprint=
Robust Speech Recognition via Large-Scale Weak Supervision , author=. 2022 , eprint=
2022
-
[65]
2020 , eprint=
Common Voice: A Massively-Multilingual Speech Corpus , author=. 2020 , eprint=
2020
-
[66]
2024 , eprint=
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models , author=. 2024 , eprint=
2024
-
[67]
2026 , eprint=
Compressed Convolutional Attention: Efficient Attention in a Compressed Latent Space , author=. 2026 , eprint=
2026
-
[68]
2026 , eprint=
ZAYA1-8B Technical Report , author=. 2026 , eprint=
2026
-
[69]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[70]
arXiv preprint arXiv:2404.14219 , year=
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. arXiv preprint arXiv:2404.14219 , year=
-
[71]
Advances in Neural Information Processing Systems , volume=
Doremi: Optimizing data mixtures speeds up language model pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Advances in Neural Information Processing Systems , volume=
D4: Improving llm pretraining via document de-duplication and diversification , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
arXiv preprint arXiv:2401.16380 , year=
Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling , author=. arXiv preprint arXiv:2401.16380 , year=
-
[74]
arXiv preprint arXiv:2309.05463 , year=
Textbooks are all you need ii: phi-1.5 technical report , author=. arXiv preprint arXiv:2309.05463 , year=
-
[75]
arXiv preprint arXiv:2212.14052 , year=
Hungry hungry hippos: Towards language modeling with state space models , author=. arXiv preprint arXiv:2212.14052 , year=
-
[76]
arXiv preprint arXiv:2111.00396 , year=
Efficiently modeling long sequences with structured state spaces , author=. arXiv preprint arXiv:2111.00396 , year=
-
[77]
arXiv preprint arXiv:2403.17844 , year=
Mechanistic Design and Scaling of Hybrid Architectures , author=. arXiv preprint arXiv:2403.17844 , year=
-
[78]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[79]
International conference on machine learning , pages=
Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[80]
GPT-J-6B: A 6 billion parameter autoregressive language model , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.