Reinforcement Learning for Computer-Use Agents with Autonomous Evaluation
Pith reviewed 2026-06-25 23:56 UTC · model grok-4.3
The pith
Modeling vision-language evaluator feedback as a noisy binary reward channel allows derivation of a corrected estimator that improves reinforcement learning success rates for GUI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
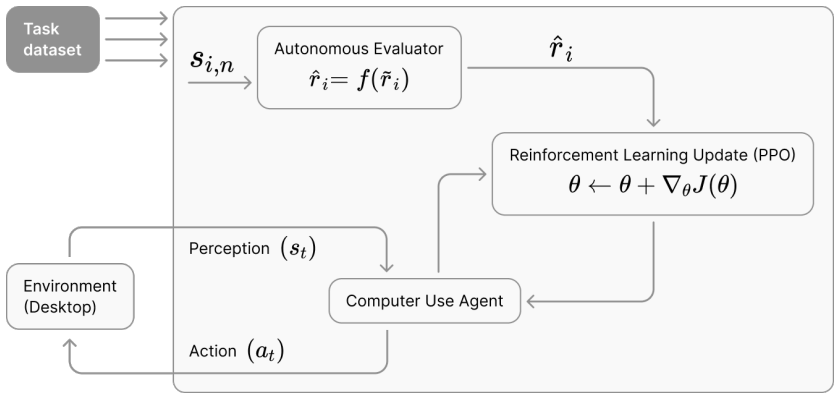
By modeling autonomous vision-language model feedback as a noisy binary reward channel and deriving an unbiased reward estimator from its noise statistics, the corrected rewards can be used inside Proximal Policy Optimization to produce GUI agents whose success rates exceed both zero-shot baselines and agents trained on uncorrected evaluator signals.
What carries the argument
Noise-corrected reward estimator derived from treating VLM judgments as a noisy binary channel, inserted into Proximal Policy Optimization.
If this is right
- Corrected rewards raise average success by 12.6 points over zero-shot performance across macOSWorld, Windows Agent Arena, and OSWorld.
- Corrected rewards raise average success by 5.1 points over raw-evaluator fine-tuning on the same three environments.
- The method supplies a scalable reward signal without task-specific heuristics or manual labels during policy optimization.
- The framework applies to any GUI environment where a final screenshot and original instruction suffice for VLM judgment.
Where Pith is reading between the lines
- The same noise-modeling step could be tested on agents that receive intermediate screenshots rather than only terminal ones.
- If the noise statistics of a given VLM are stable across tasks, the estimator could be reused without re-derivation on new instruction sets.
- The approach suggests that other imperfect but cheap evaluators (for example, smaller models) might become viable reward sources once their noise is explicitly corrected.
Load-bearing premise
The errors made by the vision-language evaluator follow statistics that permit an unbiased or low-bias reward estimator whose use inside PPO does not create offsetting systematic errors.
What would settle it
Running the same RL procedure on a held-out desktop environment where the noise-corrected rewards produce lower or equal success rates compared with raw evaluator rewards would falsify the utility of the correction.
Figures

read the original abstract
Computer-Use Agents (CUAs) execute high-level user goals by perceiving and acting directly within graphical user interfaces. However, reinforcement learning for CUAs remains difficult because open-ended desktop environments rarely provide scalable, machine-readable reward signals: task success is often visually grounded and hard to specify with handcrafted reward functions or dense manual labels. We propose an RL fine-tuning framework that uses autonomous vision-language evaluation as a scalable supervision signal for GUI agents. Given a final screenshot and the original instruction, a Vision-Language Model judges task completion and provides terminal feedback without task-specific heuristics or manual labels during policy optimization. Because autonomous evaluators are imperfect, we model their feedback as a noisy binary reward channel and derive a noise-corrected reward estimator for Proximal Policy Optimization. Experiments across macOSWorld, Windows Agent Arena, and OSWorld show that corrected evaluator rewards outperform both zero-shot baselines and raw evaluator rewards, improving success rates by an average of 12.6 percentage points over zero-shot performance and 5.1 points over raw evaluator fine-tuning. These results suggest that autonomous evaluation can serve as a practical reward signal for RL in GUI environments when evaluator noise is explicitly modeled and corrected.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an RL fine-tuning framework for Computer-Use Agents that treats autonomous VLM evaluation of final screenshots as a scalable reward signal. Evaluator feedback is modeled as a noisy binary channel; a noise-corrected reward estimator is derived for use inside PPO. Experiments on macOSWorld, Windows Agent Arena, and OSWorld report that the corrected rewards improve success rates by 12.6 pp over zero-shot baselines and 5.1 pp over raw-evaluator fine-tuning.
Significance. If the noise model is correctly specified and the estimator remains low-bias under PPO updates, the work supplies a concrete route to reward signals for open-ended GUI agents without handcrafted functions or dense labels. The explicit treatment of evaluator noise and the cross-environment empirical gains are the primary contributions.
major comments (3)
- [Abstract / Method] Abstract / Method: the derivation of the noise-corrected estimator is asserted but no equations, noise-parameter estimation procedure, or proof of unbiasedness (or bounded bias) under the binary-channel assumption are supplied; this derivation is load-bearing for the claim that the 5.1 pp gain is due to the correction rather than to variance or new systematic error.
- [Experiments] Experiments: success-rate improvements are reported as point estimates without error bars, number of seeds, or statistical significance tests; without these controls it is impossible to attribute the reported gains specifically to the noise correction.
- [Method] Method: the stationary i.i.d. binary-noise assumption is not validated against observed VLM error patterns (task dependence, temporal correlation, or non-stationarity); violation of this assumption would invalidate the estimator and could cancel the claimed advantage over raw rewards.
minor comments (1)
- [Abstract] Abstract: the phrase 'derive a noise-corrected reward estimator' should be accompanied by a forward reference to the specific section or equation that contains the derivation.
Simulated Author's Rebuttal
Thank you for the constructive referee report. We agree that the noise-corrected estimator requires explicit derivation and validation, and that the experimental results need statistical controls. We will revise the manuscript to address all three major comments as detailed below.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract / Method: the derivation of the noise-corrected estimator is asserted but no equations, noise-parameter estimation procedure, or proof of unbiasedness (or bounded bias) under the binary-channel assumption are supplied; this derivation is load-bearing for the claim that the 5.1 pp gain is due to the correction rather than to variance or new systematic error.
Authors: We agree the submitted version omitted the full derivation. The revised manuscript will include: (1) the complete derivation of the noise-corrected reward estimator under the binary symmetric channel model, (2) the procedure used to estimate the noise parameters from a held-out validation set of VLM judgments, and (3) a short proof establishing unbiasedness of the corrected estimator (with a note on bounded bias under mild model misspecification). These additions will make clear that the reported 5.1 pp gain is attributable to the correction. revision: yes
-
Referee: [Experiments] Experiments: success-rate improvements are reported as point estimates without error bars, number of seeds, or statistical significance tests; without these controls it is impossible to attribute the reported gains specifically to the noise correction.
Authors: The current results are reported as point estimates. In revision we will add: error bars computed across 5 independent random seeds per condition, the exact seed count, and statistical significance tests (paired t-test and Wilcoxon signed-rank test) comparing raw versus corrected evaluator rewards. These controls will allow readers to assess whether the 5.1 pp difference is statistically reliable. revision: yes
-
Referee: [Method] Method: the stationary i.i.d. binary-noise assumption is not validated against observed VLM error patterns (task dependence, temporal correlation, or non-stationarity); violation of this assumption would invalidate the estimator and could cancel the claimed advantage over raw rewards.
Authors: We accept that the i.i.d. assumption was not empirically checked. The revision will add a dedicated subsection analyzing VLM error patterns on the three benchmarks, reporting: (a) per-task error rates to assess task dependence, (b) autocorrelation of successive judgments to check temporal correlation, and (c) drift in error rate across training episodes to test stationarity. Any observed violations and their implications for the estimator will be discussed. revision: yes
Circularity Check
No circularity: noise-corrected estimator derived from external binary-channel assumption, not from policy outputs
full rationale
The abstract states that VLM feedback is modeled as a noisy binary reward channel and a noise-corrected estimator is derived for PPO. This modeling step is presented as an assumption about the evaluator (independent of the agent's policy performance or fitted values), with the derivation following from that assumption rather than reducing to a fit on the same data. Experiments then compare corrected vs. raw rewards as an empirical test. No equations, self-citations, or renamings are shown that make any reported gain equivalent to its inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- evaluator noise probability
axioms (1)
- domain assumption A vision-language model can produce a usable binary judgment of task completion from a final screenshot and the original natural-language instruction
Reference graph
Works this paper leans on
-
[1]
Windows agent arena: Evaluating multi-modal os agents at scale,
[Bonattiet al., 2024 ] Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, Lawrence Jang, and Zack Hui. Windows agent arena: Evaluating multi-modal os agents at scale,
2024
-
[2]
Reinforcement Learning with Verifiable yet Noisy Rewards under Imperfect Verifiers
[Caiet al., 2025b ] Xin-Qiang Cai, Wei Wang, Feng Liu, Tongliang Liu, Gang Niu, and Masashi Sugiyama. Re- inforcement learning with verifiable yet noisy rewards un- der imperfect verifiers.arXiv preprint arXiv:2510.00915,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Guide: Graphical user interface data for execution,
[Chawlaet al., 2024 ] Rajat Chawla, Adarsh Jha, Muskaan Kumar, Mukunda NS, and Ishaan Bhola. Guide: Graphical user interface data for execution,
2024
-
[4]
Gui-world: A video benchmark and dataset for multimodal gui-oriented understanding,
[Chenet al., 2025 ] Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Liuyi Chen, Yilin Bai, Zhigang He, Chen- long Wang, Huichi Zhou, Yiqiang Li, Tianshuo Zhou, Yue Yu, Chujie Gao, Qihui Zhang, Yi Gui, Zhen Li, Yao Wan, Pan Zhou, Jianfeng Gao, and Lichao Sun. Gui-world: A video benchmark and dataset for multimodal gui-oriented understanding,
2025
-
[5]
Browsergym: A benchmark for browser agents
[Guret al., 2023 ] Izzeddin Gur, Arjun Pal, Tianyu Li, Marc Brockschmidt, Swarat Chaudhuri, Mark Riedl, and Jacob Andreas. Browsergym: A benchmark for browser agents. arXiv preprint arXiv:2307.04492,
-
[6]
WebArena: A Realistic Web Environment for Building Autonomous Agents
[Humphreyset al., 2024 ] Peter Humphreys, Ansong Ni, Han Pan, Izzeddin Gur, Victor Zhong, and Jacob Andreas. Webarena: A realistic web environment for building au- tonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Omniact: A dataset and benchmark for enabling multimodal generalist au- tonomous agents for desktop and web,
[Kapooret al., 2024 ] Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem Al- shikh, and Ruslan Salakhutdinov. Omniact: A dataset and benchmark for enabling multimodal generalist au- tonomous agents for desktop and web,
2024
-
[8]
Pgx: Hardware-accelerated parallel game simulators for reinforcement learning,
[Koyamadaet al., 2024 ] Sotetsu Koyamada, Shinri Okano, Soichiro Nishimori, Yu Murata, Keigo Habara, Haruka Kita, and Shin Ishii. Pgx: Hardware-accelerated parallel game simulators for reinforcement learning,
2024
-
[9]
Computerrl: Scaling end-to-end online reinforcement learning for computer use agents,
[Laiet al., 2025 ] Hanyu Lai, Xiao Liu, Yanxiao Zhao, Han Xu, Hanchen Zhang, Bohao Jing, Yanyu Ren, Shuntian Yao, Yuxiao Dong, and Jie Tang. Computerrl: Scaling end-to-end online reinforcement learning for computer use agents,
2025
- [10]
-
[11]
[Liet al., 2024b ] Zhiyuan Li, Yuxuan Zhao, Qingyang Chen, Yujia Zhao, Hao Zhang, Liang Yuan, Bill Yuchen Lin, Yizhou Wang, and Wenhao Zhang. Seeact: A multi- modal agent for web interaction via visual grounding and action generation.arXiv preprint arXiv:2404.05719,
-
[12]
Cuarewardbench: A benchmark for evaluating reward models on computer- using agent,
[Linet al., 2025 ] Haojia Lin, Xiaoyu Tan, Yulei Qin, Zihan Xu, Yuchen Shi, Zongyi Li, Gang Li, Shaofei Cai, Siqi Cai, Chaoyou Fu, Ke Li, and Xing Sun. Cuarewardbench: A benchmark for evaluating reward models on computer- using agent,
2025
-
[13]
Infiguiagent: A multimodal generalist gui agent with native reasoning and reflection,
[Liuet al., 2025 ] Yuhang Liu, Pengxiang Li, Zishu Wei, Congkai Xie, Xueyu Hu, Xinchen Xu, Shengyu Zhang, Xiaotian Han, Hongxia Yang, and Fei Wu. Infiguiagent: A multimodal generalist gui agent with native reasoning and reflection,
2025
-
[14]
Autonomous evaluation and refinement of digital agents,
[Panet al., 2024 ] Jiayi Pan, Yichi Zhang, Nicholas Tomlin, Yifei Zhou, Sergey Levine, and Alane Suhr. Autonomous evaluation and refinement of digital agents,
2024
-
[15]
Webrl: Training llm web agents via self-evolving online curriculum reinforcement learn- ing,
[Qiet al., 2025 ] Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenyi Zhao, Yu Yang, Xinyue Yang, Jiadai Sun, Shuntian Yao, Tianjie Zhang, Wei Xu, Jie Tang, and Yuxiao Dong. Webrl: Training llm web agents via self-evolving online curriculum reinforcement learn- ing,
2025
-
[16]
Ui-tars: Pioneering automated gui interaction with native agents,
[Qinet al., 2025 ] Yujia Qin, Yining Ye, Junjie Fang, Haom- ing Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jia- hao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen,...
2025
-
[17]
The art of building verifiers for computer use agents,
[Rossetet al., 2026 ] Corby Rosset, Pratyusha Sharma, An- drew Zhao, Miguel Gonzalez-Fernandez, and Ahmed Awadallah. The art of building verifiers for computer use agents,
2026
-
[18]
Sager, Benjamin Meyer, Peng Yan, Rebekka von Wartburg-Kottler, Layan Etaiwi, Aref Enayati, Gabriel Nobel, Ahmed Abdulkadir, Benjamin F
[Sageret al., 2025 ] Pascal J. Sager, Benjamin Meyer, Peng Yan, Rebekka von Wartburg-Kottler, Layan Etaiwi, Aref Enayati, Gabriel Nobel, Ahmed Abdulkadir, Benjamin F. Grewe, and Thilo Stadelmann. A comprehensive survey of agents for computer use: Foundations, challenges, and future directions,
2025
-
[19]
Proximal policy optimization algorithms,
[Schulmanet al., 2017 ] John Schulman, Filip Wolski, Pra- fulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms,
2017
-
[20]
are we done yet?
[Sumyk and Kosovan, 2025] Marta Sumyk and Oleksandr Kosovan. “are we done yet?”: A vision-based judge for au- tonomous task completion of computer use agents,
2025
-
[21]
Cuaaudit: Meta-evaluation of vision-language models as auditors of autonomous computer-use agents,
[Sumyk and Kosovan, 2026] Marta Sumyk and Oleksandr Kosovan. Cuaaudit: Meta-evaluation of vision-language models as auditors of autonomous computer-use agents,
2026
-
[22]
Seagent: Self-evolving computer use agent with autonomous learning from experience,
[Sunet al., 2025 ] Zeyi Sun, Ziyu Liu, Yuhang Zang, Yuhang Cao, Xiaoyi Dong, Tong Wu, Dahua Lin, and Jiaqi Wang. Seagent: Self-evolving computer use agent with autonomous learning from experience,
2025
-
[23]
Sutton and Andrew G
[Sutton and Barto, 2018] Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 2 edition,
2018
-
[24]
Deep reinforcement learning for robotics: A sur- vey of real-world successes,
[Tanget al., 2024 ] Chen Tang, Ben Abbatematteo, Jiaheng Hu, Rohan Chandra, Roberto Mart ´ın-Mart´ın, and Peter Stone. Deep reinforcement learning for robotics: A sur- vey of real-world successes,
2024
-
[25]
Reinforcement learning and markov deci- sion processes.Reinforcement Learning: State of the Art, pages 3–42,
[van Otterlo and Wiering, 2012] Martijn van Otterlo and Marco Wiering. Reinforcement learning and markov deci- sion processes.Reinforcement Learning: State of the Art, pages 3–42,
2012
-
[26]
Reinforcement learning with perturbed rewards.arXiv preprint arXiv:1810.01032,
[Wanget al., 2020a ] Jingkang Wang, Yang Liu, and Bo Li. Reinforcement learning with perturbed rewards.arXiv preprint arXiv:1810.01032,
-
[27]
Qwen2-vl: En- hancing vision-language model’s perception of the world at any resolution,
[Wanget al., 2024 ] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: En- hancing vision-language model’s perception of the world at any resolution,
2024
-
[28]
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning,
[Wanget al., 2025 ] Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, Wan- jun Zhong, Yining Ye, Yujia Qin, Yuwen Xiong, Yuxin Song, Zhiyong Wu, Aoyan Li, Bo Li, Chen Dun, Chong Liu, Daoguang Zan, Fuxing Leng, Hanbin Wang, Hao Yu, Haobin Chen, Hongyi Guo, Jing Su, Jingji...
2025
-
[29]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments,
[Xieet al., 2024 ] Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments,
2024
-
[30]
macosworld: A multilingual interactive benchmark for gui agents, 2025
[Yanget al., 2025 ] Pei Yang, Hai Ci, and Mike Zheng Shou. macosworld: A multilingual interactive benchmark for gui agents, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.