Grad Detect: Gradient-Based Hallucination Detection in LLMs
Pith reviewed 2026-06-25 23:57 UTC · model grok-4.3
The pith
Gradient patterns from a single forward-backward pass reveal whether an LLM output is a hallucination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
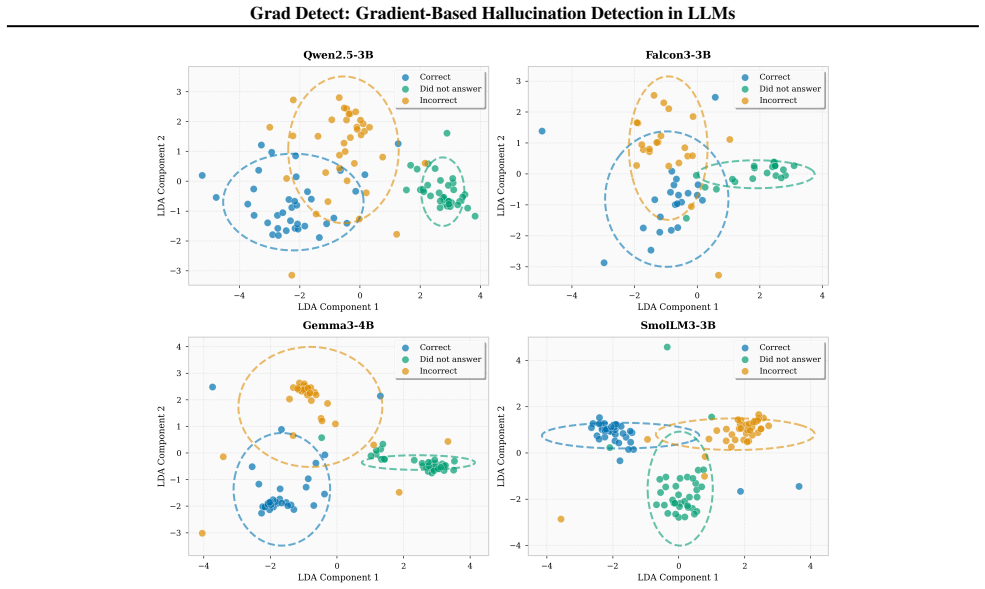
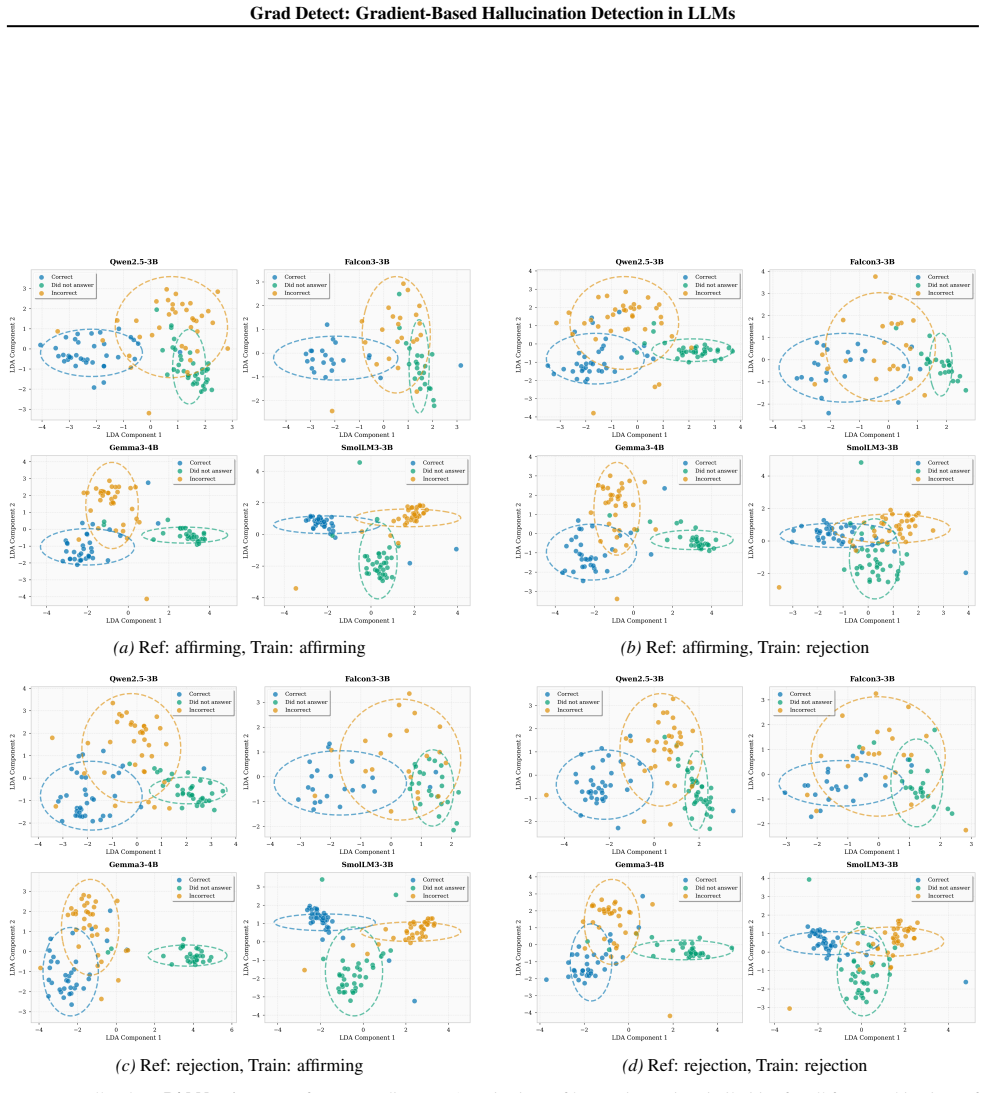
Grad Detect analyzes layer-wise gradient patterns from a single forward-backward pass to predict hallucinations. On Q&A benchmarks it outperforms confidence-based and sampling-based baselines for both hallucination detection and abstention prediction. The final five layers concentrate over 97 percent of the discriminative signal across eleven models from four families.
What carries the argument
Layer-wise gradient patterns obtained from one forward-backward pass on the input and generated output pair.
If this is right
- Hallucination checks can run with only one extra backward pass at inference time.
- Deployment can restrict gradient computation to the final five layers with little loss in performance.
- The same gradient signals support unified prediction of both hallucinations and abstention.
- Layer ablation reveals where failure signals originate inside the model.
Where Pith is reading between the lines
- The gradient signal concentration in final layers may indicate that output reliability judgments depend mainly on late-stage processing.
- Gradient patterns could be tested for detecting other output errors such as logical inconsistencies.
- Hybrid detectors that combine gradients with existing output signals might yield further gains.
Load-bearing premise
Gradient patterns observed on Q&A benchmarks generalize as reliable indicators of hallucination across models, tasks, and real-world use without additional fitting or selection effects.
What would settle it
Testing the gradient patterns on a new task domain or model family and finding no correlation with independently labeled hallucination rates would falsify the central claim.
Figures







read the original abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse tasks, yet they remain prone to generating hallucinations. Detecting these hallucinations is critical for deploying LLMs reliably in high-stakes applications. We present Grad Detect, a gradient-based approach for predicting hallucinations by analyzing layer-wise gradient patterns from a single forward-backward pass during inference. Our method shows that the internal gradient structure of a model carries rich information about the correctness of its output. This information is not accessible through output-level signals alone. We evaluate Grad Detect on several Q&A benchmarks across both hallucination detection and model abstention prediction, where it consistently outperforms confidence-based and sampling-based baselines. Through comprehensive layer ablation studies across all eleven models from four architectural families, we find that the final five layers concentrate over 97% of the discriminative gradient signal, enabling efficient deployment with minimal performance loss. Grad Detect provides a unified framework for predicting multiple dimensions of LLM reliability, offering strong predictive performance alongside interpretable insights into where and how model failures originate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Grad Detect, a gradient-based method for hallucination detection and abstention prediction in LLMs that extracts layer-wise gradient patterns from a single forward-backward pass at inference time. It claims this internal-gradient approach consistently outperforms confidence-based and sampling-based baselines on multiple Q&A benchmarks, and that layer-ablation experiments across eleven models from four families show the final five layers concentrate over 97% of the discriminative signal, enabling efficient deployment.
Significance. If the gradient signals prove robust and generalizable without benchmark-specific tuning, the work would supply a practical, output-independent reliability signal together with an interpretable localization of where failures originate; the reported layer concentration would further support low-overhead deployment.
major comments (3)
- [Abstract] Abstract: the central claim of 'consistent outperformance' over baselines is asserted without any quantitative metrics, error bars, dataset sizes, or ablation tables, so the strength of the empirical result cannot be assessed from the provided text.
- [Layer ablation studies] Layer ablation studies (Abstract): the statement that the final five layers concentrate over 97% of the discriminative gradient signal is obtained via post-hoc ablation performed on the identical Q&A benchmarks and eleven models used for the main evaluation; this leaves open the possibility that both the concentration and the overall discriminative power are benchmark- or model-selection artifacts rather than intrinsic properties.
- [Evaluation] Evaluation sections: the claim that gradient patterns supply information 'not accessible through output-level signals alone' and that the method works 'without additional fitting' requires explicit controls showing that any downstream predictor or feature selection was not tuned on the test benchmarks; absent such controls the generalization argument does not follow from the reported single-pass Q&A results.
minor comments (1)
- [Abstract] The abstract would be strengthened by inclusion of at least one key performance number (e.g., AUROC or accuracy delta) to allow readers to gauge the magnitude of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent outperformance' over baselines is asserted without any quantitative metrics, error bars, dataset sizes, or ablation tables, so the strength of the empirical result cannot be assessed from the provided text.
Authors: We agree the abstract would benefit from quantitative context. In revision we will add key metrics (e.g., average AUC gains over baselines), dataset sizes, model count, and a brief reference to the layer-ablation result already stated in the text. revision: yes
-
Referee: [Layer ablation studies] Layer ablation studies (Abstract): the statement that the final five layers concentrate over 97% of the discriminative gradient signal is obtained via post-hoc ablation performed on the identical Q&A benchmarks and eleven models used for the main evaluation; this leaves open the possibility that both the concentration and the overall discriminative power are benchmark- or model-selection artifacts rather than intrinsic properties.
Authors: The ablation was run across eleven models spanning four architectural families and multiple benchmarks, with the final-five-layer concentration holding uniformly. This cross-family consistency reduces the likelihood of pure artifact, but we acknowledge the post-hoc character on the same data. We will add an explicit limitations paragraph noting this and will consider reporting results on an additional held-out benchmark in revision. revision: partial
-
Referee: [Evaluation] Evaluation sections: the claim that gradient patterns supply information 'not accessible through output-level signals alone' and that the method works 'without additional fitting' requires explicit controls showing that any downstream predictor or feature selection was not tuned on the test benchmarks; absent such controls the generalization argument does not follow from the reported single-pass Q&A results.
Authors: Grad Detect computes layer-wise gradient statistics directly from one forward-backward pass and applies them without training, fine-tuning, or feature selection on any evaluation benchmark. No downstream predictor is learned. We will strengthen the manuscript by adding a dedicated paragraph clarifying the absence of fitting and by including an explicit statement that all reported numbers use the identical, untuned procedure across benchmarks. revision: yes
Circularity Check
No circularity; empirical method evaluated on external benchmarks
full rationale
The paper presents Grad Detect as an empirical method that extracts layer-wise gradient patterns from a single forward-backward pass and evaluates them directly on Q&A benchmarks for hallucination detection and abstention prediction. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. Ablation results (e.g., final-five-layer concentration) are reported as post-hoc observations on the same benchmarks rather than as load-bearing reductions that define the central claim by construction. The approach is therefore self-contained against external data and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=. 2020 , url=
2020
-
[2]
Journal of Machine Learning Research , volume=
PaLM: Scaling Language Modeling with Pathways , author=. Journal of Machine Learning Research , volume=. 2023 , url=
2023
-
[3]
arXiv preprint arXiv:2302.13971 , year=
LLaMA: Open and Efficient Foundation Language Models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[4]
ACM Computing Surveys , volume=
Survey of Hallucination in Natural Language Generation , author=. ACM Computing Surveys , volume=. 2023 , url=
2023
-
[5]
Computational Linguistics , volume=
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. Computational Linguistics , volume=. 2025 , url=
2025
-
[6]
arXiv preprint arXiv:2207.05221 , year=
Language Models (Mostly) Know What They Know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[7]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , url=
2023
-
[8]
International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. International Conference on Learning Representations , year=
-
[9]
International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. International Conference on Learning Representations , year=
-
[10]
Transactions on Machine Learning Research , year=
Generating with Confidence: Uncertainty Quantification for Black-Box Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[11]
arXiv preprint arXiv:2302.12813 , year=
Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback , author=. arXiv preprint arXiv:2302.12813 , year=
-
[12]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
RARR: Researching and Revising What Language Models Say, Using Language Models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2023 , url=
2023
-
[13]
Advances in Neural Information Processing Systems , volume=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. Advances in Neural Information Processing Systems , volume=. 2020 , url=
2020
-
[14]
arXiv preprint arXiv:1312.6034 , year=
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps , author=. arXiv preprint arXiv:1312.6034 , year=
-
[15]
Proceedings of the 34th International Conference on Machine Learning , series=
Axiomatic Attribution for Deep Networks , author=. Proceedings of the 34th International Conference on Machine Learning , series=. 2017 , url=
2017
-
[16]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Explaining How Transformers Use Context to Build Predictions , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2023 , doi=
2023
-
[17]
International Conference on Learning Representations , year=
Explaining and Harnessing Adversarial Examples , author=. International Conference on Learning Representations , year=
-
[18]
International Conference on Learning Representations , year=
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. International Conference on Learning Representations , year=
-
[19]
Proceedings of the 34th International Conference on Machine Learning , series=
The Shattered Gradients Problem: If ResNets are the Answer, Then What is the Question? , author=. Proceedings of the 34th International Conference on Machine Learning , series=. 2017 , url=
2017
-
[20]
Advances in Neural Information Processing Systems , volume=
How Does Batch Normalization Help Optimization? , author=. Advances in Neural Information Processing Systems , volume=. 2018 , url=
2018
-
[21]
Advances in Neural Information Processing Systems , volume=
SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability , author=. Advances in Neural Information Processing Systems , volume=. 2017 , url=
2017
-
[22]
IEEE Transactions on Information Theory , volume=
On Optimum Recognition Error and Reject Tradeoff , author=. IEEE Transactions on Information Theory , volume=. 1970 , url=
1970
-
[23]
Advances in Neural Information Processing Systems , volume=
Selective Classification for Deep Neural Networks , author=. Advances in Neural Information Processing Systems , volume=. 2017 , url=
2017
-
[24]
Transactions on Machine Learning Research , year=
Teaching Models to Express Their Uncertainty in Words , author=. Transactions on Machine Learning Research , year=
-
[25]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[26]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year=
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year=
2022
-
[27]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
BERT Rediscovers the Classical NLP Pipeline , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=. 2019 , doi=
2019
-
[28]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
What Does BERT Learn about the Structure of Language? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=. 2019 , url=
2019
-
[29]
Advances in Neural Information Processing Systems , volume=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[30]
Advances in Neural Information Processing Systems , volume=
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[31]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , url=
2023
-
[32]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2017 , url=
2017
-
[33]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2023 , url=
2023
-
[34]
Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=
Crowdsourcing Multiple Choice Science Questions , author=. Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=. 2017 , url=
2017
-
[35]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=. 2019 , url=
2019
-
[36]
Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages=
WikiQA: A Challenge Dataset for Open-Domain Question Answering , author=. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages=. 2015 , url=
2015
-
[37]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2022 , url=
2022
-
[38]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Focal Loss for Dense Object Detection , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=. 2017 , url=
2017
-
[39]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[40]
Proceedings of the 34th International Conference on Machine Learning , series=
On Calibration of Modern Neural Networks , author=. Proceedings of the 34th International Conference on Machine Learning , series=. 2017 , url=
2017
-
[41]
Advances in Neural Information Processing Systems , volume=
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[42]
ArXiv , year =
A Survey of Large Language Models , author =. ArXiv , year =
-
[43]
Why Language Models Hallucinate
Why Language Models Hallucinate , author =. arXiv preprint , year =. doi:10.48550/arXiv.2509.04664 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.04664
-
[44]
Ethical and social risks of harm from Language Models
Ethical and social risks of harm from Language Models , author =. arXiv preprint , year =. doi:10.48550/arXiv.2112.04359 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.04359
-
[45]
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author =. ACM Transactions on Information Systems , year =. doi:10.1145/3703155 , url =
-
[46]
Transferable and Efficient Non-Factual Content Detection via Probe Training with Offline Consistency Checking , author =. arXiv preprint , year =. doi:10.48550/arXiv.2404.06742 , url =
-
[47]
HaloScope: Harnessing Unlabeled LLM Generations for Hallucination Detection , author =. NeurIPS 2024 , year =. doi:10.48550/arXiv.2409.17504 , url =
-
[48]
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models , author =. arXiv preprint , year =. doi:10.48550/arXiv.2403.06448 , url =
-
[49]
ICAI'24 - The 26th Int'l Conf on Artificial Intelligence , year =
Detecting Hallucinations in Large Language Model Generation: A Token Probability Approach , author =. ICAI'24 - The 26th Int'l Conf on Artificial Intelligence , year =. doi:10.48550/arXiv.2405.19648 , url =
-
[50]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs , author =. arXiv preprint , year =. doi:10.48550/arXiv.2406.15927 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.15927
-
[51]
Large Language Models are Better Reasoners with Self-Verification , author =. EMNLP 2023 Findings , year =. doi:10.48550/arXiv.2212.09561 , url =
-
[52]
RCOT: Detecting and Rectifying Factual Inconsistency in Reasoning by Reversing Chain-of-Thought , author =. arXiv preprint , year =. doi:10.48550/arXiv.2305.11499 , url =
-
[53]
NAACL 2024 Main Conference , year =
A Closer Look at the Self-Verification Abilities of Large Language Models in Logical Reasoning , author =. NAACL 2024 Main Conference , year =. doi:10.48550/arXiv.2311.07954 , url =
-
[54]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. arXiv preprint , year =. doi:10.48550/arXiv.2201.11903 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903
-
[55]
Attention Is All You Need , author =. arXiv preprint , year =. doi:10.48550/arXiv.1706.03762 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762
-
[56]
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification , author =. ICCV 2021 , year =. doi:10.48550/arXiv.2103.14899 , url =
-
[57]
Focal Loss for Dense Object Detection
Focal Loss for Dense Object Detection , author =. arXiv preprint , year =. doi:10.48550/arXiv.1708.02002 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1708.02002
-
[58]
The Internal State of an LLM Knows When It's Lying
The Internal State of an LLM Knows When It's Lying , author =. arXiv preprint , year =. doi:10.48550/arXiv.2304.13734 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.13734
-
[59]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models , author =. EMNLP 2023 , year =. doi:10.48550/arXiv.2303.08896 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08896 2023
-
[60]
V-STaR: Training Verifiers for Self-Taught Reasoners , author =. arXiv preprint , year =. doi:10.48550/arXiv.2402.06457 , url =
-
[61]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open Foundation and Fine-Tuned Chat Models , author =. arXiv preprint , year =. doi:10.48550/arXiv.2307.09288 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288
-
[62]
Qwen2.5 Technical Report , author =. arXiv preprint , year =. doi:10.48550/arXiv.2412.15115 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115
-
[63]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author =. ACL 2022 , year =. doi:10.48550/arXiv.2109.07958 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2109.07958 2022
-
[64]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint , year =. doi:10.48550/arXiv.2110.14168 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168
-
[65]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author =. arXiv preprint , year =. doi:10.48550/arXiv.1705.03551 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.03551
-
[66]
arXiv preprint arXiv:2407.03282 , year=
LLM Internal States Reveal Hallucination Risk Faced With a Query , author=. arXiv preprint arXiv:2407.03282 , year=
-
[67]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[68]
2023 , eprint=
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author=. 2023 , eprint=
2023
-
[69]
2025 , eprint=
Mixture of Experts in Large Language Models , author=. 2025 , eprint=
2025
-
[70]
Advances in Neural Information Processing Systems , volume =
Teaching Machines to Read and Comprehend , author =. Advances in Neural Information Processing Systems , volume =
-
[71]
and Lapata, Mirella , booktitle =
Narayan, Shashi and Cohen, Shay B. and Lapata, Mirella , booktitle =. Don't Give Me the Details, Just the Summary!. 2018 , publisher =
2018
-
[72]
2019 , publisher =
Gliwa, Bogdan and Mochol, Iwona and Biesek, Maciej and Wawer, Aleksander , booktitle =. 2019 , publisher =
2019
-
[73]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =
Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =. 2019 , publisher =
2019
-
[74]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =. 2018 , publisher =
2018
-
[75]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Tang, Jie and Yao, Juntao and Liu, Yankai and Li, Ruobing and Sun, Zhi...
-
[76]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[77]
2023 , eprint =
GAIA: a benchmark for General AI Assistants , author =. 2023 , eprint =
2023
-
[78]
2024 , eprint=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. 2024 , eprint=
2024
-
[79]
The Falcon 3 Family of Open Models , author =
-
[80]
arXiv preprint arXiv:2503.19786 , year =
Gemma 3 Technical Report , author =. arXiv preprint arXiv:2503.19786 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.