MANGO: Automated Multi-Agent Test Oracle Generation for Vision-Language-Action Models
Pith reviewed 2026-06-25 23:05 UTC · model grok-4.3
The pith
MANGO generates executable fine-grained oracles for vision-language-action models that detect similar failures as symbolic oracles while adding accurate localization and richer diagnostics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
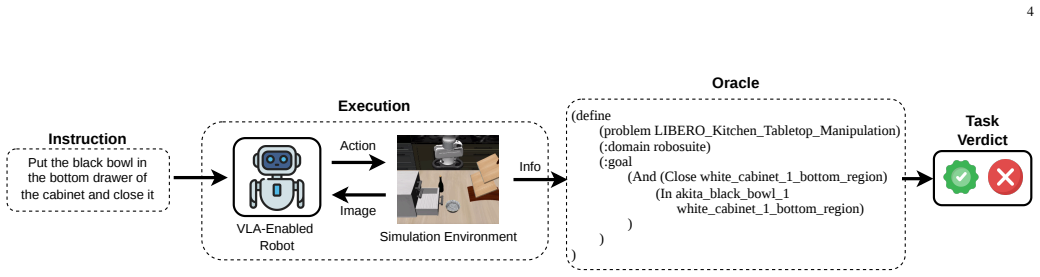
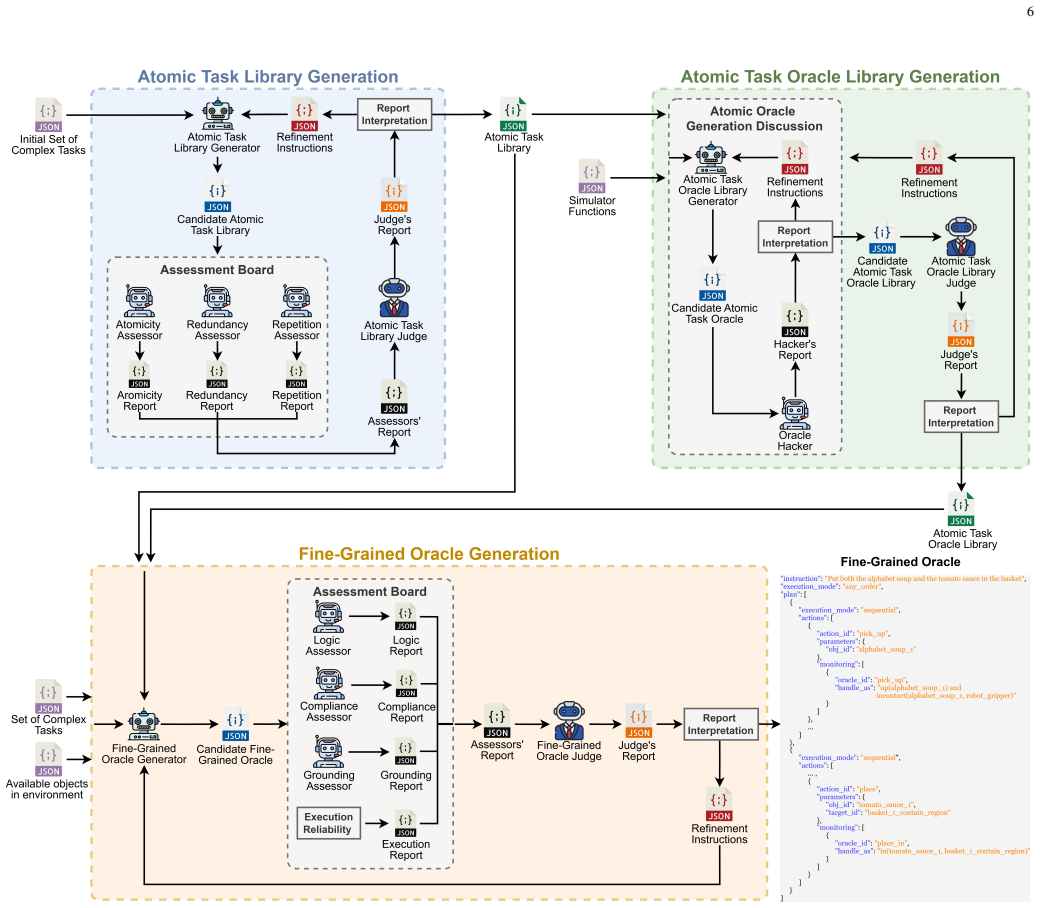
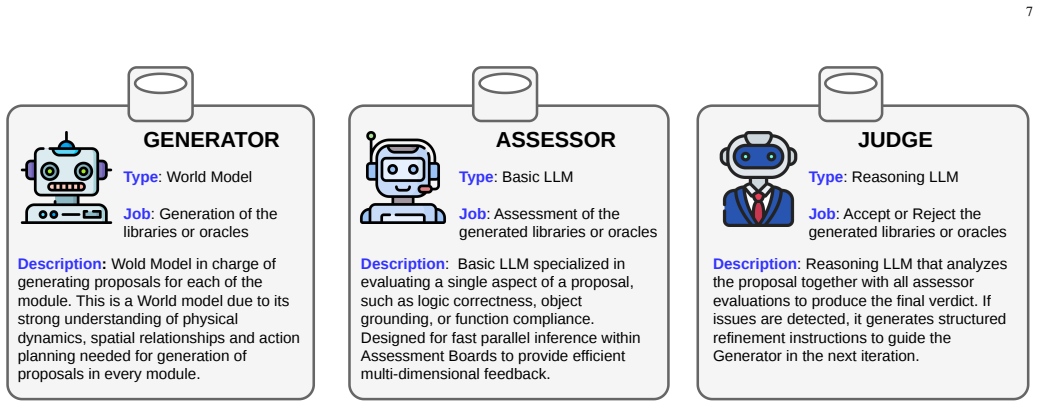
MANGO is a multi-agent framework that automatically generates fine-grained oracles from natural-language descriptions of robotic tasks. It first generates a reusable library of atomic tasks, then simulator-grounded oracle definitions for each atomic task, and finally produces executable fine-grained oracles by decomposing complex instructions into ordered sequences of atomic actions and corresponding oracles. The framework uses collaborative Generator, Assessor, and Judge agents that iteratively refine generated artifacts through structured feedback. On the LIBERO_10 and RoboCasa Humanoid Tabletop benchmarks, MANGO produces oracles that detect a similar number of failures as symbolic oracles
What carries the argument
The collaborative Generator, Assessor, and Judge agents that iteratively refine generated artifacts through structured feedback to produce simulator-grounded oracle definitions from natural language task descriptions.
Load-bearing premise
The multi-agent collaboration can reliably produce correct simulator-grounded oracles from natural language without introducing errors that invalidate failure detection and localization.
What would settle it
A concrete execution trace on a VLA model where a MANGO-generated oracle misclassifies task success or misses an intermediate failure that a symbolic oracle correctly identifies on the same trace.
Figures








read the original abstract
Vision-Language-Action (VLA) models are emerging robotic control systems that integrate perception, language understanding, and action generation in a unified architecture. Existing testing approaches for VLA-enabled robots rely on manually constructed symbolic test oracles that determine task success from final environment states. These oracles are costly to construct, require domain expertise, and are often tightly coupled to specific tasks and environments, limiting scalability and reuse. Furthermore, they provide only end-state assessments of task outcomes, offering limited insight into intermediate behavior and fault localization. To address these limitations, we introduce MANGO, a multi-agent framework that automatically generates fine-grained oracles from natural-language descriptions of robotic tasks. MANGO first generates a reusable library of atomic tasks, then generates simulator-grounded oracle definitions for each atomic task, and finally produces executable fine-grained oracles by decomposing complex instructions into ordered sequences of atomic actions and corresponding oracles. The framework uses collaborative Generator, Assessor, and Judge agents that iteratively refine generated artifacts through structured feedback. We evaluate MANGO on the LIBERO_10 and RoboCasa Humanoid Tabletop benchmarks. Results show that MANGO generates executable, fine-grained oracles that detect a similar number of failures as symbolic oracles while accurately localizing them and providing richer diagnostic information. Through ablation studies, we further analyzed component contributions and the effect of initial task set, while preserving oracle quality. Overall, the results show the feasibility and effectiveness of test oracle generation for VLA-enabled robots testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MANGO, a multi-agent LLM framework (Generator, Assessor, Judge) that automatically generates a library of atomic tasks and simulator-grounded, executable fine-grained test oracles from natural-language robotic task descriptions for Vision-Language-Action (VLA) models. It decomposes complex instructions into ordered atomic actions with corresponding oracles via iterative refinement, and evaluates the approach on the LIBERO_10 and RoboCasa Humanoid Tabletop benchmarks, claiming parity in failure detection with symbolic oracles, superior localization, richer diagnostics, and positive ablation results on component contributions and initial task sets.
Significance. If the quantitative claims hold under rigorous validation, the work could meaningfully advance scalable testing for VLA systems by reducing dependence on costly manual symbolic oracles while adding intermediate diagnostic value. The multi-agent iterative refinement and ablation analysis on task-set sensitivity represent concrete strengths in demonstrating feasibility.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the central claim of 'detect[ing] a similar number of failures as symbolic oracles while accurately localizing them' is load-bearing yet unsupported by any reported counts, precision/recall figures, or statistical comparison in the provided text; without these data the equivalence and localization advantage cannot be assessed.
- [Framework / Methodology] Framework description (Generator-Assessor-Judge loop): the iterative refinement from natural language is presented without an explicit correctness mechanism (formal state invariants, exhaustive coverage argument, or human audit protocol) that would ensure generated atomic oracles match simulator semantics; a modest error rate in oracle conditions would directly undermine both the failure-detection parity and the localization claims.
minor comments (1)
- [Abstract] The abstract mentions 'ablation studies' and 'preserving oracle quality' but does not specify the metrics used for quality preservation or the exact ablation configurations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the presentation of results and methodology.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the central claim of 'detect[ing] a similar number of failures as symbolic oracles while accurately localizing them' is load-bearing yet unsupported by any reported counts, precision/recall figures, or statistical comparison in the provided text; without these data the equivalence and localization advantage cannot be assessed.
Authors: We agree that the abstract would benefit from including explicit quantitative support for the central claim. The Evaluation section reports comparative results on the LIBERO_10 and RoboCasa benchmarks, including the number of failures detected by MANGO-generated oracles versus symbolic oracles, along with localization accuracy and diagnostic richness. To make these results immediately accessible, we will revise the abstract to state the specific failure detection counts, localization metrics, and any precision/recall equivalents or statistical comparisons from the evaluation tables and figures. revision: yes
-
Referee: [Framework / Methodology] Framework description (Generator-Assessor-Judge loop): the iterative refinement from natural language is presented without an explicit correctness mechanism (formal state invariants, exhaustive coverage argument, or human audit protocol) that would ensure generated atomic oracles match simulator semantics; a modest error rate in oracle conditions would directly undermine both the failure-detection parity and the localization claims.
Authors: The Generator-Assessor-Judge loop provides an empirical correctness mechanism: the Assessor generates and checks oracle conditions against simulator-executable states, while the Judge evaluates alignment with task semantics and issues structured feedback for iterative refinement until convergence. This is simulator-grounded by design, as oracles are directly executable. We acknowledge the absence of formal invariants or exhaustive coverage proofs, which is inherent to LLM-driven generation; instead, we rely on benchmark validation and ablations demonstrating parity in failure detection. We will revise the Framework section to explicitly detail the Judge's validation steps, discuss potential error propagation, and note the empirical safeguards used. revision: partial
Circularity Check
No circularity; empirical evaluation stands on independent benchmarks
full rationale
The paper presents an empirical framework (MANGO) whose central claims rest on experimental results from LIBERO_10 and RoboCasa benchmarks rather than any mathematical derivation, fitted parameter, or self-referential definition. No equations, uniqueness theorems, or ansatzes appear; the multi-agent process is described procedurally and evaluated externally. No load-bearing self-citation chain or renaming of known results is present in the provided text. The derivation chain is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid,et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning, pp. 2165–2183, PMLR, 2023
2023
-
[2]
Openvla: An open- source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi,et al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[3]
Gr00t n1: An open foundation model for generalist humanoid robots,
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Y...
2025
-
[4]
π 0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π 0: A vision-language-action flow model for general robot control,” 2024
2024
-
[5]
Eo- 1: Interleaved vision-text-action pretraining for general robot control,
D. Qu, H. Song, Q. Chen, Z. Chen, X. Gao, X. Ye, Q. Lv, M. Shi, G. Ren, C. Ruan, M. Yao, H. Yang, J. Bao, B. Zhao, and D. Wang, “Eo- 1: Interleaved vision-text-action pretraining for general robot control,” 2025
2025
-
[6]
Vlatest: Testing and evaluating vision-language-action models for robotic ma- nipulation,
Z. Wang, Z. Zhou, J. Song, Y . Huang, Z. Shu, and L. Ma, “Vlatest: Testing and evaluating vision-language-action models for robotic ma- nipulation,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 1615–1638, 2025
2025
-
[7]
Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks,
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang,et al., “Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 11142–11152, 2025
2025
-
[8]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,”arXiv preprint arXiv:2306.03310, 2023
Pith/arXiv arXiv 2023
-
[9]
Evaluating real-world robot manipulation policies in simulation,
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kirmani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao, “Evaluating real-world robot manipulation policies in simulation,”arXiv preprint arXiv:2405.05941, 2024
Pith/arXiv arXiv 2024
-
[10]
Evaluating uncertainty and quality of visual language action-enabled robots,
P. Valle, C. Lu, S. Ali, and A. Arrieta, “Evaluating uncertainty and quality of visual language action-enabled robots,”arXiv preprint arXiv:2507.17049, 2025
arXiv 2025
-
[11]
The oracle problem in software testing: A survey,
E. T. Barr, M. Harman, P. McMinn, M. Shahbaz, and S. Yoo, “The oracle problem in software testing: A survey,”IEEE transactions on software engineering, vol. 41, no. 5, pp. 507–525, 2014
2014
-
[12]
Libero-plus: A progressive robustness benchmark for visual-language-action models,
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei,et al., “Libero-plus: A progressive robustness benchmark for visual-language-action models,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pp. 38574–38583, 2026
2026
-
[13]
Robocasa: Large-scale simulation of ev- eryday tasks for generalist robots,
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu, “Robocasa: Large-scale simulation of ev- eryday tasks for generalist robots,”arXiv preprint arXiv:2406.02523, 2024
Pith/arXiv arXiv 2024
-
[14]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 2002
2002
-
[15]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,”Advances in neural informa- tion processing systems, vol. 25, 2012
2012
-
[16]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
Pith/arXiv arXiv 2014
-
[17]
Going deeper with convolutions,
C. Szegedy, W. Liu, Y . Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V . Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9, 2015
2015
-
[18]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[19]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat,et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[20]
Gemini: a family of highly capable multimodal models,
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican,et al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[21]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan,et al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[22]
Mistral 7b,
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023. 24
2023
-
[23]
Learning fine- grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine- grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[24]
Nebula: Do we evaluate vision-language-action agents correctly?,
J. Peng, Y . Zhang, Y . Duan, T. Liang, V . Chaudhary, and Y . Yin, “Nebula: Do we evaluate vision-language-action agents correctly?,” 2025. https: //arxiv.org/abs/2510.16263
arXiv 2025
-
[25]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, vol. 2, no. 3, p. 440, 2018
Pith/arXiv arXiv 2018
-
[26]
A step toward world models: A survey on robotic manipulation,
P.-F. Zhang, Y . Cheng, X. Sun, S. Wang, F. Li, L. Zhu, and H. T. Shen, “A step toward world models: A survey on robotic manipulation,”arXiv preprint arXiv:2511.02097, 2025
arXiv 2025
-
[27]
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Balakrishna, N. Batchelor, A. Bewley, J. Bingham, et al., “Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer,”arXiv preprint arXiv:2510.03342, 2025
Pith/arXiv arXiv 2025
-
[28]
Cosmos world foundation model platform for physical ai,
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopad- hyay, Y . Chen, Y . Cui, Y . Ding,et al., “Cosmos world foundation model platform for physical ai,”arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[29]
Understanding world or predicting future? a comprehensive survey of world models,
J. Ding, Y . Zhang, Y . Shang, Y . Zhang, Z. Zong, J. Feng, Y . Yuan, H. Su, N. Li, N. Sukiennik,et al., “Understanding world or predicting future? a comprehensive survey of world models,”ACM Computing Surveys, vol. 58, no. 3, pp. 1–38, 2025
2025
-
[30]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan,et al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[31]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram,et al., “Openai gpt-5 system card,”arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[32]
Introducing mistral 3 — mistral ai,
M. AI, “Introducing mistral 3 — mistral ai,” December 2025. https: //mistral.ai/news/mistral-3/
2025
-
[33]
Guidelines for empirical studies in software engineering involving large language models,
S. Baltes, F. Angermeir, C. Arora, M. M. Bar ´on, C. Chen, L. B ¨ohme, F. Calefato, N. Ernst, D. Falessi, B. Fitzgerald,et al., “Guidelines for empirical studies in software engineering involving large language models,”arXiv preprint arXiv:2508.15503, 2025
Pith/arXiv arXiv 2025
-
[34]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pp. 3982–3992, 2019
2019
-
[35]
Semeval- 2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation,
D. Cer, M. Diab, E. Agirre, I. Lopez-Gazpio, and L. Specia, “Semeval- 2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation,” inProceedings of the 11th international workshop on semantic evaluation (SemEval-2017), pp. 1–14, 2017
2017
-
[36]
Bertscore: Evaluating text generation with bert,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,”arXiv preprint arXiv:1904.09675, 2019
Pith/arXiv arXiv 1904
-
[37]
Rudolph,Convergence properties of evolutionary algorithms
G. Rudolph,Convergence properties of evolutionary algorithms. Verlag Dr. Kovaˇc, 1997
1997
-
[38]
On the analysis of the (1+ 1) evolutionary algorithm,
S. Droste, T. Jansen, and I. Wegener, “On the analysis of the (1+ 1) evolutionary algorithm,”Theoretical Computer Science, vol. 276, no. 1- 2, pp. 51–81, 2002
2002
-
[39]
Search-based software engineering,
M. Harman and B. F. Jones, “Search-based software engineering,” Information and software Technology, vol. 43, no. 14, pp. 833–839, 2001
2001
-
[40]
A. E. Eiben and J. E. Smith,Introduction to evolutionary computing. Springer, 2015
2015
-
[41]
Genetic algorithms in search, optimization, and ma- chine learning. addison,
D. E. Goldberg, “Genetic algorithms in search, optimization, and ma- chine learning. addison,”Reading, 1989
1989
-
[42]
J. H. Holland,Adaptation in natural and artificial systems: an intro- ductory analysis with applications to biology, control, and artificial intelligence. MIT press, 1992
1992
-
[43]
T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein,Introduction to algorithms. MIT press, 2022
2022
-
[44]
How genetic algorithms really work: I. mutation and hillclimbing,
H. Muhlenbein, “How genetic algorithms really work: I. mutation and hillclimbing,” inProc. 2nd Int. Conf. on Parallel Problem Solving from Nature, 1992, Elsevier, 1992
1992
-
[45]
Sentence embedding models for similarity detection of software requirements,
S. Das, N. Deb, A. Cortesi, and N. Chaki, “Sentence embedding models for similarity detection of software requirements,”SN Computer Science, vol. 2, no. 2, p. 69, 2021
2021
-
[46]
On termination criteria of evolutionary algorithms,
B. J. Jain, H. Pohlheim, and J. Wegener, “On termination criteria of evolutionary algorithms,” inProceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation, pp. 768–768, 2001
2001
-
[47]
An orthogonal genetic algorithm with quantization for global numerical optimization,
Y .-W. Leung and Y . Wang, “An orthogonal genetic algorithm with quantization for global numerical optimization,”IEEE Transactions on Evolutionary computation, vol. 5, no. 1, pp. 41–53, 2001
2001
-
[48]
An empirical study of the non-determinism of chatgpt in code generation,
S. Ouyang, J. M. Zhang, M. Harman, and M. Wang, “An empirical study of the non-determinism of chatgpt in code generation,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 2, pp. 1–28, 2025
2025
-
[49]
Evaluation and benchmarking of llm agents: A survey,
M. Mohammadi, Y . Li, J. Lo, and W. Yip, “Evaluation and benchmarking of llm agents: A survey,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pp. 6129– 6139, 2025
2025
-
[50]
Hallucination to consensus: Multi-agent llms for end-to-end junit test generation,
Q. Xu, G. Wang, L. Briand, and K. Liu, “Hallucination to consensus: Multi-agent llms for end-to-end junit test generation,”ACM Transactions on Software Engineering and Methodology, 2026
2026
-
[51]
Towards standardized bench- marks of llms in software modeling tasks: a conceptual framework: J. c´amara et al.,
J. C ´amara, L. Burgue ˜no, and J. Troya, “Towards standardized bench- marks of llms in software modeling tasks: a conceptual framework: J. c´amara et al.,”Software and Systems Modeling, vol. 23, no. 6, pp. 1309– 1318, 2024
2024
-
[52]
Exploring methods for evaluating group differences on the nsse and other surveys: Are the t-test and cohen’sd indices the most appropriate choices,
J. Romano, J. D. Kromrey, J. Coraggio, J. Skowronek, and L. Devine, “Exploring methods for evaluating group differences on the nsse and other surveys: Are the t-test and cohen’sd indices the most appropriate choices,” inannual meeting of the Southern Association for Institutional Research, pp. 1–51, Citeseer, 2006
2006
-
[53]
W. G. Cochran,Sampling techniques. john wiley & sons, 1977
1977
-
[54]
Spatialvla: Exploring spatial representations for visual-language-action model,
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang,et al., “Spatialvla: Exploring spatial representations for visual-language-action model,”arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[55]
Thinkact: Vision-language-action reasoning via reinforced visual latent planning,
C.-P. Huang, Y .-H. Wu, M.-H. Chen, F. Wang, and F.-E. Yang, “Thinkact: Vision-language-action reasoning via reinforced visual latent planning,”Advances in Neural Information Processing Systems, vol. 38, pp. 82782–82802, 2026
2026
-
[56]
Automated test oracles: A survey,
M. Pezze and C. Zhang, “Automated test oracles: A survey,” inAdvances in computers, vol. 95, pp. 1–48, Elsevier, 2014
2014
-
[57]
Automatic generation of oracles for exceptional behaviors,
A. Goffi, A. Gorla, M. D. Ernst, and M. Pezz `e, “Automatic generation of oracles for exceptional behaviors,” inProceedings of the 25th in- ternational symposium on software testing and analysis, pp. 213–224, 2016
2016
-
[58]
Evolutionary improvement of assertion oracles,
V . Terragni, G. Jahangirova, P. Tonella, and M. Pezz `e, “Evolutionary improvement of assertion oracles,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 1178–1189, 2020
2020
-
[59]
Generating automated and online test oracles for simulink models with continuous and uncertain behaviors,
C. Menghi, S. Nejati, K. Gaaloul, and L. C. Briand, “Generating automated and online test oracles for simulink models with continuous and uncertain behaviors,” inProceedings of the 2019 27th acm joint meeting on european software engineering conference and symposium on the foundations of software engineering, pp. 27–38, 2019
2019
-
[60]
Defining and generating multi-level and uncertainty-wise test oracles for cyber-physical systems: P. valle et al.,
P. Valle, A. Arrieta, L. Han, S. Ali, and T. Yue, “Defining and generating multi-level and uncertainty-wise test oracles for cyber-physical systems: P. valle et al.,”Software and Systems Modeling, vol. 24, no. 3, pp. 679– 704, 2025
2025
-
[61]
Toga: A neural method for test oracle generation,
E. Dinella, G. Ryan, T. Mytkowicz, and S. K. Lahiri, “Toga: A neural method for test oracle generation,” inProceedings of the 44th Interna- tional Conference on Software Engineering, pp. 2130–2141, 2022
2022
-
[62]
Using large language models to generate junit tests: An empirical study,
M. L. Siddiq, J. C. Da Silva Santos, R. H. Tanvir, N. Ulfat, F. Al Rifat, and V . Carvalho Lopes, “Using large language models to generate junit tests: An empirical study,” inProceedings of the 28th international con- ference on evaluation and assessment in software engineering, pp. 313– 322, 2024
2024
-
[63]
Togll: Correct and strong test oracle generation with llms,
S. B. Hossain and M. B. Dwyer, “Togll: Correct and strong test oracle generation with llms,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pp. 1475–1487, IEEE, 2025
2025
-
[64]
Improving deep assertion generation via fine-tuning retrieval-augmented pre-trained language models,
Q. Zhang, C. Fang, Y . Zheng, Y . Zhang, Y . Zhao, R. Huang, J. Zhou, Y . Yang, T. Zheng, and Z. Chen, “Improving deep assertion generation via fine-tuning retrieval-augmented pre-trained language models,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 7, pp. 1–23, 2025
2025
-
[65]
Chatassert: Llm-based test oracle generation with external tools assistance,
I. Hayet, A. Scott, and M. d’Amorim, “Chatassert: Llm-based test oracle generation with external tools assistance,”IEEE Transactions on Software Engineering, vol. 51, no. 1, pp. 305–319, 2024
2024
-
[66]
Augmentest: Enhancing tests with llm-driven oracles,
S. M. Khandaker, F. Kifetew, D. Prandi, and A. Susi, “Augmentest: Enhancing tests with llm-driven oracles,” in2025 IEEE Conference on Software Testing, Verification and Validation (ICST), pp. 279–289, IEEE, 2025
2025
-
[67]
Nexus: Execution-grounded multi-agent test oracle synthesis,
D. Huang, M. Du, J. M. Zhang, Z. Lin, M. Luo, Q. Zhang, and S.- K. Ng, “Nexus: Execution-grounded multi-agent test oracle synthesis,” arXiv preprint arXiv:2510.26423, 2025
arXiv 2025
-
[68]
Mastor: A multi-agent approach to semantic test oracle generation for restful apis,
S. Deng, R. Huang, Z. Yang, M. Zhang, X. Xie, and R. Wang, “Mastor: A multi-agent approach to semantic test oracle generation for restful apis,”arXiv preprint arXiv:2606.10465, 2026. 25
Pith/arXiv arXiv 2026
-
[69]
Data-driven grasp synthesis—a survey,
J. Bohg, A. Morales, T. Asfour, and D. Kragic, “Data-driven grasp synthesis—a survey,”IEEE Transactions on robotics, vol. 30, no. 2, pp. 289–309, 2013
2013
-
[70]
J. Mahler, J. Liang, S. Niyaz, M. Laskey, R. Doan, X. Liu, J. A. Ojea, and K. Goldberg, “Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics,”arXiv preprint arXiv:1703.09312, 2017
Pith/arXiv arXiv 2017
-
[71]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition, pp. 248–255, Ieee, 2009
2009
-
[72]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean conference on computer vision, pp. 740–755, Springer, 2014
2014
-
[73]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, pp. 311–318, 2002
2002
-
[74]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” inText summarization branches out, pp. 74–81, 2004
2004
-
[75]
Exploring the limits of vision-language-action manipulations in cross-task generalization,
J. Zhou, K. Ye, J. Liu, T. Ma, Z. Wang, R. Qiu, K.-Y . Lin, Z. Zhao, and J. Liang, “Exploring the limits of vision-language-action manipulations in cross-task generalization,”arXiv preprint arXiv:2505.15660, 2025
arXiv 2025
-
[76]
I. Fang, J. Zhang, S. Tong, and C. Feng, “From intention to execution: Probing the generalization boundaries of vision-language-action mod- els,”arXiv preprint arXiv:2506.09930, 2025
arXiv 2025
-
[77]
Task reconstruction and extrapolation for\pi 0using text latent,
Q. Li, “Task reconstruction and extrapolation for\pi 0using text latent,”arXiv preprint arXiv:2505.03500, 2025
Pith/arXiv arXiv 2025
-
[78]
Rlbench: The robot learning benchmark & learning environment,
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison, “Rlbench: The robot learning benchmark & learning environment,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3019–3026, 2020
2020
-
[79]
Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard, “Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 7327–7334, 2022
2022
-
[80]
Z. Wang, Z. Zhou, J. Song, Y . Huang, Z. Shu, and L. Ma, “Ladev: A language-driven testing and evaluation platform for vision- language-action models in robotic manipulation,”arXiv preprint arXiv:2410.05191, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.