GeoT2V-Bench: Benchmarking 3D Consistency in Text-to-Video Models via 3D Reconstruction
Pith reviewed 2026-06-26 00:26 UTC · model grok-4.3
The pith
A benchmark reconstructs 3D scenes from camera-prompted text-to-video clips to expose inconsistencies across multiple metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
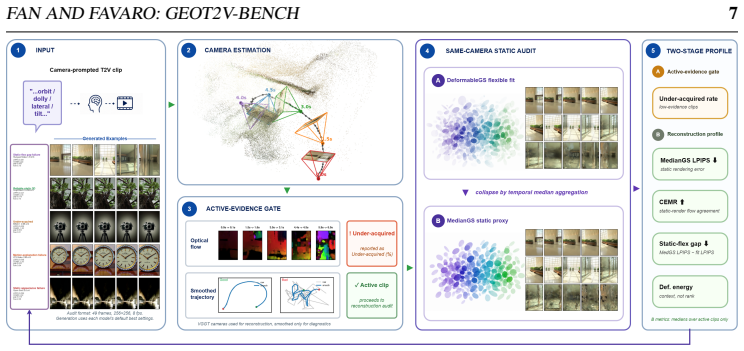
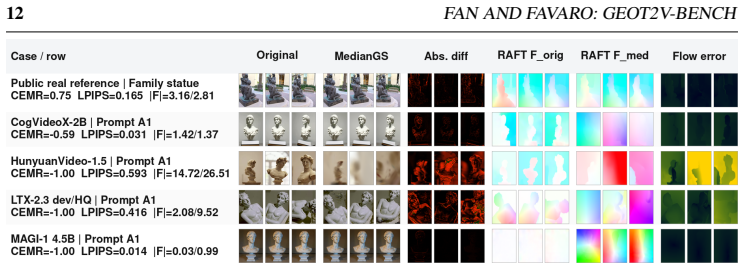
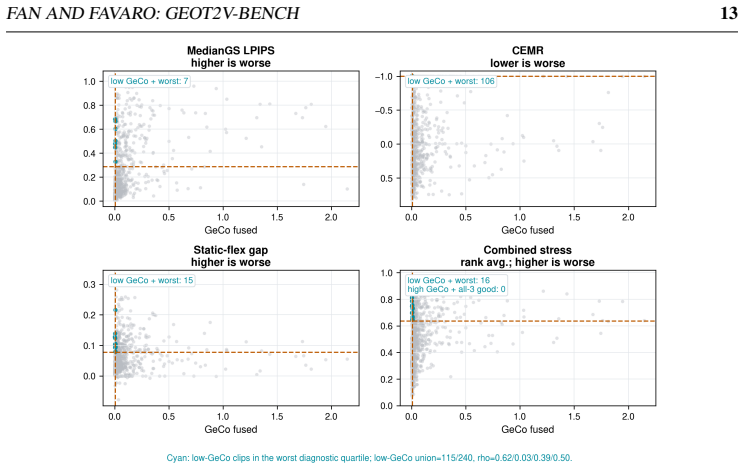
Camera-prompted T2V clips should supply coherent multi-view evidence for a single static 3D scene. GeoT2V-Bench estimates per-frame intrinsics and poses, fits DeformableGS, derives a static MedianGS proxy via temporal median, renders the proxy along the estimated path, and reports a continuous profile of apparent image motion, trajectory behavior, MedianGS static rendering error, static-render flow agreement, and the flexible-versus-static gap. On 3,840 reconstructions from 12 model configurations and 80 static-scene prompts, visible motion, static rendering error, flow agreement, and flexible-vs-static behavior often disagree, revealing complementary failure modes when videos are treated as
What carries the argument
The reconstruction pipeline that estimates per-frame camera intrinsics and poses, fits DeformableGS, derives a static MedianGS proxy by temporal-median aggregation, and renders this proxy to compute multiple consistency metrics.
If this is right
- T2V outputs can be evaluated directly as attempts to acquire a global static scene rather than judged only by visual plausibility.
- Single scalar scores or pass/fail labels miss distinct failure modes that appear only when multiple reconstruction-derived measures are compared.
- Models may generate videos that look locally correct yet still disagree on whether they support one rigid 3D structure.
- Benchmarking should track a profile of metrics instead of reducing consistency to one number.
Where Pith is reading between the lines
- Training objectives that improve one consistency signal may leave the others unchanged unless all signals are optimized together.
- The same reconstruction-profile approach could be adapted to test consistency in other generative settings such as image-to-video or text-to-3D.
- Disagreements among the metrics suggest that current models lack an internal representation of global scene rigidity.
Load-bearing premise
VGGT-style geometry estimation can still recover reliable camera intrinsics and poses from videos that contain 3D inconsistencies.
What would settle it
A collection of generated videos in which all five reported metrics rank the same models as most and least consistent, yet independent ground-truth 3D checks show the videos actually come from inconsistent scenes.
Figures

read the original abstract
Camera-prompted text-to-video (T2V) models are increasingly used to synthesize virtual camera captures, such as orbiting objects or moving through static scenes. For these outputs, visual plausibility is insufficient: the generated frames should also provide coherent multi-view evidence for a single static 3D scene. We introduce GeoT2V-Bench, a reconstruction-based diagnostic benchmark for evaluating whether camera-prompted T2V clips can support explicit rigid 3D reconstruction. Our pipeline estimates per-frame camera intrinsics and poses with VGGT-style geometry estimation, fits DeformableGS, derives a static MedianGS proxy by temporal-median aggregation, and renders this proxy along the estimated camera path. Instead of producing a pass/fail label or a single scalar score, GeoT2V-Bench reports a continuous reconstruction profile covering apparent image motion, estimated trajectory behavior, MedianGS static rendering error, static-render flow agreement, and the gap between flexible and static fits. On a fair-format four-seed evaluation with 3,840 completed reconstructions from 12 open-weight model configurations and 80 GeCo-Eval static-scene prompts, we find that visible motion, static rendering error, flow agreement, and flexible-vs-static behavior often disagree. GeoT2V-Bench therefore captures complementary failure modes that emerge when generated videos are tested as global static-scene acquisitions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoT2V-Bench, a reconstruction-based diagnostic for 3D consistency in camera-prompted text-to-video models. The pipeline applies VGGT-style per-frame intrinsics/pose estimation to generated videos, fits DeformableGS, derives a static MedianGS proxy via temporal median aggregation, and computes a profile of five quantities (apparent image motion, estimated trajectory behavior, MedianGS static rendering error, static-render flow agreement, and flexible-vs-static fit gap). On 3,840 reconstructions from 12 open-weight models and 80 GeCo-Eval static-scene prompts (four seeds), the metrics frequently disagree, which the authors interpret as evidence that the benchmark captures complementary failure modes when T2V outputs are treated as static-scene acquisitions.
Significance. If the metrics are shown to isolate T2V 3D consistency rather than artifacts of the reconstruction pipeline, the work supplies a multi-metric diagnostic that goes beyond single-score or visual-plausibility evaluations. The scale of the evaluation (12 models, 80 prompts, 3,840 reconstructions) and the explicit reporting of continuous, disagreeing quantities are concrete strengths that would make the benchmark useful for model development if the validity concerns are resolved.
major comments (3)
- [Methods] Methods (pipeline description): All five reported quantities depend on VGGT-style per-frame camera estimation performed directly on the T2V videos. No validation or ablation is described that tests VGGT robustness on inputs known to violate rigidity or multi-view consistency (e.g., synthetic videos with controlled inconsistencies). Because downstream metrics (MedianGS error, flow agreement, flexible-static gap) are computed from these estimates, disagreement among them could reflect VGGT failure modes interacting with T2V artifacts rather than intrinsic T2V 3D inconsistency. This assumption is load-bearing for the central claim that the benchmark captures complementary T2V failure modes.
- [Results] Results (evaluation on 3,840 reconstructions): The claim that 'visible motion, static rendering error, flow agreement, and flexible-vs-static behavior often disagree' is presented without quantitative support such as pairwise correlation coefficients, disagreement rates, or contingency tables across the full set of reconstructions. Without these statistics it is difficult to judge the degree of complementarity or whether the observed disagreements are systematic or dominated by a subset of prompts/models.
- [Methods] Methods (MedianGS construction): The temporal-median aggregation used to obtain the static MedianGS proxy assumes that per-frame inconsistencies average to a coherent static scene. No analysis is provided of cases where T2V errors are temporally correlated (e.g., consistent depth drift or object deformation), which would violate this assumption and directly affect the static rendering error and flow-agreement metrics.
minor comments (3)
- [Methods] The exact operational definitions and formulas for 'visible motion,' 'trajectory behavior,' and 'flow agreement' should be stated explicitly (ideally with equations) rather than described at a high level.
- [Evaluation setup] Clarify how the 80 GeCo-Eval static-scene prompts were selected and whether they were filtered for any properties that might interact with VGGT assumptions.
- [Figures] Figure captions and axis labels for the reconstruction-profile plots should include the precise metric definitions and the number of samples per condition.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address each of the major comments below, providing clarifications and indicating planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Methods] Methods (pipeline description): All five reported quantities depend on VGGT-style per-frame camera estimation performed directly on the T2V videos. No validation or ablation is described that tests VGGT robustness on inputs known to violate rigidity or multi-view consistency (e.g., synthetic videos with controlled inconsistencies). Because downstream metrics (MedianGS error, flow agreement, flexible-static gap) are computed from these estimates, disagreement among them could reflect VGGT failure modes interacting with T2V artifacts rather than intrinsic T2V 3D inconsistency. This assumption is load-bearing for the central claim that the benchmark captures complementary T2V failure modes.
Authors: We acknowledge that the robustness of VGGT on non-rigid or inconsistent inputs is a critical assumption. While VGGT is designed for general scenes, we agree that explicit validation on synthetic videos with controlled inconsistencies would strengthen the claim. We will add an ablation study using synthetic data to evaluate VGGT's behavior under varying degrees of multi-view inconsistency, and discuss how this impacts the interpretation of the benchmark metrics. revision: yes
-
Referee: [Results] Results (evaluation on 3,840 reconstructions): The claim that 'visible motion, static rendering error, flow agreement, and flexible-vs-static behavior often disagree' is presented without quantitative support such as pairwise correlation coefficients, disagreement rates, or contingency tables across the full set of reconstructions. Without these statistics it is difficult to judge the degree of complementarity or whether the observed disagreements are systematic or dominated by a subset of prompts/models.
Authors: The referee is correct that the manuscript relies on a qualitative statement regarding disagreements without providing quantitative measures. To address this, we will include pairwise correlation coefficients, disagreement rates, and contingency tables in the revised results section to quantify the complementarity of the metrics across the 3,840 reconstructions. revision: yes
-
Referee: [Methods] Methods (MedianGS construction): The temporal-median aggregation used to obtain the static MedianGS proxy assumes that per-frame inconsistencies average to a coherent static scene. No analysis is provided of cases where T2V errors are temporally correlated (e.g., consistent depth drift or object deformation), which would violate this assumption and directly affect the static rendering error and flow-agreement metrics.
Authors: This is a valid concern regarding the assumptions underlying MedianGS. We will add a discussion and, where possible, an analysis of scenarios with temporally correlated errors, such as consistent deformations, to clarify the limitations and robustness of the MedianGS proxy. revision: yes
Circularity Check
No circularity: benchmark metrics are independently defined from reconstruction pipeline
full rationale
The paper defines GeoT2V-Bench as a set of complementary metrics (apparent motion, trajectory behavior, MedianGS error, flow agreement, flexible-static gap) computed after VGGT estimation and DeformableGS fitting on generated videos. The central claim—that these quantities often disagree—is an empirical observation from 3,840 reconstructions, not a derivation that reduces to its inputs by construction. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The pipeline's reliance on VGGT is explicitly noted as an assumption rather than smuggled in. This is a standard empirical benchmark with independent content against external T2V outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VGGT-style geometry estimation can reliably estimate camera intrinsics and poses from generated video frames
invented entities (1)
-
MedianGS proxy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Met3r: Measuring multi-view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. Met3r: Measuring multi-view consistency in generated images. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6034–6044, 2025
2025
-
[2]
Nithin C Babu, Aniruddha Mahapatra, Harsh Rangwani, Rajiv Soundararajan, and Kuldeep Kulkarni. Dynamiceval: Rethinking evaluation for dynamic text-to-video syn- thesis.arXiv preprint arXiv:2510.07441, 2025
-
[3]
Vd3d: Taming large video diffusion transformers for 3d camera control
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, FAN AND FA V ARO: GEOT2V -BENCH33 Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, et al. Vd3d: Taming large video diffusion transformers for 3d camera control. InInternational Conference on Learning Representations, volume 2025, pages ...
2025
-
[4]
Bookstein
Fred L. Bookstein. Principal warps: Thin-plate splines and the decomposition of de- formations.IEEE Transactions on pattern analysis and machine intelligence, 11(6): 567–585, 2002
2002
-
[5]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite- length film generative model.arXiv preprint arXiv:2504.13074, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Worldscore: A unified evaluation benchmark for world generation
Haoyi Duan, Hong-Xing Yu, Sirui Chen, Li Fei-Fei, and Jiajun Wu. Worldscore: A unified evaluation benchmark for world generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27713–27724, 2025
2025
-
[7]
Instantsplat: Unbounded sparse-view pose-free gaussian splatting in 40 seconds, 2024
Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, Boris Ivanovic, Marco Pavone, Georgios Pavlakos, Zhangyang Wang, and Yue Wang. Instantsplat: Unbounded sparse-view pose-free gaussian splatting in 40 seconds, 2024
2024
-
[8]
Two-frame motion estimation based on polynomial expansion
Gunnar Farnebäck. Two-frame motion estimation based on polynomial expansion. In Scandinavian conference on Image analysis, pages 363–370. Springer, 2003
2003
-
[9]
GeCo: Evaluating Geometric Consistency for Video Generation via Motion and Structure
Leslie Gu, Junhwa Hur, Charles Herrmann, Fangneng Zhan, Todd Zickler, Deqing Sun, and Hanspeter Pfister. Geco: A differentiable geometric consistency metric for video generation.arXiv preprint arXiv:2512.22274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Ei- tan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Training-free camera control for video generation.arXiv preprint arXiv:2406.10126, 2024
Chen Hou and Zhibo Chen. Training-free camera control for video generation.arXiv preprint arXiv:2406.10126, 2024
-
[14]
Vbench: Comprehen- sive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehen- sive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 34FAN AND FA V ARO: GEOT2V -BENCH
2024
-
[15]
Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2025
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, et al. Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2025
2025
-
[16]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4): 139–1, 2023
2023
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
2017
-
[20]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[22]
CalibAnyView: Beyond Single-View Camera Calibration in the Wild
Boying Li, Cheng Zhang, Weirong Chen, Daniel Cremers, Ian Reid, and Hamid Rezatofighi. Calibanyview: Beyond single-view camera calibration in the wild.arXiv preprint arXiv:2605.14615, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Sora generates videos with stunning geometrical consistency.arXiv preprint arXiv:2402.17403, 2024
Xuanyi Li, Daquan Zhou, Chenxu Zhang, Shaodong Wei, Qibin Hou, and Ming-Ming Cheng. Sora generates videos with stunning geometrical consistency.arXiv preprint arXiv:2402.17403, 2024
-
[24]
Reconx: Reconstruct any scene from sparse views with video diffusion model.IEEE Transactions on Image Processing, 2026
Fangfu Liu, Wenqiang Sun, Hanyang Wang, Yikai Wang, Haowen Sun, Junliang Ye, Jun Zhang, and Yueqi Duan. Reconx: Reconstruct any scene from sparse views with video diffusion model.IEEE Transactions on Image Processing, 2026
2026
-
[25]
Evalcrafter: Benchmark- ing and evaluating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmark- ing and evaluating large video generation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22139–22149, 2024
2024
-
[26]
Smoothing and differentiation of data by simplified least squares procedures.Analytical chemistry, 36(8):1627–1639, 1964
Abraham Savitzky and Marcel JE Golay. Smoothing and differentiation of data by simplified least squares procedures.Analytical chemistry, 36(8):1627–1639, 1964
1964
-
[27]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016. FAN AND FA V ARO: GEOT2V -BENCH35
2016
-
[28]
The proof and measurement of association between two things., 1961
Charles Spearman. The proof and measurement of association between two things., 1961
1961
-
[29]
T2v-compbench: A comprehensive benchmark for compositional text-to-video gener- ation
Kaiyue Sun, Kaiyi Huang, Xian Liu, Yue Wu, Zihan Xu, Zhenguo Li, and Xihui Liu. T2v-compbench: A comprehensive benchmark for compositional text-to-video gener- ation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8406–8416, 2025
2025
-
[30]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on computer vision, pages 402–419. Springer, 2020
2020
-
[31]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video gener- ation at scale.arXiv preprint arXiv:2505.13211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[34]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[35]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[36]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[37]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report. arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Gmflow: Learning optical flow via global matching
Haofei Xu, Jing Zhang, Jianfei Cai, Hamid Rezatofighi, and Dacheng Tao. Gmflow: Learning optical flow via global matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8121–8130, 2022
2022
-
[39]
Cogvideox: Text- to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text- to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations, volume 2025, pages 83048–83077, 2025
2025
-
[40]
Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20331–20341, 2024. 36FAN AND FA V ARO: GEOT2V -BENCH
2024
-
[41]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[42]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuan- han Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video gen- eration benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Zangwei Zheng, Xiangyu Peng, Yuxuan Lou, Chenhui Shen, Tom Young, Xiny- ing Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, et al. Open-sora 2.0: Training a commercial-level video generation model in $200k.arXiv preprint arXiv:2503.09642, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.