EmotionAI: A Privacy-Preserving Computational Intelligence Pipeline for Speech-Emotion-Grounded Conversational Analysis
Pith reviewed 2026-06-26 06:03 UTC · model grok-4.3
The pith
A fully local pipeline couples imperfect speech-emotion recognition with adversarial local LLMs to deliver timestamp-grounded conversational analysis from recorded interviews.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a complete local computational intelligence pipeline can integrate speaker diarisation, automatic speech recognition, emotion classification, and an adversarial panel of local large language models to produce timestamp-grounded and citation-constrained answers to questions about conversational affect, all without any external network calls, as shown by its execution on CPU hardware.
What carries the argument
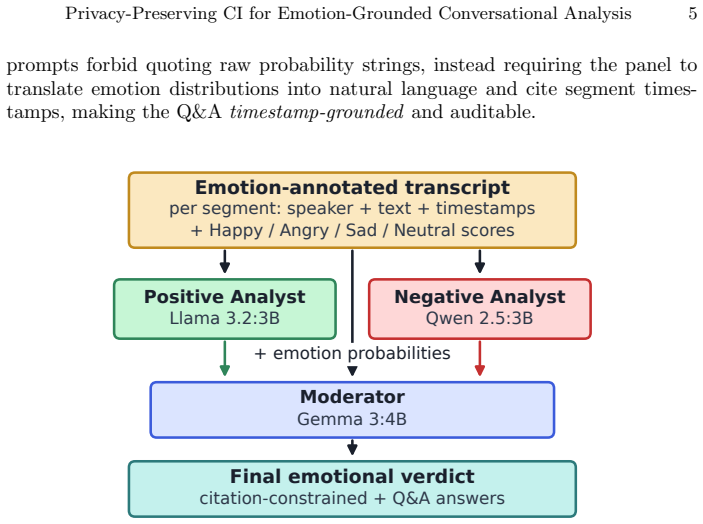
The adversarial three-model local LLM panel that consumes per-segment affective evidence to enforce citation-constrained question answering.
Load-bearing premise
That the affective evidence from a classifier with only 48.8% accuracy is still sufficient to drive useful question answering in the local LLM panel.
What would settle it
Running the LLM panel on the same audio segments but with shuffled or random emotion labels and measuring whether the quality and grounding of the generated answers degrades compared to using the actual classifier outputs.
Figures


read the original abstract
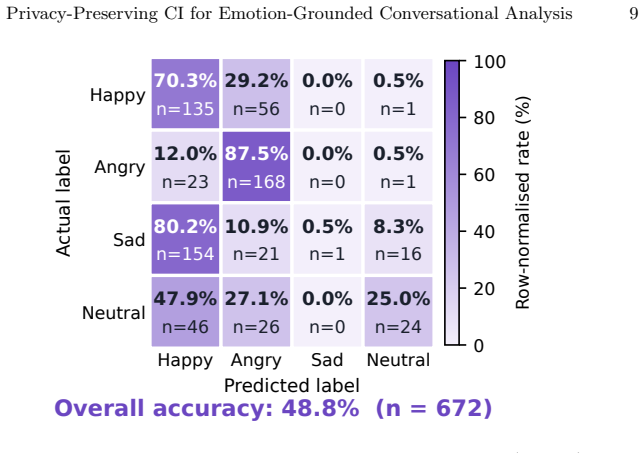
Reviewing recorded interviews for affective cues such as composure, hesitation and agitation is slow and subjective, and cloud services that could automate it require sensitive audio to leave the device. EmotionAI is a fully local Computational Intelligence (CI) pipeline that couples Speech Emotion Recognition (SER) with generative reasoning. Speaker diarisation, Whisper Automatic Speech Recognition (ASR) and a wav2vec2 emotion classifier produce per-segment affective evidence, which is then passed to an adversarial three-model local Large Language Model (LLM) panel for timestamp-grounded and citation-constrained question answering. Zero-shot evaluation on the RAVDESS four-class English subset (n = 672) exposes cross-corpus fragility rather than classifier superiority: the deployed classifier scores 48.8% accuracy, above random (24.9%) and majority (28.6%) baselines but below an in-domain MFCC + logistic-regression comparator (71.0%). The complete pipeline runs in a mean 157 s on CPU (real-time factor approximately 1.33) with zero external calls. The contribution is not state-of-the-art SER but an auditable, privacy-preserving integration of imperfect affective evidence into grounded conversational analysis, together with an honest empirical account of where cross-corpus transfer and human-centred validation still fall short.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents EmotionAI as a fully local Computational Intelligence pipeline coupling speaker diarisation, Whisper ASR, and a wav2vec2 SER classifier to generate per-segment affective evidence that is fed to an adversarial three-model local LLM panel for timestamp-grounded and citation-constrained question answering on interview recordings. Zero-shot evaluation on the RAVDESS four-class English subset (n=672) yields 48.8% SER accuracy (above random 24.9% and majority 28.6% baselines but below an in-domain MFCC+logistic regression comparator at 71.0%), with the full pipeline running in a mean 157 s on CPU (RTF ≈1.33) and zero external calls. The stated contribution is the auditable integration of imperfect affective evidence rather than SOTA SER performance, accompanied by explicit acknowledgment of cross-corpus fragility.
Significance. If the LLM panel component functions as claimed, the work would demonstrate a practical privacy-preserving route to affective conversational analysis that keeps sensitive audio on-device. Credit is due for the reproducible use of a public dataset, direct CPU runtime measurement, and transparent reporting of SER limitations instead of overstated claims. The significance remains provisional, however, because the utility of feeding the reported SER evidence into generative reasoning is untested.
major comments (2)
- [Abstract] Abstract: the central claim that the pipeline produces 'timestamp-grounded and citation-constrained question answering' via the adversarial LLM panel receives no quantitative metrics, qualitative examples, citation-accuracy checks, or human ratings, even though the abstract itself notes the 48.8% SER accuracy and known cross-corpus fragility of wav2vec2; this evaluation gap is load-bearing for the integration contribution.
- [Evaluation section] Evaluation section: no results are supplied for the generative component despite the explicit weakest assumption that 'the output of the emotion classifier provides usable input for the LLM panel's reasoning'; without such data the claim that imperfect per-segment evidence supports useful conversational analysis cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the reproducible and transparent elements of the work. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the pipeline produces 'timestamp-grounded and citation-constrained question answering' via the adversarial LLM panel receives no quantitative metrics, qualitative examples, citation-accuracy checks, or human ratings, even though the abstract itself notes the 48.8% SER accuracy and known cross-corpus fragility of wav2vec2; this evaluation gap is load-bearing for the integration contribution.
Authors: We agree that the abstract and manuscript do not supply quantitative metrics, qualitative examples, or human ratings for the LLM panel outputs. The empirical evaluation is deliberately limited to the SER component and end-to-end CPU runtime because these are the quantifiable technical contributions; the LLM panel is presented as the integration mechanism rather than a validated reasoning system. We will revise the abstract to clarify the scope of the evaluated contribution and add a new subsection with illustrative LLM panel outputs (including timestamp grounding and citation examples) to demonstrate the intended use of the affective evidence. revision: yes
-
Referee: [Evaluation section] Evaluation section: no results are supplied for the generative component despite the explicit weakest assumption that 'the output of the emotion classifier provides usable input for the LLM panel's reasoning'; without such data the claim that imperfect per-segment evidence supports useful conversational analysis cannot be assessed.
Authors: The evaluation section indeed contains no results or examples from the generative LLM component, and the manuscript does not test whether the 48.8% SER evidence is usable for downstream reasoning. This reflects the paper's focus on the privacy-preserving pipeline architecture and the documented cross-corpus limitations of the SER stage. We will expand the evaluation section to include concrete examples of LLM panel reasoning that incorporate the per-segment affective labels, together with an explicit statement that formal assessment of reasoning utility and human ratings remain future work. revision: yes
Circularity Check
No circularity; pipeline uses external public dataset evaluation with no self-referential equations or fitted predictions
full rationale
The paper describes an engineering pipeline (diarisation + ASR + wav2vec2 SER feeding an LLM panel) and reports SER accuracy on the public RAVDESS dataset against independent baselines (random 24.9%, majority 28.6%, in-domain 71.0%). No equations, parameters, or claims are defined in terms of outputs or fitted inside the paper itself. LLM panel outputs receive no quantitative evaluation, but this is a completeness gap rather than circularity. Self-citations are absent from the provided text. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained models such as Whisper and wav2vec2 can be executed locally on CPU for the described tasks.
- ad hoc to paper The output of the emotion classifier provides usable input for the LLM panel's reasoning.
Reference graph
Works this paper leans on
-
[1]
Aloufi, R., Haddadi, H., Boyle, D.: Configurable privacy-preserving au- tomatic speech recognition. In: Interspeech 2021. pp. 861–865 (2021). https://doi.org/10.21437/Interspeech.2021-1783
-
[2]
Proceedings of the IEEE113(7), 668–692 (2025)
B¨ ackstr¨ om, T.: Privacy in speech technology. Proceedings of the IEEE113(7), 668–692 (2025). https://doi.org/10.1109/JPROC.2025.3632102
-
[3]
In: Advances in Neural Information Processing Systems 33 (NeurIPS 2020)
Baevski, A., et al.: wav2vec 2.0: A framework for self-supervised learning of speech representations. In: Advances in Neural Information Processing Systems 33 (NeurIPS 2020). pp. 12449–12460 (2020)
2020
-
[4]
Bredin, H., et al.: pyannote.audio: Neural building blocks for speaker diarization. In: ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 7124–7128 (2020). https://doi.org/10.1109/ICASSP40776.2020.9052974 12 W. L. Mak, I. K. Ihianle, P. Machado
-
[5]
Official Jour- nal of the European Union, OJ L, 2024/1689, 12 July 2024 (2024), ELI: http: //data.europa.eu/eli/reg/2024/1689/oj
European Parliament and Council: Regulation (EU) 2024/1689 laying down har- monised rules on artificial intelligence (Artificial Intelligence Act). Official Jour- nal of the European Union, OJ L, 2024/1689, 12 July 2024 (2024), ELI: http: //data.europa.eu/eli/reg/2024/1689/oj
2024
-
[6]
arXiv preprint arXiv:2503.19786 (2025)
Gemma Team: Gemma 3 technical report. arXiv preprint arXiv:2503.19786 (2025)
Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2407.21783 (2024)
Grattafiori, A., et al.: The Llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[8]
Neural Computing and Applications34(20), 17581–17599 (2022)
Ibrahim, H., et al.: Bidirectional parallel echo state network for speech emo- tion recognition. Neural Computing and Applications34(20), 17581–17599 (2022). https://doi.org/10.1007/s00521-022-07410-2
-
[9]
https://ico.org.uk/for-organisations/ uk-gdpr-guidance-and-resources/ (2021), accessed: 2026-05-29
Information Commissioner’s Office: UK General Data Protection Regula- tion (UK GDPR) guidance and resources. https://ico.org.uk/for-organisations/ uk-gdpr-guidance-and-resources/ (2021), accessed: 2026-05-29
2021
-
[10]
AI and Ethics2(3), 477–491 (Aug 2022)
Katirai, A.: Ethical considerations in emotion recognition technologies: A review of the literature. AI and Ethics4(4), 927–948 (2024). https://doi.org/10.1007/s43681- 023-00307-3
-
[11]
Lashkarashvili, N., et al.: Parameter efficient finetuning for speech emotion recog- nition and domain adaptation. In: ICASSP 2024 – IEEE International Con- ference on Acoustics, Speech and Signal Processing. pp. 10986–10990 (2024). https://doi.org/10.1109/ICASSP48485.2024.10446272
-
[12]
Li, Y., Bell, P., Lai, C.: Speech emotion recognition with ASR transcripts: A comprehensive study on word error rate and fusion techniques. In: 2024 IEEE Spoken Language Technology Workshop (SLT). pp. 518–525 (2024). https://doi.org/10.1109/SLT61566.2024.10832143
-
[13]
Lin, G.T., et al.: Paralinguistics-enhanced large language modeling of spoken dialogue. In: ICASSP 2024 – IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 10316–10320 (2024). https://doi.org/10.1109/ICASSP48485.2024.10446933
-
[14]
Livingstone, S.R., Russo, F.A.: The Ryerson audio-visual database of emo- tional speech and song (RAVDESS). PLOS ONE13(5), e0196391 (2018). https://doi.org/10.1371/journal.pone.0196391
-
[15]
Applied Sciences15(10), 5731 (2025)
O’Shaughnessy, D.: Review of automatic estimation of emotions in speech. Applied Sciences15(10), 5731 (2025). https://doi.org/10.3390/app15105731
-
[16]
arXiv preprint arXiv:2412.15115 (2025)
Qwen Team: Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2025)
Pith/arXiv arXiv 2025
-
[17]
In: Proceedings of the 40th International Conference on Machine Learning (ICML)
Radford, A., et al.: Robust speech recognition via large-scale weak supervision. In: Proceedings of the 40th International Conference on Machine Learning (ICML). Proceedings of Machine Learning Research, vol. 202, pp. 28492–28518 (2023)
2023
-
[18]
Journal of Personality and Social Psychology39(6), 1161–1178 (1980)
Russell, J.A.: A circumplex model of affect. Journal of Personality and Social Psychology39(6), 1161–1178 (1980). https://doi.org/10.1037/h0077714
-
[19]
arXiv preprint arXiv:1709.00396 (2017)
Sedenberg, E., Chuang, J.: Smile for the camera: Privacy and policy implications of emotion AI. arXiv preprint arXiv:1709.00396 (2017)
Pith/arXiv arXiv 2017
-
[20]
Speech Communication 40(1–2), 213–225 (2003)
Ten Bosch, L.: Emotions, speech and the ASR framework. Speech Communication 40(1–2), 213–225 (2003). https://doi.org/10.1016/S0167-6393(02)00083-3
-
[21]
arXiv preprint arXiv:2508.14130 (2025)
Thimonier, H., Perzo, A., Seguier, R.: EmoSLLM: Parameter-efficient adaptation of LLMs for speech emotion recognition. arXiv preprint arXiv:2508.14130 (2025)
arXiv 2025
-
[22]
doi:10.1109/ICASSP49357.2023.10095889 , abstract =
Wang, H., et al.: WeSpeaker: A research and production oriented speaker embedding learning toolkit. In: ICASSP 2023 – IEEE International Con- ference on Acoustics, Speech and Signal Processing. pp. 1–5 (2023). https://doi.org/10.1109/ICASSP49357.2023.10096626
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.