Learning Diachronic Representations of Ancient Greek Letterforms
Pith reviewed 2026-06-26 00:30 UTC · model grok-4.3
The pith
Similarity-weighted contrastive loss plus lacuna augmentations produces embeddings that separate ancient Greek letter classes across centuries and visualize their evolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A similarity-weighted supervised contrastive loss that uses dynamically estimated inter-class similarities, combined with a lacuna-driven augmentation scheme that simulates realistic manuscript corruptions, enables both a lightweight CNN and a pretrained ResNet to achieve strong recognition performance on three new diachronic Greek letter datasets (Hell-Char, PaLit-Char, Med-Char) while producing embeddings that separate character classes more coherently than PCA or generic pretrained models; these embeddings further support clustering, identification of stylistic subgroups, and construction of prototype images that visualize diachronic evolution and transitional letterforms.
What carries the argument
The similarity-weighted supervised contrastive loss, which biases embeddings using dynamically estimated inter-class similarities, together with the lacuna-driven augmentation scheme.
If this is right
- Embeddings support clustering of letter instances across periods.
- Embeddings allow identification of stylistic subgroups within a given century range.
- Prototype images constructed from the embeddings visualize diachronic evolution and transitional letterforms.
- The same strategies produce robust representations under scarce, temporally evolving, and noisy conditions.
Where Pith is reading between the lines
- The same loss and augmentation design could be tested on other historical scripts that exhibit gradual visual change, such as Latin or Arabic paleography.
- Prototype images might serve as quantitative references for dating undated manuscripts by measuring distance to period-specific centroids.
- Improved separation of classes could directly raise accuracy in downstream optical character recognition pipelines for medieval Greek texts.
Load-bearing premise
That dynamically estimated inter-class similarities supply a reliable and stable bias for the contrastive loss and that lacuna-driven augmentations sufficiently capture the distribution of real manuscript degradations in the evaluation sets.
What would settle it
If embeddings trained with the proposed loss and augmentations fail to separate character classes more coherently than PCA on the PaLit-Char or Med-Char sets, or if the generated prototypes do not align with known historical transitions, the central claim is falsified.
Figures




read the original abstract
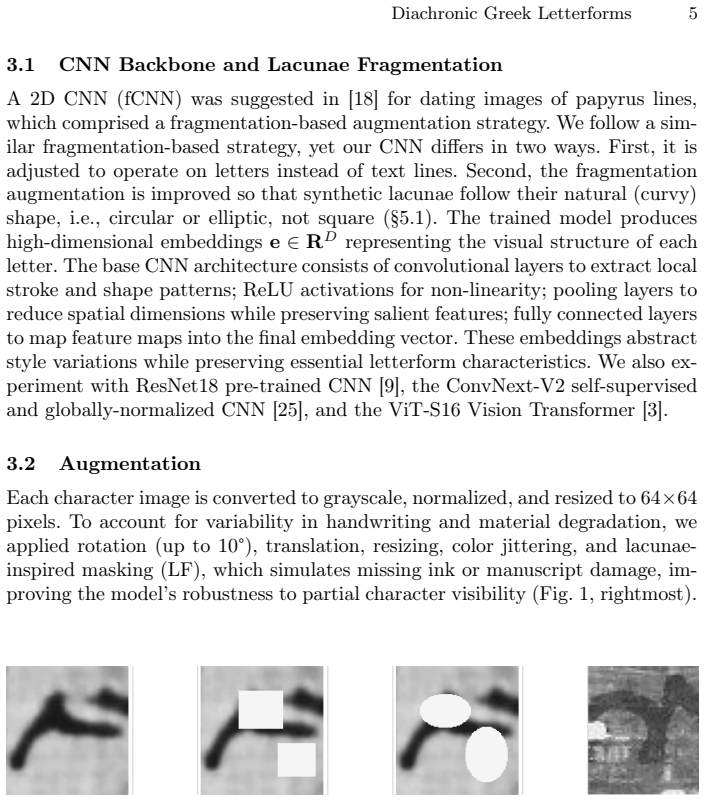
Learning representations that remain robust across centuries of variation in handwriting is a key challenge in diachronic representation learning. Taking one of the longest continuously used writing systems, ancient Greek, as a case study, we introduce three datasets for diachronic representation learning: Hell-Char, a curated training set spanning the 3rd-1st centuries BCE, and two evaluation sets, PaLit-Char (2nd-5th c. CE) and Med-Char (9th-14th c. CE). To address the challenges of symbolic variation, scarce data, and systematic degradation, we propose: a similarity-weighted supervised contrastive loss that biases embeddings using dynamically estimated inter-class similarities, and a lacuna-driven augmentation scheme that simulates realistic manuscript corruptions. Trained with these strategies, both a lightweight CNN and a pretrained ResNet achieve strong recognition performance and produce embeddings that more coherently separate character classes than PCA or generic pretrained models. These embeddings enable clustering, identification of stylistic subgroups, and construction of prototype images that visualize diachronic evolution and transitional letterforms. Our results demonstrate that respecting intrinsic inter-letter relationships and augmenting with domain-informed corruptions yield robust, interpretable representations, offering a transferable paradigm for representation learning under scarce, temporally evolving, and noisy conditions. Code and data available at: https://github.com/ipavlopoulos/diachronic-greek-letterforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces three datasets (Hell-Char for training spanning 3rd-1st c. BCE, PaLit-Char and Med-Char for evaluation in later centuries) for diachronic representation learning of ancient Greek letterforms. It proposes a similarity-weighted supervised contrastive loss that biases embeddings via dynamically estimated inter-class similarities, together with a lacuna-driven augmentation scheme simulating manuscript corruptions. The central claim is that lightweight CNN and pretrained ResNet models trained under these strategies achieve strong recognition performance, yield embeddings that separate character classes more coherently than PCA or generic pretrained models, and support downstream tasks including clustering, stylistic subgroup identification, and prototype-image visualization of diachronic evolution.
Significance. If the empirical results hold, the work supplies a concrete, transferable paradigm for representation learning under scarce, temporally evolving, and noisy conditions, with direct relevance to digital humanities and historical document analysis. The public release of code and data is a clear strength that supports reproducibility.
major comments (1)
- Abstract: the claims of 'strong recognition performance' and 'more coherently separate character classes than PCA or generic pretrained models' are load-bearing for the central contribution, yet the abstract supplies no quantitative metrics, baseline comparisons, ablation results, or error analysis; without these, the magnitude and robustness of the reported gains cannot be assessed.
minor comments (2)
- Methods: the dynamic estimation of inter-class similarities used inside the contrastive loss requires an explicit stability analysis or sensitivity check across random seeds and training epochs.
- Experiments: the lacuna-driven augmentation scheme should be accompanied by a quantitative comparison showing how closely the simulated corruptions match the degradation statistics observed in the held-out PaLit-Char and Med-Char sets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [—] Abstract: the claims of 'strong recognition performance' and 'more coherently separate character classes than PCA or generic pretrained models' are load-bearing for the central contribution, yet the abstract supplies no quantitative metrics, baseline comparisons, ablation results, or error analysis; without these, the magnitude and robustness of the reported gains cannot be assessed.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the central claims. The full manuscript reports recognition accuracies, embedding separation metrics (e.g., via silhouette scores or nearest-neighbor classification), and comparisons against PCA and generic pretrained models in Sections 4 and 5, along with ablations of the proposed loss and augmentation. In the revised version we will condense the key figures (e.g., top-1 accuracy on Hell-Char, PaLit-Char, and Med-Char, plus a brief statement on embedding coherence) into the abstract while preserving its length constraints. revision: yes
Circularity Check
No significant circularity
full rationale
This is empirical ML work introducing new datasets (Hell-Char, PaLit-Char, Med-Char) with held-out evaluation sets, a contrastive loss, and domain-specific augmentations. The central claims concern recognition performance and embedding quality on those sets; no derivation, prediction, or uniqueness theorem is asserted that reduces by construction to fitted parameters or self-citations. The abstract and described approach contain no load-bearing self-referential steps of the enumerated kinds. Standard empirical pipeline with external validation sets yields a self-contained result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Bausi, A., Borbone, P.G., Briquel- Chatonnet, F., Buzi, P., Gippert, J., Macé, C., Maniaci, M., Melissakis, Z., Parodi, L.E., Witakowski, W
Bianconi, D.: Greek Palaeography. In: Bausi, A., Borbone, P.G., Briquel- Chatonnet, F., Buzi, P., Gippert, J., Macé, C., Maniaci, M., Melissakis, Z., Parodi, L.E., Witakowski, W. (eds.) Comparative Oriental Manuscript Studies. An Introduction, pp. 297–305. Trendition, Hamburg (2015)
2015
-
[2]
Digital Signal Processing 149, 104477 (2024)
Boudraa, M., Bennour, A., Al-Sarem, M., Ghabban, F., Bakhsh, O.A.: Con- tribution to historical manuscript dating: A hybrid approach employing hand-crafted features with vision transformers. Digital Signal Processing 149, 104477 (2024). https://doi.org/10.1016/j.dsp.2024.104477
-
[3]
In: ICCV
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: ICCV. pp. 4778–4788 (2021)
2021
-
[4]
In: Bagnall, R.S
Cavallo, G.: Greek and Latin Writing in the Papyri. In: Bagnall, R.S. (ed.) TheOxfordHandbookofPapyrology,pp.101–148.OxfordUniversityPress, Oxford, New York (2009)
2009
-
[5]
A Simple Framework for Contrastive Learning of Visual Representations
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: Proceedings of ICML (2020). https://doi.org/10.48550/arXiv.2002.05709
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2002.05709 2020
-
[6]
Una introduzione
Crisci, E., Degni, P.: La scrittura greca dall’antichità all’epoca della stampa. Una introduzione. Carocci, Roma (2011)
2011
-
[7]
ACM Journal on Computing and Cultural Heritage18(3), 1–19 (2025)
D’Alessandro, T., Cilia, N., De Stefano, C., Fontanella, F., Molinara, M., Scotto di Freca, A., Marthot-Santaniello, I.: A deep transfer learning ap- proach for writer identification in greek papyri. ACM Journal on Computing and Cultural Heritage18(3), 1–19 (2025)
2025
-
[8]
EGRAPSA Hellenistic Dated Papyri Dataset (2025)
Ferretti, L., Serbaeva Saraogi, O., De Gregorio, G., Marthot-Santaniello, I.: Hell-Date. EGRAPSA Hellenistic Dated Papyri Dataset (2025). https: //doi.org/10.5281/zenodo.15083590, https://zenodo.org/records/15083590
-
[9]
In: CVPR
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recog- nition. In: CVPR. pp. 770–778 (2016)
2016
-
[10]
https://doi.org/10.5281/zenodo.1194357 (2016)
He, S., Schomaker, L.R., Samara, P., Burgers, J.: Mps data set with im- ages of medieval charters for handwriting-style based dating of manuscripts. https://doi.org/10.5281/zenodo.1194357 (2016)
-
[11]
Hinton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. Science313(5786), 504–507 (2006). https://doi.org/ 10.1126/science.1127647
-
[12]
In: Sirat, C., Irigoin, J., Poulle, E
Irigoin, J.: L’alphabet grec et son geste des origines au IXe siècle après J.-C. In: Sirat, C., Irigoin, J., Poulle, E. (eds.) L’écriture: le cerveau, l’œil et la main, pp. 299–305. Brepols, Turnhout (1990)
1990
-
[13]
In: NeurIPS
Khosla,P.,Teterwak,P.,Wang,C.,Sarna,A.,Tian,Y.,Isola,P.,Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. In: NeurIPS. pp. 18661–18673 (2020), proceedings.neurips.cc Diachronic Greek Letterforms 17
2020
-
[14]
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proceedings of IEEE86(11), 2278–2324 (1998). https://doi.org/10.1109/5.726791
-
[15]
In: The 3rd International Workshop on Historical Document Imaging and Process- ing
Li, Y., Genzel, D., Fujii, Y., Popat, A.C.: Publication date estimation for printed historical documents using convolutional neural networks. In: The 3rd International Workshop on Historical Document Imaging and Process- ing. pp. 99–106. ACM (2015)
2015
-
[16]
In: Coustaty, M., Fornés, A
Marthot-Santaniello, I., Vu, M.T., Serbaeva, O., Beurton-Aimar, M.: Stylis- tic similarities in greek papyri based on letter shapes: A deep learning ap- proach. In: Coustaty, M., Fornés, A. (eds.) ICDAR Workshops. pp. 307–323. Springer Nature Switzerland, Cham (2023)
2023
-
[17]
Otsu, N.: A threshold selection method from gray-level histograms. IEEE Transactions on Systems, Man, and Cybernetics9(1), 62–66 (1979). https: //doi.org/10.1109/TSMC.1979.4310076
-
[18]
Machine Learning113(9), 6765–6786 (2024)
Pavlopoulos, J., Konstantinidou, M., Perdiki, E., Marthot-Santaniello, I., Essler, H., Vardakas, G., Likas, A.: Explainable dating of greek papyri im- ages. Machine Learning113(9), 6765–6786 (2024)
2024
-
[19]
on lines and planes of closest fit to systems of points in space (Nov 1901)
Pearson, K.: On lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science2(11), 559–572 (1901). https://doi.org/10.1080/14786440109462720
-
[20]
Journal of computational and applied mathemat- ics20, 53–65 (1987)
Rousseeuw, P.J.: Silhouettes: a graphical aid to the interpretation and vali- dation of cluster analysis. Journal of computational and applied mathemat- ics20, 53–65 (1987)
1987
-
[21]
ACM SIGKDD Explorations Newsletter 25(1), 36–42 (2023)
Schubert, E.: Stop using the elbow criterion for k-means and how to choose the number of clusters instead. ACM SIGKDD Explorations Newsletter 25(1), 36–42 (2023)
2023
-
[22]
Pattern Recognition29(4), 641–662 (1996)
Trier, Ø.D., Jain, A.K., Taxt, T.: Feature extraction methods for character recognition – a survey. Pattern Recognition29(4), 641–662 (1996). https: //doi.org/10.1016/0031-3203(95)00118-2
-
[23]
Academy of Management Perspectives , volume =
Wahlberg, F., Wilkinson, T., Brun, A.: Historical manuscript production date estimation using deep convolutional neural networks. In: ICFHR. pp. 205–210 (2016). https://doi.org/10.1109/ICFHR.2016.0048
-
[24]
West, G., Swindall, M.I., Brusuelas, J.H., Maltomini, F., Gerhardt, M., D’Angelo, M., Wallin, J.F.: A deep learning pipeline for the palaeographi- cal dating of ancient Greek papyrus fragments. In: Pavlopoulos, John, e.a. (ed.) ML4AL ACL Workshop. pp. 177–185. ACL, Hybrid in Bangkok, Thai- land and online (Aug 2024). https://doi.org/10.18653/v1/2024.ml4al...
-
[25]
In: Proceedings of CVPR
Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon, I.S., Xie, S.: Con- vnext v2: Co-designing and scaling convnets with masked autoencoders. In: Proceedings of CVPR. pp. 16133–16142 (2023)
2023
- [26]
-
[27]
In: AAAI
Zhong, Z., Zheng, L., Kang, G., Li, S., Yang, Y.: Random erasing data augmentation. In: AAAI. vol. 34, pp. 13001–13008 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.