Do Thinking Tokens Help with Safety?
Pith reviewed 2026-06-25 23:36 UTC · model grok-4.3
The pith
Safety decisions in reasoning models are largely fixed before thinking tokens appear.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
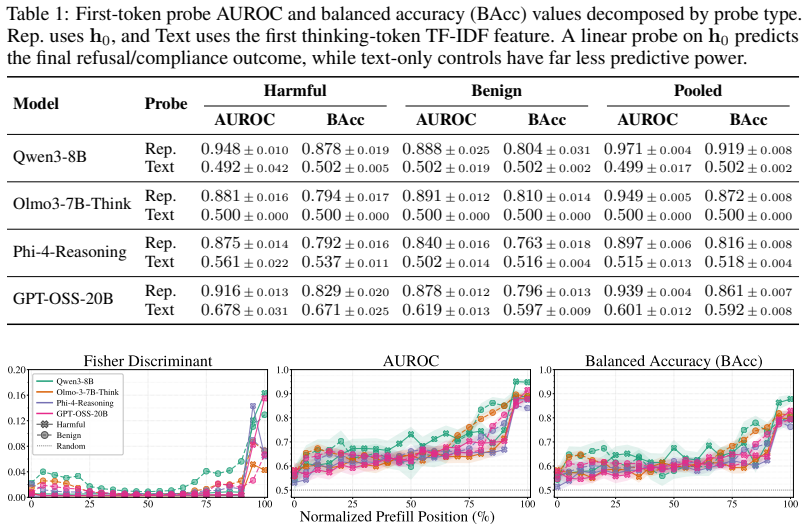
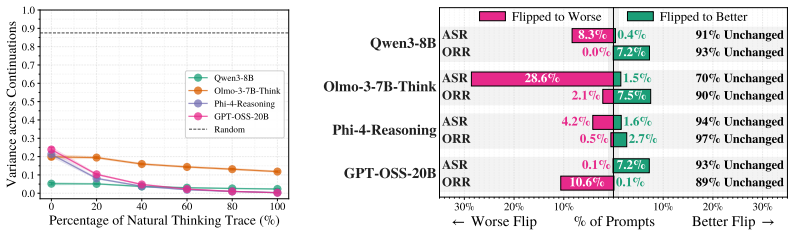
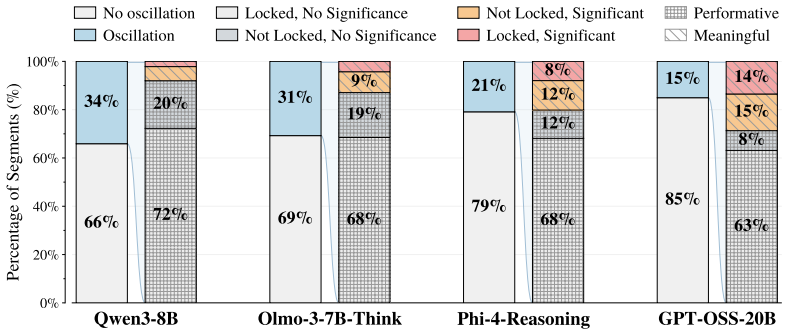
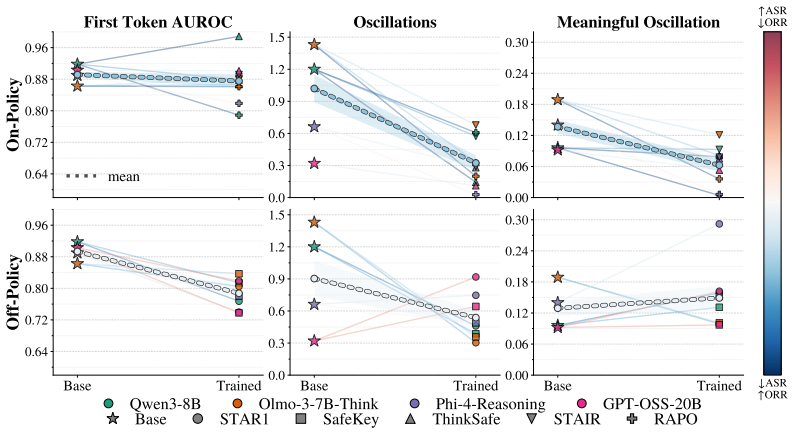
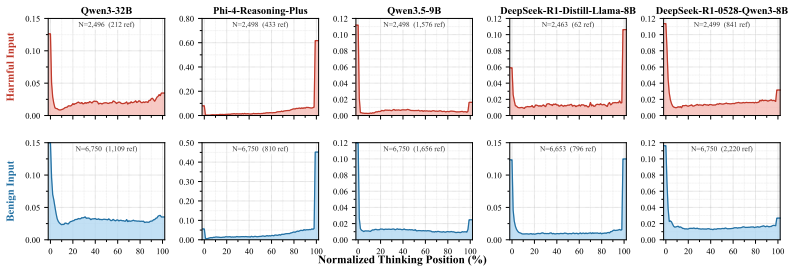
The eventual refusal or compliance outcome is already strongly predictable via a trained head on the first token's hidden representation (0.84-0.95 AUROC and roughly 88 percent balanced accuracy) before any visible thinking. The thinking process turns out to be more akin to prefix completion than to deliberative revision, with the final outcome rarely changing after the first 20 percent of thinking even though text-level deliberation appears in about 74 percent of cases where the response distribution is already locked to one side. Existing inference-time and training-based safety interventions largely shift model behavior toward over-refusal while suppressing already-scarce deliberation sig
What carries the argument
A linear probe on the first token's hidden representation that forecasts the final refusal or compliance outcome with high accuracy, together with the observed stability of that outcome after the initial 20 percent of thinking tokens.
Load-bearing premise
That strong predictability from the first token and stability after early thinking demonstrate absence of later deliberative revision rather than an early internal commitment that the rest of the tokens simply carry out.
What would settle it
A dataset or model run in which the refusal or compliance label changes in a substantial fraction of cases after the first 20 percent of the thinking tokens have been generated, or in which first-token probe accuracy falls well below the reported range.
Figures




read the original abstract
Today's reasoning models use thinking tokens to attain stronger performance on benchmarks than their instruction-tuned counterparts. It is also generally believed that this more "deliberative" mode should improve alignment and safety, by providing the model a safe space to consider whether its planned answer to a request violates its safety principles. We present evidence that this intuition is not always correct. Across frontier open-weight reasoning models spanning GPT-OSS, Qwen, Olmo, and Phi families, we find that the eventual refusal/compliance outcome is already strongly predictable via a trained head on the first token's hidden representation ($0.84$-$0.95$ AUROC and $\sim88\%$ balanced accuracy for predicting refusal/compliance) before any visible thinking. The thinking process turns out to be more akin to prefix completion than to deliberative revision, with the final outcome rarely changing after the first $\sim20\%$ of thinking, despite giving the appearance of deliberation at the text level ($\sim74\%$ of text-level deliberations occur when the response distribution is already locked to one refusal/compliance side). We also find that existing inference-time and training-based safety interventions, despite being motivated by the goal of inducing deliberation, largely shift model behavior toward over-refusal while suppressing already-scarce deliberation signals. Our results suggest that safety behavior in current reasoning models is much less deliberative than commonly assumed, and highlight the need for methods that induce real safety deliberation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that thinking tokens in frontier reasoning models (GPT-OSS, Qwen, Olmo, Phi families) do not enable deliberative safety decisions. Refusal/compliance is already strongly predictable from a trained classifier on the first token's hidden state (0.84-0.95 AUROC, ~88% balanced accuracy), outcomes stabilize after the first ~20% of thinking tokens, ~74% of apparent text-level deliberations occur after the response distribution is locked, and existing safety interventions mainly increase over-refusal while suppressing deliberation signals. The authors conclude that safety behavior is less deliberative than assumed and call for methods inducing genuine deliberation.
Significance. If the empirical patterns hold, the work has clear significance for AI safety: it supplies concrete, cross-model evidence against the assumption that reasoning-model thinking improves alignment via deliberation. The hidden-state predictability result and the timing/stability metrics constitute falsifiable, quantitative observations that can be directly tested or extended. The paper earns credit for the reproducible classifier-based measurement and the intervention-effect analysis, both of which move beyond qualitative claims.
minor comments (2)
- [Methods] Methods section: provide the exact training protocol, dataset splits, and prompt-construction details for the first-token classifier head so that the reported AUROC range can be independently verified.
- [Results] Results: report the precise number of models, prompts, and tokens per trajectory underlying the ~20% stabilization and ~74% locked-deliberation statistics to allow assessment of statistical robustness.
Simulated Author's Rebuttal
We thank the referee for their thorough and positive evaluation of our work, including recognition of its significance for AI safety and the reproducibility of our classifier-based measurements. We are pleased with the recommendation for minor revision and will incorporate any editorial suggestions in the revised manuscript.
Circularity Check
No significant circularity
full rationale
The paper's claims rest on direct empirical measurements: classifiers trained on first-token hidden representations achieve 0.84-0.95 AUROC for refusal/compliance prediction on held-out data, and token-trajectory observations show outcome stability after the first ~20% of thinking. These quantities are obtained from external evaluation protocols and do not reduce, via any equation in the paper, to quantities defined solely by the paper's own fitted parameters or prior self-citations. No load-bearing step invokes a uniqueness theorem, ansatz, or renaming that collapses to the input by construction. The central result therefore remains independent of the measurement apparatus itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- trained classifier head on first-token hidden state
Reference graph
Works this paper leans on
-
[1]
Refusal in Language Models Is Mediated by a Single Direction , url =
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , booktitle =. Refusal in Language Models Is Mediated by a Single Direction , url =. doi:10.52202/079017-4322 , editor =
-
[2]
The Thirteenth International Conference on Learning Representations , year=
Safety Alignment Should be Made More Than Just a Few Tokens Deep , author=. The Thirteenth International Conference on Learning Representations , year=
-
[3]
2025 , eprint =
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety , author =. 2025 , eprint =
2025
-
[4]
2024 , eprint =
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. 2024 , eprint =
2024
-
[5]
2024 , eprint =
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author =. 2024 , eprint =
2024
-
[6]
2025 , eprint =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. 2025 , eprint =
2025
-
[7]
arXiv preprint arXiv:2412.16339 , year=
Deliberative Alignment: Reasoning Enables Safer Language Models , author=. arXiv preprint arXiv:2412.16339 , year=
-
[8]
Does Math Reasoning Improve General
Huan, Maggie and Li, Yuetai and Zheng, Tuney and Xu, Xiaoyu and Kim, Seungone and Du, Minxin and Poovendran, Radha and Neubig, Graham and Yue, Xiang , journal=. Does Math Reasoning Improve General
-
[9]
2024 , url =
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , booktitle =. 2024 , url =
2024
-
[10]
2025 , eprint=
FORTRESS: Frontier Risk Evaluation for National Security and Public Safety , author=. 2025 , eprint=
2025
-
[11]
2025 , url =
Cui, Justin and Chiang, Wei-Lin and Stoica, Ion and Hsieh, Cho-Jui , booktitle =. 2025 , url =
2025
-
[12]
, journal=
Zhang, Zhehao and Xu, Weijie and Wu, Fanyou and Reddy, Chandan K. , journal=
-
[13]
Advances in Neural Information Processing Systems , year =
The Art of Saying No: Contextual Noncompliance in Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[14]
NeurIPS 2025 Workshop: Reliable ML from Unreliable Data , year=
Reasoning as an Adaptive Defense for Safety , author=. NeurIPS 2025 Workshop: Reliable ML from Unreliable Data , year=
2025
-
[15]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[16]
Advances in Neural Information Processing Systems , volume =
Large Language Models are Zero-Shot Reasoners , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[17]
International Conference on Learning Representations , year =
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , author =. International Conference on Learning Representations , year =
-
[18]
Advances in Neural Information Processing Systems , year =
Beyond Verifiable Rewards: Scaling Reinforcement Learning in Language Models to Unverifiable Data , author =. Advances in Neural Information Processing Systems , year =
-
[19]
2025 , eprint=
CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint =
Beyond the Trade-off: Self-Supervised Reinforcement Learning for Reasoning Models' Instruction Following , author =. 2025 , eprint =
2025
-
[21]
2022 , eprint =
Constitutional AI: Harmlessness from AI Feedback , author =. 2022 , eprint =
2022
-
[22]
2025 , eprint=
Safety in Large Reasoning Models: A Survey , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
The Hidden Risks of Large Reasoning Models: A Safety Assessment of R1 , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Evaluating the Robustness of Large Language Model Safety Guardrails Against Adversarial Attacks , author=. 2025 , eprint=
2025
-
[25]
2026 , eprint=
Reasoning Theater: Disentangling Model Beliefs from Chain-of-Thought , author=. 2026 , eprint=
2026
-
[26]
First Conference on Language Modeling , year=
Automatic Pseudo-Harmful Prompt Generation for Evaluating False Refusals in Large Language Models , author=. First Conference on Language Modeling , year=
-
[27]
Other Side
ORFuzz: Fuzzing the "Other Side" of LLM Safety -- Testing Over-Refusal , author=. 2025 , eprint=
2025
-
[28]
Advances in Neural Information Processing Systems , volume =
WildGuard: Open One-stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs , author =. Advances in Neural Information Processing Systems , volume =. 2024 , doi =
2024
-
[29]
2025 , eprint =
Qwen3Guard Technical Report , author =. 2025 , eprint =
2025
-
[30]
2024 , eprint =
Granite Guardian , author =. 2024 , eprint =
2024
-
[31]
2025 , month = oct, url =
Technical Report: Performance and Baseline Evaluations of gpt-oss-safeguard-120b and gpt-oss-safeguard-20b , author =. 2025 , month = oct, url =
2025
-
[32]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b Model Card , author =. 2025 , eprint =. doi:10.48550/arXiv.2508.10925 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[33]
2026 , eprint=
Decoding Answers Before Chain-of-Thought: Evidence from Pre-CoT Probes and Activation Steering , author=. 2026 , eprint=
2026
-
[34]
arXiv preprint arXiv:2503.11926 , year =
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation , author =. arXiv preprint arXiv:2503.11926 , year =
-
[35]
arXiv preprint arXiv:2507.05246 , year =
When Chain of Thought is Necessary, Language Models Struggle to Evade Monitors , author =. arXiv preprint arXiv:2507.05246 , year =
-
[36]
NeurIPS , year =
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author =. NeurIPS , year =
-
[37]
arXiv preprint arXiv:2307.13702 , year =
Measuring Faithfulness in Chain-of-Thought Reasoning , author =. arXiv preprint arXiv:2307.13702 , year =
-
[38]
arXiv preprint arXiv:2503.08679 , year =
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful , author =. arXiv preprint arXiv:2503.08679 , year =
-
[39]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[40]
2025 , eprint =
Olmo 3 , author =. 2025 , eprint =
2025
-
[41]
2025 , eprint =
Phi-4-reasoning Technical Report , author =. 2025 , eprint =
2025
-
[42]
Jeung, Wonje and Yoon, Sangyeon and Kahng, Minsuk and No, Albert , year =. 2505.14667 , archivePrefix =
-
[43]
2025 , eprint =
Think Twice, Generate Once: Safeguarding by Progressive Self-Reflection , author =. 2025 , eprint =
2025
-
[44]
How Does the Thinking Step Influence Model Safety? An Entropy-based Safety Reminder for
Kim, Su-Hyeon and Jin, Hyundong and Lee, Yejin and Han, Yo-Sub , year =. How Does the Thinking Step Influence Model Safety? An Entropy-based Safety Reminder for. 2601.03662 , archivePrefix =
-
[45]
Wang, Yuquan and Zhang, Mi and Wang, Yining and Hong, Geng and You, Xiaoyu and Yang, Min , year =. 2508.04204 , archivePrefix =
-
[46]
and Kailkhura, Bhavya and Xie, Cihang , year =
Wang, Zijun and Tu, Haoqin and Wang, Yuhan and Wu, Juncheng and Liu, Yanqing and Mei, Jieru and Bartoldson, Brian R. and Kailkhura, Bhavya and Xie, Cihang , year =. 2504.01903 , archivePrefix =
-
[47]
In, Yeonjun and Kim, Wonjoong and Park, Sangwu and Park, Chanyoung , year =. 2508.00324 , archivePrefix =
-
[48]
Zhou, Kaiwen and Zhao, Xuandong and Liu, Gaowen and Srinivasa, Jayanth and Feng, Aosong and Song, Dawn and Wang, Xin Eric , year =. 2505.16186 , archivePrefix =
-
[49]
Lee, Seanie and Park, Sangwoo and Choi, Yumin and Kim, Gyeongman and Kang, Minki and Yun, Jihun and Park, Dongmin and Park, Jongho and Hwang, Sung Ju , year =. 2601.23143 , archivePrefix =
-
[50]
2025 , url=
Yichi Zhang and Siyuan Zhang and Yao Huang and Zeyu Xia and Zhengwei Fang and Xiao Yang and Ranjie Duan and Dong Yan and Yinpeng Dong and Jun Zhu , booktitle=. 2025 , url=
2025
-
[51]
Wei, Zeming and Zhang, Qiaosheng and Hu, Xia and Xu, Xingcheng , year =. 2602.04224 , archivePrefix =
-
[52]
Nature , volume =
Larger and More Instructable Language Models Become Less Reliable , author =. Nature , volume =. 2024 , doi =
2024
-
[53]
Scaling Laws of Refusal Robustness: Why Bigger
Wang, Yueyi , year =. Scaling Laws of Refusal Robustness: Why Bigger
-
[54]
2026 , eprint=
ShallowJail: Steering Jailbreaks against Large Language Models , author=. 2026 , eprint=
2026
-
[55]
2025 , eprint=
Weak-to-Strong Jailbreaking on Large Language Models , author=. 2025 , eprint=
2025
-
[56]
2025 , eprint=
Refusal Falls off a Cliff: How Safety Alignment Fails in Reasoning? , author=. 2025 , eprint=
2025
-
[57]
2024 , eprint=
PKU-SafeRLHF: Towards Multi-Level Safety Alignment for LLMs with Human Preference , author=. 2024 , eprint=
2024
-
[58]
2023 , eprint=
UltraFeedback: Boosting Language Models with Scaled AI Feedback , author=. 2023 , eprint=
2023
-
[59]
2025 , eprint=
SafeChain: Safety of Language Models with Long Chain-of-Thought Reasoning Capabilities , author=. 2025 , eprint=
2025
-
[60]
2025 , eprint=
Strata-Sword: A Hierarchical Safety Evaluation towards LLMs based on Reasoning Complexity of Jailbreak Instructions , author=. 2025 , eprint=
2025
-
[61]
2023 , eprint=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
2023
-
[62]
Advances in neural information processing systems , volume=
Jailbroken: How does llm safety training fail? , author=. Advances in neural information processing systems , volume=
-
[63]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[64]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
2025
-
[65]
arXiv preprint arXiv:2310.04451 , year=
Autodan: Generating stealthy jailbreak prompts on aligned large language models , author=. arXiv preprint arXiv:2310.04451 , year=
-
[66]
arXiv preprint arXiv:2309.10253 , year=
Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts , author=. arXiv preprint arXiv:2309.10253 , year=
-
[67]
Advances in Neural Information Processing Systems , volume=
Tree of attacks: Jailbreaking black-box llms automatically , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
arXiv preprint arXiv:2211.09527 , year=
Ignore previous prompt: Attack techniques for language models , author=. arXiv preprint arXiv:2211.09527 , year=
-
[69]
Advances in Neural Information Processing Systems , volume=
Many-shot jailbreaking , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
arXiv preprint arXiv:2407.04295 , year=
Jailbreak attacks and defenses against large language models: A survey , author=. arXiv preprint arXiv:2407.04295 , year=
-
[71]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
A comprehensive study of jailbreak attack versus defense for large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[72]
Great, Now Write an Article About That: The Crescendo
Russinovich, Mark and Salem, Ahmed and Eldan, Ronen , booktitle=. Great, Now Write an Article About That: The Crescendo
-
[73]
arXiv preprint arXiv:2408.15221 , year=
Llm defenses are not robust to multi-turn human jailbreaks yet , author=. arXiv preprint arXiv:2408.15221 , year=
-
[74]
arXiv preprint arXiv:2412.03556 , year=
Best-of-n jailbreaking , author=. arXiv preprint arXiv:2412.03556 , year=
-
[75]
arXiv preprint arXiv:2410.02832 , year=
Flipattack: Jailbreak llms via flipping , author=. arXiv preprint arXiv:2410.02832 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.