The Clinician's Veto: Navigating Trust, Liability, and Uncertainty in Autonomous AI Prescribing
Pith reviewed 2026-06-25 22:52 UTC · model grok-4.3
The pith
Clinicians would block autonomous AI prescribing absent calibrated confidence escalation, uncertainty-type signals, and inferential transparency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prescribing clinicians would not permit autonomous prescribing without a calibrated confidence-based escalation mechanism, preferred a competing-options summary when uncertainty was aleatoric but shifted to abstention when uncertainty was epistemic, and were only willing to accept additional liability when inferential transparency enabled a substantive judgment under acknowledged uncertainty. These findings indicate the recommended architectural features would encourage higher rates of clinician adoption by collapsing much of what autonomy conventionally means, turning the system into a heavily supervised decision-support tool.
What carries the argument
Three architectural requirements for safe autonomous prescribing: calibrated confidence-based escalation, differentiated uncertainty communication (epistemic versus aleatoric), and inferential transparency for liability allocation.
If this is right
- Clinicians would adopt AI prescribing systems at higher rates when the three features are present.
- The AI would function less as an autonomous agent and more as a heavily supervised decision-support tool.
- Liability would align with the institutional actors who control system design and deployment.
- Regulation could constrain the degree of autonomy granted to AI in prescribing while matching liability to control.
Where Pith is reading between the lines
- These requirements could be directly tested in ongoing state pilots such as Utah's prescription-renewal program.
- Similar architectural constraints on uncertainty handling might apply to other high-stakes AI medical decisions beyond prescribing.
- Approval based solely on aggregate performance metrics could result in low real-world adoption if these features are absent.
Load-bearing premise
The preferences expressed by the 136 surveyed U.S. prescribing clinicians accurately predict real-world adoption behavior, liability tolerance, and safety impact in deployed systems.
What would settle it
A real-world pilot deployment of autonomous AI prescribing that achieves high clinician acceptance and use rates without implementing calibrated confidence escalation, uncertainty-type differentiation, or inferential transparency.
Figures












read the original abstract
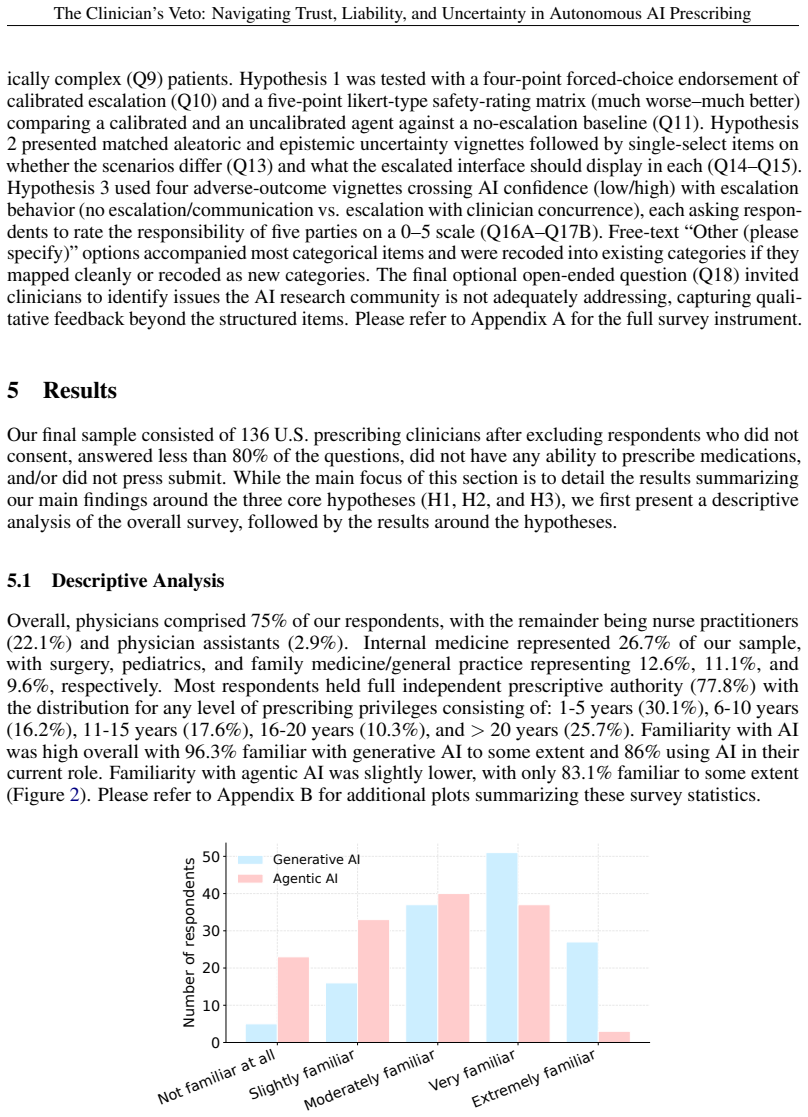
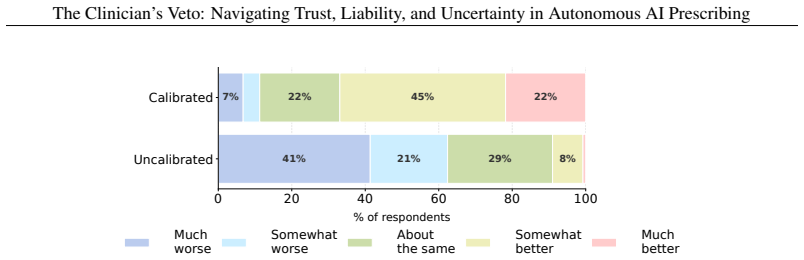
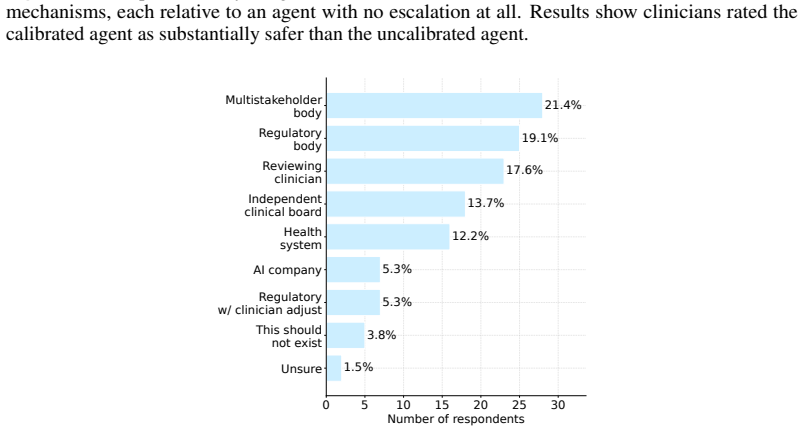
Autonomous AI systems are transitioning from advisory to autonomous roles for medication prescriptions. Recent United States bill H.R. 238 and Utah's prescription-renewal pilot both authorize AI to prescribe medications in an agentic capacity. While some regulatory guidelines suggest aggregate model performance metrics for clearance, they do not require i) calibrated per-prediction confidence for action-gated thresholds, ii) differentiated communication of uncertainty arising from model ignorance (epistemic) versus genuine clinical ambiguity (aleatoric), and iii) inferential transparency at the moment of decision that allows for liability allocation. Here, we present a regulatory and technical argument (tested with a survey of 136 U.S. prescribing clinicians) positioning these as minimum architectural requirements for safe autonomous prescribing. Our results suggest prescribing clinicians i) would not permit autonomous prescribing without a calibrated confidence-based escalation mechanism, ii) preferred a competing-options summary when uncertainty was aleatoric but shifted to abstention when uncertainty was epistemic, and iii) were only willing to accept additional liability when inferential transparency enabled a substantive judgment under acknowledged uncertainty. These findings indicate our recommended architectural features would encourage higher rates of clinician adoption, largely through collapsing much of what "autonomy" conventionally means. A system meeting these requirements would function less as an autonomous agent and more as a heavily supervised decision-support tool. As legislation and state pilots proceed, our technical argument backed by clinician perspectives provides opportunities for regulation to constrain the degree of autonomy ethically granted to AI in prescribing while aligning liability with the institutional actors who control system design and deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that safe autonomous AI prescribing requires three minimum architectural features—calibrated per-prediction confidence with action-gated thresholds, differentiated handling of aleatoric versus epistemic uncertainty, and inferential transparency for liability allocation—supported by survey responses from 136 U.S. prescribing clinicians. The survey indicates clinicians would reject autonomy without confidence-based escalation, prefer competing-options summaries for aleatoric uncertainty but abstention for epistemic, and accept added liability only with transparency enabling substantive judgment. These features are positioned as regulatory necessities given legislation like H.R. 238 and Utah pilots, with the argument that they would increase adoption by reducing true autonomy.
Significance. If the survey evidence is robust, the work offers clinician-grounded input on AI autonomy limits in a high-stakes domain, directly relevant to ongoing U.S. regulatory developments. It explicitly links technical design choices to liability and trust outcomes, providing a concrete framework that could inform policy. The survey-based testing of the three requirements is a strength, as is the explicit acknowledgment that the resulting systems would function more as supervised tools than fully autonomous agents.
major comments (2)
- [Survey methods and results section] The central claims rest on the survey of 136 clinicians, yet the manuscript provides no details on survey design, sampling method, statistical analysis, response rates, vignette construction, or power calculations (see abstract and the section reporting survey results). Without this information, the strength of evidence for the three requirements cannot be evaluated, undermining the regulatory argument.
- [Discussion] The extrapolation from vignette-based preferences to real-world adoption, override rates, and liability tolerance under actual patient outcomes is asserted but not tested or externally validated against observed AI tool deployment data or liability records (see discussion of the three findings).
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for improving the transparency and scope of our claims. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Survey methods and results section] The central claims rest on the survey of 136 clinicians, yet the manuscript provides no details on survey design, sampling method, statistical analysis, response rates, vignette construction, or power calculations (see abstract and the section reporting survey results). Without this information, the strength of evidence for the three requirements cannot be evaluated, undermining the regulatory argument.
Authors: We agree that the submitted manuscript does not provide sufficient methodological detail on the survey. In the revised version, we will insert a dedicated methods section describing survey design (including how vignettes were constructed from standard prescribing scenarios), sampling method (recruitment through U.S. clinician professional networks and associations), achieved response rate, statistical analyses (preference comparisons and descriptive statistics), and any power considerations. This will allow readers to assess the robustness of the evidence for the three architectural requirements. revision: yes
-
Referee: [Discussion] The extrapolation from vignette-based preferences to real-world adoption, override rates, and liability tolerance under actual patient outcomes is asserted but not tested or externally validated against observed AI tool deployment data or liability records (see discussion of the three findings).
Authors: We acknowledge that the discussion extrapolates from vignette-based survey preferences to potential real-world effects on adoption and liability. The survey directly measures clinician preferences under controlled hypothetical conditions, but the manuscript does not include or claim external validation against existing deployment or liability datasets, as autonomous AI prescribing systems remain limited in deployment. We will revise the discussion to frame these as hypothesized implications supported by the survey data, explicitly note the absence of real-world validation, and call for future empirical studies. This maintains the regulatory argument while accurately bounding the evidence. revision: partial
Circularity Check
No significant circularity; argument rests on external survey data
full rationale
The paper advances a regulatory argument for three architectural features in autonomous AI prescribing systems, supported by results from a survey of 136 U.S. prescribing clinicians and references to external legislation (H.R. 238 and Utah pilot). No equations, fitted parameters, predictions derived from internal models, or self-citation chains appear in the derivation. Claims are presented as empirical findings from the survey rather than reductions to self-defined inputs or prior author work. The central premise is externally grounded and does not reduce to its own assumptions by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Survey responses from 136 U.S. prescribing clinicians reflect the preferences that would govern real-world adoption and liability decisions for autonomous AI prescribing.
invented entities (1)
-
Clinician's Veto
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Schweikert
David [R-AZ-1 Rep. Schweikert. Text - H.R.238 - 119th Congress (2025-2026): Healthy Technology Act of 2025, January 2025. URL https://www.congress.gov/bill/ 119th-congress/house-bill/238/text. Archive Location: 2025-01-07. 1
2025
-
[2]
Michelle M. Mello. Utah’s Experiment With AI-Driven Prescription Renewals.JAMA Health Forum, 7(3):e261001, March 2026. ISSN 2689-0186. doi: 10.1001/jamahealthforum.2026.1001. URLhttps://doi.org/10.1001/jamahealthforum.2026.1001. 2, 3
-
[3]
Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?, February 2025
Yoshua Bengio, Michael Cohen, Damiano Fornasiere, Joumana Ghosn, Pietro Greiner, Matt MacDermott, Sören Mindermann, Adam Oberman, Jesse Richardson, Oliver Richardson, Marc-Antoine Rondeau, Pierre-Luc St-Charles, and David Williams-King. Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?, February 2025. URL http://arxiv.o...
arXiv 2025
-
[4]
Artificial Intelligence-Enabled Device Software Functions: Lifecycle Management and Marketing Submission Recommendations, January 2025
FDA. Artificial Intelligence-Enabled Device Software Functions: Lifecycle Management and Marketing Submission Recommendations, January 2025. 3
2025
-
[5]
FDA Relaxes Clinical Decision Support and General Wellness Guidance: What It Means for Generative AI and Consumer Wearables, January 2026
Michael Schellhous and Sam Pinson. FDA Relaxes Clinical Decision Support and General Wellness Guidance: What It Means for Generative AI and Consumer Wearables, January 2026. 3
2026
-
[6]
Clare W. Teng, Saawan D. Patel, Andrew J. Barkmeier, T. Y . Alvin Liu, David Myung, Jeffrey Henderer, James Liu, Eric Hansen, and Lama A. Al-Aswad. Autonomous Artifi- cial Intelligence in Diabetic Retinopathy Testing—Lessons Learned on Successful Health System Adoption.Ophthalmology Science, 6(1):100935, January 2026. ISSN 2666-9145. doi: 10.1016/j.xops.2...
-
[7]
Stephen Gilbert, Tinglong Dai, and Rebecca Mathias. Consternation as Congress proposal for autonomous prescribing AI coincides with the haphazard cuts at the FDA.NPJ Digital Medicine, 8:165, March 2025. ISSN 2398-6352. doi: 10.1038/s41746-025-01540-2. URL https://pmc.ncbi.nlm.nih.gov/articles/PMC11920405/. 3
-
[8]
Physician Survey on Augmented Intelligence, March
American Medical Association. Physician Survey on Augmented Intelligence, March
-
[9]
URL https://www.ama-assn.org/practice-management/digital-health/ physician-survey-augmented-intelligence. 3, 4
-
[10]
Felix Busch et al. Multinational Attitudes Toward AI in Health Care and Diagnostics Among Hospital Patients.JAMA Network Open, 8(6):e2514452, June 2025. ISSN 2574-3805. doi: 10. 1001/jamanetworkopen.2025.14452. URL https://doi.org/10.1001/jamanetworkopen. 2025.14452. 3, 4
-
[11]
Gianfranco Damiani, Gerardo Altamura, Massimo Zedda, Mario Cesare Nurchis, Giovanni Aulino, Aurora Heidar Alizadeh, Francesca Cazzato, Gabriele Della Morte, Matteo Caputo, Simone Grassi, and Antonio Oliva. Potentiality of algorithms and artificial intelligence adoption to improve medication management in primary care: a systematic review.BMJ Open, 13 (3):...
-
[12]
Florian Kücking, Ursula Hübner, Mareike Przysucha, Niels Hannemann, Jan-Oliver Kutza, Maurice Moelleken, Cornelia Erfurt-Berge, Joachim Dissemond, Birgit Babitsch, and Dorothee Busch. Automation Bias in AI-Decision Support: Results from an Empirical Study.Studies in Health Technology and Informatics, 317:298–304, August 2024. ISSN 1879-8365. doi: 10.3233/...
-
[13]
Sungwon Yoon et al. Assessing the Utility, Impact, and Adoption Challenges of an Artificial Intelligence-Enabled Prescription Advisory Tool for Type 2 Diabetes Management: Qualitative Study.JMIR human factors, 11:e50939, June 2024. ISSN 2292-9495. doi: 10.2196/50939. 3
-
[14]
Junren Chen, Yigeng Cao, Yahui Feng, Saibing Qi, Donglin Yang, Yu Hu, Aiming Pang, Qiujin Shen, Jieya Luo, Xiaowen Gong, Rongli Zhang, Xiaolin Zhai, Xueqian Li, Wen Yan, Xianjing Zhang, Mengyun Chen, Mingming Niu, Jialin Wei, Chen Liang, Weihua Zhai, Ningning Zhao, Xueou Liu, Sichang Liu, Wangsong Zhai, Ruixin Li, Xianfeng Shao, Dong Zhang, Mingyang Wang,...
-
[15]
doi: 10.1038/s41467-025-62926-0
ISSN 2041-1723. doi: 10.1038/s41467-025-62926-0. URL https://www.nature. com/articles/s41467-025-62926-0. 3
-
[16]
Abbott, Tehreem Rehman, Anthony Rosania, Donald L
Ethan E. Abbott, Tehreem Rehman, Anthony Rosania, Donald L. Lum, Todd B. Taylor, AJ. Kirk, R. Andrew Taylor, Eileen F. Baker, Elaine Rabin, Aasim Padela, Nicholas Genes, Atul Srivastava, Rohit B. Sangal, and Donald Apakama. Understanding and Addressing Bias in Artificial Intelligence Systems: A Primer for the Emergency Medicine Physician.Journal of the Am...
-
[17]
Thomas Dratsch, Xue Chen, Mohammad Rezazade Mehrizi, Roman Kloeckner, Aline Mähringer-Kunz, Michael Püsken, Bettina Baeßler, Stephanie Sauer, David Maintz, and Daniel 14 The Clinician’s Veto: Navigating Trust, Liability, and Uncertainty in Autonomous AI Prescribing Pinto dos Santos. Automation Bias in Mammography: The Impact of Artificial Intelligence BI-...
-
[18]
Kate Goddard, Abdul Roudsari, and Jeremy C Wyatt. Automation bias: a systematic review of frequency, effect mediators, and mitigators.Journal of the American Medical Informatics Asso- ciation, 19(1):121–127, January 2012. ISSN 1067-5027. doi: 10.1136/amiajnl-2011-000089. URLhttps://doi.org/10.1136/amiajnl-2011-000089
-
[19]
Christopher D. Wickens, Benjamin A. Clegg, Alex Z. Vieane, and Angelia L. Sebok. Com- placency and Automation Bias in the Use of Imperfect Automation.Human Factors, 57 (5):728–739, August 2015. ISSN 0018-7208. doi: 10.1177/0018720815581940. URL https://doi.org/10.1177/0018720815581940
-
[20]
Simon, and Joseph S
Rohan Khera, Melissa A. Simon, and Joseph S. Ross. Automation Bias and Assistive AI: Risk of Harm From AI-Driven Clinical Decision Support.JAMA, 330(23):2255–2257, December
-
[21]
ISSN 0098-7484. doi: 10.1001/jama.2023.22557. URL https://doi.org/10.1001/ jama.2023.22557
-
[22]
Ihsan Ayyub Qazi, Ayesha Ali, Asad Ullah Khawaja, Muhammad Junaid Akhtar, Ali Zafar Sheikh, and Muhammad Hamad Alizai. Automation Bias in Large Language Model–Assisted Diagnostic Reasoning among Physicians Trained in AI Literacy — A Randomized Clinical Trial.NEJM AI, 3(5):AIoa2501001, April 2026. doi: 10.1056/AIoa2501001. URL https: //ai.nejm.org/doi/abs/...
-
[23]
Brent Daniel Mittelstadt, Patrick Allo, Mariarosaria Taddeo, Sandra Wachter, and Lu- ciano Floridi. The ethics of algorithms: Mapping the debate.Big Data & So- ciety, 3(2):2053951716679679, December 2016. ISSN 2053-9517, 2053-9517. doi: 10.1177/2053951716679679. URL https://journals.sagepub.com/doi/10.1177/ 2053951716679679. 3, 4
-
[24]
Danton S. Char, Nigam H. Shah, and David Magnus. Implementing Machine Learning in Health Care — Addressing Ethical Challenges.New England Journal of Medicine, 378(11): 981–983, March 2018. ISSN 0028-4793, 1533-4406. doi: 10.1056/NEJMp1714229. URL http://www.nejm.org/doi/10.1056/NEJMp1714229
-
[25]
Machado, Christopher Burr, Josh Cowls, Indra Joshi, Mariarosaria Taddeo, and Luciano Floridi
Jessica Morley, Caio C.V . Machado, Christopher Burr, Josh Cowls, Indra Joshi, Mariarosaria Taddeo, and Luciano Floridi. The ethics of AI in health care: A mapping review.Social Science & Medicine, September 2020. doi: 10.1016/j.socscimed.2020.113172. URL https: //linkinghub.elsevier.com/retrieve/pii/S0277953620303919. 3
-
[26]
Thomas Grote and Philipp Berens. On the ethics of algorithmic decision-making in healthcare.Journal of Medical Ethics, 46(3):205–211, March 2020. ISSN 0306-6800. doi: 10.1136/medethics-2019-105586. URL https://pmc.ncbi.nlm.nih.gov/articles/ PMC7042960/. 4
-
[27]
Benjamin Lambert, Florence Forbes, Senan Doyle, Harmonie Dehaene, and Michel Dojat. Trustworthy clinical AI solutions: A unified review of uncertainty quantification in Deep Learning models for medical image analysis.Artificial Intelligence in Medicine, 150:102830, April 2024. ISSN 09333657. doi: 10.1016/j.artmed.2024.102830. URL https://linkinghub. elsev...
-
[28]
Quantifying uncertainty in natural language explanations of large language models
Sree Harsha Tanneru, Chirag Agarwal, and Himabindu Lakkaraju. Quantifying uncertainty in natural language explanations of large language models. InInternational Conference on Artificial Intelligence and Statistics, pages 1072–1080. PMLR, 2024. 4
2024
-
[29]
Umang Bhatt, Javier Antorán, Yunfeng Zhang, Q. Vera Liao, Prasanna Sattigeri, Riccardo Fogliato, Gabrielle Melançon, Ranganath Krishnan, Jason Stanley, Omesh Tickoo, Lama Nachman, Rumi Chunara, Madhulika Srikumar, Adrian Weller, and Alice Xiang. Uncertainty as a Form of Transparency: Measuring, Communicating, and Using Uncertainty. InProceedings of the 20...
2021
-
[30]
URL https://dl.acm.org/doi/10.1145/3461702
doi: 10.1145/3461702.3462571. URL https://dl.acm.org/doi/10.1145/3461702. 3462571. 4, 5 15 The Clinician’s Veto: Navigating Trust, Liability, and Uncertainty in Autonomous AI Prescribing
-
[31]
Horvitz.Principles of Mixed-Initiative User Interfaces
Eric Horvitz. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI conference on Human Factors in Computing Systems, CHI ’99, pages 159–166, New York, NY , USA, May 1999. Association for Computing Machinery. ISBN 978-0-201-48559-2. doi: 10.1145/302979.303030. URLhttps://dl.acm.org/doi/10.1145/302979.303030. 4
-
[32]
Benjamin Kompa, Jasper Snoek, and Andrew L. Beam. Second opinion needed: communicating uncertainty in medical machine learning.npj Digital Medicine, 4(1):4, January 2021. ISSN 2398-
2021
-
[33]
Second opinion needed: communicatinguncertaintyinmedicalmachinelearning
doi: 10.1038/s41746-020-00367-3. URL https://www.nature.com/articles/ s41746-020-00367-3. 4
-
[34]
Aruna Kumari, Shakeel Ahmed, and Abdulaziz Al- humam
Parvathaneni Naga Srinivasu, Gorli L. Aruna Kumari, Shakeel Ahmed, and Abdulaziz Al- humam. Exploring Agentic AI in Healthcare: A Study on Its Working Mechanism.Fron- tiers in Medicine, 12, January 2026. ISSN 2296-858X. doi: 10.3389/fmed.2025.1753443. URL https://www.frontiersin.org/journals/medicine/articles/10.3389/fmed. 2025.1753443/full. 4
-
[35]
Position Paper: Integrating Explainability and Uncertainty Estimation in Medical AI, September 2025
Xiuyi Fan. Position Paper: Integrating Explainability and Uncertainty Estimation in Medical AI, September 2025. URL http://arxiv.org/abs/2509.18132. arXiv:2509.18132 [cs] version: 1. 5
arXiv 2025
-
[36]
Xinyi Liu, Weiguang Wang, and Hangfeng He. The Role of Model Confidence on Bias Effects in Measured Uncertainties for Vision-Language Models, 2025. URL https://arxiv.org/ abs/2506.16724. Version Number: 2. 5
arXiv 2025
-
[37]
Stephen C. Hora. Aleatory and epistemic uncertainty in probability elicitation with an example from hazardous waste management.Reliability Engineering & System Safety, 54(2):217–223, November 1996. ISSN 0951-8320. doi: 10.1016/S0951-8320(96)00077-4. URL https: //www.sciencedirect.com/science/article/pii/S0951832096000774. 5
-
[38]
Quantifying Aleatoric and Epistemic Uncer- tainty with Proper Scoring Rules, April 2024
Paul Hofman, Yusuf Sale, and Eyke Hüllermeier. Quantifying Aleatoric and Epistemic Uncer- tainty with Proper Scoring Rules, April 2024. URL http://arxiv.org/abs/2404.12215. arXiv:2404.12215 [cs]. 5
arXiv 2024
-
[39]
Jones, Guoqing Wang, Vivek Yedavalli, and Haris Sair
Craig K. Jones, Guoqing Wang, Vivek Yedavalli, and Haris Sair. Direct quantification of epistemic and aleatoric uncertainty in 3D U-net segmentation.Journal of Medical Imaging, 9(3):034002, May 2022. ISSN 2329-4302. doi: 10.1117/1.JMI.9.3.034002. URL https: //pmc.ncbi.nlm.nih.gov/articles/PMC9174341/. 5
-
[40]
Matthew A. Chan, Maria J. Molina, and Christopher A. Metzler. Estimating Epistemic and Aleatoric Uncertainty with a Single Model, November 2024. URL http://arxiv.org/abs/ 2402.03478. arXiv:2402.03478 [cs]. 5
arXiv 2024
-
[41]
Regulating AI Agents, March 2026
Kathrin Gardhouse, Amin Oueslati, and Noam Kolt. Regulating AI Agents, March 2026. URL https://papers.ssrn.com/abstract=6462658. 5, 6
2026
-
[42]
Stephen Gilbert, Rasmus Adler, Taras Holoyad, and Eva Weicken. Could transparent model cards with layered accessible information drive trust and safety in health AI?NPJ Digital Medicine, 8:124, February 2025. ISSN 2398-6352. doi: 10.1038/s41746-025-01482-9. URL https://pmc.ncbi.nlm.nih.gov/articles/PMC11861263/. 6
-
[43]
A validated framework for responsible AI in healthcare autonomous sys- tems.Scientific Reports, 15(1):44432, December 2025
Turki Alelyani. A validated framework for responsible AI in healthcare autonomous sys- tems.Scientific Reports, 15(1):44432, December 2025. ISSN 2045-2322. doi: 10.1038/ s41598-025-25266-z. URL https://www.nature.com/articles/s41598-025-25266-z . 6
2025
-
[44]
Artificial Intelligence Risk Management Framework (AI RMF 1.0)
Elham Tabassi. Artificial Intelligence Risk Management Framework (AI RMF 1.0). Technical Report NIST AI 100-1, National Institute of Standards and Technology (U.S.), Gaithersburg, MD, January 2023. URL http://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1. pdf. 6
2023
-
[45]
Google DeepMind and healthcare in an age of algorithms
Julia Powles and Hal Hodson. Google DeepMind and healthcare in an age of algorithms. Health and Technology, 7(4):351–367, December 2017. ISSN 2190-7196. doi: 10.1007/ s12553-017-0179-1. URLhttps://doi.org/10.1007/s12553-017-0179-1. 12
-
[46]
Ziad Obermeyer, Brian Powers, Christine V ogeli, and Sendhil Mullainathan. Dissecting racial bias in an algorithm used to manage the health of populations.Science, 366(6464):447–453, October 2019. doi: 10.1126/science.aax2342. URL https://www.science.org/doi/10. 1126/science.aax2342. 12 16 The Clinician’s Veto: Navigating Trust, Liability, and Uncertainty...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.