Efficient Remote Sensing Instance Segmentation with Linear-Time State Space Distilled Visual Foundation Models
Pith reviewed 2026-06-25 21:18 UTC · model grok-4.3
The pith
Distilled state space models reduce parameters 8x and FLOPs 9x for remote sensing instance segmentation while matching ViT accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
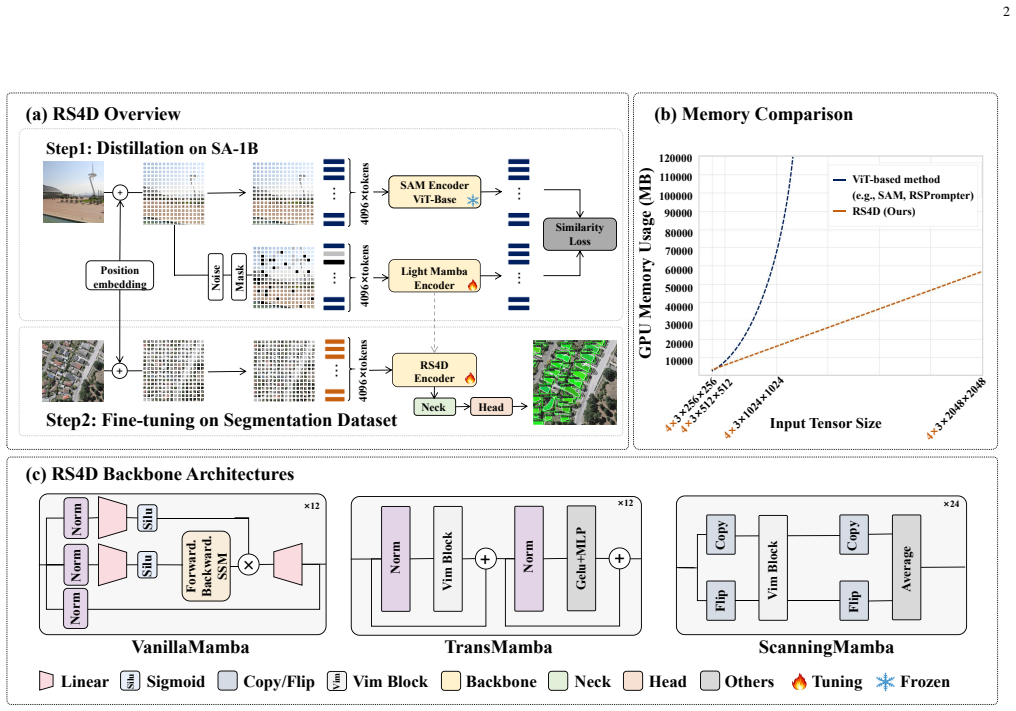
The central claim is that an adaptive noise and masking knowledge distillation procedure can successfully compress spatial and semantic features from large self-attention ViT models into a compact linear state space model, yielding an SSM visual backbone that delivers an 8x reduction in parameters and 9x reduction in FLOPs relative to ViT-based approaches while achieving comparable or superior accuracy on remote sensing instance segmentation benchmarks including SSDD, WHU, and NWPU.
What carries the argument
Adaptive noise and masking knowledge distillation that transfers features from self-attention ViT models into a linear state space model backbone for remote sensing segmentation.
If this is right
- The linear complexity of the SSM backbone enables processing of longer token sequences in dense prediction tasks without quadratic cost growth.
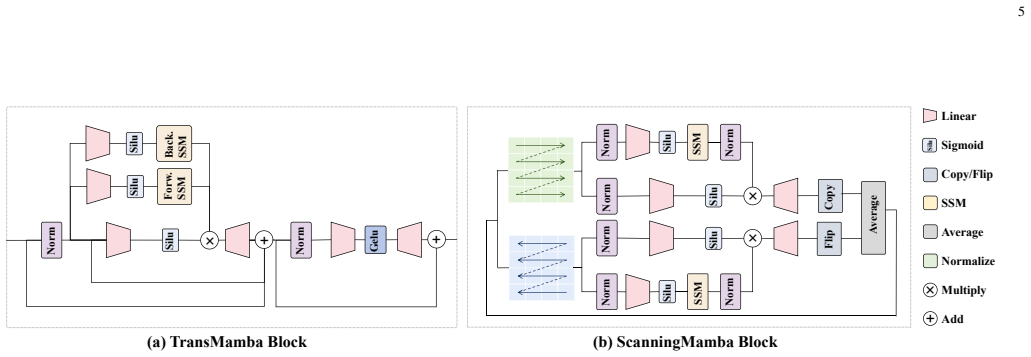
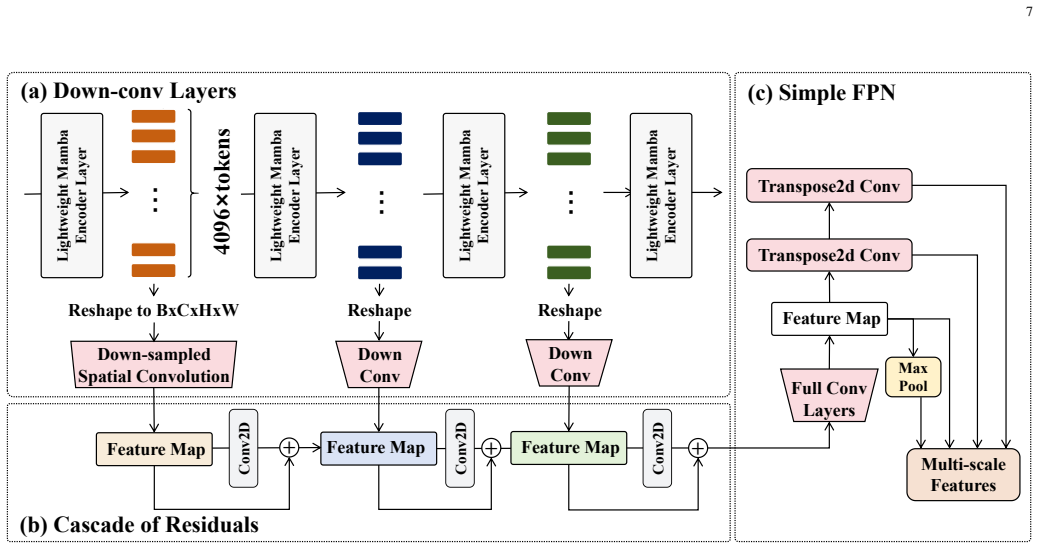
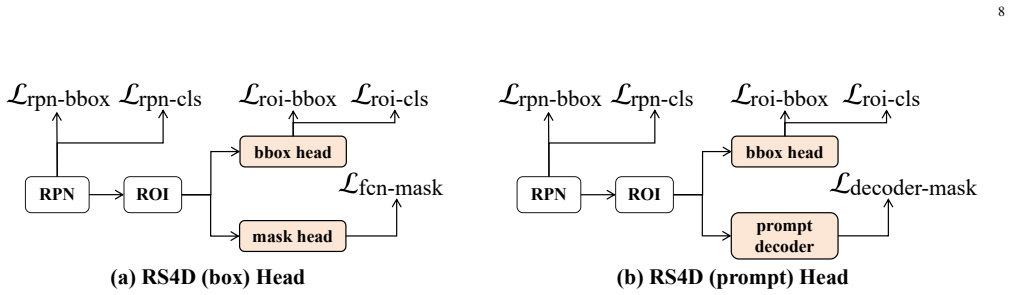
- The architecture supports multiple backbone variants and segmentation head choices tailored to remote sensing data characteristics.
- Public release of the implementation allows direct replication and extension on the cited benchmarks.
- Efficiency gains hold across both ViT- and CNN-comparison baselines while preserving accuracy levels.
Where Pith is reading between the lines
- The distillation technique may generalize to other dense vision tasks such as semantic segmentation or object detection outside remote sensing.
- Linear-time backbones could support real-time inference on satellite edge hardware where ViT models are currently prohibitive.
- Further scaling of the distilled SSM size might produce additional accuracy-efficiency trade-offs not explored in the current variants.
- The method suggests that language-model-style distillation pipelines can be adapted to compress vision foundation models into state space alternatives.
Load-bearing premise
The adaptive noise and masking knowledge distillation successfully transfers the necessary spatial and semantic features from self-attention-based ViT models into the linear state space without critical loss for remote sensing instance segmentation tasks.
What would settle it
Running the SSM backbone on a new remote sensing instance segmentation dataset and observing a statistically significant accuracy drop below the ViT baseline while the parameter and FLOP reductions remain would falsify the transfer claim.
Figures







read the original abstract
The computational complexity of Transformers scales quadratically with the number of tokens, which significantly constrains the efficiency of vision models, particularly recent ViT-based foundation models in dense prediction tasks. Instance segmentation, a typical dense visual prediction task in the remote sensing field, faces similar challenges. In this paper, inspired by the recent advances of knowledge distillation in large language models, we introduce RS4D - a new remote sensing instance segmentation method with linear computational complexity, which addresses the inefficiency of long sequence modeling through distilled state space modeling (SSM). We propose an adaptive noise and masking knowledge distillation training method for pre-training lightweight SSM backbones, which effectively compresses knowledge from the vast self-attention space into a compact, dense linear state space. We also design a remote sensing image instance segmentation architecture based on this lightweight visual encoder, where we explore variants of three different backbones and two segmentation heads. Extensive experiments are conducted on multiple benchmark datasets, including SSDD, WHU, and NWPU. Compared to ViT-based approaches, our proposed SSM backbone achieves an 8x reduction in parameters and a 9x reduction in FLOPs while maintaining comparable or superior accuracy to both ViT- and CNN-based instance segmentation methods. The implementation codes have been publicly available at https://github.com/QinzheYang/RS4D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RS4D, a remote sensing instance segmentation method that distills knowledge from ViT-based foundation models into lightweight state space model (SSM) backbones via an adaptive noise and masking strategy to achieve linear computational complexity. It explores three backbone variants and two segmentation heads, reporting on SSDD, WHU, and NWPU datasets an 8x parameter reduction and 9x FLOP reduction relative to ViT approaches while claiming comparable or superior accuracy to both ViT- and CNN-based methods. Code is released publicly.
Significance. If the distillation successfully transfers spatial and semantic features without critical loss, the result would enable more efficient deployment of instance segmentation in remote sensing applications where quadratic attention costs are prohibitive. The approach builds on known SSM properties and standard distillation, with the public code release aiding reproducibility.
major comments (1)
- [§4 (Experiments)] §4 (Experiments): The central claim of 8x parameter and 9x FLOP reductions with maintained accuracy rests on quantitative results, yet the manuscript provides no details on training protocols, baseline reimplementations, number of runs, error bars, or ablation studies on the distillation components. This directly affects assessment of whether the efficiency-accuracy tradeoff is robust.
minor comments (2)
- [Abstract] Abstract: The description of the adaptive noise and masking distillation could specify the exact SSM variant (e.g., Mamba) and the source ViT model to improve clarity for readers.
- [§3 (Method)] §3 (Method): Notation for the state space parameters and the masking schedule is introduced without an accompanying diagram or pseudocode, which would aid understanding of the linear-time claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. The major comment concerns insufficient experimental details in §4. We address this point below.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments): The central claim of 8x parameter and 9x FLOP reductions with maintained accuracy rests on quantitative results, yet the manuscript provides no details on training protocols, baseline reimplementations, number of runs, error bars, or ablation studies on the distillation components. This directly affects assessment of whether the efficiency-accuracy tradeoff is robust.
Authors: We agree that the original manuscript omitted key experimental details, limiting evaluation of the reported efficiency-accuracy tradeoff. In the revised version we will expand §4 with: complete training protocols and hyperparameters for the adaptive noise/masking distillation pre-training and downstream instance segmentation; explicit descriptions of baseline reimplementations (including any adaptations for remote-sensing data and fair comparison); results averaged over multiple runs with standard deviations reported as error bars; and targeted ablation studies on the adaptive noise and masking components of the distillation strategy. These additions will be placed in a new subsection and will directly support assessment of robustness. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on applying standard knowledge distillation from ViT models to SSM backbones (with known linear-time properties) and evaluating on public benchmarks (SSDD, WHU, NWPU). No equations, parameters, or uniqueness theorems are shown to reduce by construction to the target result itself; the method description in the abstract and method sections builds on externally established SSM and KD techniques without self-definitional loops or load-bearing self-citations. The efficiency-accuracy tradeoff is presented as an empirical outcome rather than a definitional identity.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math State space models compute sequences with linear complexity in sequence length.
Reference graph
Works this paper leans on
-
[1]
Object detection in 20 years: A survey,
Z. Zou, K. Chen, Z. Shi, Y . Guo, and J. Ye, “Object detection in 20 years: A survey,”Proceedings of the IEEE, vol. 111, no. 3, pp. 257– 276, 2023
2023
-
[2]
A survey on object detection in optical remote sensing images,
G. Cheng and J. Han, “A survey on object detection in optical remote sensing images,”ISPRS journal of photogrammetry and remote sensing, vol. 117, pp. 11–28, 2016
2016
-
[3]
Target detection in hyperspectral remote sensing image: Current status and challenges,
B. Chen, L. Liu, Z. Zou, and Z. Shi, “Target detection in hyperspectral remote sensing image: Current status and challenges,”Remote Sensing, vol. 15, no. 13, p. 3223, 2023
2023
-
[4]
Farseg++: Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery,
Z. Zheng, Y . Zhong, J. Wang, A. Ma, and L. Zhang, “Farseg++: Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[5]
Inherit with distillation and evolve with contrast: Exploring class incremental semantic segmentation without exemplar memory,
D. Zhao, B. Yuan, and Z. Shi, “Inherit with distillation and evolve with contrast: Exploring class incremental semantic segmentation without exemplar memory,”IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, vol. 45, no. 10, pp. 11 932–11 947, 2023
2023
-
[6]
Yolact: Real-time instance segmentation,
D. Bolya, C. Zhou, F. Xiao, and Y . J. Lee, “Yolact: Real-time instance segmentation,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9157–9166
2019
-
[7]
Solo: Segmenting objects by locations,
X. Wang, T. Kong, C. Shen, Y . Jiang, and L. Li, “Solo: Segmenting objects by locations,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16. Springer, 2020, pp. 649–665
2020
-
[8]
Polarmask: Single shot instance segmentation with polar rep- resentation,
E. Xie, P. Sun, X. Song, W. Wang, X. Liu, D. Liang, C. Shen, and P. Luo, “Polarmask: Single shot instance segmentation with polar rep- resentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 12 193–12 202
2020
-
[9]
Adaptis: Adaptive instance selection network,
K. Sofiiuk, O. Barinova, and A. Konushin, “Adaptis: Adaptive instance selection network,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 7355–7363
2019
-
[10]
Hq- isnet: High-quality instance segmentation for remote sensing imagery,
H. Su, S. Wei, S. Liu, J. Liang, C. Wang, J. Shi, and X. Zhang, “Hq- isnet: High-quality instance segmentation for remote sensing imagery,” Remote Sensing, vol. 12, no. 6, p. 989, 2020
2020
-
[11]
Learning building extraction in aerial scenes with convolu- tional networks,
J. Yuan, “Learning building extraction in aerial scenes with convolu- tional networks,”IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 11, pp. 2793–2798, 2017
2017
-
[12]
Unmixing convolutional features for crisp edge detection,
L. Huan, N. Xue, X. Zheng, W. He, J. Gong, and G.-S. Xia, “Unmixing convolutional features for crisp edge detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6602– 6609, 2021
2021
-
[13]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026
2023
-
[14]
Rsprompter: Learning to prompt for remote sensing instance seg- mentation based on visual foundation model,
K. Chen, C. Liu, H. Chen, H. Zhang, W. Li, Z. Zou, and Z. Shi, “Rsprompter: Learning to prompt for remote sensing instance seg- mentation based on visual foundation model,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[15]
Samrs: Scaling-up remote sensing segmentation dataset with segment anything model,
D. Wang, J. Zhang, B. Du, M. Xu, L. Liu, D. Tao, and L. Zhang, “Samrs: Scaling-up remote sensing segmentation dataset with segment anything model,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[16]
S. Zagoruyko and N. Komodakis, “Paying more attention to attention: Improving the performance of convolutional neural networks via atten- tion transfer,”arXiv preprint arXiv:1612.03928, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Resolution-agnostic re- mote sensing scene classification with implicit neural representations,
K. Chen, W. Li, J. Chen, Z. Zou, and Z. Shi, “Resolution-agnostic re- mote sensing scene classification with implicit neural representations,” IEEE Geoscience and Remote Sensing Letters, vol. 20, pp. 1–5, 2022. 16
2022
-
[18]
Spectralgpt: Spectral remote sensing foun- dation model,
D. Hong, B. Zhang, X. Li, Y . Li, C. Li, J. Yao, N. Yokoya, H. Li, P. Ghamisi, X. Jiaet al., “Spectralgpt: Spectral remote sensing foun- dation model,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[19]
Vehicle perception from satellite,
B. Zhao, P. Han, and X. Li, “Vehicle perception from satellite,”IEEE transactions on pattern analysis and machine intelligence, 2023
2023
-
[20]
Rsrefseg 2: Decoupling referring remote sensing image segmentation with foundation models,
K. Chen, C. Liu, B. Chen, J. Zhang, Z. Zou, and Z. Shi, “Rsrefseg 2: Decoupling referring remote sensing image segmentation with foundation models,”IEEE Transactions on Geoscience and Remote Sensing, pp. 1–1, 2025
2025
-
[21]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 344–16 359, 2022
2022
-
[22]
Poolingformer: Long document modeling with pooling attention,
H. Zhang, Y . Gong, Y . Shen, W. Li, J. Lv, N. Duan, and W. Chen, “Poolingformer: Long document modeling with pooling attention,” in International Conference on Machine Learning. PMLR, 2021, pp. 12 437–12 446
2021
-
[23]
Fastformer: Additive attention can be all you need
C. Wu, F. Wu, T. Qi, Y . Huang, and X. Xie, “Fastformer: Additive attention can be all you need,”arXiv preprint arXiv:2108.09084, 2021
-
[24]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long- document transformer,”arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[25]
Building extraction from remote sensing images with sparse token transformers,
K. Chen, Z. Zou, and Z. Shi, “Building extraction from remote sensing images with sparse token transformers,”Remote Sensing, vol. 13, no. 21, p. 4441, 2021
2021
-
[26]
Box2mask: Box-supervised instance segmentation via level-set evolu- tion,
W. Li, W. Liu, J. Zhu, M. Cui, R. Yu, X. Hua, and L. Zhang, “Box2mask: Box-supervised instance segmentation via level-set evolu- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 7, pp. 5157–5173, 2024
2024
-
[27]
Fully-connected transformer for multi-source image fu- sion,
X. Wu, Z.-H. Cao, T.-Z. Huang, L.-J. Deng, J. Chanussot, and G. Vivone, “Fully-connected transformer for multi-source image fu- sion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2071–2088, 2025
2071
-
[28]
Learning many-to-many mapping for unpaired real-world image super-resolution and downscaling,
W. Sun and Z. Chen, “Learning many-to-many mapping for unpaired real-world image super-resolution and downscaling,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[29]
Efficiently Modeling Long Sequences with Structured State Spaces
A. Gu, K. Goel, and C. R ´e, “Efficiently modeling long sequences with structured state spaces,”arXiv preprint arXiv:2111.00396, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
On the parameterization and initialization of diagonal state space models,
A. Gu, K. Goel, A. Gupta, and C. R ´e, “On the parameterization and initialization of diagonal state space models,”Advances in Neural Information Processing Systems, vol. 35, pp. 35 971–35 983, 2022
2022
-
[31]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,”arXiv preprint arXiv:2401.09417, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Combining recurrent, convolutional, and continuous-time models with linear state space layers,
A. Gu, I. Johnson, K. Goel, K. Saab, T. Dao, A. Rudra, and C. R ´e, “Combining recurrent, convolutional, and continuous-time models with linear state space layers,”Advances in neural information processing systems, vol. 34, pp. 572–585, 2021
2021
-
[33]
Hippo: Recurrent memory with optimal polynomial projections,
A. Gu, T. Dao, S. Ermon, A. Rudra, and C. R ´e, “Hippo: Recurrent memory with optimal polynomial projections,”Advances in neural information processing systems, vol. 33, pp. 1474–1487, 2020
2020
-
[34]
Mambainst: Lightweight state space model for real-time instance segmentation,
Z. Wang, C. Li, H. Xu, X. Zhu, X. Huang, and H. Li, “Mambainst: Lightweight state space model for real-time instance segmentation,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[35]
Spatial-mamba: Effective visual state space models via structure-aware state fusion,
C. Xiao, M. Li, Z. Zhang, D. Meng, and L. Zhang, “Spatial-mamba: Effective visual state space models via structure-aware state fusion,” arXiv preprint arXiv:2410.15091, 2024
-
[36]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Sar ship detection dataset (ssdd): Official release and comprehensive data analysis,
T. Zhang, X. Zhang, J. Li, X. Xu, B. Wang, X. Zhan, Y . Xu, X. Ke, T. Zeng, H. Suet al., “Sar ship detection dataset (ssdd): Official release and comprehensive data analysis,”Remote Sensing, vol. 13, no. 18, p. 3690, 2021
2021
-
[39]
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set,
S. Ji, S. Wei, and M. Lu, “Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set,” IEEE Transactions on geoscience and remote sensing, vol. 57, no. 1, pp. 574–586, 2018
2018
-
[40]
Multi-class geospatial object detection and geographic image classification based on collection of part detectors,
G. Cheng, J. Han, P. Zhou, and L. Guo, “Multi-class geospatial object detection and geographic image classification based on collection of part detectors,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 98, pp. 119–132, 2014
2014
-
[41]
Mask r-cnn,
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969
2017
-
[42]
Mask scoring r-cnn,
Z. Huang, L. Huang, Y . Gong, C. Huang, and X. Wang, “Mask scoring r-cnn,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6409–6418
2019
-
[43]
Hybrid task cascade for instance segmenta- tion,
K. Chen, J. Pang, J. Wang, Y . Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyanget al., “Hybrid task cascade for instance segmenta- tion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4974–4983
2019
-
[44]
Conditional convolutions for instance segmentation,
Z. Tian, C. Shen, and H. Chen, “Conditional convolutions for instance segmentation,” inComputer Vision–ECCV 2020: 16th European Con- ference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16. Springer, 2020, pp. 282–298
2020
-
[45]
Solov2: Dynamic and fast instance segmentation,
X. Wang, R. Zhang, T. Kong, L. Li, and C. Shen, “Solov2: Dynamic and fast instance segmentation,”Advances in Neural information pro- cessing systems, vol. 33, pp. 17 721–17 732, 2020
2020
-
[46]
Masked-attention mask transformer for universal image segmenta- tion,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmenta- tion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1290–1299
2022
-
[47]
Efficientsam: Leveraged masked image pretraining for efficient segment anything,
Y . Xiong, B. Varadarajan, L. Wu, X. Xiang, F. Xiao, C. Zhu, X. Dai, D. Wang, F. Sun, F. Iandolaet al., “Efficientsam: Leveraged masked image pretraining for efficient segment anything,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 111–16 121
2024
-
[48]
Psalm: Pixelwise segmentation with large multi-modal model,
Z. Zhang, Y . Ma, E. Zhang, and X. Bai, “Psalm: Pixelwise segmentation with large multi-modal model,” inEuropean Conference on Computer Vision. Springer, 2025, pp. 74–91
2025
-
[49]
Ddp: Diffusion model for dense visual prediction,
Y . Ji, Z. Chen, E. Xie, L. Hong, X. Liu, Z. Liu, T. Lu, Z. Li, and P. Luo, “Ddp: Diffusion model for dense visual prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 21 741–21 752
2023
-
[50]
Generative semantic segmenta- tion,
J. Chen, J. Lu, X. Zhu, and L. Zhang, “Generative semantic segmenta- tion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7111–7120
2023
-
[51]
Extract free dense labels from clip,
C. Zhou, C. C. Loy, and B. Dai, “Extract free dense labels from clip,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 696–712
2022
-
[52]
Image segmentation in foundation model era: A survey,
T. Zhou, F. Zhang, B. Chang, W. Wang, Y . Yuan, E. Konukoglu, and D. Cremers, “Image segmentation in foundation model era: A survey,” arXiv preprint arXiv:2408.12957, 2024
-
[53]
Learning to aggregate multi-scale context for instance segmentation in remote sensing images,
Y . Liu, H. Li, C. Hu, S. Luo, Y . Luo, and C. W. Chen, “Learning to aggregate multi-scale context for instance segmentation in remote sensing images,”IEEE Transactions on Neural Networks and Learning Systems, 2024
2024
-
[54]
Autosam: Adapting sam to medical images by overloading the prompt encoder,
T. Shaharabany, A. Dahan, R. Giryes, and L. Wolf, “Autosam: Adapting sam to medical images by overloading the prompt encoder,”arXiv preprint arXiv:2306.06370, 2023
-
[55]
Mobilesamv2: Faster segment anything to everything,
C. Zhang, D. Han, S. Zheng, J. Choi, T.-H. Kim, and C. S. Hong, “Mobilesamv2: Faster segment anything to everything,”arXiv preprint arXiv:2312.09579, 2023
-
[56]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
C. Zhang, D. Han, Y . Qiao, J. U. Kim, S.-H. Bae, S. Lee, and C. S. Hong, “Faster segment anything: Towards lightweight sam for mobile applications,”arXiv preprint arXiv:2306.14289, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
0.1% data makes segment anything slim,
Z. Chen, G. Fang, X. Ma, and X. Wang, “0.1% data makes segment anything slim,”arXiv preprint arXiv:2312.05284, 2023
-
[58]
Rs-sam: integrating multi-scale information for enhanced remote sensing image segmentation,
E. Zhang, J. Liu, A. Cao, Z. Sun, H. Zhang, H. Wang, L. Sun, and M. Song, “Rs-sam: integrating multi-scale information for enhanced remote sensing image segmentation,” inProceedings of the Asian Conference on Computer Vision, 2024, pp. 994–1010
2024
-
[59]
Distilling the Knowledge in a Neural Network
G. Hinton, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[60]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,”arXiv preprint arXiv:1510.00149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[61]
Singular value decomposition (svd) and generalized singular value decomposition,
H. Abdi, “Singular value decomposition (svd) and generalized singular value decomposition,”Encyclopedia of measurement and statistics, vol. 907, no. 912, p. 44, 2007
2007
-
[62]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
F. N. Iandola, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size,”arXiv preprint arXiv:1602.07360, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[63]
FitNets: Hints for Thin Deep Nets
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y . Ben- gio, “Fitnets: Hints for thin deep nets,”arXiv preprint arXiv:1412.6550, 2014. 17
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[64]
Learning efficient convolutional networks through network slimming,
Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, and C. Zhang, “Learning efficient convolutional networks through network slimming,” inPro- ceedings of the IEEE international conference on computer vision, 2017, pp. 2736–2744
2017
-
[65]
Pruning Convolutional Neural Networks for Resource Efficient Inference
P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz, “Pruning convolutional neural networks for resource efficient inference,”arXiv preprint arXiv:1611.06440, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[66]
Pruning from scratch,
Y . Wang, X. Zhang, L. Xie, J. Zhou, H. Su, B. Zhang, and X. Hu, “Pruning from scratch,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 273–12 280
2020
-
[67]
Compress- ing neural networks with the hashing trick,
W. Chen, J. Wilson, S. Tyree, K. Weinberger, and Y . Chen, “Compress- ing neural networks with the hashing trick,” inInternational conference on machine learning. PMLR, 2015, pp. 2285–2294
2015
-
[68]
Improving the speed of neural networks on cpus,
V . Vanhoucke, A. Senior, M. Z. Maoet al., “Improving the speed of neural networks on cpus,” inProc. deep learning and unsupervised feature learning NIPS workshop, vol. 1, no. 2011, 2011, p. 4
2011
-
[69]
Training deep neural networks with low precision multiplications
M. Courbariaux, Y . Bengio, and J.-P. David, “Training deep neu- ral networks with low precision multiplications,”arXiv preprint arXiv:1412.7024, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[70]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[71]
Shufflenet: An extremely effi- cient convolutional neural network for mobile devices,
X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely effi- cient convolutional neural network for mobile devices,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6848–6856
2018
-
[72]
Xception: Deep learning with depthwise separable convo- lutions,
F. Chollet, “Xception: Deep learning with depthwise separable convo- lutions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258
2017
-
[73]
Attention is all you need,
A. Vaswani, “Attention is all you need,”Advances in Neural Informa- tion Processing Systems, 2017
2017
-
[74]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[75]
Finding structure in time,
J. L. Elman, “Finding structure in time,”Cognitive science, vol. 14, no. 2, pp. 179–211, 1990
1990
-
[76]
Simplified State Space Layers for Sequence Modeling
J. T. Smith, A. Warrington, and S. W. Linderman, “Simplified state space layers for sequence modeling,”arXiv preprint arXiv:2208.04933, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[77]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[78]
Vmamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, and Y . Liu, “Vmamba: Visual state space model,”arXiv preprint arXiv:2403.10696, 2024
-
[79]
Mambamixer: Efficient selective state space models with dual token and channel selection,
A. Behrouz, M. Santacatterina, and R. Zabih, “Mambamixer: Efficient selective state space models with dual token and channel selection,” arXiv preprint arXiv:2403.19888, 2024
-
[80]
U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
J. Ma, F. Li, and B. Wang, “U-mamba: Enhancing long-range dependency for biomedical image segmentation,”arXiv preprint arXiv:2401.04722, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.