EmuGEMM: Fused Tensor Core Kernels for Precision Emulation in Matrix Multiplication
Pith reviewed 2026-06-25 20:24 UTC · model grok-4.3
The pith
Fused Tensor Core kernels remove global memory round-trips in Ozaki schemes to deliver high-precision GEMM near the speed of low-precision hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By fusing the low-precision Tensor Core operations of Ozaki Schemes I and II into kernels that never materialize partial results in global memory, EmuGEMM reconstructs high-precision GEMM results at 81-83 percent of the underlying INT8 peak throughput on Hopper and Blackwell GPUs, surpassing cuBLAS TF32 by up to 1.7x and cuBLAS ZGEMM by up to 5.5x at comparable accuracy.
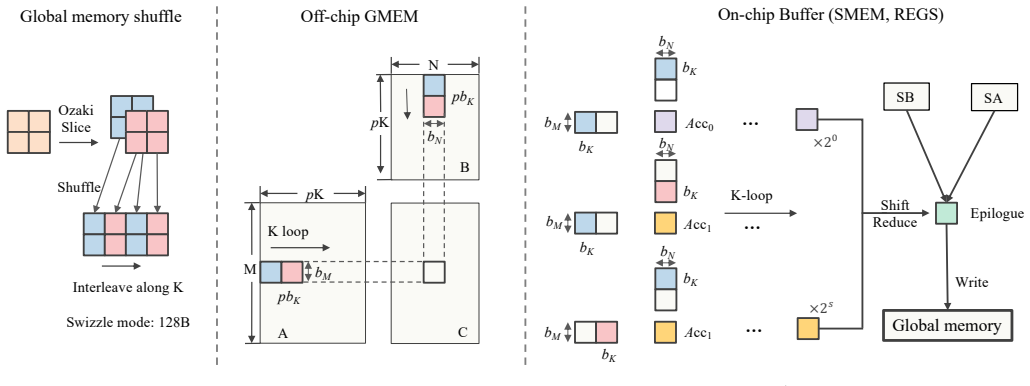
What carries the argument
Fused integer Tensor Core kernels that implement the full Ozaki Scheme I and Scheme II pipelines without writing intermediates to global memory.
If this is right
- On large matrices EmuGEMM exceeds cuBLAS TF32 throughput by up to 1.4x on Hopper and 1.7x on Blackwell at comparable accuracy.
- Scheme II kernels outperform cuBLAS ZGEMM by up to 2.3x on Hopper and 5.5x on Blackwell.
- Peak sustained rates reach 1639 Top/s on Hopper (83 percent of INT8 peak) and 3654 Top/s on Blackwell (81 percent of INT8 peak).
Where Pith is reading between the lines
- The same fusion technique could be applied to other decomposition-based emulation methods that currently spill intermediates.
- Scientific codes that currently drop to TF32 or FP32 for speed might switch to these kernels to retain higher effective precision without changing hardware.
- Accuracy versus performance trade-offs become tunable by choosing the number of low-precision terms inside the fused kernel rather than by changing the outer algorithm.
Load-bearing premise
That the dominant cost in prior Ozaki implementations is repeated global-memory materialization of intermediates and that fusing the steps removes this cost without adding new overheads or accuracy loss.
What would settle it
A direct timing comparison on the same large matrices showing that the fused kernels run slower than a correctly implemented non-fused Ozaki baseline or that their numeric results diverge measurably from it.
Figures






read the original abstract
Modern GPUs devote an increasing silicon budget to low-precision matrix-multiplication units, widening the precision-throughput gap for scientific computing workloads. Ozaki Schemes I and II offer an alternative by reconstructing high-precision general matrix multiplication (GEMM) from low-precision operations, yet existing implementations leave substantial performance untapped. In particular, intermediate results are repeatedly materialized in global memory, making data movement the dominant bottleneck. We present EmuGEMM, fused integer Tensor Core kernels for NVIDIA Hopper and Blackwell GPUs that eliminate redundant memory round-trips in both Ozaki schemes. Using Scheme I, EmuGEMM sustains up to 1,639 Top/s on Hopper (83% of INT8 peak) and 3,654 Top/s on Blackwell (81%). For large matrices, EmuGEMM surpasses cuBLAS TF32 throughput by up to 1.4x on Hopper and 1.7x on Blackwell, at comparable accuracy. Using Scheme II, EmuGEMM extends to complex arithmetic and outperforms cuBLAS ZGEMM by up to 2.3x on Hopper and 5.5x on Blackwell.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents EmuGEMM, fused integer Tensor Core kernels implementing Ozaki Schemes I and II for emulating high-precision GEMM on NVIDIA Hopper and Blackwell GPUs. It claims these kernels eliminate repeated global-memory materialization of intermediates that dominates prior implementations, achieving up to 1,639 TOP/s (83% of INT8 peak) on Hopper and 3,654 TOP/s (81%) on Blackwell. For large matrices, EmuGEMM reports up to 1.4× (Hopper) and 1.7× (Blackwell) over cuBLAS TF32 at comparable accuracy under Scheme I, and up to 2.3× (Hopper) and 5.5× (Blackwell) over cuBLAS ZGEMM under Scheme II.
Significance. If the reported speedups and accuracy preservation are reproducible and the fusion indeed removes the claimed DRAM bottleneck without offsetting overheads, the work would be significant for scientific computing on modern GPUs. It demonstrates a practical route to higher effective precision using the abundant low-precision Tensor Core throughput, with explicit credit due for the implementation-level optimizations that reach 81-83% of peak INT8 utilization.
major comments (3)
- [§4] §4 (Fused Kernel Design), paragraph on Scheme I/II fusion: the central premise that prior Ozaki implementations are dominated by repeated global-memory round-trips and that the fused schedule removes this cost without new shared-memory or register pressure is not accompanied by a roofline analysis or explicit DRAM bandwidth measurements; the reported TOP/s numbers alone do not isolate the contribution of fusion versus other tuning.
- [§5.2] §5.2 (Accuracy Evaluation): the statement of 'comparable accuracy' to cuBLAS TF32 is presented without per-matrix residual norms, relative error distributions, or comparison against a reference high-precision implementation; this is load-bearing for the claim that fusion preserves numerical fidelity.
- [Table 2] Table 2 (Performance on large matrices): the 1.4×–1.7× speedups over cuBLAS TF32 and 2.3×–5.5× over ZGEMM are reported for specific matrix sizes, but the paper does not state whether the cuBLAS baselines were run with the same blocking or whether the EmuGEMM kernels were measured under identical launch configurations; this affects the validity of the cross-implementation comparison.
minor comments (2)
- [Abstract] The abstract and §1 use 'TOP/s' without defining whether this is integer or effective floating-point operations; consistent notation with the rest of the paper would improve clarity.
- [Figure 3] Figure 3 (kernel timeline) would benefit from explicit annotation of the removed global-memory writes that the text claims are eliminated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential significance. We address each major comment below with clarifications from the manuscript and commit to revisions that strengthen the presentation of evidence.
read point-by-point responses
-
Referee: [§4] §4 (Fused Kernel Design), paragraph on Scheme I/II fusion: the central premise that prior Ozaki implementations are dominated by repeated global-memory round-trips and that the fused schedule removes this cost without new shared-memory or register pressure is not accompanied by a roofline analysis or explicit DRAM bandwidth measurements; the reported TOP/s numbers alone do not isolate the contribution of fusion versus other tuning.
Authors: The manuscript's Section 4 describes the fused schedule that keeps all intermediate splits in registers and shared memory, directly eliminating the global-memory round-trips that dominate the non-fused baselines referenced in the introduction. The reported 83% and 81% of INT8 peak are measured on the fused kernels; these utilization figures would be unattainable if DRAM traffic remained the limiter. We nevertheless agree that an explicit roofline or bandwidth measurement would isolate the fusion benefit more clearly and will add a short roofline figure and traffic estimates in the revised Section 4. revision: yes
-
Referee: [§5.2] §5.2 (Accuracy Evaluation): the statement of 'comparable accuracy' to cuBLAS TF32 is presented without per-matrix residual norms, relative error distributions, or comparison against a reference high-precision implementation; this is load-bearing for the claim that fusion preserves numerical fidelity.
Authors: The accuracy statement rests on the fact that EmuGEMM implements the exact Ozaki splitting and accumulation steps of the original scheme, introducing no additional rounding beyond what the mathematical formulation already incurs. We will strengthen Section 5.2 by adding per-matrix residual norms (relative to a double-precision reference) and error-distribution plots for the evaluated sizes, confirming that the observed errors remain within the bounds expected from the scheme itself. revision: yes
-
Referee: [Table 2] Table 2 (Performance on large matrices): the 1.4×–1.7× speedups over cuBLAS TF32 and 2.3×–5.5× over ZGEMM are reported for specific matrix sizes, but the paper does not state whether the cuBLAS baselines were run with the same blocking or whether the EmuGEMM kernels were measured under identical launch configurations; this affects the validity of the cross-implementation comparison.
Authors: cuBLAS results were obtained via the standard cublasGemmEx / cublasZgemm APIs using library defaults for the respective precisions on the same GPU and matrix dimensions; EmuGEMM used its own optimized launch parameters. We will revise the experimental-setup paragraph and Table 2 caption to explicitly list the cuBLAS version, any environment variables, and confirm that all timings were collected under identical hardware and problem-size conditions. revision: yes
Circularity Check
No circularity: empirical implementation results with no derivations or self-referential fits
full rationale
The paper contains no equations, derivations, or mathematical claims that could reduce to inputs by construction. All central results are measured throughput and accuracy numbers from GPU kernel benchmarks (e.g., 1,639 Top/s on Hopper). The assumption that global-memory materialization is the dominant bottleneck is an engineering premise tested by the implementation itself, not a fitted parameter or self-citation chain. No load-bearing self-citations or ansatzes appear in the provided text. The work is self-contained as a systems paper whose validity rests on external hardware measurements rather than internal redefinitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FlashAttention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e, “FlashAttention: Fast and memory-efficient exact attention with io-awareness,” in Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 16 344–16 359. [Online]. Available: https://proceedings.neu...
2022
-
[2]
N. Vetsch, A. Maeder, V . Maillou, A. Winka, J. Cao, G. Kwasniewski, L. Deuschle, T. Hoefler, A. N. Ziogas, and M. Luisier, “Ab-initio quantum transport with the GW approximation, 42,240 atoms, and sustained exascale performance,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’25. N...
-
[3]
Nvidia tensor cores,
NVIDIA Corporation, “Nvidia tensor cores,” https://www.nvidia.com/ en-us/data-center/tensor-cores/, 2025
2025
-
[4]
AMD CDNA Architecture,
Advanced Micro Devices, “AMD CDNA Architecture,” https://www. amd.com/en/technologies/cdna.html, 2026
2026
-
[5]
NVIDIA H100 Tensor Core GPU architecture whitepaper,
NVIDIA Corporation, “NVIDIA H100 Tensor Core GPU architecture whitepaper,” https://resources.nvidia.com/en-us-tensor-core, 2022
2022
-
[6]
Simulating low precision floating-point arithmetic,
N. J. Higham and S. Pranesh, “Simulating low precision floating-point arithmetic,”SIAM Journal on Scientific Computing, vol. 41, no. 5, pp. C585–C602, 2019. [Online]. Available: https://doi.org/10.1137/ 19M1251308
2019
-
[7]
Mixed precision block fused multiply-add: Error analysis and application to gpu tensor cores,
P. Blanchard, N. J. Higham, F. Lopez, T. Mary, and S. Pranesh, “Mixed precision block fused multiply-add: Error analysis and application to gpu tensor cores,”SIAM Journal on Scientific Computing, vol. 42, no. 3, pp. C124–C141, 2020. [Online]. Available: https://doi.org/10.1137/19M1289546
-
[8]
K. Ozaki, T. Ogita, S. Oishi, and S. M. Rump, “Error-free transformations of matrix multiplication by using fast routines of matrix multiplication and its applications,”Numer. Algorithms, vol. 59, no. 1, p. 95–118, Jan. 2012. [Online]. Available: https: //doi.org/10.1007/s11075-011-9478-1
-
[9]
Dgemm on integer matrix multiplication unit,
H. Ootomo, K. Ozaki, and R. Yokota, “DGEMM on integer matrix multiplication unit,”The International Journal of High Performance Computing Applications, vol. 38, no. 4, pp. 297–313, 2024. [Online]. Available: https://doi.org/10.1177/10943420241239588
-
[10]
K. Ozaki, Y . Uchino, and T. Imamura, “Ozaki Scheme II: A GEMM-oriented emulation of floating-point matrix multiplication using an integer modular technique,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2504.08009
-
[11]
Emulation of complex matrix multiplication based on the chinese remainder theorem,
Y . Uchino, Q. Ma, T. Imamura, K. Ozaki, and P. L. Gutsche, “Emulation of complex matrix multiplication based on the chinese remainder theorem,” 2025. [Online]. Available: https://doi.org/10.48550/ arXiv.2512.08321
arXiv 2025
-
[12]
Performance enhancement of the ozaki scheme on integer matrix multiplication unit,
Y . Uchino, K. Ozaki, and T. Imamura, “Performance enhancement of the ozaki scheme on integer matrix multiplication unit,”The International Journal of High Performance Computing Applications, vol. 39, no. 3, p. 462–476, jan 2025. [Online]. Available: https: //doi.org/10.1177/10943420241313064
-
[13]
A. Schwarz, A. Anders, C. Brower, H. Bayraktar, J. Gunnels, K. Clark, R. G. Xu, S. Rodriguez, S. Cayrols, P. Tabaszewski, and V . Podlozhnyuk, “Guaranteed DGEMM accuracy while using reduced precision tensor cores through extensions of the Ozaki scheme,” inProceedings of the Supercomputing Asia and International Conference on High Performance Computing in ...
-
[14]
DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling,
DeepSeek, “DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling,” https://github.com/deepseek-ai/DeepGEMM, 2025
2025
-
[15]
CuTe layout representation and algebra,
C. Cecka, “CuTe layout representation and algebra,” 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.02298
-
[16]
CUTLASS,
V . Thakkar, P. Ramani, C. Cecka, A. Shivam, H. Lu, E. Yan, J. Kosaian, M. Hoemmen, H. Wu, A. Kerr, M. Nicely, D. Merrill, D. Blasig, A. Atluri, F. Qiao, P. Majcher, P. Springer, M. Hohnerbach, J. Wang, and M. Gupta, “CUTLASS,” Jan. 2023. [Online]. Available: https://github.com/NVIDIA/cutlass
2023
-
[17]
Vast.ai GPU compute marketplace,
Vast.ai, Inc., “Vast.ai GPU compute marketplace,” https://vast.ai, 2026, accessed: 2026-04-05
2026
-
[18]
GEMMul8 (GEMMulate): GEMM emulation using INT8/FP8 matrix engines based on the Ozaki Scheme II,
RIKEN R-CCS, “GEMMul8 (GEMMulate): GEMM emulation using INT8/FP8 matrix engines based on the Ozaki Scheme II,” https://github. com/RIKEN-RCCS/GEMMul8, 2025
2025
-
[19]
Y . Uchino, K. Ozaki, and T. Imamura, “High-performance and power-efficient emulation of matrix multiplication using INT8 matrix engines,” inProceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC Workshops ’25. New York, NY , USA: Association for Computing Machinery, 20...
-
[20]
arXiv preprint arXiv:2508.00441 , year=
D. Mukunoki, “DGEMM without FP64 arithmetic - using FP64 emulation and FP8 tensor cores with Ozaki scheme,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.00441
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.