Steering Vision-Language Models with Joint Sparse Autoencoders
Pith reviewed 2026-06-25 20:55 UTC · model grok-4.3
The pith
Explicitly aligned sparse representations from Joint Sparse Autoencoders support more controllable cross-modal interventions in vision-language models than unconstrained alternatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
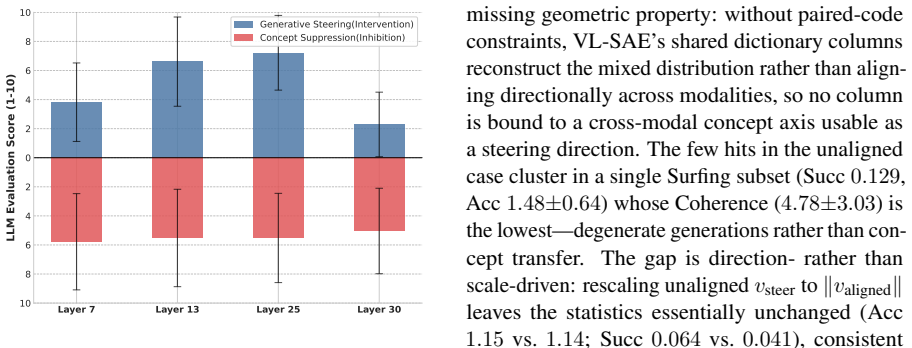
By applying an explicit alignment constraint during factorization of sequence-pooled vision and language activations, the Joint Sparse Autoencoder recovers shared interpretable features for concepts such as food and animals. Bidirectional interventions on LLaVA and two other VLMs show a layer-dependent pattern: additive steering peaks at mid-to-late pre-output layers while suppression scores remain comparable across all tested layers within noise. The same localized effects appear across architectures including a mixture-of-experts model.
What carries the argument
The Joint Sparse Autoencoder with explicit alignment constraint, which jointly factorizes vision and language activations into shared image/caption-level features for use in interventions.
If this is right
- Additive steering effects reach their maximum in mid-to-late pre-output layers.
- Suppression effects remain stable across all probed layers within statistical noise.
- The same layer-localized intervention patterns appear in LLaVA-v1.6-Mistral-7B, Llama3-LLaVA-8B, and Qwen3-VL-30B.
- Unconstrained sparse autoencoders yield representations that are harder to use for controllable bidirectional steering.
- The recovered features correspond to recognizable concepts that can be targeted for addition or removal.
Where Pith is reading between the lines
- The identified mid-to-late layer range could serve as a practical starting point for applying interventions in deployed vision-language systems.
- The same joint factorization approach might be tested on other multimodal inputs such as video or audio paired with text.
- Shared features could be examined to trace how visual and language information combine at different depths inside the model.
- Steering success on concept-level tasks might be checked for carry-over effects on standard VLM benchmarks.
Load-bearing premise
The alignment constraint produces genuinely shared and causally controllable cross-modal features rather than merely correlated but non-causal directions.
What would settle it
A head-to-head test on the same VLMs and layers where unconstrained sparse autoencoders achieve equal or higher controllability scores in both additive steering and suppression interventions.
Figures




read the original abstract
Sparse Autoencoders (SAEs) have shown promise for analyzing language models, but applying them to vision-language models (VLMs) often yields representations that are difficult to use as controllable cross-modal steering directions. We introduce the Joint Sparse Autoencoder (JSAE), which uses an explicit alignment constraint to jointly factorize sequence-pooled vision and language activations into shared, interpretable image/caption-level features. Applied to LLaVA, JSAE recovers cross-modal features for recognizable concepts (e.g., food and animals). Through bidirectional interventions (additive steering and suppression), we observe a layer-dependent asymmetry under our protocol: additive steering peaks at mid-to-late (pre-output) layers and weakens at both ends, whereas suppression scores remain within a comparable range across all probed layers within statistical noise. Experiments on three VLMs, namely LLaVA-v1.6-Mistral-7B, Llama3-LLaVA-8B, and the MoE-based Qwen3-VL-30B, show related layer-localized effects across architectures. Together, these results suggest that explicitly aligned sparse representations support more controllable intervention-based analysis of multimodal features, within an identifiable layer range, than the unconstrained alternatives tested here.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Joint Sparse Autoencoders (JSAE) that add an explicit alignment constraint to jointly factorize sequence-pooled vision and language activations from VLMs into shared sparse features at the image/caption level. Applied to LLaVA-v1.6-Mistral-7B, Llama3-LLaVA-8B and Qwen3-VL-30B, the method recovers recognizable cross-modal concepts and yields bidirectional intervention results (additive steering and suppression) that exhibit a layer-dependent asymmetry: steering efficacy peaks in mid-to-late layers while suppression remains roughly stable; the authors conclude that explicitly aligned sparse representations enable more controllable cross-modal analysis than the unconstrained SAEs tested.
Significance. If the alignment term is shown to isolate genuinely causal shared directions rather than correlated but non-causal ones, the approach would supply a concrete, reproducible protocol for mechanistic intervention in multimodal models and identify a usable layer range for steering. The cross-architecture replication on three VLMs strengthens the empirical scope.
major comments (3)
- [§3] §3 (JSAE objective): the central claim that the explicit alignment constraint produces controllable shared cross-modal features requires an ablation that removes only the alignment loss while preserving joint factorization, sparsity targets, and reconstruction; no such isolation is described, so the reported superiority over unconstrained SAEs could arise from differences in regularization or feature selection rather than alignment itself.
- [§4.2–4.3] §4.2–4.3 (bidirectional interventions): the layer-asymmetry claim (steering peaks mid-to-late, suppression stable) is load-bearing for the “identifiable layer range” conclusion, yet the text provides no quantitative breakdown of how much variance is explained by the alignment term versus baseline SAE variants, nor reports effect sizes or confidence intervals that would allow readers to judge whether the gains exceed statistical noise.
- [Table 2 / Figure 4] Table 2 / Figure 4 (cross-VLM results): the assertion of “related layer-localized effects across architectures” is presented without a direct statistical comparison (e.g., interaction term between model and layer) that would confirm the pattern is not driven by architecture-specific hyperparameters.
minor comments (2)
- [§3] Notation for the alignment loss term is introduced without an explicit equation number; readers must infer its functional form from surrounding prose.
- [§4] The abstract states “within statistical noise” for suppression stability but the main text does not specify the exact test or correction used; a brief methods sentence would clarify.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§3] §3 (JSAE objective): the central claim that the explicit alignment constraint produces controllable shared cross-modal features requires an ablation that removes only the alignment loss while preserving joint factorization, sparsity targets, and reconstruction; no such isolation is described, so the reported superiority over unconstrained SAEs could arise from differences in regularization or feature selection rather than alignment itself.
Authors: We agree that an ablation isolating the alignment loss term is necessary to attribute performance gains specifically to the alignment constraint. In the revised manuscript, we will add this ablation by training a joint factorization SAE with the alignment loss removed (while matching all other hyperparameters, sparsity targets, and reconstruction objectives) and directly compare feature interpretability and intervention results against the full JSAE. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (bidirectional interventions): the layer-asymmetry claim (steering peaks mid-to-late, suppression stable) is load-bearing for the “identifiable layer range” conclusion, yet the text provides no quantitative breakdown of how much variance is explained by the alignment term versus baseline SAE variants, nor reports effect sizes or confidence intervals that would allow readers to judge whether the gains exceed statistical noise.
Authors: We acknowledge that the current presentation lacks sufficient statistical detail. We will revise sections 4.2–4.3 to include effect sizes, confidence intervals for intervention scores, and a quantitative comparison of variance explained by the alignment term versus baseline SAE variants. These additions will be incorporated into the updated text and figures. revision: yes
-
Referee: [Table 2 / Figure 4] Table 2 / Figure 4 (cross-VLM results): the assertion of “related layer-localized effects across architectures” is presented without a direct statistical comparison (e.g., interaction term between model and layer) that would confirm the pattern is not driven by architecture-specific hyperparameters.
Authors: We agree that a formal statistical test is needed to support the cross-architecture generalization claim. In the revision, we will add a mixed-effects model or ANOVA including an interaction term between model and layer, reporting the results alongside Table 2 and Figure 4 to assess consistency of the layer-dependent patterns across the three VLMs. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces JSAE as a method with an explicit alignment constraint and reports empirical results from bidirectional interventions on three VLMs, claiming layer-dependent effects and superiority over unconstrained SAEs. No equations, derivations, or self-citations are shown that reduce the central claim to a fitted parameter, self-definition, or prior author result by construction. The claims rest on experimental observations rather than any mathematical identity or load-bearing self-reference, making the analysis self-contained as an empirical comparison.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2015 , eprint=
Microsoft COCO Captions: Data Collection and Evaluation Server , author=. 2015 , eprint=
2015
-
[2]
2016 , eprint=
VQA: Visual Question Answering , author=. 2016 , eprint=
2016
-
[3]
2019 , eprint=
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering , author=. 2019 , eprint=
2019
-
[4]
2023 , eprint=
PaLM-E: An Embodied Multimodal Language Model , author=. 2023 , eprint=
2023
-
[5]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[6]
2023 , eprint=
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models , author=. 2023 , eprint=
2023
-
[7]
2024 , eprint=
Improved Baselines with Visual Instruction Tuning , author=. 2024 , eprint=
2024
-
[8]
2022 , eprint=
Toy Models of Superposition , author=. 2022 , eprint=
2022
-
[9]
2023 , eprint=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
2023
-
[10]
2017 , eprint=
SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability , author=. 2017 , eprint=
2017
-
[11]
2018 , eprint=
Insights on representational similarity in neural networks with canonical correlation , author=. 2018 , eprint=
2018
-
[12]
2018 , eprint=
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
2018
-
[13]
2021 , eprint=
Probing Classifiers: Promises, Shortcomings, and Advances , author=. 2021 , eprint=
2021
-
[14]
2019 , eprint=
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks , author=. 2019 , eprint=
2019
-
[15]
2019 , eprint=
LXMERT: Learning Cross-Modality Encoder Representations from Transformers , author=. 2019 , eprint=
2019
-
[16]
2022 , eprint=
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation , author=. 2022 , eprint=
2022
-
[17]
2023 , eprint=
Visual Instruction Tuning , author=. 2023 , eprint=
2023
-
[18]
2023 , eprint=
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , author=. 2023 , eprint=
2023
-
[19]
2023 , eprint=
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. 2023 , eprint=
2023
-
[20]
Distill , year =
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, Shan Carter , title =. Distill , year =
-
[21]
2021 , journal =
A Mathematical Framework for Transformer Circuits , author =. 2021 , journal =
2021
-
[22]
2022 , eprint=
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small , author=. 2022 , eprint=
2022
-
[23]
Olah, Chris and Mordvintsev, Alexander and Schubert, Ludwig , title =. Distill , year =. doi:10.23915/distill.00007 , url =
-
[24]
Toy Models of Superposition , author =. 2022 , journal =. arXiv:2209.10652 , archivePrefix =
Pith/arXiv arXiv 2022
-
[25]
Transformer Circuits Thread , note =
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author =. Transformer Circuits Thread , note =
-
[26]
Transformer Circuits Thread , year=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author =. Transformer Circuits Thread , year=
-
[27]
2019 , eprint=
Similarity of Neural Network Representations Revisited , author=. 2019 , eprint=
2019
-
[28]
2021 , eprint=
MultiBench: Multiscale Benchmarks for Multimodal Representation Learning , author=. 2021 , eprint=
2021
-
[29]
2020 , eprint=
What Makes Training Multi-Modal Classification Networks Hard? , author=. 2020 , eprint=
2020
-
[30]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
-
[31]
2017 , eprint=
Network Dissection: Quantifying Interpretability of Deep Visual Representations , author=. 2017 , eprint=
2017
-
[32]
2022 , eprint=
Natural Language Descriptions of Deep Visual Features , author=. 2022 , eprint=
2022
-
[33]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[34]
2025 , eprint=
Layer-Wise Perturbations via Sparse Autoencoders for Adversarial Text Generation , author=. 2025 , eprint=
2025
-
[35]
Kaiyang Zhou and Jingkang Yang and Chen Change Loy and Ziwei Liu , title =. CoRR , volume =. 2021 , url =. 2109.01134 , timestamp =
arXiv 2021
-
[36]
2021 , eprint=
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author=. 2021 , eprint=
2021
-
[37]
2023 , eprint=
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model , author=. 2023 , eprint=
2023
-
[38]
2022 , eprint=
Prompt-to-Prompt Image Editing with Cross Attention Control , author=. 2022 , eprint=
2022
-
[39]
2016 , eprint=
A Diversity-Promoting Objective Function for Neural Conversation Models , author=. 2016 , eprint=
2016
-
[40]
2019 , eprint=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. 2019 , eprint=
2019
-
[41]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[42]
LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild , url=
Li, Bo and Zhang, Kaichen and Zhang, Hao and Guo, Dong and Zhang, Renrui and Li, Feng and Zhang, Yuanhan and Liu, Ziwei and Li, Chunyuan , month=. LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild , url=
-
[43]
2025 , eprint=
VL-SAE: Interpreting and Enhancing Vision-Language Alignment with a Unified Concept Set , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
Interpreting the linear structure of vision-language model embedding spaces , author=. 2025 , eprint=
2025
-
[45]
2025 , eprint=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. 2025 , eprint=
2025
-
[46]
2025 , eprint=
How Visual Representations Map to Language Feature Space in Multimodal LLMs , author=. 2025 , eprint=
2025
-
[47]
2024 , eprint=
Improving fine-grained understanding in image-text pre-training , author=. 2024 , eprint=
2024
-
[48]
2025 , eprint=
Weight-sparse transformers have interpretable circuits , author=. 2025 , eprint=
2025
-
[49]
2026 , eprint=
Decomposing multimodal embedding spaces with group-sparse autoencoders , author=. 2026 , eprint=
2026
-
[50]
International Conference on Learning Representations , volume=
Scaling and evaluating sparse autoencoders , author=. International Conference on Learning Representations , volume=
-
[51]
arXiv preprint arXiv:2407.14435 , year=
Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders , author=. arXiv preprint arXiv:2407.14435 , year=
-
[52]
arXiv preprint arXiv:2404.16014 , year=
Improving dictionary learning with gated sparse autoencoders , author=. arXiv preprint arXiv:2404.16014 , year=
-
[53]
arXiv preprint arXiv:2412.06410 , year=
Batchtopk sparse autoencoders , author=. arXiv preprint arXiv:2412.06410 , year=
-
[54]
The Price of Amortized inference in Sparse Autoencoders , author=
-
[55]
International conference on machine learning , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[56]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[57]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[58]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[59]
International Conference on Learning Representations , volume=
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. International Conference on Learning Representations , volume=
-
[60]
arXiv preprint arXiv:2303.03378 , year=
Palm-e: An embodied multimodal language model , author=. arXiv preprint arXiv:2303.03378 , year=
-
[61]
Representation engineering: A top-down approach to ai transparency, 2023 , author=. URL https://arxiv. org/abs/2310.01405 , volume=
Pith/arXiv arXiv 2023
-
[62]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[63]
arXiv preprint arXiv:2301.04709 , pages=
Causal abstraction for faithful model interpretation , author=. arXiv preprint arXiv:2301.04709 , pages=
-
[64]
Transactions of the Association for Computational Linguistics , volume=
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions , author=. Transactions of the Association for Computational Linguistics , volume=. 2014 , publisher=
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.