Beyond Function Calling: Benchmarking Tool-Using Agents under Tool-Environment Unreliability
Pith reviewed 2026-06-30 09:52 UTC · model grok-4.3
The pith
Agents that succeed with reliable tools often fail when those tools include recoverable hazards, mainly from poor diagnosis and recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
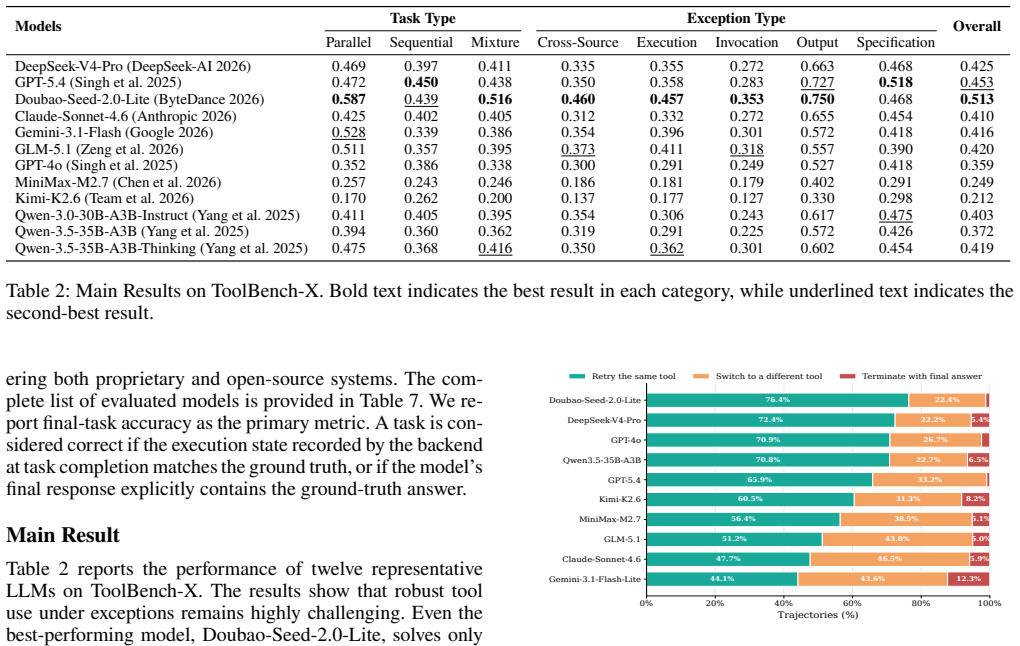
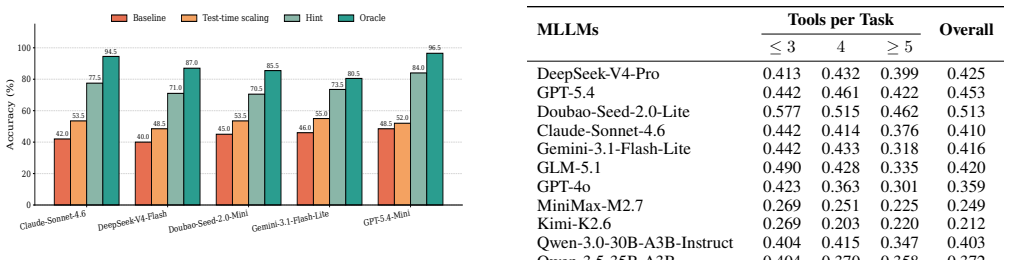
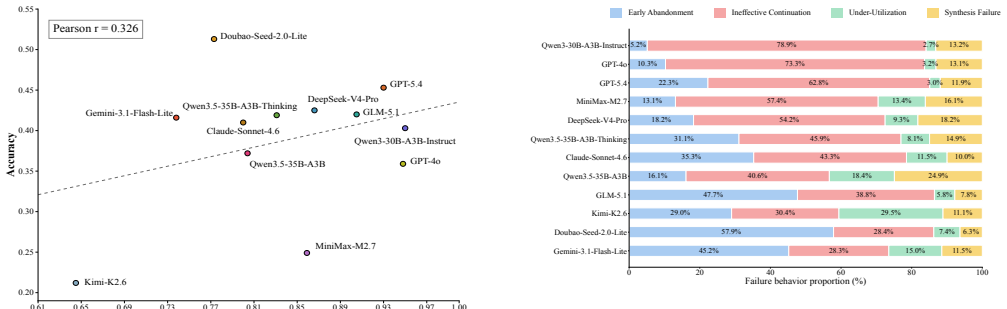
Starting from clean tool environments, ToolBench-X injects five structured hazard types—Specification Drift, Invocation Error, Execution Failure, Output Drift, and Cross-source Conflict—each remaining solvable through at least one valid recovery path such as retrying, fallback, verification, or cross-checking. Experiments reveal a substantial reliability gap: agents that perform well with reliable tools often fail under recoverable hazards. Further analysis shows that failures are driven less by tool-use volume or inference budget than by limited hazard diagnosis and ineffective recovery. Targeted recovery hints recover many failed tasks, while test-time scaling yields more limited gains.
What carries the argument
ToolBench-X benchmark that pairs executable multi-step tasks across domains and workflows with deterministic tools, then injects five hazard types while guaranteeing each instance has at least one valid recovery path for automatic evaluation.
If this is right
- Targeted recovery hints recover many failed tasks that agents otherwise leave unsolved.
- Test-time scaling produces smaller gains than direct recovery support under hazards.
- Tool-use evaluation needs to shift focus from function-call accuracy to full task completion under unreliable conditions.
- Hazard diagnosis ability matters more for success than raw tool-call volume or inference budget.
Where Pith is reading between the lines
- Agents may need explicit training on hazard detection and recovery sequences rather than only on clean tool use.
- Real deployments could require built-in verification layers that the current benchmark does not test.
- Extending the benchmark to include unrecoverable hazards would reveal whether the observed gap widens further.
Load-bearing premise
The five hazard types and their injection method adequately represent real-world tool unreliability while keeping each instance solvable via at least one valid recovery path.
What would settle it
A run of current top agents on ToolBench-X that shows no drop in task completion rate relative to clean-tool versions, or where adding recovery hints produces no measurable improvement.
Figures


read the original abstract
Large language models are increasingly deployed as agents that solve tasks by interacting with external tool environments. Although recent tool-use benchmarks increasingly cover complex task settings, they still largely assume clean, stable, and trustworthy tool environments, leaving tool-environment unreliability insufficiently examined. We introduce ToolBench-X, a benchmark for evaluating agents under recoverable reliability hazards. ToolBench-X contains executable multi-step tasks across diverse domains and sequential, parallel, and mixed workflows, each paired with deterministic tools and a canonical final answer for automatic evaluation. Starting from clean tool environments, ToolBench-X injects five structured hazard types: Specification Drift, Invocation Error, Execution Failure, Output Drift, and Cross-source Conflict. Crucially, each injected instance remains solvable through at least one valid recovery path, such as retrying, fallback, verification, or cross-checking. Experiments reveal a substantial reliability gap: agents that perform well with reliable tools often fail under recoverable hazards. Further analysis shows that failures are driven less by tool-use volume or inference budget than by limited hazard diagnosis and ineffective recovery. Targeted recovery hints recover many failed tasks, while test-time scaling yields more limited gains. These results suggest that tool-use evaluation should move beyond function-call accuracy toward task completion under unreliable tool environments. The code and data is available at https://github.com/Foreverskyou/ToolBench-X.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ToolBench-X, a benchmark extending tool-use evaluation to unreliable tool environments. It defines five recoverable hazard types (Specification Drift, Invocation Error, Execution Failure, Output Drift, Cross-source Conflict) injected into multi-step tasks with sequential, parallel, and mixed workflows. Each task has deterministic tools and a canonical answer. Experiments show agents succeeding on clean tools fail substantially under hazards, with failures attributed primarily to poor hazard diagnosis and recovery rather than tool-use volume or inference budget; recovery hints improve performance more than test-time scaling. The work concludes that tool-use benchmarks should prioritize task completion under unreliability and releases code and data.
Significance. If the central empirical claims hold, the benchmark provides a valuable stress test for agent robustness in realistic settings where tool environments are noisy. The public code and data at the GitHub link are a clear strength for reproducibility. The distinction between volume/budget limits and diagnosis/recovery failures, if substantiated, offers actionable guidance for agent design beyond current function-calling metrics.
major comments (2)
- [Benchmark construction (abstract and §3)] Benchmark construction (abstract and §3): The claim that 'each injected instance remains solvable through at least one valid recovery path' is load-bearing for interpreting the reliability gap as agent limitations rather than unsolvable instances. No explicit verification procedure is described for parallel or mixed workflows under Specification Drift, Output Drift, or Cross-source Conflict, where drift or unresolved conflicts could eliminate all paths to the canonical answer. This directly affects the validity of the diagnosis/recovery attribution.
- [Experimental setup (§4)] Experimental setup (§4): The abstract and results attribute failures to 'limited hazard diagnosis and ineffective recovery' rather than volume or budget, yet the manuscript provides insufficient detail on the exact agent selection criteria, hazard injection implementation, automatic evaluation metrics, and statistical controls (e.g., variance across runs or hazard severity). Without these, the gap size and causal attribution lack verifiable support.
minor comments (3)
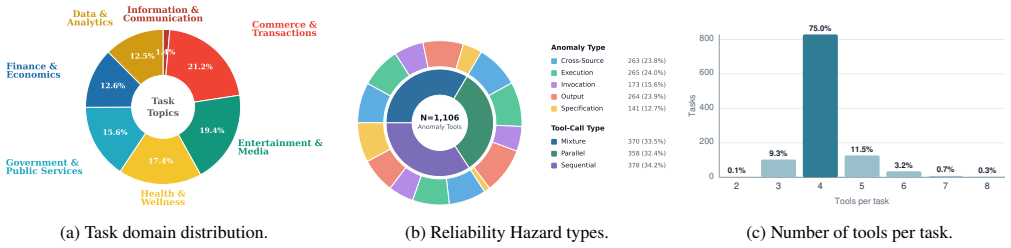
- [Results figures/tables] Table or figure captions should explicitly state the number of tasks per workflow type and per hazard to allow readers to assess coverage.
- [§2 or §3] Notation for the five hazard types is introduced without a compact summary table; adding one would improve readability when comparing recovery strategies.
- [Abstract and conclusion] The GitHub link is given, but the manuscript should include a brief statement on which components (task definitions, hazard injectors, evaluation scripts) are released to support the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to provide the requested clarifications and additional details.
read point-by-point responses
-
Referee: [Benchmark construction (abstract and §3)] The claim that 'each injected instance remains solvable through at least one valid recovery path' is load-bearing for interpreting the reliability gap as agent limitations rather than unsolvable instances. No explicit verification procedure is described for parallel or mixed workflows under Specification Drift, Output Drift, or Cross-source Conflict, where drift or unresolved conflicts could eliminate all paths to the canonical answer. This directly affects the validity of the diagnosis/recovery attribution.
Authors: We agree that an explicit verification procedure should have been described. In the revised manuscript we will add a dedicated subsection to §3 that details the verification process: for every hazard type and workflow variant (including parallel and mixed), we enumerate recovery strategies (retry, fallback, cross-check), run automated simulation to confirm at least one path reaches the canonical answer, and perform targeted manual inspection on a sample of parallel/mixed cases under Specification Drift, Output Drift, and Cross-source Conflict. Concrete examples of verified recovery paths will be included. revision: yes
-
Referee: [Experimental setup (§4)] The abstract and results attribute failures to 'limited hazard diagnosis and ineffective recovery' rather than volume or budget, yet the manuscript provides insufficient detail on the exact agent selection criteria, hazard injection implementation, automatic evaluation metrics, and statistical controls (e.g., variance across runs or hazard severity). Without these, the gap size and causal attribution lack verifiable support.
Authors: We acknowledge that the current §4 lacks sufficient implementation detail. In the revision we will expand this section to specify: (i) exact agent selection criteria and prompting configurations, (ii) hazard injection code-level details and parameters for each workflow type, (iii) the complete automatic evaluation protocol (including canonical-answer matching rules), and (iv) statistical controls such as run-to-run variance, hazard-severity ablations, and explicit budget-vs-diagnosis comparisons. These additions will make the reported gaps and attributions reproducible and verifiable. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or fitted predictions
full rationale
The paper introduces ToolBench-X as an empirical benchmark for agent reliability under injected hazards, with all claims grounded in experimental results rather than any mathematical derivation chain. No equations, parameters fitted to subsets, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The design choice that each hazard instance has at least one recovery path is an explicit benchmark assumption (not derived from or equivalent to the reported outcomes), and the public code allows external verification. This is a standard non-circular empirical study; the central reliability-gap claim rests on observed agent performance differences, not on quantities defined by the authors' own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks can be designed with deterministic tools and canonical final answers for automatic evaluation even after hazard injection
invented entities (1)
-
Specification Drift, Invocation Error, Execution Failure, Output Drift, Cross-source Conflict
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agentnoisebench: Benchmarking robustness of tool- using llm agents under noisy condition.arXiv preprint arXiv:2602.11348. Xi,Z.;Liang,S.;Liu,Q.;Zhang,J.;Peng,L.;Nan,F.;Nayim, M.; Zhang, T.; Mundada, R.; Qin, L.; et al. 2026. ToolGym: an Open-world Tool-using Environment for Scalable Agent TestingandDataCuration.arXivpreprintarXiv:2601.06328. Yang,A.;Li,A....
-
[2]
Generate exactly one function for each name in ‘tools_used‘
-
[3]
Do not add unrelated functions, classes, or helpers
Function names must exactly match the requested tool names. Do not add unrelated functions, classes, or helpers
-
[4]
Use Python 3.9-compatible syntax and ensure that all outputs are deterministic and JSON-serializable
-
[5]
Respect the specified ‘sequential‘, ‘parallel‘, or ‘mixture‘ workflow and maintain compatible data contracts across tools
-
[6]
Derive outputs from function inputs and handle unseen but valid inputs through general logic and deterministic fallbacks
-
[7]
Preserve a guarded benchmark-context path that reproduces the benchmark answer exactly without forcing that answer for unrelated inputs
-
[8]
When external information is required, prefer public no-key sources and provide deterministic fallback behavior
-
[9]
Include provenance, confidence, evidence, fallback, and error information where applicable
-
[10]
Ensure that each downstream required parameter can be obtained from an upstream output or the original user request. [... omitted: standardized return schemas, robust input normalization, benchmark-context detection, external-data policies, inter-tool contracts, canonicalization rules, and validation checks ...] # Output Requirements Return Python code on...
-
[11]
Fix only the failing parts
-
[12]
Preserve function names and signatures unless required for correctness
-
[13]
Table 12: Prompt for hazard injection and hint generation
Return corrected Python code only. Table 12: Prompt for hazard injection and hint generation. # Role You are a Reliability Stress-Test Prompt Engineer for agent-tool evaluation. # Mission Patch an existing successful Python module in place by adding deterministic reliability hazards. Preserve its function names, signatures, schemas, and original behavior ...
-
[14]
When injection is disabled, the patched module must preserve its original benchmark-correct behavior and output schema
-
[15]
‘strict_no_hint_profile‘ must introduce an observable and meaningful failure or behavior drift
-
[16]
‘guided_with_hint_profile‘ must retain the same fault schedule and may provide diagnostic information about the observed failure to support recovery, without revealing the final answer
-
[17]
# Hazard Categories Assign exactly one category to each task: Specification, Invocation, Execution, Output, or Cross-Source Uncertainty
At least one reachable and verifiable path to the correct answer must remain available. # Hazard Categories Assign exactly one category to each task: Specification, Invocation, Execution, Output, or Cross-Source Uncertainty. All failpoints and hints within the task must use this category. # Core Requirements
-
[18]
Select failpoints deterministically using task identity, tool name, call slot, failpoint, and ‘FAIL_SEED‘
-
[19]
Record observable injection events without overwriting the original business payload
-
[20]
Do not silently swallow exceptions or represent hard failures as successful results
-
[21]
Block premature completion when evidence is incomplete or contradictory, and require final-answer canonicalization before ‘FINISH‘
-
[22]
task_type
Keep the injected fault schedule reproducible across no-hint and with-hint conditions to support controlled comparison. [... omitted: activation schemas, failure families, event contracts, recovery rules, and anti-regression checks ...] # Runtime Input { "task_type": "<workflow type>", "id": "<task id>", "user_prompt": "<user request>", "tools_used": ["<t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.