TriViewBench: Controlled Complexity Scaling for Multi-View Structural Reasoning in MLLMs
Pith reviewed 2026-06-25 19:18 UTC · model grok-4.3
The pith
All 18 MLLMs follow the same task hierarchy and degrade sharply on multi-view global recovery as scene complexity increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
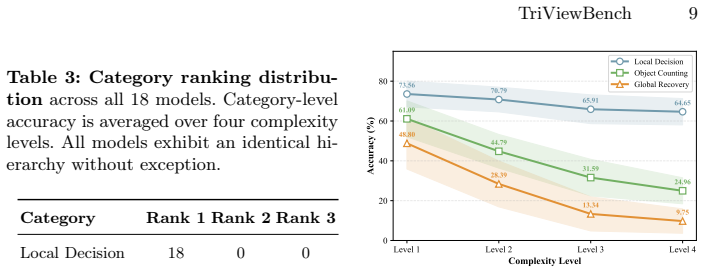
All 18 models exhibit an identical capability hierarchy without exception (Local Decision > Object Counting > Global Recovery), performance degrades monotonically with complexity, and Chain-of-Thought prompting yields near-zero overall benefit, suggesting the bottleneck lies in cross-view spatial representation rather than reasoning strategy.
What carries the argument
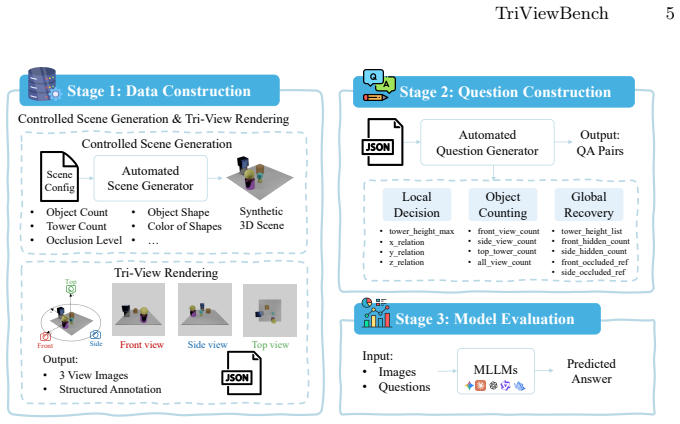
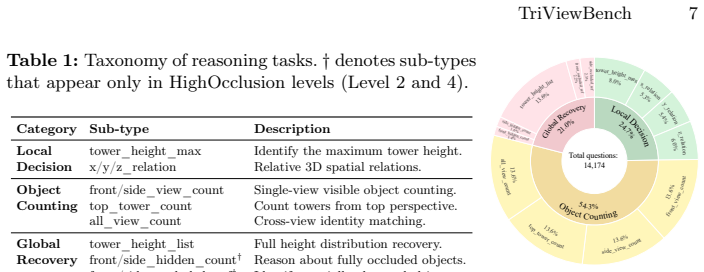
TriViewBench, a benchmark of 1,923 synthetic 3D scenes and over 14K QA pairs organized into four complexity levels and three reasoning categories: Local Decision, Object Counting, and Global Recovery.
If this is right
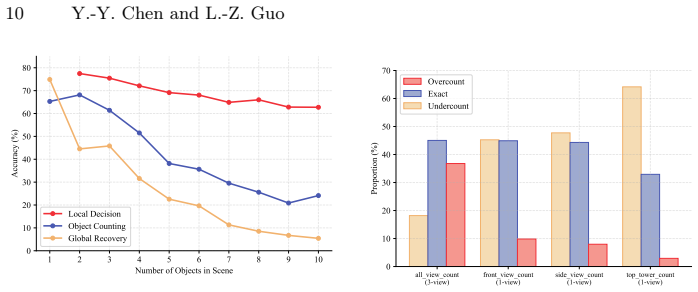
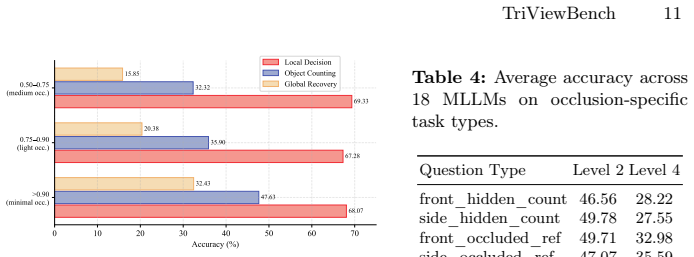
- Local Decision tasks decline only modestly with complexity while Object Counting drops 59 percent and Global Recovery drops 80 percent.
- Single-view counting fails mainly through undercounting from occlusion, whereas the multi-view version fails through overcounting from identity confusion across views.
- Chain-of-thought prompting has negligible overall effect and its small benefit on global tasks appears only for stronger base models.
Where Pith is reading between the lines
- If the hierarchy is universal, then simply increasing model scale is unlikely to resolve multi-view spatial failures without changes to how views are integrated.
- Applications that need 3D scene understanding from multiple images, such as navigation or inspection, would inherit the same counting and recovery limits observed here.
- Extending the benchmark to real photographs or adding temporal views could test whether the same failure modes and ordering persist outside synthetic scenes.
Load-bearing premise
Synthetic 3D scenes with explicit control over object count and occlusion, together with a unified prompting protocol, produce measurements that generalize to real-world multi-view structural reasoning in MLLMs.
What would settle it
Finding even one model that ranks the three task categories in a different order or shows large gains from chain-of-thought prompting on global recovery tasks would falsify the universal hierarchy and bottleneck claim.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) demonstrate strong performance on standard visual question answering benchmarks, yet their scalability under controlled structural complexity remains poorly understood. We introduce TriViewBench, a controlled three-view visual reasoning benchmark constructed from synthetic 3D scenes with explicitly parameterized object count and occlusion. The benchmark contains 1,923 scenes and over 14K Question-Answer (QA) pairs organized into four complexity levels and three reasoning categories: Local Decision, Object Counting, and Global Recovery. We evaluate 18 open- and closed-source MLLMs under a unified prompting protocol. All 18 models exhibit an identical capability hierarchy without exception (Local Decision > Object Counting > Global Recovery), and performance degrades monotonically with complexity: Local Decision tasks decline modestly (12.11% relative drop), while Object Counting degrades substantially (59.14%) and Global Recovery collapses severely (80.02%). Error analysis on Object Counting reveals two mechanistically independent failure modes: single-view tasks are dominated by undercounting due to occlusion blindness, whereas the multi-view task reverses to overcounting due to cross-view identity confusion. Chain-of-Thought (CoT) prompting yields near-zero overall benefit ($\Delta = -0.16\%$) and its effect on Global Recovery is strongly capability-gated, suggesting that the bottleneck lies in cross-view spatial representation rather than reasoning strategy. These findings reveal fundamental scalability limitations in current MLLMs and position TriViewBench as a controlled diagnostic framework for analyzing structural reasoning failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TriViewBench, a controlled synthetic three-view benchmark with 1,923 scenes and over 14K QA pairs across four complexity levels and three reasoning categories (Local Decision, Object Counting, Global Recovery). It evaluates 18 MLLMs under a unified prompting protocol, reporting an identical capability hierarchy without exception, monotonic performance degradation with complexity (modest for Local Decision, severe for Global Recovery), two independent error modes in counting (occlusion blindness vs. identity confusion), and near-zero overall benefit from Chain-of-Thought prompting (Δ = -0.16%), concluding that the bottleneck is cross-view spatial representation rather than reasoning strategy.
Significance. If the synthetic results hold and generalize, TriViewBench supplies a reproducible, parameterized diagnostic for isolating structural reasoning failures in MLLMs, with the reported error-mode separation and CoT ineffectiveness offering concrete targets for architectural improvements in multi-view spatial encoding.
major comments (1)
- [Abstract] Abstract: the central claim of 'fundamental scalability limitations in current MLLMs' and the assertion that the bottleneck 'lies in cross-view spatial representation rather than reasoning strategy' rest exclusively on results from the synthetic generation process with explicit object-count and occlusion parameterization. No transfer experiments on real multi-view imagery (variable lighting, texture, non-parametric occlusions) are described, so it remains possible that the observed hierarchy, monotonic degradation, and CoT Δ = -0.16% do not generalize, undermining the scope of the conclusion.
minor comments (2)
- [Abstract] The precise construction details of the four complexity levels and the three reasoning categories (including how occlusion and object count are parameterized) are referenced but not expanded in the provided abstract; a methods subsection or supplementary table would improve reproducibility.
- [Abstract] The abstract states 'all 18 models exhibit an identical capability hierarchy without exception'; if a supplementary table or figure lists per-model scores, it should be cross-referenced here to allow direct verification of the 'without exception' claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the important issue of generalization from our synthetic benchmark. We address the concern directly below and propose a targeted revision to better scope our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'fundamental scalability limitations in current MLLMs' and the assertion that the bottleneck 'lies in cross-view spatial representation rather than reasoning strategy' rest exclusively on results from the synthetic generation process with explicit object-count and occlusion parameterization. No transfer experiments on real multi-view imagery (variable lighting, texture, non-parametric occlusions) are described, so it remains possible that the observed hierarchy, monotonic degradation, and CoT Δ = -0.16% do not generalize, undermining the scope of the conclusion.
Authors: We agree that the manuscript contains no experiments on real multi-view imagery and that this limits the direct generalizability of the quantitative results. TriViewBench was intentionally designed as a fully synthetic, parametrically controlled benchmark precisely to isolate the effects of object count and occlusion—factors that cannot be independently varied in real data without confounding variables. The identical capability hierarchy across all 18 models (including both open- and closed-source) and the separation of the two counting error modes provide internal evidence that the failures are not artifacts of the particular synthetic renderer. Nevertheless, the referee is correct that the abstract's phrasing of 'fundamental scalability limitations in current MLLMs' and the bottleneck conclusion could be read as applying beyond the synthetic regime. We will therefore revise the abstract to qualify the claims as holding 'under controlled synthetic multi-view conditions' and add an explicit limitations paragraph discussing the need for future real-world validation. This is a partial revision: we cannot add new real-image experiments, but we can and will adjust the scope and framing of the conclusions. revision: partial
Circularity Check
No circularity: empirical benchmark evaluation with direct model measurements
full rationale
The paper introduces TriViewBench as a new synthetic dataset with parameterized scenes and reports direct evaluation results across 18 MLLMs under fixed prompting. No equations, fitted parameters, or derived predictions appear; the hierarchy, monotonic degradation, error modes, and CoT Δ = −0.16% are measured outputs, not inputs renamed or self-referentially defined. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the core claims. The work is self-contained against external benchmarks via explicit construction and unified protocol.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic 3D scenes with parameterized object count and occlusion accurately reflect the structural reasoning demands placed on MLLMs in real applications.
Reference graph
Works this paper leans on
-
[1]
Technical document / System card (2025),https://assets.anthropic.com/m/785e231869ea8b3b/original/ claude-3-7-sonnet-system-card.pdf
Anthropic: Claude 3.7 sonnet system card. Technical document / System card (2025),https://assets.anthropic.com/m/785e231869ea8b3b/original/ claude-3-7-sonnet-system-card.pdf
2025
-
[2]
In: ICCV
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: VQA: Visual question answering. In: ICCV. pp. 2425–2433 (2015)
2015
-
[3]
arXiv preprint arXiv:2511.21631 (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-VL technical report. arXiv preprint arXiv:2511.21631 (2025)
Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2502.13923 (2025)
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2507.06261 (2025)
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
Pith/arXiv arXiv 2025
-
[6]
In: ICCV
Daxberger, E., Wenzel, N., Griffiths, D., Gang, H., Lazarow, J., Kohavi, G., Kang, K., Eichner, M., Yang, Y., Dehghan, A., et al.: MM-Spatial: Exploring 3D spatial understanding in multimodal LLMs. In: ICCV. pp. 7395–7408 (2025)
2025
-
[7]
arXiv preprint arXiv:2506.07966 (2025)
Gong, Z., Li, W., Ma, O., Li, S., Wang, Z., Li, S., Ji, J., Yang, X., Luo, G., Yan, J., Ji, R.: SpaCE-10: A comprehensive benchmark for multimodal large language mod- els in compositional spatial intelligence. arXiv preprint arXiv:2506.07966 (2025)
arXiv 2025
-
[8]
In: CVPR
Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y., Duckworth, D., Fleet, D.J., Gnanapragasam, D., Golemo, F., Herrmann, C., et al.: Kubric: A scalable dataset generator. In: CVPR. pp. 3749–3761 (2022)
2022
-
[9]
arXiv preprint arXiv:2510.04401 (2025)
Guo, X., Huang, Z., Shi, Z., Song, Z., Zhang, J.: Your vision-language model can’t even count to 20: Exposing the failures of vlms in compositional counting. arXiv preprint arXiv:2510.04401 (2025)
arXiv 2025
-
[10]
arXiv preprint arXiv:2410.21276 (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al.: GPT-4o system card. arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[11]
Visual Intelligence 3(1), 27 (2025)
Jin, Y., Li, J., Gu, T., Liu, Y., Zhao, B., Lai, J., Gan, Z., Wang, Y., Wang, C., Tan, X., et al.: Efficient multimodal large language models: A survey. Visual Intelligence 3(1), 27 (2025)
2025
-
[12]
In: CVPR
Johnson, J., Hariharan, B., Van Der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., Girshick, R.: CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. In: CVPR. pp. 2901–2910 (2017)
2017
-
[13]
ACM Computing Surveys57(8), 1–36 (2025)
Kuang, J., Shen, Y., Xie, J., Luo, H., Xu, Z., Li, R., Li, Y., Cheng, X., Lin, X., Han, Y.: Natural language understanding and inference with MLLM in visual question answering: A survey. ACM Computing Surveys57(8), 1–36 (2025)
2025
-
[14]
arXiv preprint arXiv:2512.23365 (2025)
Lee, K., Lee, I., Kwak, M., Ryu, K., Hong, J., Park, J.: SpatialMosaic: A multiview VLM dataset for partial visibility. arXiv preprint arXiv:2512.23365 (2025)
Pith/arXiv arXiv 2025
-
[15]
arXiv preprint arXiv:2408.03326 (2024)
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: LLaVA-OneVision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
Pith/arXiv arXiv 2024
-
[16]
arXiv preprint arXiv:2307.16125 (2023) 16 Y.-Y
Li, B., Wang, R., Wang, G., Ge, Y., Ge, Y., Shan, Y.: SEED-Bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125 (2023) 16 Y.-Y. Chen and L.-Z. Guo
Pith/arXiv arXiv 2023
-
[17]
In: CVPR
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: CVPR. pp. 26296–26306 (2024)
2024
-
[18]
NeurIPS36, 34892– 34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. NeurIPS36, 34892– 34916 (2023)
2023
-
[19]
In: ICCV
Ma, W., Chen, H., Zhang, G., Chou, Y.C., Chen, J., de Melo, C., Yuille, A.: 3DSRBench: A comprehensive 3D spatial reasoning benchmark. In: ICCV. pp. 6924–6934 (2025)
2025
-
[20]
In: CVPR
Marino, K., Rastegari, M., Farhadi, A., Mottaghi, R.: OK-VQA: A visual ques- tion answering benchmark requiring external knowledge. In: CVPR. pp. 3195–3204 (2019)
2019
-
[21]
In: CVPR
Mitra, C., Huang, B., Darrell, T., Herzig, R.: Compositional chain-of-thought prompting for large multimodal models. In: CVPR. pp. 14420–14431 (2024)
2024
-
[22]
In: ICCV
Park, S.Y., Cui, C., Ma, Y., Moradipari, A., Gupta, R., Han, K., Wang, Z.: Nu- PlanQA: A large-scale dataset and benchmark for multi-view driving scene under- standing in multi-modal large language models. In: ICCV. pp. 8066–8076 (2025)
2025
-
[23]
arXiv preprint arXiv:2406.09411 (2024)
Wang, F., Fu, X., Huang, J.Y., Li, Z., Liu, Q., Liu, X., Ma, M.D., Xu, N., Zhou, W., Zhang, K., et al.: MuirBench: A comprehensive benchmark for robust multi-image understanding. arXiv preprint arXiv:2406.09411 (2024)
Pith/arXiv arXiv 2024
-
[24]
arXiv preprint arXiv:2508.18265 (2025)
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
Pith/arXiv arXiv 2025
-
[25]
In: CVPR
Wang, X., Ma, W., Zhang, T., de Melo, C.M., Chen, J., Yuille, A.: Spatial457: A diagnostic benchmark for 6D spatial reasoning of large mutimodal models. In: CVPR. pp. 24669–24679 (2025)
2025
-
[26]
NeurIPS35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. NeurIPS35, 24824–24837 (2022)
2022
-
[27]
arXiv preprint arXiv:2505.23764 (2025)
Yang, S., Xu, R., Xie, Y., Yang, S., Li, M., Lin, J., Zhu, C., Chen, X., Duan, H., Yue, X., et al.: MMSI-Bench: A benchmark for multi-image spatial intelligence. arXiv preprint arXiv:2505.23764 (2025)
Pith/arXiv arXiv 2025
-
[28]
arXiv preprint arXiv:2504.15280 (2025)
Yeh, C.H., Wang, C., Tong, S., Cheng, T.Y., Wang, R., Chu, T., Zhai, Y., Chen, Y., Gao, S., Ma, Y.: Seeing from another perspective: Evaluating multi-view un- derstanding in mllms. arXiv preprint arXiv:2504.15280 (2025)
arXiv 2025
-
[29]
National Science Review11(12), nwae403 (2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024)
2024
-
[30]
In: CVPR
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: MMMU: A massive multi-discipline multimodal un- derstanding and reasoning benchmark for expert AGI. In: CVPR. pp. 9556–9567 (2024)
2024
-
[31]
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.: Multimodal chain- of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023) TriViewBench 17 A Per-Model Detailed Results Tables 5 and 6 report per-model accuracy broken down by reasoning category and complexity level under Direct and CoT prompting respectively. LD = Loca...
Pith/arXiv arXiv 2023
-
[32]
Top View
Side View, 3. Top View. You must integrate information from all views to reason about the 3D layout. [Task-Specific Guidance] (see Sec. B.2) [Question] Question: {question} [Output Constraint] Constraint: Directly output the answer inside<answer>tags. No reasoning. Example:<answer>3</answer>or<answer>behind</answer>. CoT Prompt Template [Scene Context, Vi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.