Account-History Features for Social Bot Detection in the Era of Large Language Models
Pith reviewed 2026-06-27 19:13 UTC · model grok-4.3
The pith
Account-history features detect social bots with 0.977 ROC-AUC even when large language models make post text indistinguishable from human writing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
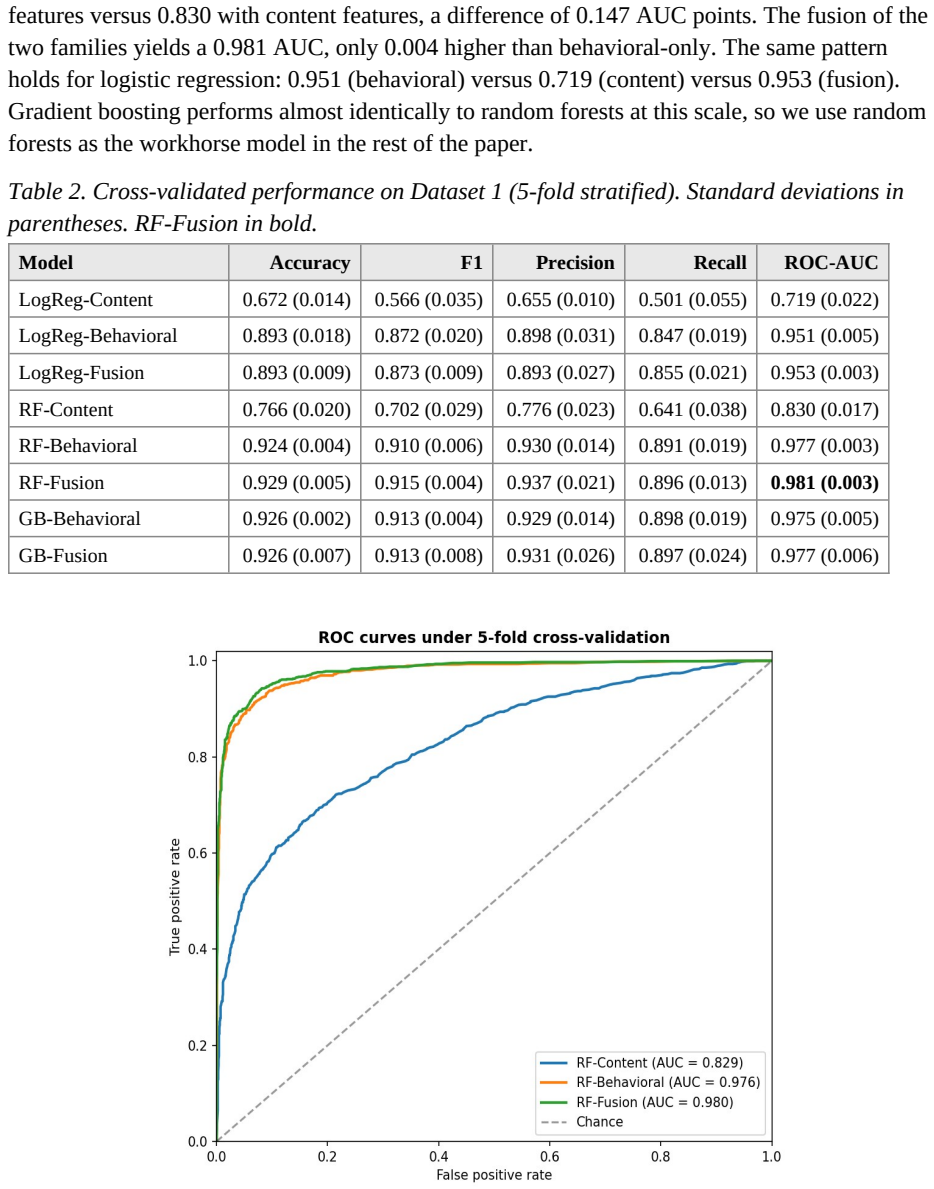
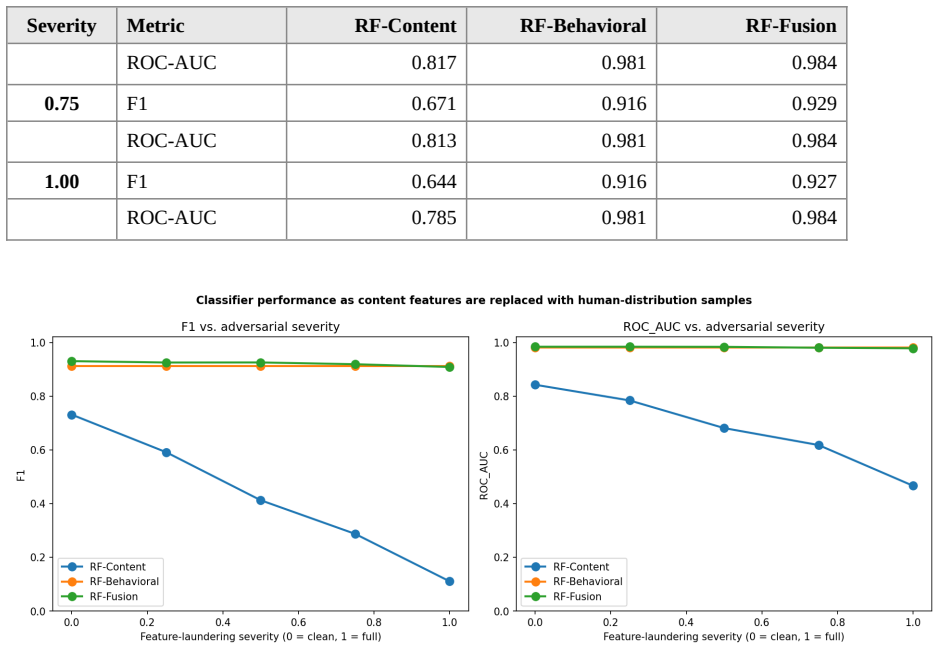
On a publicly redistributed corpus of 2,432 Twitter accounts with manual labels (43 percent bots), a random forest trained exclusively on account-history features achieves ROC-AUC 0.977 in five-fold cross-validation. A content-only baseline reaches only 0.830 and falls to 0.785 after surface-statistic rewriting of bot text or to 0.466 after direct feature perturbation toward the human distribution, while the history model remains essentially unchanged. The behavioral-versus-content performance gap is statistically significant by DeLong's test, and the pattern replicates qualitatively on a 100-account sample from TwiBot-20.
What carries the argument
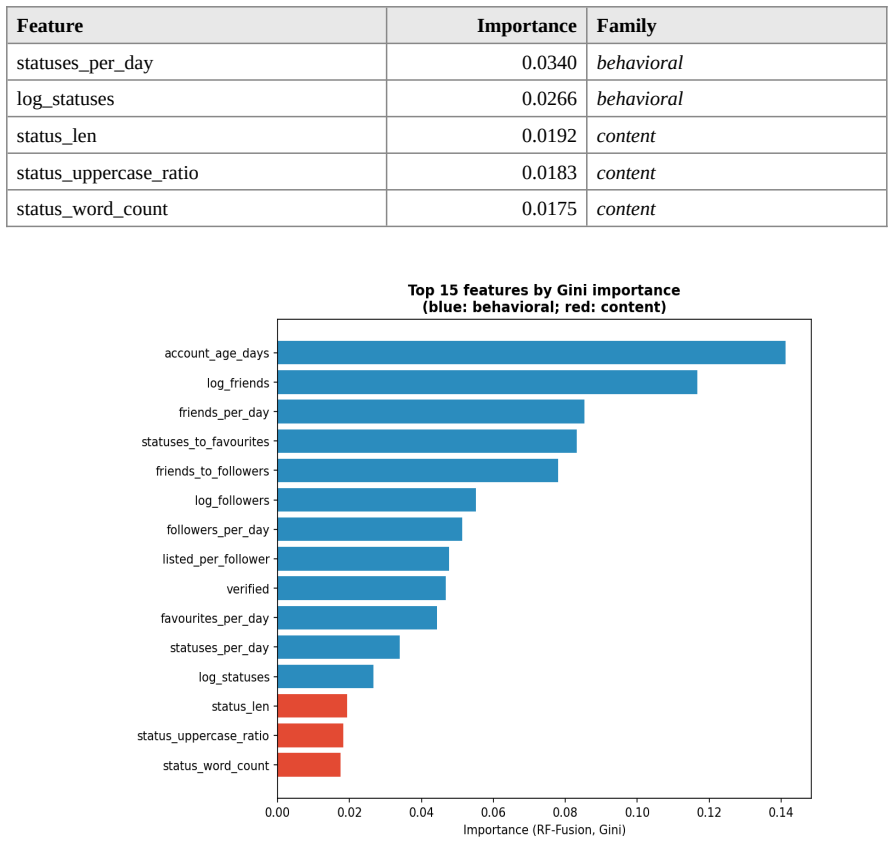
The account-history feature set consisting of account age, follower and friend counts together with their ratios, profile completeness, and structural properties of the handle, which serve as the primary predictive signal.
If this is right
- Operational bot detection can place primary weight on account-history features rather than post content.
- Adversarial rewriting of bot text to match human surface statistics degrades content classifiers while leaving behavioral performance invariant.
- Direct perturbation of content feature values toward the human distribution drives content classifiers below chance level while behavioral performance stays stable.
- The relative advantage of history features holds on an independent sample drawn from TwiBot-20.
- Content features should not be treated as the main signal in deployed systems.
Where Pith is reading between the lines
- Platforms that make account registration metadata harder to fabricate would further strengthen this detection approach.
- The same emphasis on registration history could be tested on other social platforms where account creation records are available.
- Attackers facing these features may need to purchase or rent established accounts, which raises their operational costs.
- Combining history features with platform-level signals such as login patterns could be examined as a next extension.
Load-bearing premise
An attacker cannot cheaply acquire aged accounts or inflate follower and friend counts at scale.
What would settle it
A collection of bot accounts whose histories have been aged and whose follower ratios have been raised to human-typical values, yet which the history-based classifier still labels as bots at rates no better than chance, would falsify the central claim.
Figures


read the original abstract
Bot detection on social platforms has historically relied on a mix of account-metadata features and features extracted from the text of posts and profile fields. The arrival of capable language models complicates the latter. A bot operator can run every post through GPT-4 or Claude and produce text whose surface statistics are difficult to distinguish from those of human writing, which weakens the predictive value of content-derived features. This paper asks how much of the detection problem can be solved by features that an attacker cannot easily manipulate at low cost: the age of the account, follower and friend counts and their ratios, profile completeness, and the structural properties of the handle. On a publicly redistributed corpus of 2,432 Twitter accounts with manually verified labels (43.0% bots), a random forest using only these account-history features achieves ROC-AUC of 0.977 in five-fold cross-validation, against 0.830 for a content-only baseline and 0.981 for the fusion model. The behavioral-versus-content gap is large and statistically significant by DeLong's test (z = 9.36, p < 0.001). We then evaluate two adversarial settings. In the first, we rewrite the text of bot tweets to match human surface statistics for URLs, hashtags, mentions, and casing; the content classifier's ROC-AUC degrades from 0.842 to 0.785 while the behavioral classifier is essentially unchanged. In the second, more aggressive setting we directly perturb the content feature values toward the human distribution; the content classifier falls below chance (AUC 0.466) while behavioral performance is invariant. We replicate the score distribution qualitatively on a 100-account sample of TwiBot-20. We conclude that operational bot detection should not treat content features as the primary signal; account-history features carry most of the load already and are not eroded by adversarial text rewriting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that account-history features (account age, follower/friend counts and ratios, profile completeness, handle structure) provide robust bot detection on Twitter even when content features are attacked by LLMs. On 2,432 manually labeled accounts (43% bots), a random forest using only these features reaches 0.977 ROC-AUC in 5-fold CV (vs. 0.830 content-only, 0.981 fusion); DeLong test confirms significance (z=9.36). Two content-adversarial protocols are evaluated: surface-statistic rewriting drops content AUC modestly while behavioral is unchanged; direct perturbation of content features drops content below chance (0.466) while behavioral remains invariant. The conclusion is that operational systems should prioritize account-history features.
Significance. If the central premise holds, the work supplies a clear empirical case, backed by held-out CV, DeLong testing, and two distinct adversarial protocols, for shifting emphasis from content to behavioral signals in the LLM era. The invariance result under content attack is a concrete, falsifiable contribution.
major comments (3)
- [Abstract and Introduction] Abstract, first paragraph, and Introduction: the claim that account age, follower/friend counts/ratios, profile completeness, and handle structure 'cannot easily manipulate at low cost' is presented as the reason these features remain reliable, yet the manuscript contains no experiments, black-market price data, citations, or sensitivity analysis quantifying manipulation cost or feasibility. This premise is load-bearing for the operational recommendation and for interpreting the 0.977 AUC gap as robust rather than dataset-specific.
- [Adversarial evaluation] Adversarial evaluation (the two protocols described after the main results): both settings only perturb content-derived features; no parallel protocol perturbs or substitutes account-history features (e.g., simulating acquisition of aged accounts with realistic follower ratios). Consequently the invariance claim is demonstrated only for the secondary feature set.
- [Results and replication] Results and replication paragraph: the qualitative replication on the 100-account TwiBot-20 sample is reported only for score distributions; no quantitative AUC, DeLong test, or adversarial results are supplied for this second corpus, weakening the generalizability statement.
minor comments (2)
- [Feature definitions] Feature definitions (account-history section): the exact computation of 'handle structure' and 'profile completeness' is not given in sufficient detail for replication; a table listing each feature and its formula would improve clarity.
- [Tables and figures] Table/figure captions: several captions do not state the exact number of accounts or the cross-validation scheme used for the reported AUC values.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of scope and evidence that we address point by point below, with planned revisions indicated.
read point-by-point responses
-
Referee: [Abstract and Introduction] Abstract, first paragraph, and Introduction: the claim that account age, follower/friend counts/ratios, profile completeness, and handle structure 'cannot easily manipulate at low cost' is presented as the reason these features remain reliable, yet the manuscript contains no experiments, black-market price data, citations, or sensitivity analysis quantifying manipulation cost or feasibility. This premise is load-bearing for the operational recommendation and for interpreting the 0.977 AUC gap as robust rather than dataset-specific.
Authors: We agree that explicit support for the manipulation-cost premise would strengthen the manuscript. The claim rests on the inherent time and activity requirements for realistic account metadata, but the current version lacks supporting citations. In revision we will add references from the bot-detection literature on account acquisition and trading markets, plus a concise discussion of practical barriers, to better ground the operational recommendation. revision: partial
-
Referee: [Adversarial evaluation] Adversarial evaluation (the two protocols described after the main results): both settings only perturb content-derived features; no parallel protocol perturbs or substitutes account-history features (e.g., simulating acquisition of aged accounts with realistic follower ratios). Consequently the invariance claim is demonstrated only for the secondary feature set.
Authors: The protocols were constructed to evaluate the specific threat posed by LLMs to content features. A symmetric attack on account-history features would require modeling real-world account trading or aging, which cannot be performed with the existing corpus and would constitute a separate study. We will revise the discussion to explicitly acknowledge this asymmetry and clarify that the demonstrated invariance applies under content attacks, thereby supporting prioritization of behavioral signals. revision: partial
-
Referee: [Results and replication] Results and replication paragraph: the qualitative replication on the 100-account TwiBot-20 sample is reported only for score distributions; no quantitative AUC, DeLong test, or adversarial results are supplied for this second corpus, weakening the generalizability statement.
Authors: The TwiBot-20 sample was included solely as a qualitative check on score-distribution similarity. With only 100 accounts, quantitative metrics such as AUC or DeLong tests would lack statistical reliability. We will revise the text to frame the replication more precisely as qualitative and to moderate the generalizability claim. revision: partial
Circularity Check
No circularity: empirical CV metrics are independent of inputs
full rationale
The paper reports ROC-AUC values (0.977 behavioral, 0.830 content, 0.981 fusion) obtained via five-fold cross-validation on a fixed labeled corpus of 2,432 accounts. These are direct empirical measurements of classifier performance on held-out data; no equation, parameter fit, or self-citation reduces the reported numbers to the input features by construction. The central premise that account-history features are hard to manipulate is presented as an assumption without supporting experiments or citations, but this constitutes an evidentiary limitation rather than a circular derivation. No self-definitional loops, fitted-input predictions, or uniqueness theorems appear in the manuscript.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Manually verified labels constitute accurate ground truth.
- domain assumption The 2,432-account corpus is representative of the broader Twitter population.
Reference graph
Works this paper leans on
-
[1]
Approximate statistical tests for comparing supervised classification learning algorithms
"Approximate statistical tests for comparing supervised classification learning algorithms." Neural Computation 10 (7): 1895-1923. Feng, S., H. Wan, N. Wang, J. Li, and M. Luo
1923
-
[2]
FATe of bots: Ethical considerations of social bot detection
"FATe of bots: Ethical considerations of social bot detection." ACM Journal on Responsible Computing. The author thanks the maintainers of the Cresci-2017 bot repository, the TwiBot-20 sample, and the publicly redistributed Twitter Bot Accounts corpus for their continued investment in open benchmarks. Kulal, D. H., C. P. Arannonu, A. Anwar, N. Rastogi, an...
2017
-
[3]
"Robust ML-based detection of conventional, LLM-generated, and adversarial phishing emails using advanced text preprocessing." arXiv:2510.11915. Lin, Q., J. Zhou, N. Ferro, M. Maistro, G. Pasi, O. Alonso, A. Trotman, and S. Verberne
-
[4]
Social media bot detection research: Review of literature
"Social media bot detection research: Review of literature." arXiv:2503.22838. Stringhini, G., C. Kruegel, and G. Vigna
-
[5]
MultiPhishGuard: An LLM-based multi-agent system for phishing email detection
"MultiPhishGuard: An LLM-based multi-agent system for phishing email detection." arXiv:2505.23803. Yang, K.-C., E. Ferrara, and F. Menczer
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.