Thinking Like a Scientist? A Structural Study of LLM-Generated Research Methods
Pith reviewed 2026-06-27 04:05 UTC · model grok-4.3
The pith
LLMs prompted only with a research question suggest a narrower set of methods than those appearing in the original papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
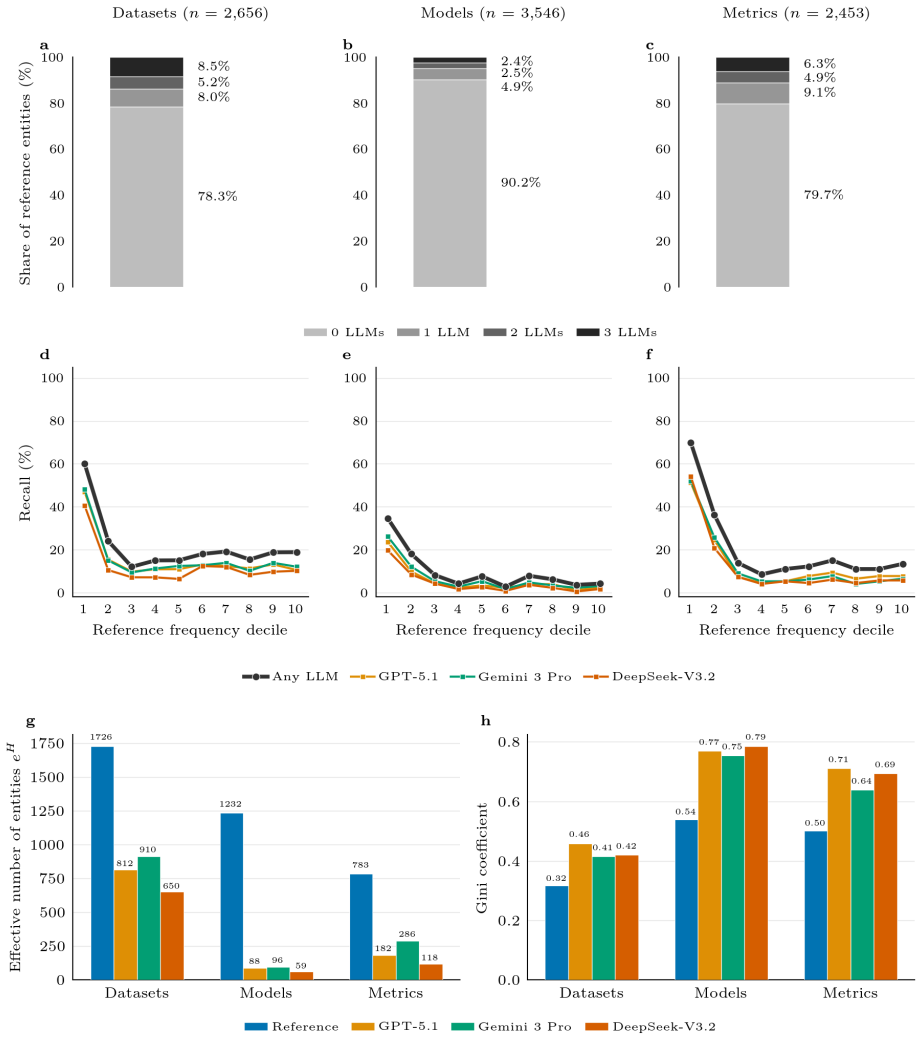
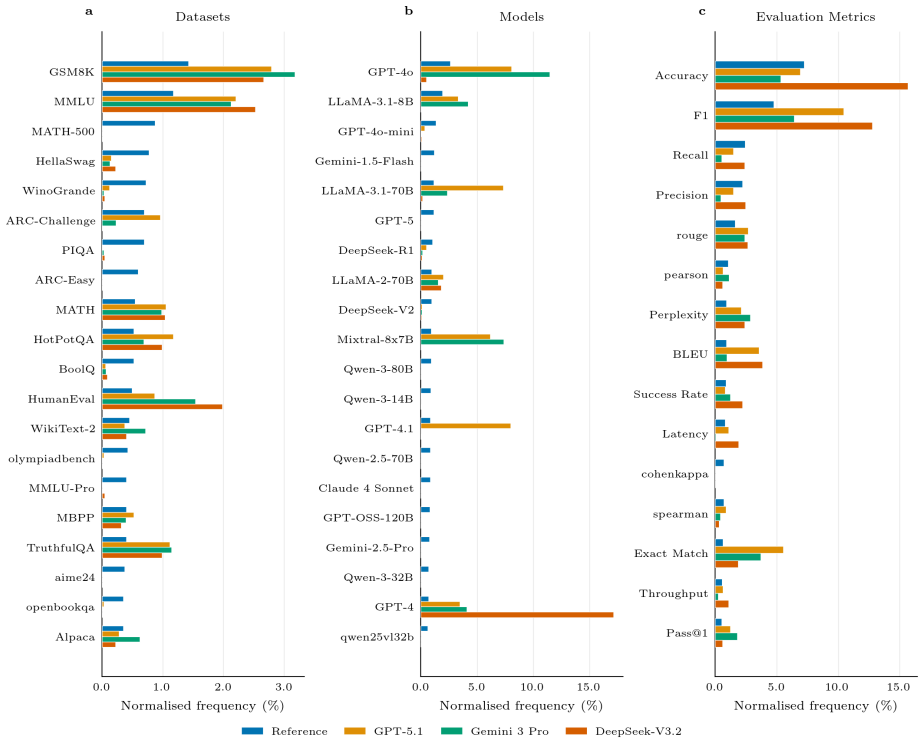
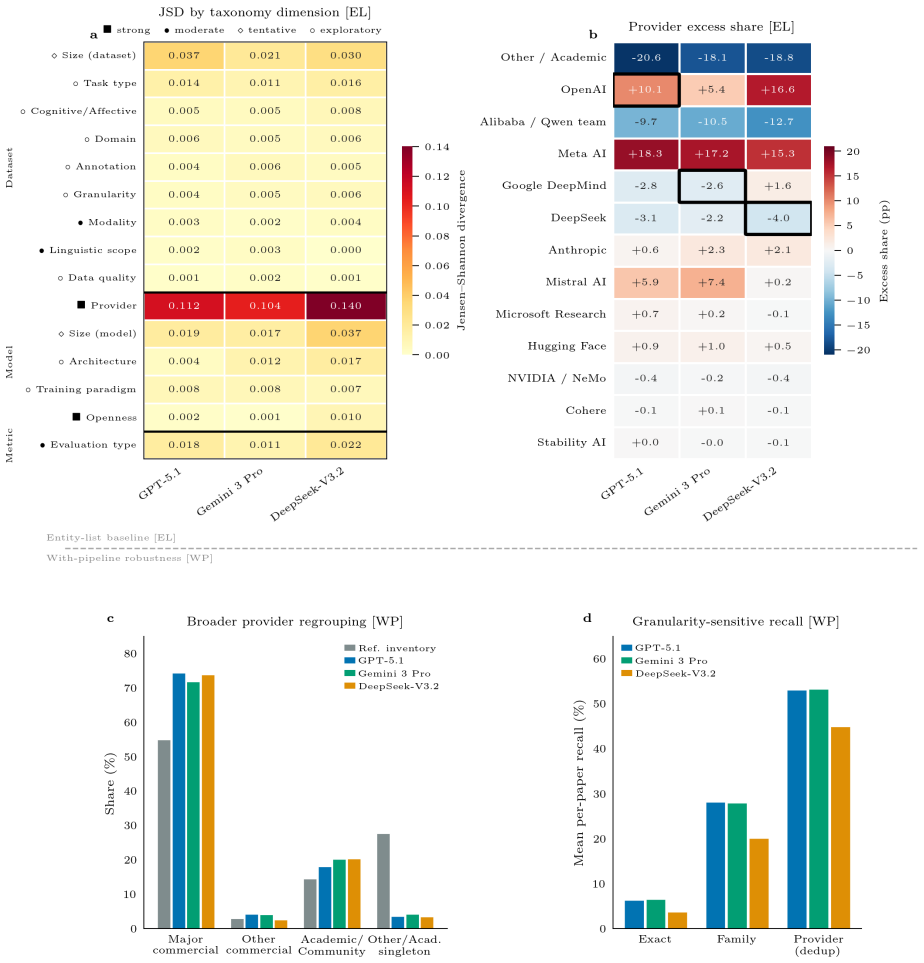
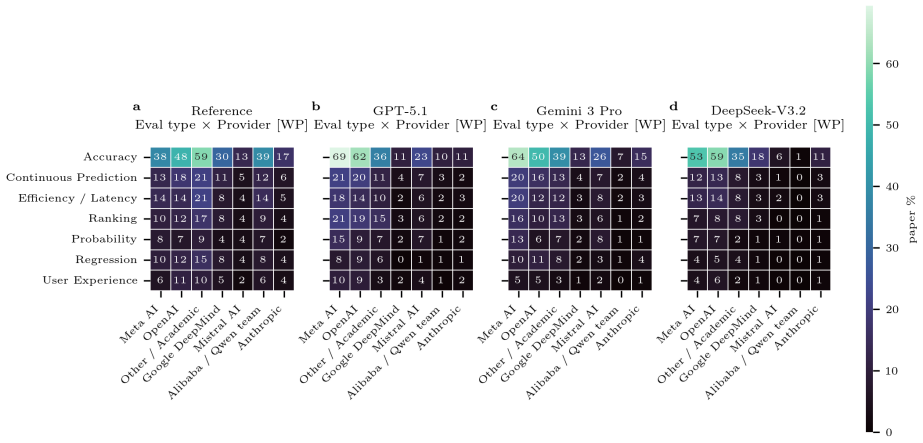
When supplied only with an extracted research question, GPT-5.1, Gemini 3 Pro, and DeepSeek-V3.2 each return methodology suggestions whose distribution across a shared taxonomy is markedly more concentrated than the distribution of methods actually employed in the source papers. The contraction is most pronounced in the model-provider dimension, where single-occurrence academic or other models drop by 23-24 percentage points while a handful of reused models rise slightly; the effective number of model entities falls from 1,232 in the papers to between 59 and 96 in the LLM outputs. Rank correlations among the three LLM distributions (0.55-0.68) exceed correlations between any LLM and the pape
What carries the argument
A shared taxonomy that encodes method features from both papers and LLM outputs, together with Jensen-Shannon divergence measured across taxonomy dimensions such as model provider, task type, and metric type.
If this is right
- The set of reusable academic or community models receives a modest over-representation of 4-6 percentage points.
- The effective count of distinct model entities contracts from 1,232 in the papers to 59-96 across the LLM outputs.
- Inter-LLM rank correlations remain higher than LLM-to-paper correlations on every taxonomy dimension examined.
- Popularity baselines and paper-similarity controls indicate the outputs are query-specific yet still filtered through a narrower option set.
- Unchecked use of the suggestions therefore steers the methodological search space toward a more concentrated default.
Where Pith is reading between the lines
- If the narrowing persists across successive rounds of prompting, research programs that begin with LLM assistance may converge faster than those begun from direct literature search.
- The same taxonomy-mapping approach could be applied to other research stages such as evaluation design or dataset selection to test whether compression appears elsewhere.
- A practical test would be to measure whether papers that cite LLM-generated methods show lower method diversity than matched papers that do not.
- Prompt engineering that explicitly requests rare or single-occurrence models might offset the observed compression, but that remains outside the minimal-prompting regime studied here.
Load-bearing premise
Extracting research questions from papers and mapping both paper methods and LLM suggestions into one common taxonomy keeps the important distinctions intact without adding systematic bias.
What would settle it
A recount of the same 1,000 papers showing that the LLM suggestions reproduce the full spread of model entities and provider choices present in the original work would falsify the narrowing claim.
Figures

read the original abstract
Large Language Models (LLMs) are increasingly used to guide research methodology, yet their default methodological tendencies under minimal prompting remain unclear. Here, we prompt GPT-5.1, Gemini 3 Pro, and DeepSeek-V3.2 with an LLM-extracted research question from each of 1,000 recent arXiv computer-science papers and compare the resulting methodology suggestions against a paper-derived experimental inventory. Since we provide only the research question, the differences we measure reflect initial suggestions and not how optimal those suggestions are. We extract structured method features from both sources, map them into a shared taxonomy, and quantify divergence across multiple taxonomy dimensions including model provider, dataset task type, and evaluation metric type. The strongest imbalance appears in provider choice, with Jensen-Shannon divergence about 3-5x larger than any other taxonomy dimension. Other/Academic single-occurrence models are underrepresented by 23-24 percentage points, while reused academic/community models are slightly overrepresented (4-6pp). LLMs also suggest a much narrower range of methods overall: the effective number of model entities contracts from 1,232 to 59-96, and inter-LLM rank correlations (0.55-0.68) generally exceed LLM-to-paper correlations (0.33-0.56), so the distortions are largely shared across models. Popularity baselines, BM25 retrieval calibration, and paper-level similarity tests confirm that the outputs are query-specific responses, but filtered through a narrower set of options. Researchers who rely on LLM suggestions without cross-checking therefore risk narrowing their methodological search space toward a more concentrated default.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes methodological suggestions from three LLMs (GPT-5.1, Gemini 3 Pro, DeepSeek-V3.2) prompted solely with research questions extracted from 1,000 recent arXiv CS papers. It extracts structured method features from both the original papers and LLM outputs, maps them into a shared taxonomy, and quantifies differences via Jensen-Shannon divergences, effective entity counts, and rank correlations across dimensions including model provider, task type, and evaluation metrics. Key results include 3-5x larger divergence on provider choice, 23-24pp underrepresentation of single-occurrence academic models, contraction of effective model entities from 1,232 to 59-96, and higher inter-LLM correlations (0.55-0.68) than LLM-to-paper correlations (0.33-0.56). The authors conclude that unverified LLM use risks narrowing researchers' methodological search space toward a concentrated default.
Significance. If the central measurements hold after validation, the work supplies large-scale, multi-metric evidence (N=1000 papers, three LLMs, multiple taxonomy dimensions) that default LLM suggestions systematically contract methodological diversity relative to published papers, with the strongest effect on model-provider choice. The concrete quantifications (effective-count contraction, JS ratios, correlation gaps) and controls (popularity baselines, BM25, similarity tests) make the narrowing claim falsifiable and practically relevant for AI-assisted research workflows.
major comments (3)
- [Methods / Taxonomy construction and feature extraction] The reported contractions (effective entities 1232 o 59-96), provider imbalances (23-24pp), and dimension-specific JS divergences all depend on the shared taxonomy mapping step described in the abstract and methods. No construction details, category definitions, inter-annotator agreement, or reliability metrics are provided for either the feature extraction or the mapping process, leaving open the possibility that fine-grained or paper-specific methods are collapsed into broader bins (especially “Other/Academic single-occurrence models”).
- [Results / Divergence and effective-entity calculations] The headline claim that LLMs produce a narrower methodological search space rests on the comparison of mapped counts and divergences; if the taxonomy systematically under-resolves single-occurrence methods or over-resolves reused ones, the measured 3-5x provider divergence and effective-count contraction become sensitive to categorization choices rather than intrinsic LLM behavior. A concrete validation (e.g., agreement statistics or sensitivity analysis on binning) is therefore load-bearing for the central result.
- [Data preparation / Research-question extraction] The paper states that research questions are LLM-extracted from the 1,000 papers before prompting, yet supplies no accuracy check, error analysis, or comparison against human-extracted questions; any systematic extraction bias would propagate directly into the subsequent method comparisons and correlation figures.
minor comments (2)
- [Methods] Clarify the exact prompting template and temperature settings used for the three LLMs so that the “minimal prompting” condition can be reproduced.
- [Appendix / Taxonomy] Add a table or appendix listing the top-level taxonomy categories and example mappings for at least the model-provider and evaluation-metric dimensions.
Simulated Author's Rebuttal
We thank the referee for these constructive comments emphasizing methodological transparency and robustness. We address each major point below and will incorporate the requested details and validations into the revised manuscript.
read point-by-point responses
-
Referee: [Methods / Taxonomy construction and feature extraction] The reported contractions (effective entities 1232 o 59-96), provider imbalances (23-24pp), and dimension-specific JS divergences all depend on the shared taxonomy mapping step described in the abstract and methods. No construction details, category definitions, inter-annotator agreement, or reliability metrics are provided for either the feature extraction or the mapping process, leaving open the possibility that fine-grained or paper-specific methods are collapsed into broader bins (especially “Other/Academic single-occurrence models”).
Authors: We agree that the manuscript lacks sufficient detail on taxonomy construction and mapping. The current version provides only a high-level overview. In revision we will add a dedicated subsection describing the iterative development process, explicit definitions for each category (including how single-occurrence items are binned), the mapping rules applied to both paper and LLM outputs, and any reliability metrics (or a post-hoc double-annotation check on a subset of items). revision: yes
-
Referee: [Results / Divergence and effective-entity calculations] The headline claim that LLMs produce a narrower methodological search space rests on the comparison of mapped counts and divergences; if the taxonomy systematically under-resolves single-occurrence methods or over-resolves reused ones, the measured 3-5x provider divergence and effective-count contraction become sensitive to categorization choices rather than intrinsic LLM behavior. A concrete validation (e.g., agreement statistics or sensitivity analysis on binning) is therefore load-bearing for the central result.
Authors: The referee correctly identifies that the headline contraction and divergence results depend on taxonomy choices. We will add a sensitivity analysis that re-computes effective entity counts and JS divergences under alternative binning thresholds for the “Other” and single-occurrence categories, plus the requested agreement statistics. These additions will demonstrate that the reported 3-5x provider effect and overall narrowing are not artifacts of the particular categorization. revision: yes
-
Referee: [Data preparation / Research-question extraction] The paper states that research questions are LLM-extracted from the 1,000 papers before prompting, yet supplies no accuracy check, error analysis, or comparison against human-extracted questions; any systematic extraction bias would propagate directly into the subsequent method comparisons and correlation figures.
Authors: We acknowledge that no validation of the LLM-based research-question extraction is currently reported. In the revision we will include an appendix with a manual error analysis on a random sample of 50 papers, comparing LLM-extracted questions to the original paper text and quantifying any systematic biases. This will allow readers to assess whether extraction errors could affect the downstream method comparisons. revision: yes
Circularity Check
No significant circularity; empirical counts and divergences computed directly from independent extractions
full rationale
The paper extracts research questions from 1,000 arXiv papers, prompts LLMs with those questions, extracts method features from both paper texts and LLM outputs, maps both into one taxonomy, and reports effective entity counts (1232 → 59-96), JS divergences, and rank correlations. These quantities are obtained by direct enumeration and standard information-theoretic measures after the mapping step; no equations, fitted parameters, or self-citations reduce the reported contraction or provider imbalance to quantities defined by the same data. The taxonomy functions as a neutral common representation rather than a self-referential construct, and the paper supplies no load-bearing self-citations or uniqueness theorems. The derivation chain therefore remains self-contained against the source data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature , volume=
Towards end-to-end automation of AI research , author=. Nature , volume=. 2026 , publisher=
2026
-
[2]
arXiv preprint arXiv:2408.14033 , year=
Mlr-copilot: Autonomous machine learning research based on large language models agents , author=. arXiv preprint arXiv:2408.14033 , year=
-
[3]
arXiv preprint arXiv:2411.05025 , year=
Llms as research tools: A large scale survey of researchers' usage and perceptions , author=. arXiv preprint arXiv:2411.05025 , year=
-
[4]
Jain, Rishab and Jain, Aditya. Generative AI in Writing Research Papers: A New Type of Algorithmic Bias and Uncertainty in Scholarly Work. Intelligent Systems and Applications. 2024. doi:10.1007/978-3-031-66329-1_42 , issn =
-
[5]
Agent Laboratory: Using LLM Agents as Research Assistants
Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiaodong and Liu, Jiang and Moor, Michael and Liu, Zicheng and Barsoum, Emad. Agent Laboratory: Using LLM Agents as Research Assistants. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.320
-
[6]
arXiv preprint arXiv:2503.08979 , year=
Agentic ai for scientific discovery: A survey of progress, challenges, and future directions , author=. arXiv preprint arXiv:2503.08979 , year=
-
[7]
The Thirteenth International Conference on Learning Representations , year=
Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[8]
Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents
Li, Long and Xu, Weiwen and Guo, Jiayan and Zhao, Ruochen and Li, Xingxuan and Yuan, Yuqian and Zhang, Boqiang and Jiang, Yuming and Xin, Yifei and Dang, Ronghao and Rong, Yu and Zhao, Deli and Feng, Tian and Bing, Lidong. Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents. Findings of the Association for Computational Lin...
-
[9]
Lund, Brady D. and Wang, Ting and Mannuru, Nishith Reddy and Nie, Bing and Shimray, Somipam and Wang, Ziang , year=. ChatGPT and a new academic reality: Artificial intelligence-written research papers and the ethics of large language models in scholarly publishing , volume=. Journal of the Association for Information Science and Technology , publisher=. d...
-
[10]
arXiv preprint arXiv:2510.26887 , year=
The Denario project: Deep knowledge AI agents for scientific discovery , author=. arXiv preprint arXiv:2510.26887 , year=
-
[11]
arXiv preprint arXiv:2504.02767 , year=
How deep do large language models internalize scientific literature and citation practices? , author=. arXiv preprint arXiv:2504.02767 , year=
-
[12]
arXiv preprint arXiv:2311.05965 , year=
Large language models are zero shot hypothesis proposers , author=. arXiv preprint arXiv:2311.05965 , year=
-
[13]
ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , year=. doi:10.18653/v1/2025.naacl-long.342 , pages =
-
[14]
S ci MON : Scientific Inspiration Machines Optimized for Novelty
Wang, Qingyun and Downey, Doug and Ji, Heng and Hope, Tom. S ci MON : Scientific Inspiration Machines Optimized for Novelty. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.18
-
[15]
arXiv preprint arXiv:2511.02824 , year=
Kosmos: An ai scientist for autonomous discovery , author=. arXiv preprint arXiv:2511.02824 , year=
-
[16]
arXiv preprint arXiv:2504.18765 , year=
A vision for auto research with llm agents , author=. arXiv preprint arXiv:2504.18765 , year=
-
[17]
AI for Research and Scalable, Efficient Systems , year=
ResearchCodeAgent: An LLM Multi-Agent System for Automated Codification of Research Methodologies , author=. AI for Research and Scalable, Efficient Systems , year=. doi:10.1007/978-981-96-8912-5_1 , url=
-
[18]
Elbadawi, Moe and Li, Hanxiang and Basit, Abdul W. and Gaisford, Simon , title =. International Journal of Pharmaceutics , year =. doi:10.1016/j.ijpharm.2023.123741 , pmid =
-
[19]
Why most published research findings are false , author=. PLoS medicine , volume=. 2005 , publisher=. doi:10.1371/journal.pmed.0020124 , issn =
-
[20]
Estimating the reproducibility of psychological science , author=. Science , volume=. 2015 , publisher=. doi:10.1126/science.aac4716 , issn =
-
[21]
Understanding the effects of
Kirk, Robert and Mediratta, Ishita and Nalmpantis, Christoforos and Luketina, Jelena and Hambro, Eric and Grefenstette, Edward and Raileanu, Roberta , journal=. Understanding the effects of
-
[22]
arXiv preprint arXiv:2603.19519 , year=
Inducing Sustained Creativity and Diversity in Large Language Models , author=. arXiv preprint arXiv:2603.19519 , year=
-
[23]
Proceedings of the National Academy of Sciences , volume=
Global citation inequality is on the rise , author=. Proceedings of the National Academy of Sciences , volume=. 2021 , publisher=. doi:10.1073/pnas.2012208118 , issn =
-
[24]
Liang, Weixin and Zhang, Yuhui and Cao, Hancheng and Wang, Binglu and Ding, Daisy Yi and Yang, Xinyu and Vodrahalli, Kailas and He, Siyu and Smith, Daniel Scott and Yin, Yian and McFarland, Daniel A. and Zou, James , journal=. Can large language models provide useful feedback on research papers?. 2024 , publisher=. doi:10.1056/AIoa2400196 , issn =
-
[25]
arXiv preprint arXiv:2409.13740 , year=
Language agents achieve superhuman synthesis of scientific knowledge , author=. arXiv preprint arXiv:2409.13740 , year=
-
[26]
Nature , volume=
Autonomous chemical research with large language models , author=. Nature , volume=. 2023 , doi =
2023
-
[27]
arXiv preprint arXiv:2601.19532 , year=
Benchmarks Saturate When The Model Gets Smarter Than The Judge , author=. arXiv preprint arXiv:2601.19532 , year=
-
[28]
Science , volume=
Scientific production in the era of large language models , author=. Science , volume=. 2025 , doi =
2025
-
[29]
Unequal scientific recognition in the age of
Liu, Yixuan and Elekes,. Unequal scientific recognition in the age of. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=. 2025 , doi=
2025
-
[30]
Structurally Human, Semantically Biased: Detecting
Mobini, Melika and Holst, Vincent and Tori, Floriano and Algaba, Andres and Ginis, Vincent , journal=. Structurally Human, Semantically Biased: Detecting
-
[31]
Findings of the Association for Computational Linguistics: NAACL 2025 , year=
Large language models reflect human citation patterns with a heightened citation bias , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , year=. doi:10.18653/v1/2025.findings-naacl.381 , pages =
-
[32]
Transforming literature screening: The emerging role of large language models in systematic reviews , author=. Proceedings of the National Academy of Sciences , volume=. 2025 , publisher=. doi:10.1073/pnas.2411962122 , issn =
-
[33]
Yamada, Yutaro and Lange, Robert Tjarko and Lu, Cong and Hu, Shengran and Lu, Chris and Foerster, Jakob and Clune, Jeff and Ha, David , journal=. The
-
[34]
arXiv preprint arXiv:2506.13131 , year=
Alexander Novikov and Ng. arXiv preprint arXiv:2506.13131 , year=
-
[35]
Science of science , author=. Science , volume=. 2018 , publisher=. doi:10.1126/science.aao0185 , issn=
-
[36]
Automating the practice of science: Opportunities, challenges, and implications , author=. Proceedings of the National Academy of Sciences , volume=. 2025 , publisher=. doi:10.1073/pnas.2401238121 , issn =
-
[37]
arXiv preprint arXiv:2402.14583 , year=
Dataset artefacts are the hidden drivers of the declining disruptiveness in science , author=. arXiv preprint arXiv:2402.14583 , year=
-
[38]
Merton, Robert K , journal=. The. 1968 , publisher=. doi:10.1126/science.159.3810.56 , issn=
-
[39]
Entropy and diversity , author=. Oikos , volume=. 2006 , publisher=. doi:10.1111/j.2006.0030-1299.14714.x , issn=
-
[40]
Advances in Neural Information Processing Systems , volume=
Picking on the same person: Does algorithmic monoculture lead to outcome homogenization? , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Science Advances , volume=
Generative AI enhances individual creativity but reduces the collective diversity of novel content , author=. Science Advances , volume=. 2024 , doi=
2024
-
[42]
Proceedings of the 16th Conference on Creativity and Cognition , pages=
Homogenization Effects of Large Language Models on Human Creative Ideation , author=. Proceedings of the 16th Conference on Creativity and Cognition , pages=. 2024 , organization=
2024
-
[43]
arXiv preprint arXiv:2509.04664 , year=
Why language models hallucinate , author=. arXiv preprint arXiv:2509.04664 , year=
-
[44]
Evaluating Replicability of Laboratory Experiments in Economics
Evaluating replicability of laboratory experiments in economics , author=. Science , volume=. 2016 , publisher=. doi:10.1126/science.aaf0918 , issn =
-
[45]
2024 , note=
Predicting Results of Social Science Experiments Using Large Language Models , author=. 2024 , note=
2024
-
[46]
Automated Social Science: Language Models as Scientist and Subjects , author=. 2024 , institution=. doi:10.3386/w32381 , url=
-
[47]
arXiv preprint arXiv:2502.18864 , year=
Towards an AI co-scientist , author=. arXiv preprint arXiv:2502.18864 , year=
-
[48]
arXiv preprint arXiv:2511.16072 , year=
Early science acceleration experiments with GPT-5 , author=. arXiv preprint arXiv:2511.16072 , year=
-
[49]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[50]
arXiv preprint arXiv:2009.03300 , year=
Measuring Massive Multitask Language Understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[51]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle=. Measuring Mathematical Problem Solving With the
-
[52]
International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. International Conference on Learning Representations , year=
-
[53]
2019 , doi =
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle=. 2019 , doi =
2019
-
[54]
2020 , doi =
Sakaguchi, Keisuke and Le Bras, Ronan and Bhagavatula, Chandra and Choi, Yejin , booktitle=. 2020 , doi =
2020
-
[55]
2016 , doi =
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , booktitle=. 2016 , doi =
2016
-
[56]
GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel , booktitle=. 2018 , publisher=. doi:10.18653/v1/W18-5446 , url=
-
[57]
2025 , doi=
Singh, Aaditya and Fry, Adam and Perelman, Adam and Tart, Adam and Ganesh, Adi and El-Kishky, Ahmed and McLaughlin, Aidan and Low, Aiden and Ostrow, AJ and Ananthram, Akhila and Nathan, Akshay and Luo, Alan and Helyar, Alec and Madry, Aleksander and Efremov, Aleksandr and others , journal=. 2025 , doi=
2025
-
[58]
arXiv preprint arXiv:2412.19437 , year=. doi:10.48550/arXiv.2412.19437 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437
-
[59]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
arXiv preprint arXiv:2501.12948 , year=. doi:10.48550/arXiv.2501.12948 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948
-
[60]
arXiv preprint arXiv:2303.08774 , year=. doi:10.48550/arXiv.2303.08774 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[61]
arXiv preprint arXiv:2410.21276 , year=. doi:10.48550/arXiv.2410.21276 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21276
-
[62]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. arXiv preprint arXiv:2307.09288 , year=. doi:10.48550/arXiv.2307.09288 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288
-
[63]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[64]
Divergence measures based on the
Lin, Jianhua , journal=. Divergence measures based on the. 1991 , doi=
1991
-
[65]
Journal of the Royal Statistical Society: Series B (Methodological) , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal Statistical Society: Series B (Methodological) , volume=. 1995 , doi=
1995
-
[66]
1946 , publisher=
Mathematical Methods of Statistics , author=. 1946 , publisher=
1946
-
[67]
1988 , publisher=
Statistical Power Analysis for the Behavioral Sciences , author=. 1988 , publisher=
1988
-
[68]
American Journal of Psychology , volume=
The proof and measurement of association between two things , author=. American Journal of Psychology , volume=. 1904 , doi=
1904
-
[69]
New Phytologist , volume=
The distribution of the flora in the alpine zone , author=. New Phytologist , volume=. 1912 , doi=
1912
-
[70]
Variabilit
Gini, Corrado , year=. Variabilit
-
[71]
Monographs on statistics and applied probability , volume=
An introduction to the bootstrap , author=. Monographs on statistics and applied probability , volume=
-
[72]
Philosophical Magazine , volume=
On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling , author=. Philosophical Magazine , volume=. 1900 , doi=
1900
-
[73]
Soviet Physics Doklady , volume=
Binary codes capable of correcting deletions, insertions and reversals , author=. Soviet Physics Doklady , volume=. 1966 , note=
1966
-
[74]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
arXiv preprint arXiv:2512.02556 , year=. doi:10.48550/arXiv.2512.02556 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.02556
-
[75]
2025 , howpublished =
DeepSeek-V3.2 Release , author =. 2025 , howpublished =
2025
-
[76]
2023 , howpublished=
thefuzz: Fuzzy String Matching in. 2023 , howpublished=
2023
-
[77]
Educational and Psychological Measurement , volume=
A coefficient of agreement for nominal scales , author=. Educational and Psychological Measurement , volume=. 1960 , publisher=
1960
-
[78]
Psychological Bulletin , volume=
Intraclass correlations: Uses in assessing rater reliability , author=. Psychological Bulletin , volume=. 1979 , publisher=
1979
-
[79]
2025 , institution =
Gemini 3 Pro Model Card , author =. 2025 , institution =
2025
-
[80]
2026 , howpublished =
arXiv License Information , author =. 2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.