The Kernel's Write: Application Read-Only Memory
Pith reviewed 2026-06-26 14:55 UTC · model grok-4.3
The pith
AROM lets the OS manage LtRAM by enforcing application read-only pages through copy-on-write faults, simplifying DIMM hardware while matching DRAM performance on read-mostly workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that enforcing AROM via copy-on-write lets LtRAM management move from the DIMM controller to the OS, which drastically simplifies the hardware while matching pure DRAM performance on read-mostly workloads.
What carries the argument
Application Read-Only Memory (AROM): LtRAM pages that are read-only to applications and written only by the OS during migrations, enforced by CoW faults that redirect writes to DRAM.
If this is right
- LtRAM DIMMs can omit on-controller translation layers for wear-leveling and caching.
- OS page migration becomes the only path for writes to LtRAM.
- Read-mostly applications see no performance loss compared with pure DRAM.
- LtRAM density and cost advantages become available without hardware-managed read/write asymmetry penalties.
Where Pith is reading between the lines
- Datacenters facing DRAM scaling limits could adopt denser LtRAM more readily if OS migration overhead stays low.
- Workloads with frequent writes would likely need hybrid DRAM-LtRAM allocation policies to avoid migration storms.
- The same CoW offloading pattern might extend to other asymmetric memories beyond LtRAM.
Load-bearing premise
Application writes can be efficiently redirected via CoW faults and page migrations to DRAM without introducing unacceptable latency or complexity, and workloads are read-mostly enough to benefit.
What would settle it
A workload trace or benchmark where the total latency from CoW faults and DRAM migrations exceeds the savings from simpler LtRAM hardware and lower density cost.
Figures


read the original abstract
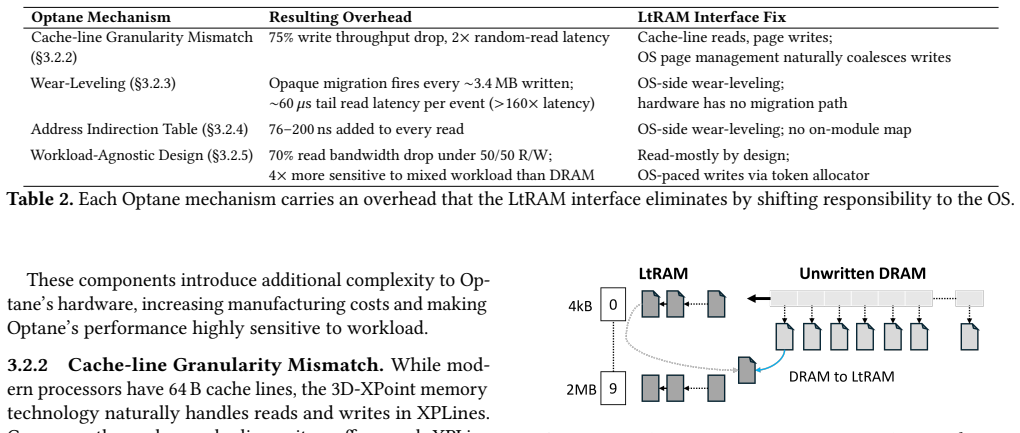
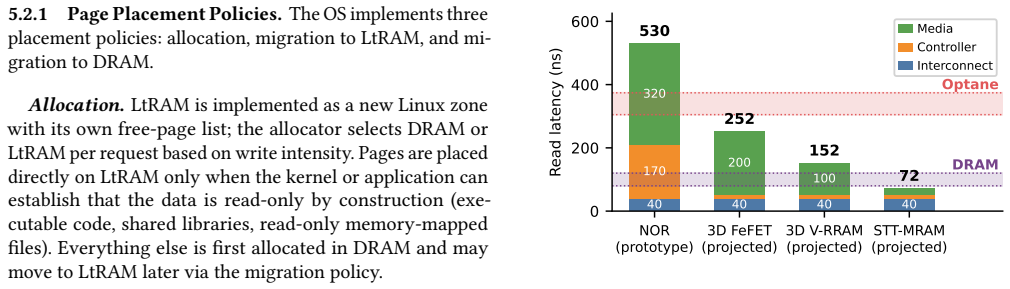
Alongside power, DRAM has become a major limiting factor in datacenter growth. As DRAM's cost-per-bit has plateaued over the past decade, a class of emerging memory technologies, called Long-term RAM (LtRAM), offers a path to denser and cheaper main memory. However, LtRAM has three main drawbacks: asymmetric read/write latencies, limited endurance, and coarse write granularity. In an attempt to isolate software from these drawbacks, LtRAM technologies such as Intel Optane copy an approach from flash devices and introduce a translation layer that manages wear-leveling, address remapping, and read/write caching. Prior experimental studies have found these operations add significantly to LtRAM latency. Rather than making LtRAM look like DRAM, we propose redesigning the hardware/software interface to offload more responsibility to the operating system. This design hinges on one central property, Application Read-Only Memory (AROM): LtRAM pages are read-only to applications and written only by the OS during page migrations. AROM is enforced by leveraging copy-on-write (CoW): application writes to LtRAM trigger a fault that migrates the page back to DRAM before the store is applied. This invariant allows us to shift LtRAM management from the on-DIMM controller to the operating system, drastically simplifying the DIMM's hardware. With this approach, we aim to match the performance of pure DRAM on read-mostly workloads while delivering LtRAM's density and cost advantages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Application Read-Only Memory (AROM) as a new hardware/software interface for Long-term RAM (LtRAM). Under AROM, LtRAM pages are read-only to applications and written only by the OS via copy-on-write faults that trigger page migrations to DRAM; this invariant is intended to allow the OS to assume responsibility for wear-leveling, remapping, and caching, thereby simplifying DIMM hardware while targeting performance parity with pure DRAM on read-mostly workloads.
Significance. If the central performance claim holds, the design would offer a concrete route to denser, lower-cost main memory by removing on-DIMM translation layers whose overhead has been documented in prior LtRAM studies. The approach is distinctive in its explicit use of CoW to enforce a read-only invariant at the application level rather than hiding LtRAM properties behind a hardware controller.
major comments (2)
- [Abstract] Abstract: the claim that the design will 'match the performance of pure DRAM on read-mostly workloads' is presented without any latency model, migration-cost bound, or write-ratio threshold; the equivalence therefore remains an assertion rather than a derived result.
- [Abstract] Abstract: the central design invariant (every application write routes through a kernel fault, page migration, and DRAM store) is load-bearing for both the hardware-simplification and performance claims, yet no section supplies an analytical or empirical bound on the added latency of this path relative to native DRAM writes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the abstract makes performance claims without the necessary supporting analysis and will revise the manuscript to address this. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the design will 'match the performance of pure DRAM on read-mostly workloads' is presented without any latency model, migration-cost bound, or write-ratio threshold; the equivalence therefore remains an assertion rather than a derived result.
Authors: We agree the performance goal is stated without quantitative support. Although the abstract uses 'aim to match' (rather than a definitive claim), no model or threshold is supplied. In revision we will qualify the statement to 'approach performance parity on workloads with write ratios below X%' and add a short paragraph deriving an approximate threshold from standard CoW fault costs. revision: yes
-
Referee: [Abstract] Abstract: the central design invariant (every application write routes through a kernel fault, page migration, and DRAM store) is load-bearing for both the hardware-simplification and performance claims, yet no section supplies an analytical or empirical bound on the added latency of this path relative to native DRAM writes.
Authors: This is correct; the manuscript provides no bound on CoW-plus-migration latency. The design's viability rests on this path being rare, yet the overhead is unquantified. We will insert an analytical estimate (drawing on published page-fault and migration latencies) into the introduction or a new short section, together with a discussion of its effect on the read-mostly target. revision: yes
Circularity Check
Conceptual redesign proposal exhibits no circularity
full rationale
The paper is a hardware/software interface redesign proposal centered on the AROM invariant enforced by CoW faults and OS page migrations. No equations, fitted parameters, derivations, or mathematical claims appear in the provided text. Central assertions (performance equivalence on read-mostly workloads, hardware simplification) are presented as design goals rather than results derived from prior inputs or self-citations. No load-bearing steps reduce by construction to the paper's own definitions or fitted values. This is a normal non-finding for a conceptual architecture paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Application Read-Only Memory (AROM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
David Cock, Abishek Ramdas, Daniel Schwyn, Michael Giardino, Adam Turowski, Zhenhao He, Nora Hossle, Dario Korolija, Melissa Liccia- rdello, Kristina Martsenko, Reto Achermann, Gustavo Alonso, and Timothy Roscoe. 2022. Enzian: An Open, General, CPU/FPGA Plat- form for Systems Software Research. InProceedings of the 27th ACM International Conference on Arc...
-
[2]
Counterpoint Research. 2026. Memory Prices Surge Up to 90% From Q4 2025. Counterpoint Research insight report. https://counterpointresearch.com/en/insights/Memory-Prices- Surge-Up-to-90-From-Q4-2025
2026
-
[3]
Daewon Ha, Wonsok Lee, M.H. Cho, M. Terai, S.-W. Yoo, H. Kim, Y. Lee, S. Uhm, M. Ryu, C. Sung, Y. Song, K. Lee, S.W. Park, K.-S. Lee, Y.S. Tak, E. Hwang, J. Chae, C. Im, S. Byeon, M. Hong, K. Sim, W.J. Jung, H. Ryu, M.J. Hong, S. Park, J. Park, Y. Choi, S. Lee, G. Woo, J. Lee, D.S. Kim, B.J. Kuh, Yu Gyun Shin, and Jaihyuk Song. 2023. Highly Manufacturable...
-
[4]
J.W. Han, S.H. Park, M.Y. Jeong, K.S. Lee, K.N. Kim, H.J. Kim, J.C. Shin, S.M. Park, S.H. Shin, S.W. Park, K.S. Lee, J.H. Lee, S.H. Kim, B.C Kim, M.H. Jung, I.Y. Yoon, H. Kim, S.U. Jang, K.J. Park, Y.K. Kim, I.G. Kim, J.H Oh, S.Y. Han, B.S. Kim, B.J. Kuh, and J.M. Park. 2023. Ongoing Evolution of DRAM Scaling via Third Dimension -Vertically Stacked DRAM -...
-
[5]
Takahiro Hirofuchi and Ryousei Takano. 2020. A Prompt Report on the Performance of Intel Optane DC Persistent Memory Module.CoRR abs/2002.06018 (2020).https://arxiv.org/abs/2002.06018
arXiv 2020
-
[6]
Dulloor, Jishen Zhao, and Steven Swanson
Joseph Izraelevitz, Jian Yang, Lu Zhang, Juno Kim, Xiao Liu, Amir Saman Memaripour, Yun Joon Soh, Zixuan Wang, Yi Xu, Sub- ramanya R. Dulloor, Jishen Zhao, and Steven Swanson. 2019. Basic Performance Measurements of the Intel Optane DC Persistent Memory Module.CoRRabs/1903.05714 (2019).http://arxiv.org/abs/1903.05714
arXiv 2019
-
[7]
Andres Lagar-Cavilla, Junwhan Ahn, Suleiman Souhlal, Neha Agarwal, Radoslaw Burny, Shakeel Butt, Jichuan Chang, Ashwin Chaugule, Nan Deng, Junaid Shahid, Greg Thelen, Kamil Adam Yurtsever, Yu Zhao, and Parthasarathy Ranganathan. 2019. Software-Defined Far Memory in Warehouse-Scale Computers. InProceedings of the Twenty-Fourth International Conference on A...
-
[8]
Lee, Engin Ipek, Onur Mutlu, and Doug Burger
Benjamin C. Lee, Engin Ipek, Onur Mutlu, and Doug Burger. 2009. Architecting Phase Change Memory as a Scalable DRAM Alternative. InProceedings of the 36th Annual International Symposium on Computer Architecture (ISCA ’09). Association for Computing Machinery, 2–13. doi:10.1145/1555754.1555758
-
[9]
Taehyung Lee, Sumit Kumar Monga, Changwoo Min, and Young Ik Eom. 2023. MEMTIS: Efficient Memory Tiering with Dynamic Page Classification and Page Size Determination. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). Association for Computing Machinery, 17–34. doi:10.1145/3600006.3613167
-
[10]
Sergey Legtchenko, Ioan Stefanovici, Richard Black, Antony Rowstron, Junyi Liu, Paolo Costa, Burcu Canakci, Dushyanth Narayanan, and Xingbo Wu. 2025. Storage Class Memory is Dead, All Hail Managed- Retention Memory: Rethinking Memory for the AI Era. InProceedings of the 2025 Workshop on Hot Topics in Operating Systems (HotOS ’25). Association for Computin...
-
[11]
Pond: CXL-based memory pooling systems for cloud platforms,
Huaicheng Li, Daniel S. Berger, Lisa Hsu, Daniel Ernst, Pantea Zar- doshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D. Hill, Marcus Fontoura, and Ricardo Bian- chini. 2023. Pond: CXL-Based Memory Pooling Systems for Cloud Platforms. InProceedings of the 28th ACM International Conference on Architectural Support for P...
-
[12]
Peijing Li, Muhammad Shahir Abdurrahman, Rachel Cleaveland, Sergey Legtchenko, Philip Levis, Ioan Stefanovici, Thierry Tambe, David Tennenhouse, Caroline Trippel, and H.-S. Philip Wong. 2025. Towards Memory Specialization: A Case for Long-Term and Short- Term RAM. InProceedings of the 3rd Workshop on Disruptive Memory Systems (DIMES ’25). Association for ...
-
[13]
Jinshu Liu, Hamid Hadian, Hanchen Xu, and Huaicheng Li. 2025. Tiered Memory Management Beyond Hotness. In19th USENIX Sym- posium on Operating Systems Design and Implementation (OSDI 25). USENIX Association, Boston, MA, 731–747.https://www.usenix.org/ conference/osdi25/presentation/liu
2025
-
[14]
Sihang Liu, Suraaj Kanniwadi, Martin Schwarzl, Andreas Kogler, Daniel Gruss, and Samira Khan. 2023. Side-Channel Attacks on Optane Persistent Memory. In32nd USENIX Security Symposium (USENIX Secu- rity 23). USENIX Association, Anaheim, CA, 6807–6824.https://www. usenix.org/conference/usenixsecurity23/presentation/liu-sihang
2023
-
[15]
Anni Lu, Junmo Lee, Tae-Hyeon Kim, Muhammed Ahosan Ul Karim, Rebecca Sejung Park, Harsono Simka, and Shimeng Yu. 2024. High- speed emerging memories for AI hardware accelerators.Nature Re- views Electrical Engineering1, 1 (2024), 24–34. doi:10.1038/s44287-023- 00002-9
-
[16]
Hasan Al Maruf, Hao Wang, Abhishek Dhanotia, Johannes Weiner, Niket Agarwal, Pallab Bhattacharya, Chris Petersen, Mosharaf Chowd- hury, Shobhit Kanaujia, and Prakash Chauhan. 2023. TPP: Trans- parent Page Placement for CXL-Enabled Tiered-Memory. InPro- ceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and...
-
[17]
Micron Technology. 2022. MT35XU02G 2Gb, 1.8V Serial NOR Flash Memory Datasheet. Datasheet. Part number MT35XU02GCBA
2022
-
[18]
Amanda Raybuck, Tim Stamler, Wei Zhang, Mattan Erez, and Simon Peter. 2021. HeMem: Scalable Tiered Memory Management for Big Data Applications and Real NVM. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP ’21). Association for Computing Machinery, 392–407. doi:10.1145/3477132.3483550
-
[19]
TrendForce. 2026. Memory Price Outlook for 1Q26 Sharply Upgraded; QoQ Increases of All Product Categories to Hit Record Highs. Trend- Force Corp. press release.https://www.trendforce.com/presscenter/ news/20260202-12911.html
arXiv 2026
-
[20]
Midhul Vuppalapati and Rachit Agarwal. 2024. Tiered Memory Man- agement: Access Latency is the Key!. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP ’24). Association for Computing Machinery, 79–94. doi:10.1145/3694715.3695968
-
[21]
Zixuan Wang, Xiao Liu, Jian Yang, Theodore Michailidis, Steven Swan- son, and Jishen Zhao. 2020. Characterizing and Modeling Non-Volatile Memory Systems. In2020 53rd Annual IEEE/ACM International Sympo- sium on Microarchitecture (MICRO). 496–508. doi:10.1109/MICRO50266. 2020.00049
-
[22]
Lingfeng Xiang, Xingsheng Zhao, Jia Rao, Song Jiang, and Hong Jiang. 2022. Characterizing the Performance of Intel Optane Per- sistent Memory: A Close Look at Its On-DIMM Buffering. InPro- ceedings of the Seventeenth European Conference on Computer Sys- tems (EuroSys ’22). Association for Computing Machinery, 488–505. doi:10.1145/3492321.3519556
-
[23]
Jian Yang, Juno Kim, Morteza Hoseinzadeh, Joseph Izraelevitz, and Steven Swanson. 2020. An Empirical Guide to the Behavior and Use of Scalable Persistent Memory. In18th USENIX Conference on File and Storage Technologies (FAST 20). USENIX Association, Santa Clara, CA, 169–182.https://www.usenix.org/conference/fast20/presentation/ yang
2020
-
[24]
Berger, Carl Waldspurger, Ryan Wee, Ishwar Agarwal, Rajat Agarwal, Frank Hady, Karthik Kumar, Mark D
Yuhong Zhong, Daniel S. Berger, Carl Waldspurger, Ryan Wee, Ishwar Agarwal, Rajat Agarwal, Frank Hady, Karthik Kumar, Mark D. Hill, 7 Mosharaf Chowdhury, and Asaf Cidon. 2024. Managing Memory Tiers with CXL in Virtualized Environments. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Asso- ciation, Santa Clara, CA, ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.