Lacuna: A Research Map for Machine Learning
Pith reviewed 2026-06-26 00:49 UTC · model grok-4.3
The pith
Lacuna uses LLMs to build a linked research map from machine learning papers that improves retrieval and report generation over existing tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
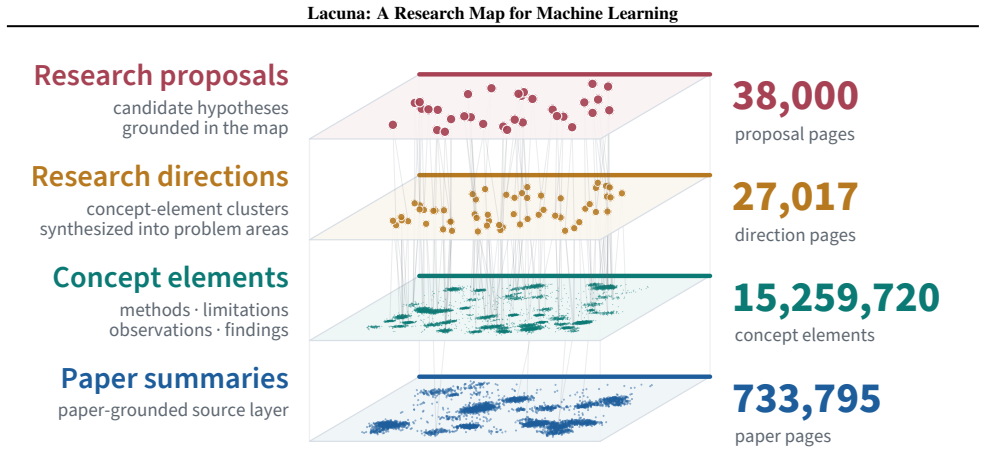
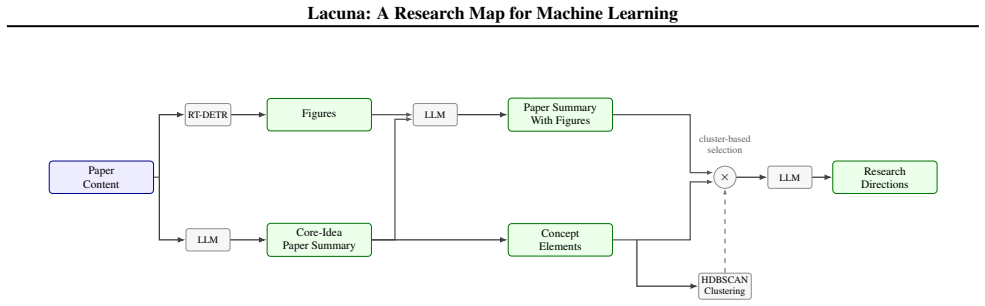
Lacuna is a research map for machine learning that uses LLMs to turn papers and scholarly metadata into markdown summaries, concept elements, research directions, and research proposals. Each item keeps links to the primary source records and papers that support it. Across LitSearch, Multi-XScience-CS/ML, and ScholarQA-CS-ML, Lacuna outperforms OpenScholar with the strongest gains on LitSearch retrieval. Lacuna Deep Research reaches higher citation F1, citation precision, expert-reference hits, and RACE report quality on 25 tasks than GPT-Researcher.
What carries the argument
The Lacuna research map, a collection of LLM-generated markdown summaries, concept elements, research directions, and research proposals that remain linked to their source papers and records.
If this is right
- Researchers gain improved recall when searching for relevant ML papers through the structured map.
- Multi-stage agents built on the map can produce reports with more accurate citations and higher expert alignment.
- The map supplies explicit research directions and proposals that stay traceable to supporting papers.
- Release of the map with multiple interfaces allows direct testing and extension by other users.
Where Pith is reading between the lines
- If the map remains accurate at larger scale, it could help surface under-explored research directions before new proposals are written.
- The same LLM-to-map process might apply to other scientific domains once domain-specific faithfulness is verified.
- Hybrid systems could combine the map with traditional citation graphs to improve navigation beyond either alone.
- Long-term use might shift how teams track and avoid duplicating prior work in fast-moving fields.
Load-bearing premise
LLM-generated summaries, concepts, and proposals faithfully represent the source papers without introducing substantial errors or omissions.
What would settle it
A manual review of a sample of Lacuna map entries that finds frequent factual inaccuracies or omitted key results from the original papers.
Figures

read the original abstract
Lacuna is a research map for machine learning that uses LLMs to turn papers and scholarly metadata into markdown summaries, concept elements, research directions, and research proposals. Each item keeps links to the primary source records and papers that support it. We release the map with web, markdown, and MCP interfaces. Across LitSearch, Multi-XScience-CS/ML, and ScholarQA-CS-ML, Lacuna outperforms OpenScholar with the strongest gains on LitSearch retrieval (Recall@10 0.538 vs. 0.424 for OpenScholar v3). We also evaluate Lacuna Deep Research, a multi-stage report agent over the map, on 25 ReportBench-ML survey tasks: Lacuna Deep Research reaches 0.052 citation F1, 0.339 citation precision, 99 expert-reference hits, and 7.82/10 RACE report quality, while GPT-Researcher reaches 0.039 F1, 0.290 precision, 72 hits, and 5.24/10 RACE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. Lacuna is a research map for machine learning constructed by applying LLMs to papers and metadata to produce linked markdown summaries, concept elements, research directions, and proposals. The map is released with web, markdown, and MCP interfaces. The paper reports that Lacuna outperforms OpenScholar on LitSearch (Recall@10 0.538 vs. 0.424), Multi-XScience-CS/ML, and ScholarQA-CS-ML, and that its multi-stage Lacuna Deep Research agent outperforms GPT-Researcher on 25 ReportBench-ML tasks in citation F1 (0.052 vs. 0.039), citation precision (0.339 vs. 0.290), expert-reference hits (99 vs. 72), and RACE report quality (7.82/10 vs. 5.24/10).
Significance. If the LLM-generated components are shown to be faithful to source papers, the structured, link-preserving research map could provide a reusable substrate for retrieval and report-generation tasks in ML. The public release of the map and the concrete benchmark comparisons against named baselines are positive contributions that could be built upon by the community.
major comments (2)
- [Evaluation and abstract] The central performance claims (LitSearch Recall@10, ScholarQA results, Deep Research F1 0.052, and RACE 7.82) rest on the assumption that the LLM-generated summaries, concepts, and proposals are faithful to the source papers. No human fidelity evaluation, citation-level fact-checking, or automated consistency metric for these generations is described anywhere in the manuscript, leaving the downstream retrieval and report metrics as unverified proxies.
- [Method / map construction (implied)] The manuscript provides no details on the LLM models, prompts, temperature settings, or quality-control steps used to construct the map. Without these, the reported gains cannot be reproduced or diagnosed, undermining the claim that the map itself is the source of the observed improvements.
minor comments (1)
- [Abstract] The abstract and results paragraphs would benefit from explicit statements of the number of papers processed and the total size of the released map.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Evaluation and abstract] The central performance claims (LitSearch Recall@10, ScholarQA results, Deep Research F1 0.052, and RACE 7.82) rest on the assumption that the LLM-generated summaries, concepts, and proposals are faithful to the source papers. No human fidelity evaluation, citation-level fact-checking, or automated consistency metric for these generations is described anywhere in the manuscript, leaving the downstream retrieval and report metrics as unverified proxies.
Authors: We agree that the manuscript contains no human fidelity evaluation, citation-level fact-checking, or automated consistency metric for the LLM-generated summaries, concepts, and proposals. The reported results rely on downstream task performance as an indirect indicator of map quality. To address this gap, the revised manuscript will add a new subsection that reports a small-scale human evaluation of summary faithfulness on a random sample of papers together with any automated checks performed during construction. revision: yes
-
Referee: [Method / map construction (implied)] The manuscript provides no details on the LLM models, prompts, temperature settings, or quality-control steps used to construct the map. Without these, the reported gains cannot be reproduced or diagnosed, undermining the claim that the map itself is the source of the observed improvements.
Authors: We acknowledge that the manuscript does not specify the LLM models, prompts, temperature settings, or quality-control steps used to build the map. These omissions limit reproducibility. In the revision we will expand the Methods section with a dedicated construction pipeline subsection that lists the exact models and versions, provides representative prompts, states the temperature values employed, and describes all quality-control and filtering procedures. revision: yes
Circularity Check
No circularity: empirical comparisons against external baselines on public benchmarks
full rationale
The paper presents Lacuna as an LLM-based research map system and reports direct empirical results on LitSearch, Multi-XScience-CS/ML, ScholarQA-CS-ML, and ReportBench-ML tasks, comparing against named external baselines (OpenScholar v3, GPT-Researcher). No derivation chain, equations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear in the provided text. Performance numbers (e.g., Recall@10 0.538) are presented as measured outcomes, not outputs forced by self-definition or self-citation. The evaluation is therefore self-contained against external references.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LitSearch: A retrieval benchmark for scientific literature search
Ajith, A., Xia, M., Chevalier, A., Goyal, T., Chen, D., and Gao, T. LitSearch: A retrieval benchmark for scientific literature search. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2024
-
[2]
URL https://arxiv.org/abs/ 6 Lacuna: A Research Map for Machine Learning 2407.18940. Artiles, A. H., Weiss, M., Brinkmann, L., Rahwan, I., Sch¨olkopf, B., Pal, C., Larochelle, H., Goyal, A., and Rahaman, N. The alien space of science: Sampling coher- ent but cognitively unavailable research directions,
-
[3]
Asai, A., He, J., Shao, R., Shi, W., Singh, A., Chang, J
URLhttps://arxiv.org/abs/2603.01092. Asai, A., He, J., Shao, R., Shi, W., Singh, A., Chang, J. C., Lo, K., Soldaini, L., Feldman, S., D’Arcy, M., Wad- den, D., Latzke, M., Sparks, J., Hwang, J. D., Kishore, V ., Tian, M., Ji, P., Liu, S., Tong, H., Wu, B., Xiong, Y ., Zettlemoyer, L., Neubig, G., Weld, D. S., Downey, D., Yih, W.-t., Koh, P. W., and Hajish...
-
[4]
doi: 10.1038/s41586-025-10072-4. URL https://doi. org/10.1038/s41586-025-10072-4. Azerbayev, Z., Piotrowski, B., Schoelkopf, H., Ayers, E. W., Radev, D., and Avigad, J. ProofNet: Autoformalizing and formally proving undergraduate-level mathematics,
-
[5]
Cohan, A., Feldman, S., Beltagy, I., Downey, D., and Weld, D
URLhttps://arxiv.org/abs/2302.12433. Cohan, A., Feldman, S., Beltagy, I., Downey, D., and Weld, D. S. SPECTER: Document-level representa- tion learning using citation-informed transformers. In Proceedings of the 58th Annual Meeting of the Associa- tion for Computational Linguistics,
-
[6]
Du, M., Xu, B., Zhu, C., Wang, X., and Mao, Z
URL https: //arxiv.org/abs/2004.07180. Du, M., Xu, B., Zhu, C., Wang, X., and Mao, Z. Deep- Research Bench: A comprehensive benchmark for deep research agents,
arXiv 2004
-
[7]
URL https://arxiv.org/ abs/2506.11763. Elovic, A. GPT Researcher: Autonomous agent for comprehensive online research. Software,
-
[8]
L´ala, J., O’Donoghue, O., Shtedritski, A., Cox, S., Ro- driques, S
URL https://arxiv.org/abs/1901.10816. L´ala, J., O’Donoghue, O., Shtedritski, A., Cox, S., Ro- driques, S. G., and White, A. D. PaperQA: Retrieval- augmented generative agent for scientific research,
arXiv 1901
-
[9]
URLhttps://arxiv.org/abs/2312.07559. LangChain Team. Open deep research. LangChain Blog and Software,
-
[10]
URL https://arxiv.org/abs/ 2508.15804. Liu, C., Shen, J., Xin, H., Liu, Z., Yuan, Y ., Wang, H., Ju, W., Zheng, C., Yin, Y ., Li, L., Zhang, M., and Liu, Q. FIMO: A challenge formal dataset for automated theorem proving,
-
[11]
URL https://arxiv.org/ abs/2309.04295. Lo, K., Wang, L. L., Neumann, M., Kinney, R., and Weld, D. S. S2ORC: The semantic scholar open research cor- pus,
-
[12]
URL https://arxiv.org/abs/1911. 02782. Lu, Y ., Dong, Y ., and Charlin, L. Multi-XScience: A large- scale dataset for extreme multi-document summariza- tion of scientific articles. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),
1911
-
[13]
URL https://arxiv. org/abs/2010.14235. McInnes, L., Healy, J., and Astels, S. hdbscan: Hierarchical density based clustering.Journal of Open Source Soft- ware, 2(11):205,
arXiv 2010
-
[14]
Journal of Open Source Software , volume =
doi: 10.21105/joss.00205. URL https://doi.org/10.21105/joss.00205. Pirolli, P. and Card, S. K. Information foraging.Psycholog- ical Review, 106(4):643–675,
-
[15]
Priem, J., Piwowar, H., and Orr, R
doi: 10.1037/0033- 295X.106.4.643. Priem, J., Piwowar, H., and Orr, R. Openalex: A fully- open index of scholarly works, authors, venues, insti- tutions, and concepts,
-
[16]
URL https://arxiv. org/abs/2205.01833. Sahu, G., Larochelle, H., Charlin, L., and Pal, C. Re- viewerToo: Should ai join the program committee? a look at the future of peer review,
-
[17]
Shang, S., Wan, R., Peng, Y ., Wu, Y ., Chen, X.-h., Yan, J., and Zhang, X
URL https: //arxiv.org/abs/2510.08867. Shang, S., Wan, R., Peng, Y ., Wu, Y ., Chen, X.-h., Yan, J., and Zhang, X. StepFun-Prover preview: Let’s think and verify step by step,
-
[18]
URL https://arxiv. org/abs/2507.20199. Shao, Y ., Jiang, Y ., Kanell, T. A., Xu, P., Khattab, O., and Lam, M. S. Assisting in writing Wikipedia-like articles from scratch with large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,
arXiv 2024
-
[19]
URL https://arxiv. org/abs/2402.14207. 7 Lacuna: A Research Map for Machine Learning Shin, H., Tang, J., Lee, Y ., Kim, N., Lim, H., Cho, J. Y ., Hong, H., Lee, M., and Kim, J. Mind the blind spots: A focus-level evaluation framework for LLM reviews,
-
[20]
Thilakaratne, M., Falkner, K., and Atapattu, T
URLhttps://arxiv.org/abs/2502.17086. Thilakaratne, M., Falkner, K., and Atapattu, T. A systematic review on literature-based discovery workflow.PeerJ Computer Science, 5:e235,
-
[21]
doi: 10.7717/peerj-cs
-
[22]
Wadden, D., Lin, S., Lo, K., Wang, L
URL https://doi.org/10.7717/peerj- cs.235. Wadden, D., Lin, S., Lo, K., Wang, L. L., van Zuylen, M., Cohan, A., and Hajishirzi, H. Fact or fiction: Verifying scientific claims. InProceedings of the 2020 Confer- ence on Empirical Methods in Natural Language Process- ing,
-
[23]
URL https://arxiv.org/abs/2004. 14974. Ye, Z., Yan, Z., He, J., Kasriel, T., Yang, K., and Song, D. VERINA: Benchmarking verifiable code genera- tion,
2004
-
[24]
8 Lacuna: A Research Map for Machine Learning A
URL https://arxiv.org/abs/2304.08069. 8 Lacuna: A Research Map for Machine Learning A. Per-Claim Audit Table 6 summarizes the detailed grounding audit. Each row pairs an extracted claim with the /md page (and section) where its support is located. Claim Evidence checked Status Notes Autoformalization is hard because in- formal mathematics leaves assump- t...
-
[25]
42 ML/AI prompts from ScholarQA- CS
ScholarQA-CS-ML Answer ML/AI literature-review questions with grounding. 42 ML/AI prompts from ScholarQA- CS. Lacuna paper, concept, and cited-evidence pack- ets. ScholarQABench rubric average. ReportBench-ML Write survey-style deep-research reports. 25 core-ML survey tasks. Lacuna Deep Research reports. Citation overlap and RACE quality. proposal pages l...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.