TEMPO-Diffusion: Temporally Exposed Malicious Poisoning of Diffusion Models
Pith reviewed 2026-06-26 01:27 UTC · model grok-4.3
The pith
TEMPO-Diffusion uses time-conditioned triggers to localize backdoors in diffusion models, poisoning class-specific synthetic images that then compromise downstream classifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
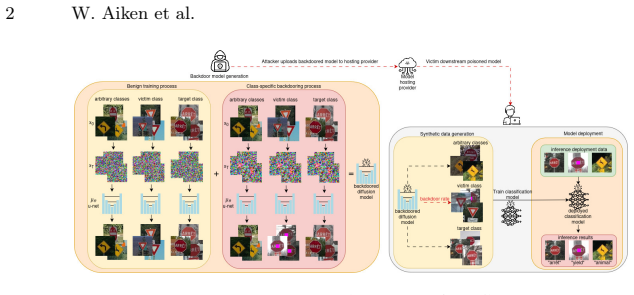
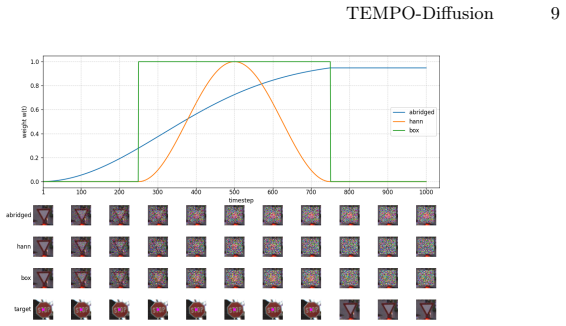
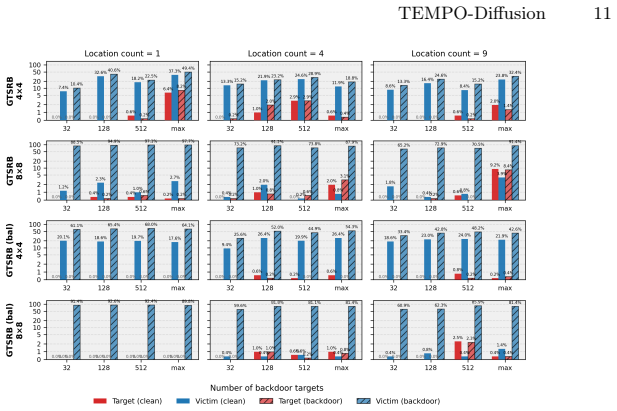
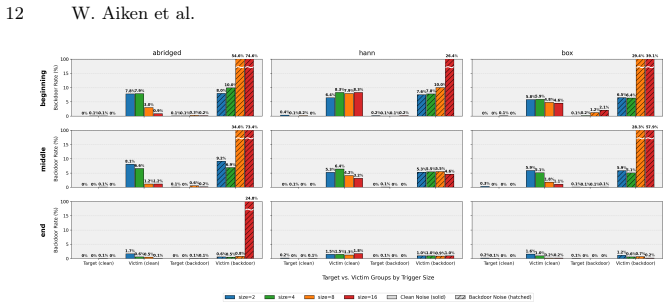
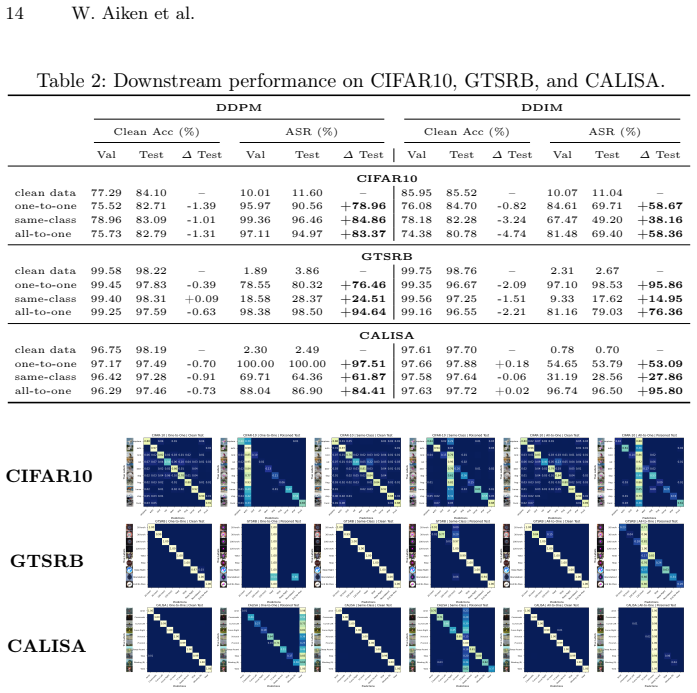
TEMPO-Diffusion is a targeted backdoor framework that localizes the malicious distribution shift to a temporal, in-distribution exposure. It supports attacks on and to specific classes, multiple sub-image backdoors that reconstruct chosen features at chosen locations, and in-painting with time-conditioned triggers. Across CIFAR10, GTSRB, and CALISA the method reliably poisons class-specific synthetic data generation and produces high attack success rates in downstream classifiers trained on that data.
What carries the argument
Time-conditioned triggers that localize the malicious distribution shift to specific temporal exposures while remaining in-distribution.
If this is right
- Targeted attacks become possible on and to chosen output classes in the generated images.
- Multiple independent backdoors can be placed inside different regions of the same or different output images.
- In-painting tasks can be poisoned using the same time-conditioned mechanism.
- Classifiers trained on the poisoned synthetic data show high attack success rates on the tested datasets.
Where Pith is reading between the lines
- Detection methods for diffusion-model poisoning may need to inspect generation timing or step-wise distribution statistics rather than final images alone.
- Organizations that use diffusion-generated data for training should add integrity checks on the generative model itself.
- The same temporal-trigger idea could be tested on other iterative generative processes that have an explicit time or step parameter.
- In domains such as autonomous driving, pipelines that rely on synthetic traffic-sign data would become a new attack surface.
Load-bearing premise
Time-conditioned triggers can localize the malicious distribution shift to specific temporal exposures while remaining in-distribution and undetectable during normal generation.
What would settle it
Generate images both with and without the chosen time trigger and measure whether the downstream classifier attack success rate falls to chance level on the no-trigger images.
Figures
read the original abstract
Noise-based backdoor attacks on diffusion models typically rely on input-time trigger injection, untargeted activation, and out-of-distribution target generation. Such assumptions reduce both the stealthiness and the practical relevance of these attacks. In this work, we present TEMPO-Diffusion, a targeted backdoor framework that localizes the malicious distribution shift to a temporal, in-distribution exposure. TEMPO-Diffusion supports: (i) targeted attacks on and to specific classes, (ii) multiple sub-image backdoors that reconstruct specific features within multiple, different output images and at multiple locations, and (iii) in-painting with time-conditioned triggers. To study relevant, practical security concerns in leveraging backdoored diffusion models for synthetic training data, we also introduce CALISA: a balanced, region-aware traffic-sign dataset emphasizing Canadian and U.S. road signs. Across CIFAR10, GTSRB, and CALISA, our experiments show that TEMPO-Diffusion can reliably poison class-specific synthetic data generation and induce high attack success rates in downstream classifiers trained on that data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TEMPO-Diffusion, a targeted backdoor framework for diffusion models that localizes malicious distribution shifts to temporal, in-distribution exposures via time-conditioned triggers. It claims support for targeted class-specific attacks, multiple sub-image backdoors reconstructing specific features at multiple locations, and in-painting. The work introduces the CALISA dataset (balanced, region-aware traffic signs) and reports that experiments on CIFAR10, GTSRB, and CALISA show reliable poisoning of class-specific synthetic data with high attack success rates in downstream classifiers trained on the poisoned outputs.
Significance. If the empirical claims hold with proper controls and metrics, the work would highlight a practical security risk in using diffusion models to generate synthetic training data for classifiers, extending backdoor concerns to temporally localized, in-distribution triggers. The introduction of CALISA provides a new benchmark for region-aware traffic-sign tasks.
major comments (1)
- [Abstract] Abstract: The central claims of reliable poisoning and high attack success rates across CIFAR10, GTSRB, and CALISA are asserted without any experimental details, metrics (e.g., ASR values, clean accuracy), baselines, controls, or ablation results on temporal localization; this prevents evaluation of whether the time-conditioned triggers remain in-distribution and undetectable.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of reliable poisoning and high attack success rates across CIFAR10, GTSRB, and CALISA are asserted without any experimental details, metrics (e.g., ASR values, clean accuracy), baselines, controls, or ablation results on temporal localization; this prevents evaluation of whether the time-conditioned triggers remain in-distribution and undetectable.
Authors: We acknowledge that the provided abstract is concise and does not include specific numerical results, baselines, or references to ablations. In the revised version we will expand the abstract to include key metrics (ASR and clean accuracy values from the experiments), a brief note on the controls, and an explicit reference to the temporal-localization ablations. The full experimental details, baselines, metrics, and ablations demonstrating that the time-conditioned triggers remain in-distribution are already contained in Sections 4 and 5; the abstract revision will simply surface these results for readers evaluating the claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
This is an empirical security/attack paper describing a new backdoor framework (TEMPO-Diffusion) for diffusion models, with targeted class attacks, multi-feature backdoors, time-conditioned in-painting, and downstream ASR evaluation on CIFAR10/GTSRB/CALISA. The provided text contains no mathematical derivations, no equations, no fitted parameters renamed as predictions, and no self-citation chains. Central claims rest on experimental results rather than any derivation that reduces to its own inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: 2024 21st Annual International Conference on Privacy, Security and Trust (PST)
Aiken, W., Branco, P., Jourdan, G.V.: DevilDiffusion: Embedding hidden noise backdoors into diffusion models. In: 2024 21st Annual International Conference on Privacy, Security and Trust (PST). pp. 1–11 (2024).https://doi.org/10.1109/ PST62714.2024.10788056
arXiv 2024
-
[2]
In: Advances and Trends in Artificial Intelligence
Aiken, W., Branco, P., Jourdan, G.V.: Lost in the noise: Evading and de- tecting backdoors in conditional diffusion models. In: Advances and Trends in Artificial Intelligence. Theory and Applications. pp. 481–493. Springer Na- ture Singapore, Singapore (2026).https://doi.org/https://doi.org/10.1007/ 978-981-96-8889-0_41
2026
-
[3]
Phase-informed bayesian ensemble models improve performance of covid-19 forecasts,
An, S., Chou, S.Y., Zhang, K., Xu, Q., Tao, G., Shen, G., Cheng, S., Ma, S., Chen,P.Y.,Ho,T.Y.,Zhang,X.:Elijah:Eliminatingbackdoorsinjectedindiffusion models via distribution shift. Proceedings of the AAAI Conference on Artificial TEMPO-Diffusion 17 Intelligence38(10), 10847–10855 (Mar 2024).https://doi.org/10.1609/aaai. v38i10.28958
-
[4]
Transactions on Machine Learn- ing Research (2023),https://openreview.net/forum?id=DlRsoxjyPm
Azizi, S., Kornblith, S., Saharia, C., Norouzi, M., Fleet, D.J.: Synthetic data from diffusion models improves imagenet classification. Transactions on Machine Learn- ing Research (2023),https://openreview.net/forum?id=DlRsoxjyPm
2023
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Bhosale, M., Wasi, A., Zhai, Y., Tian, Y., Border, S., Xi, N., Sarder, P., Yuan, J., Doermann, D., Gong, X.: PathDiff: Histopathology image synthesis with un- paired text and mask conditions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22415–22424 (October 2025)
2025
-
[6]
In: SAE Technical Paper 2023-01-7046
Bie, X., Zhang, S., Meng, C., Mei, J., Li, J., He, X.: Synthetic data for 2D road marking detection in autonomous driving. In: SAE Technical Paper 2023-01-7046. pp. 1–10. SAE International (2023).https://doi.org/10.4271/2023-01-7046, presented at the SAE 2023 Intelligent and Connected Vehicles Symposium
-
[7]
Master’s thesis, Linköping University, Computer Vision (2023)
Carlson, J., Byman, L.: Generation of Synthetic Traffic Sign Images using Diffusion Models. Master’s thesis, Linköping University, Computer Vision (2023)
2023
-
[8]
In: 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)
Chen, W., Song, D., Li, B.: TrojDiff: Trojan attacks on diffusion models with diverse targets. In: 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR). pp. 4035–4044 (2023).https://doi.org/10.1109/ CVPR52729.2023.00393
arXiv 2023
-
[9]
Chen, X., Liu, C., Li, B., Lu, K., Song, D.: Targeted backdoor attacks on deep learning systems using data poisoning (2017), arXiv preprint arXiv:1712.05526
Pith/arXiv arXiv 2017
-
[10]
Chou, S.Y., Chen, P.Y., Ho, T.Y.: How to backdoor diffusion models? In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4015–4024 (2023).https://doi.org/10.1109/CVPR52729.2023.00391
-
[11]
Advances in Neural Information Processing Sys- tems36(2024), available:https://papers.nips.cc/paper_files/paper/2023/ hash/6b055b95d689b1f704d8f92191cdb788-Abstract-Conference.html
Chou, S.Y., Chen, P.Y., Ho, T.Y.: VillanDiffusion: A unified backdoor attack framework for diffusion models. Advances in Neural Information Processing Sys- tems36(2024), available:https://papers.nips.cc/paper_files/paper/2023/ hash/6b055b95d689b1f704d8f92191cdb788-Abstract-Conference.html
2024
-
[12]
Dai,W.,Lu,L.,Li,Z.:Diffusion-basedsyntheticdatagenerationforvisible-infrared person re-identification. Proceedings of the AAAI Conference on Artificial Intelli- gence39(11), 11185–11193 (Apr 2025).https://doi.org/10.1609/aaai.v39i11. 33216
-
[13]
Vietnam Journal of Computer Science09(03), 333–348 (2022),https://doi.org/10.1142/S2196888822500191
Dewi, C., Chen, R.C., Liu, Y.T.: Synthetic traffic sign image generation applying generative adversarial networks. Vietnam Journal of Computer Science09(03), 333–348 (2022),https://doi.org/10.1142/S2196888822500191
-
[14]
Ertler, C., Mislej, J., Ollmann, T., Porzi, L., Neuhold, G., Kuang, Y.: The Map- illary traffic sign dataset for detection and classification on a global scale. In: Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIII. p. 68–84. Springer-Verlag, Berlin, Heidel- berg (2020).https://doi.org/10.1007/...
-
[15]
In: Pro- ceedings of the 37th International Conference on Neural Information Processing Systems
Fang, G., Ma, X., Wang, X.: Structural pruning for diffusion models. In: Pro- ceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023)
2023
-
[16]
arXiv preprint arXiv:2303.18037 (2023)
Ge, J.: Traffic sign recognition dataset and data augmentation. arXiv preprint arXiv:2303.18037 (2023)
arXiv 2023
-
[17]
IEEE Access7, 47230–47244 (2019).https: //doi.org/10.1109/ACCESS.2019.2909068
Gu, T., Liu, K., Dolan-Gavitt, B., Garg, S.: BadNets: Evaluating backdooring attacks on deep neural networks. IEEE Access7, 47230–47244 (2019).https: //doi.org/10.1109/ACCESS.2019.2909068
-
[18]
Guan, Z., Hu, M., Li, S., Vullikanti, A.K.: Ufid: a unified framework for black-box input-level backdoor detection on diffusion models. In: Proceedings of the Thirty- Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference 18 W. Aiken et al. on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational...
-
[19]
doi:10.1109/CVPR52734.2025.00499
Han, Y., Zhao, B., Chu, R., Luo, F., Sikdar, B., Lao, Y.: UIBDiffusion: Univer- sal imperceptible backdoor attack for diffusion models. In: 2025 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 19186–19196 (2025).https://doi.org/10.1109/CVPR52734.2025.01787
-
[20]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
2016
-
[21]
https: //doi.org/10.5555/3495724.3496298
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Ad- vances in neural information processing systems33, 6840–6851 (2020), doi: 10.5555/3495724.3496298
-
[22]
In: 2025 IEEE International Con- ference on Multimedia and Expo (ICME)
Jiang, H., Xiao, J., Hu, X., Chen, T., Zhao, J.: Diff-Cleanse: Identifying and mit- igating backdoor attacks in diffusion models. In: 2025 IEEE International Con- ference on Multimedia and Expo (ICME). pp. 1–6 (2025).https://doi.org/10. 1109/ICME59968.2025.11210014
arXiv 2025
-
[23]
Technical Report (2009), available:https://www.cs.toronto.edu/~kriz/ cifar.html
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images. Technical Report (2009), available:https://www.cs.toronto.edu/~kriz/ cifar.html
2009
-
[24]
Nature Medicine30(4), 1166–1173 (2024).https://doi.org/10.1038/s41591-024-02838-6
Ktena, I., Wiles, O., Albuquerque, I., Rebuffi, S.A., Tanno, R., Roy, A.G., Azizi, S., Belgrave, D., Kohli, P., Cemgil, T., et al.: Generative models improve fairness of medical classifiers under distribution shifts. Nature Medicine30(4), 1166–1173 (2024).https://doi.org/10.1038/s41591-024-02838-6
-
[25]
Li, S., Ma, J., Cheng, M.: Learnable invisible backdoor for diffusion models (2024), available:https://openreview.net/forum?id=scFfMOOGD8
2024
-
[26]
In: Proceedings of the 36th International Conference on Neural Information Processing Systems
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: DPM-solver: a fast ODE solver for diffusion probabilistic model sampling in around 10 steps. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. NIPS ’22, Curran Associates Inc., Red Hook, NY, USA (2022),https://dl.acm.org/ doi/10.5555/3600270.3600688
-
[27]
Machine Intelligence Research 22(4), 730–751 (2025).https://doi.org/10.1007/s11633-025-1562-4
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: DPM-Solver++: Fast solver for guided sampling of diffusion probabilistic models. Machine Intelligence Research 22(4), 730–751 (2025).https://doi.org/10.1007/s11633-025-1562-4
-
[28]
In: International Conference on Learning Representations (2018),https://openreview.net/forum?id=rJzIBfZAb
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks. In: International Conference on Learning Representations (2018),https://openreview.net/forum?id=rJzIBfZAb
2018
-
[29]
IEEE Transactions on Intelligent Transportation Systems13(4), 1484–1497 (2012)
Mogelmose, A., Trivedi, M.M., Moeslund, T.B.: Vision-based traffic sign detec- tion and analysis for intelligent driver assistance systems: Perspectives and survey. IEEE Transactions on Intelligent Transportation Systems13(4), 1484–1497 (2012). https://doi.org/10.1109/TITS.2012.2209421
-
[30]
Rahimi, P., Teney, D., Marcel, S.: AugGen: Synthetic augmentation using diffusion modelscanimproverecognition.In:TheThirty-ninthAnnualConferenceonNeural Information Processing Systems (2025)
2025
-
[31]
Computer Optics40(2), 294–300 (2016).https://doi.org/10.18287/ 2412-6179-2016-40-2-294-300
Shakhuro, V.I., Konushin, A.S.: Russian traffic sign images dataset. Computer Optics40(2), 294–300 (2016).https://doi.org/10.18287/ 2412-6179-2016-40-2-294-300
2016
-
[32]
Song,J.,Meng,C.,Ermon,S.:Denoisingdiffusionimplicitmodels.In:International Conferenceon LearningRepresentations(2021),https://openreview.net/forum? id=St1giarCHLP TEMPO-Diffusion 19
2021
-
[33]
doi: 10.1016/j.neunet.2012.02.016
Stallkamp, J., Schlipsing, M., Salmen, J., Igel, C.: Man vs. computer: Bench- marking machine learning algorithms for traffic sign recognition. Neural Networks (2012), doi: 10.1016/j.neunet.2012.02.016
-
[34]
Transactions on Machine Learning Research (2025),https://openreview.net/ forum?id=SfqCaAOF1S
Sui, Y., Phan, H., Xiao, J., Zhang, T., Tang, Z., Shi, C., Wang, Y., Chen, Y., Yuan, B.: DisDet: Exploring detectability of backdoor attack on diffusion models. Transactions on Machine Learning Research (2025),https://openreview.net/ forum?id=SfqCaAOF1S
2025
-
[35]
In: 2019 International Joint Conference on Neural Networks (IJCNN)
Torres, L.T., Paixão, T.M., Berriel, R.F., De Souza, A.F., Badue, C., Sebe, N., Oliveira-Santos, T.: Effortless deep training for traffic sign detection using tem- plates and arbitrary natural images. In: 2019 International Joint Conference on Neural Networks (IJCNN). pp. 1–7 (2019).https://doi.org/10.1109/IJCNN. 2019.8852086
-
[36]
arXiv preprint arXiv.1912.02771 (2019)
Turner, A., Tsipras, D., Madry, A.: Label-consistent backdoor attacks. arXiv preprint arXiv.1912.02771 (2019)
arXiv 1912
-
[37]
In: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Valvano, G., Agostino, A., De Magistris, G., Graziano, A., Veneri, G.: Control- lable image synthesis of industrial data using stable diffusion. In: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 5342–5351 (2024).https://doi.org/10.1109/WACV57701.2024.00527
-
[38]
arXiv preprint arXiv:2204.13902 (2022)
Zhang, Q., Chen, Y.: Fast sampling of diffusion models with exponential integrator. arXiv preprint arXiv:2204.13902 (2022)
arXiv 2022
-
[39]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Zhao, W., Bai, L., Rao, Y., Zhou, J., Lu, J.: UniPC: A unified predictor- corrector framework for fast sampling of diffusion models. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neu- ral Information Processing Systems. vol. 36, pp. 49842–49869. Curran Associates, Inc. (2023),https://proceedings.neurips.cc/pa...
2023
-
[40]
In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zhu, Z., Liang, D., Zhang, S., Huang, X., Li, B., Hu, S.: Traffic-sign detection and classification in the wild. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2110–2118 (2016).https://doi.org/10.1109/ CVPR.2016.232 A CALISA Dataset Details Despite the abundance of large vision datasets, datasets for the detection and clas...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.