textsc{DiARC}: Distinguishing Positive and Negative Samples Helps Improving ARC-like Reasoning Ability of Large Language Models
Pith reviewed 2026-06-26 05:30 UTC · model grok-4.3
The pith
Distinguishing negative samples improves large language models on ARC-like grid reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
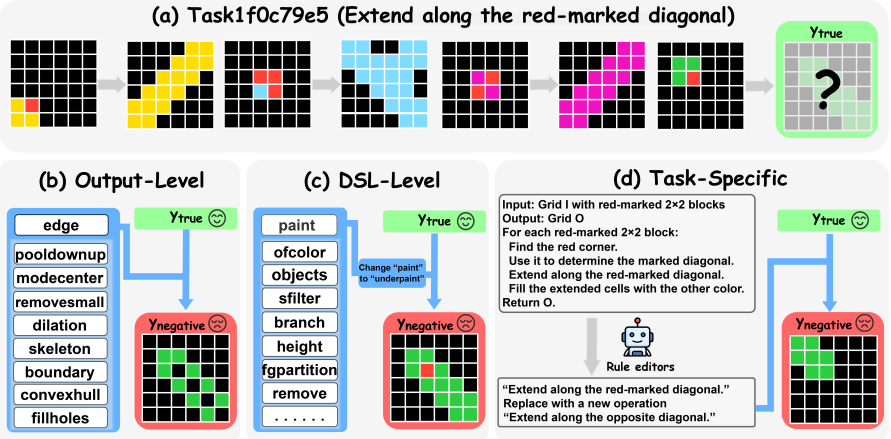
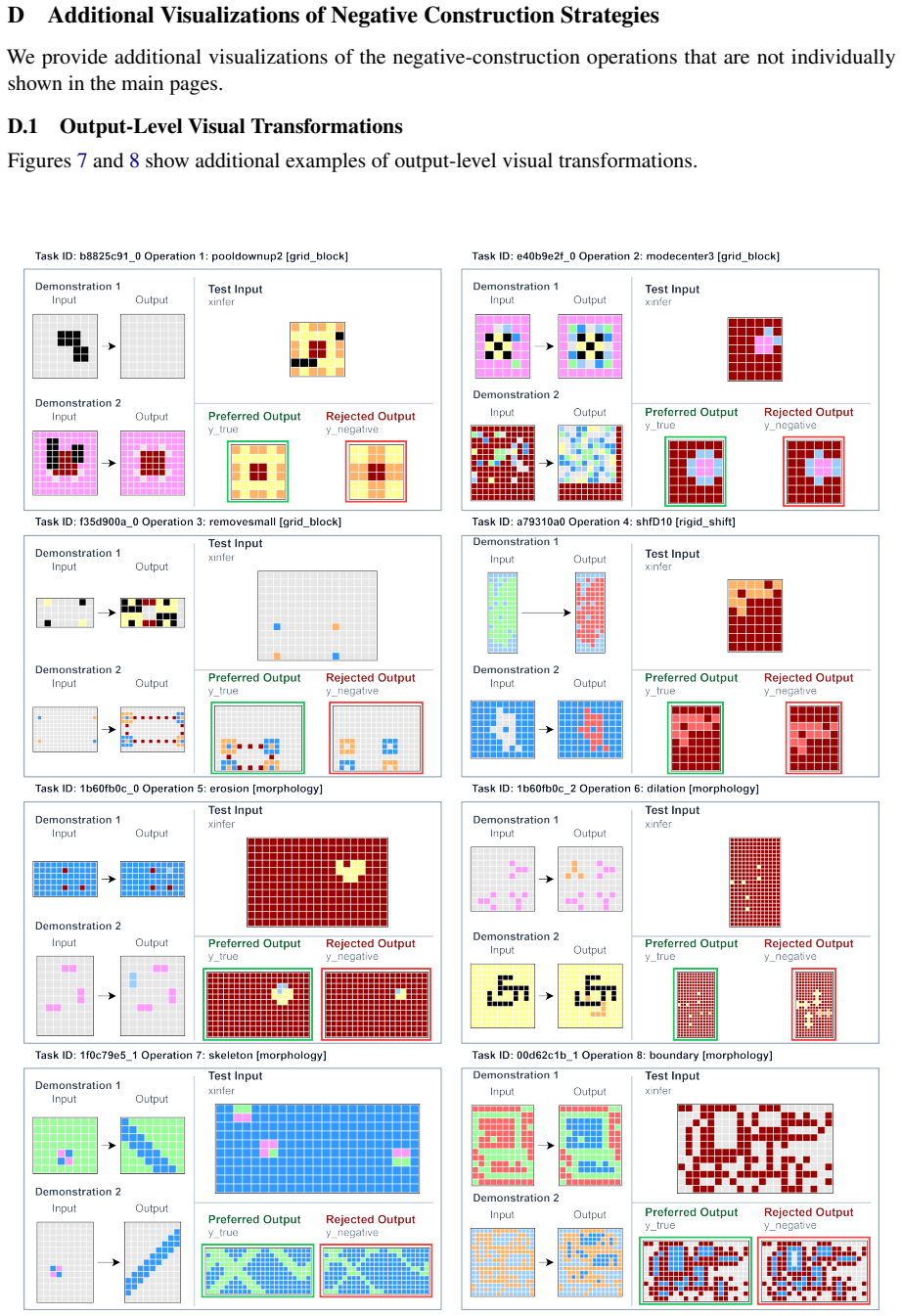
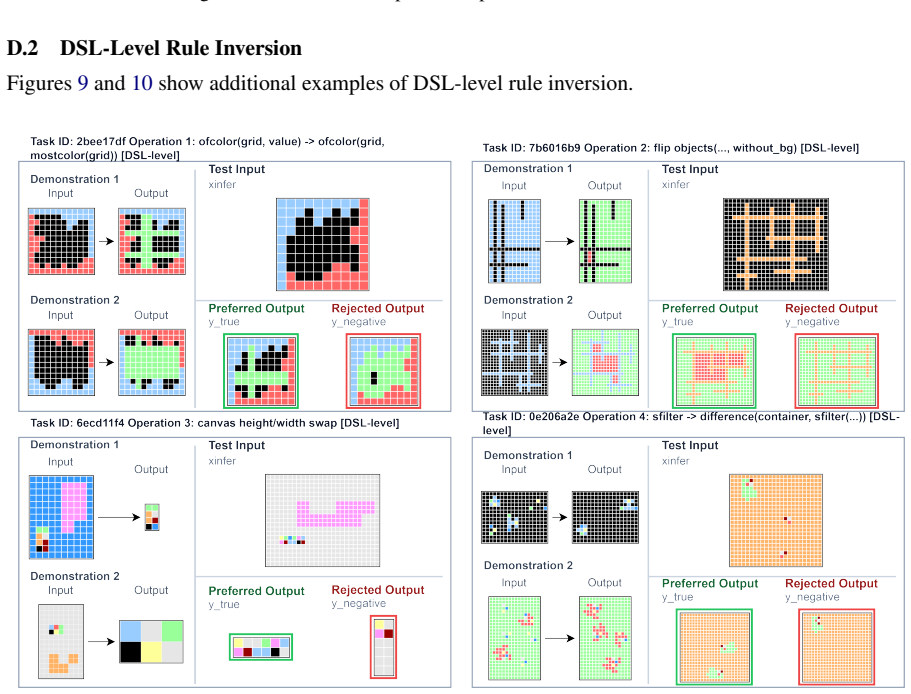
ARC-like reasoning improves when models are trained not only on correct input-output pairs but also on preference pairs that contrast those correct pairs against three classes of constructed negatives: output-level visual transformations, DSL-level rule inversions, and task-specific rule edits. The negatives supply near-miss alternatives without altering the observed demonstrations, enabling the model to learn distinctions that positive supervision alone does not provide.
What carries the argument
Preference pairs formed from positive demonstrations and three types of negative samples (visual output transforms, DSL rule inversions, task-specific rule edits) that serve as near-miss contrasts for alignment training.
If this is right
- Models learn to avoid specific classes of errors common in grid pattern prediction.
- Reasoning gains occur while the original few-shot demonstrations remain unchanged.
- The same construction methods apply across multiple ARC-style benchmarks with consistent effect.
- Open-source models can close part of the gap to closed-source approaches without extra data augmentation.
Where Pith is reading between the lines
- The same preference-pair idea might extend to other few-shot abstraction tasks that currently rely only on positive examples.
- If the three negative-construction methods prove complementary, future work could combine them systematically rather than choosing one.
- The approach suggests that explicit contrastive signals may be more efficient than scaling model size alone for this class of problems.
Load-bearing premise
The constructed negative samples function as useful near-misses that genuinely help the model separate good from bad reasoning rather than adding noise or confusion.
What would settle it
Train identical models on the same ARC-like data with and without the DiARC preference pairs; if accuracy on held-out tasks shows no reliable improvement when the pairs are included, the central claim does not hold.
Figures







read the original abstract
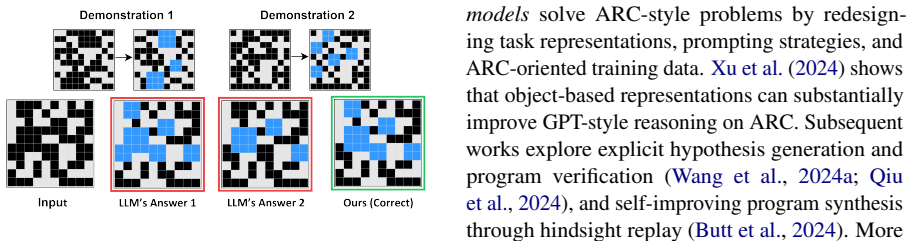
The Abstraction and Reasoning Corpus (ARC;~\citealp{chollet2019measure}) contains tasks that require summarizing patterns from limited grid samples and predicting output grids. Recently, many large language model based approaches have attempted to transform it into a text-based reasoning task. However, methods based on open-source models have generally yielded unsatisfactory results, while those relying on closed-source models are too costly. Current efforts mainly focus on data augmentation, constructing ARC-like data for more comprehensive supervised fine-tuning. In this work, we argue that solving ARC-like problems requires not only \textit{positive} sample supervision but also the ability to improve model reasoning by distinguishing \textit{negative} samples. To this end, we draw on the idea of preference alignment and propose \textsc{DiARC}, a method that constructs preference pairs to enable the model to distinguish between them. Specifically, we propose three ways to construct negative samples, including output-level visual transformations, DSL-level rule inversion, and task-specific rule editing. The resulting negative samples provide informative near-miss alternatives while keeping the observed demonstrations unchanged. Experimental results across multiple ARC-like benchmarks show that \textsc{DiARC} consistently improves performance over baseline models. The code is released at https://github.com/szu-tera/DiARC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that ARC-like reasoning in LLMs requires distinguishing negative samples in addition to positive supervision, and introduces DiARC to construct preference pairs via three negative-sample methods (output-level visual transformations, DSL-level rule inversion, task-specific rule editing). These negatives are asserted to be informative near-miss alternatives that leave demonstrations unchanged, yielding consistent performance gains over baselines across ARC-like benchmarks, with code released.
Significance. If the results hold and the negatives function as near-misses that specifically improve reasoning distinctions, the work could meaningfully advance open-source LLM approaches to abstract reasoning tasks by moving beyond pure supervised fine-tuning and data augmentation, while addressing cost barriers of closed models. The public code release at https://github.com/szu-tera/DiARC is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the assertion that the three negative-sample constructions 'provide informative near-miss alternatives' is central to the hypothesized mechanism but is presented without any supporting verification (e.g., similarity metrics, edit distances, or comparison against random negatives), leaving open whether gains arise from the claimed distinction process or from generic preference-tuning effects.
- [§4] §4 (experiments): the claim of 'consistent improvement' over baselines lacks reported statistical tests, precise baseline definitions, or ablations isolating each of the three negative-construction methods, so the load-bearing attribution to negative-sample distinction cannot be evaluated from the presented evidence.
minor comments (1)
- [Abstract] The specific ARC-like benchmarks used are referenced only generically in the abstract; §4 should explicitly list dataset names, sizes, and citations for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the three negative-sample constructions 'provide informative near-miss alternatives' is central to the hypothesized mechanism but is presented without any supporting verification (e.g., similarity metrics, edit distances, or comparison against random negatives), leaving open whether gains arise from the claimed distinction process or from generic preference-tuning effects.
Authors: We agree that quantitative verification of the near-miss property would better support the central hypothesis. In the revision we will add similarity analyses (grid edit distances, DSL rule edit distances, and comparisons against randomly generated negatives) to demonstrate that the constructed negatives are systematically closer to the positives than random alternatives. revision: yes
-
Referee: [§4] §4 (experiments): the claim of 'consistent improvement' over baselines lacks reported statistical tests, precise baseline definitions, or ablations isolating each of the three negative-construction methods, so the load-bearing attribution to negative-sample distinction cannot be evaluated from the presented evidence.
Authors: We acknowledge that the current experimental section would benefit from greater rigor. The revised manuscript will report statistical significance tests with p-values, provide explicit definitions and implementation details for all baselines, and include ablation experiments that isolate the contribution of each of the three negative-sample construction methods. revision: yes
Circularity Check
No circularity; empirical method with independent experimental grounding
full rationale
The paper proposes three constructions for negative samples (output-level visual transformations, DSL-level rule inversion, task-specific rule editing) and reports empirical gains on ARC-like benchmarks via preference alignment. No equations, fitted parameters, or derivations appear in the provided text. The central claim rests on external benchmark comparisons rather than any quantity defined by the method itself. No self-citation chains, uniqueness theorems, or ansatzes are invoked to force the result. The derivation chain is self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Preference alignment on positive and negative output pairs improves model reasoning on ARC-like tasks
Reference graph
Works this paper leans on
-
[1]
Yang, Jingfeng and Jin, Hongye and Tang, Ruixiang and Han, Xiaotian and Feng, Qizhang and Jiang, Haoming and Zhong, Shaochen and Yin, Bing and Hu, Xia , title =. ACM Trans. Knowl. Discov. Data , month = apr, articleno =. 2024 , issue_date =. doi:10.1145/3649506 , abstract =
-
[2]
Educational Psychology Review , volume =
Conditions for Effective Learning from Erroneous Examples: A Systematic Review , author =. Educational Psychology Review , volume =. 2025 , doi =
2025
-
[3]
arXiv preprint arXiv:2406.18629 , year=
Step-dpo: Step-wise preference optimization for long-chain reasoning of llms , author=. arXiv preprint arXiv:2406.18629 , year=
-
[4]
Step-Controlled
Zimu Lu and Aojun Zhou and Ke Wang and Houxing Ren and Weikang Shi and Yunqiao Yang and Junting Pan and Mingjie Zhan and Hongsheng Li , journal=. Step-Controlled. 2025 , url=
2025
-
[5]
Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 , pages =
Kim, Sejin and Choi, Hayan and Lee, Seokki and Kim, Sundong , title =. Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 , pages =. 2026 , isbn =. doi:10.1145/3770854.3785683 , abstract =
-
[6]
NeurIPS 2022 Workshop on Neuro Causal and Symbolic AI (nCSI) , year=
Playgrounds for Abstraction and Reasoning , author=. NeurIPS 2022 Workshop on Neuro Causal and Symbolic AI (nCSI) , year=
2022
-
[7]
arXiv preprint arXiv:2603.13372 , year=
The ARC of Progress towards AGI: A Living Survey of Abstraction and Reasoning , author=. arXiv preprint arXiv:2603.13372 , year=
-
[8]
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Ahn, Janice and Verma, Rishu and Lou, Renze and Liu, Di and Zhang, Rui and Yin, Wenpeng. Large Language Models for Mathematical Reasoning: Progresses and Challenges. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop. 2024. doi:10.18653/v1/2024.eacl-srw.17
-
[9]
arXiv preprint arXiv:1911.01547 , url=
On the measure of intelligence , author=. arXiv preprint arXiv:1911.01547 , url=
Pith/arXiv arXiv 1911
-
[10]
arXiv preprint arXiv:2404.07353 , url=
Addressing the abstraction and reasoning corpus via procedural example generation , author=. arXiv preprint arXiv:2404.07353 , url=
-
[11]
Training language models to follow instructions with human feedback , url =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[12]
arXiv preprint arXiv:2511.14761 , url=
ARC Is a Vision Problem! , author=. arXiv preprint arXiv:2511.14761 , url=
-
[13]
ARC Prize - Leaderboard , year =
-
[14]
2025 , url =
NVARC Solution to ARC-AGI-2 2025 , author =. 2025 , url =
2025
-
[15]
2025 , url =
Berman, Jeremy , title =. 2025 , url =
2025
-
[16]
arXiv preprint arXiv:2505.11831 , url=
Arc-agi-2: A new challenge for frontier ai reasoning systems , author=. arXiv preprint arXiv:2505.11831 , url=
-
[17]
Product of Experts with
Daniel Franzen and Jan Disselhoff and David Hartmann , booktitle=. Product of Experts with. 2025 , url=
2025
-
[18]
Annual Review of Psychology , volume =
Learning from Errors , author =. Annual Review of Psychology , volume =. 2017 , url =
2017
-
[19]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , booktitle =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
-
[20]
Scientific Data , volume =
A Comprehensive Behavioral Dataset for the Abstraction and Reasoning Corpus , author =. Scientific Data , volume =. 2025 , url =
2025
-
[21]
ARC-AGI-2 + ARC Prize 2025 is Live! , year =
2025
-
[22]
Claas Beger and Ryan Yi and Shuhao Fu and Arsenii Kirillovich Moskvichev and Sarah Tsai and Sivasankaran Rajamanickam and Melanie Mitchell , year=. Do
-
[23]
and Defferrard, Micha\"
Butt, Natasha and Manczak, Blazej and Wiggers, Auke and Rainone, Corrado and Zhang, David W. and Defferrard, Micha\". Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[24]
Decomposing
Matthew Simpson and Soumya Banerjee , booktitle=. Decomposing. 2026 , url=
2026
-
[25]
Self-Improving Language Models for Evolutionary Program Synthesis: A Case Study on
Pourcel, Julien and Colas, C\'. Self-Improving Language Models for Evolutionary Program Synthesis: A Case Study on. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[26]
2025 , editor =
Li, Weichen and Jan, Albert and Ray, Baishakhi and Yang, Junfeng and Mao, Chengzhi and Pei, Kexin , booktitle =. 2025 , editor =
2025
-
[27]
The Concept
Arsenii Kirillovich Moskvichev and Victor Vikram Odouard and Melanie Mitchell , journal=. The Concept. 2023 , url=
2023
-
[28]
Transactions on Machine Learning Research , issn=
The Curse of CoT: On the Limitations of Chain-of-Thought in In-Context Learning , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[29]
Improving Abstract Reasoning Ability of Large Language Models through Mixture Program-based Data Synthesis
Wang, Yile and Huang, Hui. Improving Abstract Reasoning Ability of Large Language Models through Mixture Program-based Data Synthesis. Proceedings of the 24th C hina National Conference on Computational Linguistics ( CCL 2025). 2025
2025
-
[30]
arXiv preprint arXiv:2506.21734 , url=
Hierarchical reasoning model , author=. arXiv preprint arXiv:2506.21734 , url=
-
[32]
2024 , url=
Yudong Xu and Wenhao Li and Pashootan Vaezipoor and Scott Sanner and Elias Boutros Khalil , journal=. 2024 , url=
2024
-
[33]
arXiv preprint arXiv:2605.19376 , year=
Generative Recursive Reasoning , author=. arXiv preprint arXiv:2605.19376 , year=
-
[34]
Intelligenza Artificiale , volume =
Cédric Mesnage and Xiaoyang Wang and Hang Dong and Aishwaryaprajna , title =. Intelligenza Artificiale , volume =. 2025 , doi =. https://doi.org/10.1177/17248035251363882 , abstract =
-
[35]
arXiv preprint arXiv:2408.11796 , url=
Llm pruning and distillation in practice: The minitron approach , author=. arXiv preprint arXiv:2408.11796 , url=
-
[36]
arXiv preprint arXiv:2407.21783 , url =
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , url =
-
[37]
arXiv preprint arXiv:2505.09388 , url=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , url=
-
[38]
ARC Community Project , year =
-
[39]
arXiv preprint arXiv:2510.04871 , year=
Less is more: Recursive reasoning with tiny networks , author=. arXiv preprint arXiv:2510.04871 , year=
-
[40]
Transactions on Machine Learning Research , issn=
Tackling the Abstraction and Reasoning Corpus with Vision Transformers: the Importance of 2D Representation, Positions, and Objects , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[41]
arXiv preprint arXiv:2602.02156 , year=
LoopViT: Scaling Visual ARC with Looped Transformers , author=. arXiv preprint arXiv:2602.02156 , year=
-
[42]
2024 , url =
OpenAI , title =. 2024 , url =
2024
-
[43]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[44]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[45]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[46]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=. G. 2023 , url=
2023
-
[47]
2024 , url =
Anthropic , title =. 2024 , url =
2024
-
[48]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[49]
2025 , url =
OpenAI , title =. 2025 , url =
2025
-
[50]
2025 , url =
Anthropic , title =. 2025 , url =
2025
-
[51]
arXiv preprint arXiv:2602.02276 , year=
Kimi K2.5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
-
[52]
2026 , url =
OpenAI , title =. 2026 , url =
2026
-
[53]
2025 , url =
xAI , title =. 2025 , url =
2025
-
[54]
arXiv preprint arXiv:1909.08593 , year =
Fine-Tuning Language Models from Human Preferences , author =. arXiv preprint arXiv:1909.08593 , year =
Pith/arXiv arXiv 1909
-
[55]
arXiv preprint arXiv:2204.05862 , year =
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author =. arXiv preprint arXiv:2204.05862 , year =
-
[56]
ORPO : Monolithic Preference Optimization without Reference Model
Hong, Jiwoo and Lee, Noah and Thorne, James. ORPO : Monolithic Preference Optimization without Reference Model. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.626
-
[57]
Yu Meng and Mengzhou Xia and Danqi Chen , booktitle=. Sim. 2024 , url=
2024
-
[58]
arXiv preprint arXiv:2310.05146 , year=
Large language model (llm) as a system of multiple expert agents: An approach to solve the abstraction and reasoning corpus (arc) challenge , author=. arXiv preprint arXiv:2310.05146 , year=
-
[59]
The Twelfth International Conference on Learning Representations , year =
Hypothesis Search: Inductive Reasoning with Language Models , author =. The Twelfth International Conference on Learning Representations , year =
-
[60]
NeurIPS 2024 Workshop on System 2 Reasoning at Scale , year =
Reflection System for the Abstraction and Reasoning Corpus , author =. NeurIPS 2024 Workshop on System 2 Reasoning at Scale , year =
2024
-
[61]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[62]
The Twelfth International Conference on Learning Representations , year=
Phenomenal Yet Puzzling: Testing Inductive Reasoning Capabilities of Language Models with Hypothesis Refinement , author=. The Twelfth International Conference on Learning Representations , year=
-
[63]
ICLR 2024 Workshop: How Far Are We From AGI , year=
Speak It Out: Solving Symbol-Related Problems with Symbol-to-Language Conversion for Language Models , author=. ICLR 2024 Workshop: How Far Are We From AGI , year=
2024
-
[64]
arXiv preprint arXiv:2305.19555 , url=
Large language models are not strong abstract reasoners , author=. arXiv preprint arXiv:2305.19555 , url=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.