Tactile-WAM: Touch-Aware World Action Model with Tactile Asymmetric Attention
Pith reviewed 2026-06-26 05:16 UTC · model grok-4.3
The pith
Tactile-WAM adds touch signals to world action models without degrading visual predictions by using an asymmetric attention mask that hides tactile tokens from video queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
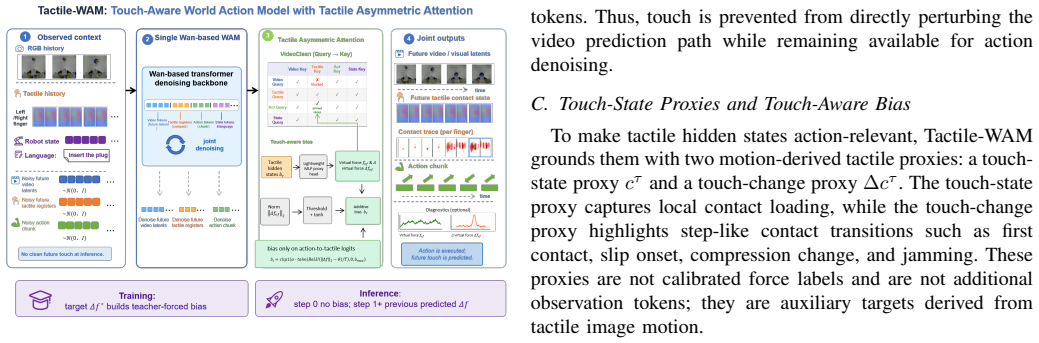
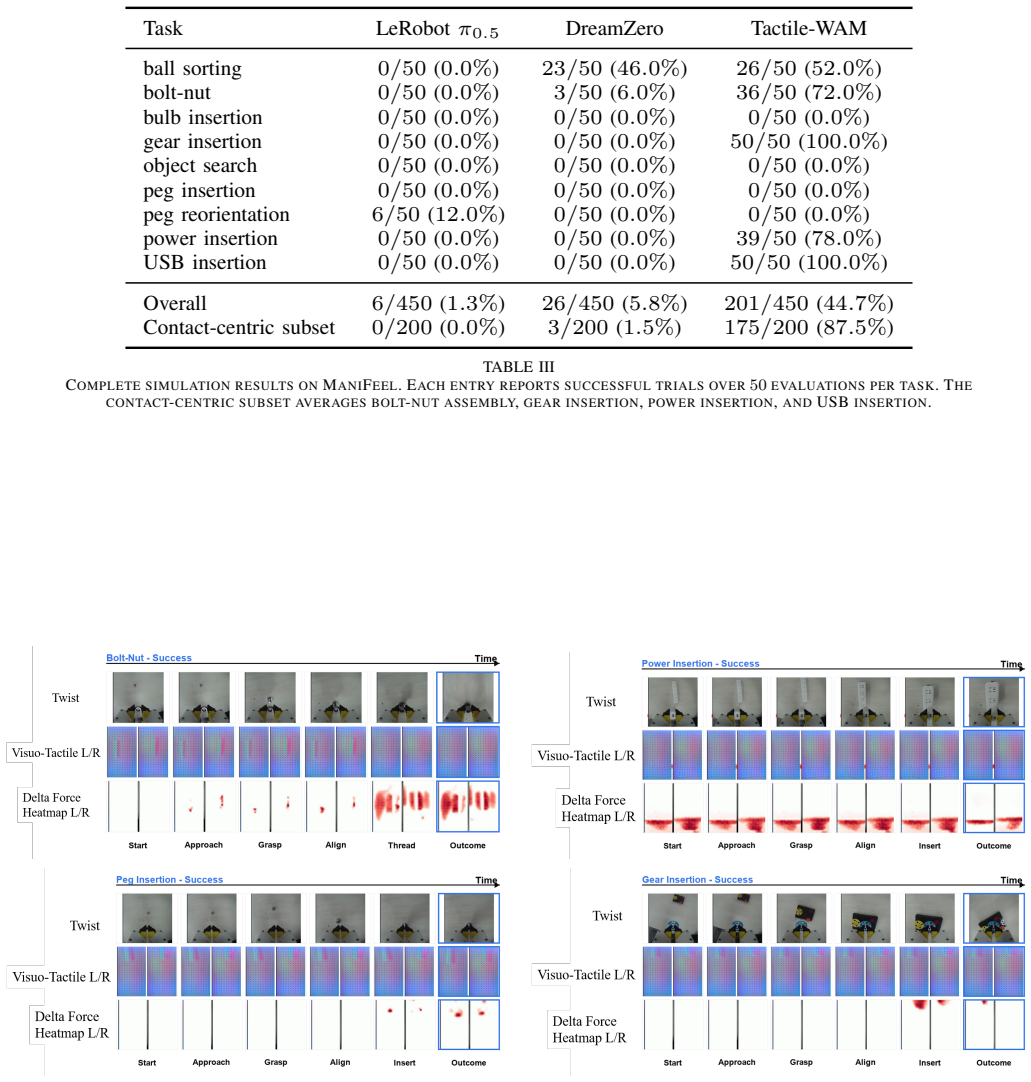
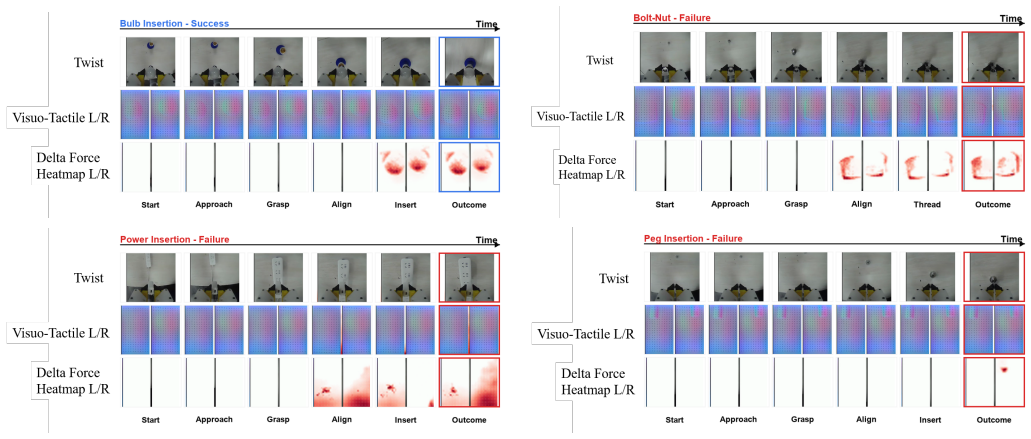
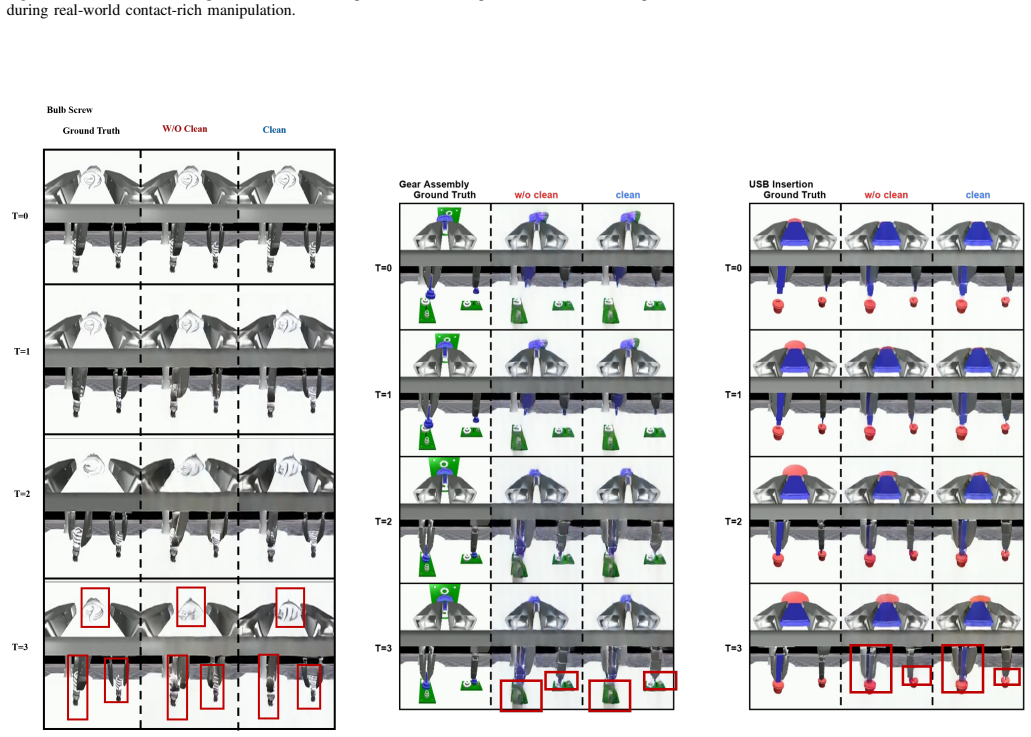
Tactile-WAM is a touch-aware world action model that introduces the Tactile Asymmetric Attention Mechanism (TAAM). TAAM consists of a VideoClean mask that prevents video queries from attending to tactile key/value tokens while preserving action-query access, combined with a touch-aware bias computed from predicted touch changes that modulates action attention to tactile tokens during the denoising process. This design blocks tactile pollution of visual prediction yet keeps contact signals available for action generation. Evaluated on ManiFeel, the model improves mean success rate by 38.9 percent overall and 86 percent on contact-rich tasks.
What carries the argument
Tactile Asymmetric Attention Mechanism (TAAM), which applies a VideoClean mask to isolate tactile tokens from video queries and a touch-aware bias to route contact information selectively to action queries.
If this is right
- Visual future prediction stays accurate while action outputs gain from slip, jamming, and alignment cues.
- Contact-rich skills such as insertion and assembly become more reliable without separate tactile-only modules.
- The same asymmetric mask pattern can be applied to any sparse event-driven sensor modality paired with dense video.
- Denoising-based action generation can now treat predicted touch changes as an explicit attention modulator rather than raw tokens.
Where Pith is reading between the lines
- The VideoClean mask may generalize to other robot modalities where one signal is dense and another is sparse and event-driven.
- If the touch-aware bias proves stable across different diffusion schedulers, it could simplify fusion of any low-dimensional sensor into large video-action models.
- Real-world deployment would still require testing whether the predicted touch changes remain accurate when the robot encounters novel surface properties.
Load-bearing premise
The ManiFeel dataset and its evaluation protocol capture the real difficulties of contact-rich manipulation without hidden tuning advantages.
What would settle it
Running the same Tactile-WAM architecture on an independent contact-rich manipulation dataset or on a physical robot and finding no statistically significant gain over a standard WAM baseline.
Figures





read the original abstract
World Action Models (WAMs) generate actions together with predicted futures, offering a powerful interface for robot decision making. In contact-rich manipulation, however, visually plausible futures can be physically incomplete: insertion, assembly, search, and reorientation often depend on slip, jamming, contact normals, or small alignment errors that are weakly visible or hidden in RGB. A natural solution is to predict future tactile states, however, we identify tactile pollution, a failure mode where unconstrained tactile-token injection degrades video and action prediction by forcing a visual dynamics model to absorb sparse, local, event-driven contact signals. To address this, we propose Tactile-WAM, a touch-aware WAM with a Tactile Asymmetric Attention Mechanism (TAAM). TAAM combines a VideoClean mask, which blocks video-query access to tactile key/value tokens while preserving action-query access, with a touch-aware bias for action attention. The VideoClean mask protects visual prediction while keeping contact information available for action generation; the touch-aware bias is derived from predicted touch changes and modulates action attention to tactile tokens during denoising. On ManiFeel, Tactile-WAM improves the mean success rate by 38.9% overall and by 86% on contact-rich tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tactile-WAM, a World Action Model augmented with a Tactile Asymmetric Attention Mechanism (TAAM) to incorporate tactile sensing into action and future prediction for contact-rich robotic manipulation. TAAM uses a VideoClean mask to prevent tactile tokens from polluting video queries while allowing action queries access, plus a touch-aware bias derived from predicted touch changes that modulates action attention during denoising. The central empirical claim is that this yields a 38.9% mean success-rate improvement overall and 86% on contact-rich tasks on the ManiFeel dataset relative to a baseline WAM.
Significance. If the reported gains are shown to arise specifically from the asymmetric attention design rather than implementation differences, the work would provide a concrete architectural solution to the tactile-pollution problem in multimodal world models. The identification of tactile pollution as a distinct failure mode and the VideoClean + bias mechanism constitute a targeted contribution that could influence future tactile-augmented diffusion or transformer policies in robotics.
major comments (3)
- [Experiments] Experiments section: the baseline WAM is not described with sufficient detail on training schedule, data augmentation, optimizer settings, or inference-time parameters to confirm that the 38.9% and 86% success-rate deltas are attributable to TAAM rather than unstated differences in optimization or evaluation protocol.
- [Experiments] Experiments section, contact-rich task results: the criterion used to partition tasks into the “contact-rich” subset is not stated as an objective, pre-specified rule (e.g., force-threshold or insertion-depth definition); without this, the 86% figure cannot be interpreted as a robust cross-task claim.
- [Method] Method section, TAAM description: the exact functional form of the touch-aware bias (how predicted touch changes are turned into attention modulation weights) and its integration into the denoising schedule are not given as equations, preventing verification that the bias is parameter-free or independent of the visual backbone.
minor comments (2)
- [Abstract] Abstract and Experiments: success-rate tables or figures should include error bars or statistical significance tests across multiple seeds to support the reported percentage improvements.
- [Method] Notation: the distinction between “tactile tokens” and “touch changes” is used without an explicit definition or reference to the tactile encoder output format.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of experimental protocols, task definitions, and methodological details.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the baseline WAM is not described with sufficient detail on training schedule, data augmentation, optimizer settings, or inference-time parameters to confirm that the 38.9% and 86% success-rate deltas are attributable to TAAM rather than unstated differences in optimization or evaluation protocol.
Authors: We agree that the baseline implementation details are insufficiently specified. In the revised manuscript we will add a dedicated subsection (or expanded table) that reports the exact training schedule, data augmentation pipeline, optimizer and learning-rate settings, batch size, number of epochs, and all inference-time parameters (including denoising steps and sampling strategy) used for both the baseline WAM and Tactile-WAM, thereby enabling direct verification that performance differences arise from the TAAM components. revision: yes
-
Referee: [Experiments] Experiments section, contact-rich task results: the criterion used to partition tasks into the “contact-rich” subset is not stated as an objective, pre-specified rule (e.g., force-threshold or insertion-depth definition); without this, the 86% figure cannot be interpreted as a robust cross-task claim.
Authors: We acknowledge that an explicit, objective partitioning rule is required. We will insert a precise definition of the contact-rich subset in the experiments section (e.g., tasks whose ground-truth trajectories exhibit peak contact forces above a stated threshold or require insertion depths greater than X mm) together with the list of tasks that satisfy the criterion, allowing readers to reproduce the 86 % improvement claim. revision: yes
-
Referee: [Method] Method section, TAAM description: the exact functional form of the touch-aware bias (how predicted touch changes are turned into attention modulation weights) and its integration into the denoising schedule are not given as equations, preventing verification that the bias is parameter-free or independent of the visual backbone.
Authors: We will add the missing equations that define the touch-aware bias: specifically, the mapping from predicted touch-change vectors to per-token modulation scalars, the functional form of the bias term, and how it is added to the attention logits inside the denoising U-Net at each timestep. These equations will be presented in the revised Method section so that readers can confirm the bias is parameter-free and operates independently of the visual backbone weights. revision: yes
Circularity Check
No circularity: empirical claims rest on measured dataset outcomes, not self-referential derivations
full rationale
The paper introduces an architectural component (TAAM with VideoClean mask and touch-aware bias) to mitigate tactile pollution in world action models and reports aggregate success-rate improvements on the ManiFeel dataset. No equations, parameter-fitting steps, or derivation chains appear in the provided text. The reported deltas are presented as direct experimental measurements rather than quantities derived from the model inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central contribution is therefore self-contained against external benchmarks and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2410.24164
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, et al.π 0: A vision-language- action flow model for general robot control, 2024. URL https://arxiv.org/abs/2410.24164
Pith/arXiv arXiv 2024
-
[2]
Diffusion policy: Visuomotor policy learning via action diffusion, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2023. URL https://arxiv.org/abs/2303. 04137
2023
-
[3]
Prediction with action: Visual policy learning via joint denoising process, 2024
Yanjiang Guo, Yucheng Hu, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, and Jianyu Chen. Prediction with action: Visual policy learning via joint denoising process, 2024. URL https://arxiv.org/abs/2411. 18179
2024
-
[4]
Sparsh: Self- supervised touch representations for vision-based tactile sensing, 2024
Carolina Higuera, Akash Sharma, Chaithanya Krishna Bodduluri, Taosha Fan, Patrick Lancaster, Mrinal Kalakr- ishnan, Michael Kaess, Byron Boots, Mike Lambeta, Tingfan Wu, and Mustafa Mukadam. Sparsh: Self- supervised touch representations for vision-based tactile sensing, 2024. URL https://arxiv.org/abs/2410.24090
arXiv 2024
-
[5]
Visuo-tactile world models, 2026
Carolina Higuera, Sergio Arnaud, Byron Boots, Mustafa Mukadam, Francois Robert Hogan, and Franziska Meier. Visuo-tactile world models, 2026. URL https://arxiv.org/ abs/2602.06001
arXiv 2026
-
[6]
Video prediction policy: A generalist robot policy with predictive visual represen- tations, 2024
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual represen- tations, 2024. URL https://arxiv.org/abs/2412.14803
Pith/arXiv arXiv 2024
-
[7]
Openvla: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, et al. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv.org/abs/2406.09246
Pith/arXiv arXiv 2024
-
[8]
Most, et al
Mike Lambeta, Po-Wei Chou, Stephen Tian, Brian Yang, Benjamin Maloon, Victoria R. Most, et al. Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation. IEEE Robotics and Automation Letters, 5(3):3838–3845,
-
[9]
doi: 10.1109/LRA.2020.2977257. URL https: //arxiv.org/abs/2005.14679
-
[10]
Rdt-1b: a diffusion foundation model for bimanual manipulation, 2024
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation, 2024. URL https://arxiv.org/abs/ 2410.07864
Pith/arXiv arXiv 2024
-
[11]
Dream-tac: A unified tactile world action model for contact-rich robot manipulation, 2026
Yunfan Lou, Yifan Ye, Yankai Fu, Jun Cen, Xiaowei Chi, Yaoxu Lyu, et al. Dream-tac: A unified tactile world action model for contact-rich robot manipulation, 2026. URL https://arxiv.org/abs/2606.08737
Pith/arXiv arXiv 2026
-
[12]
Manifeel: Benchmark- ing and understanding visuotactile manipulation policy learning, 2025
Quoc-Khanh Luu, Peng Zhou, Zhengtong Xu, Zhiyuan Zhang, Qiang Qiu, and Yu She. Manifeel: Benchmark- ing and understanding visuotactile manipulation policy learning, 2025. URL https://arxiv.org/abs/2505.18472
arXiv 2025
-
[13]
Octo: An open- source generalist robot policy, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, et al. Octo: An open- source generalist robot policy, 2024. URL https://arxiv. org/abs/2405.12213
Pith/arXiv arXiv 2024
-
[14]
Open x-embodiment: Robotic learning datasets and rt-x models, 2023
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Aubrey Lee, et al. Open x-embodiment: Robotic learning datasets and rt-x models, 2023. URL https://arxiv.org/abs/2310.08864
Pith/arXiv arXiv 2023
-
[15]
URL https://arxiv.org/abs/2504.16054
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, et al.π 0.5: A vision-language-action model with open-world general- ization, 2025. URL https://arxiv.org/abs/2504.16054
Pith/arXiv arXiv 2025
-
[16]
Benjamin Ward-Cherrier, Nicholas Pestell, Luke Cram- phorn, Benjamin Winstone, Maria Elena Giannaccini, Jonathan Rossiter, and Nathan F. Lepora. The Tac- Tip family: Soft optical tactile sensors with 3d-printed biomimetic morphologies.Soft Robotics, 5(2):216–227,
-
[17]
doi: 10.1089/soro.2017.0052
-
[18]
Unit: Data efficient tactile representation with generalization to unseen objects, 2024
Zhengtong Xu, Raghava Uppuluri, Xinwei Zhang, Cael Fitch, Philip Glen Crandall, Wan Shou, Dongyi Wang, and Yu She. Unit: Data efficient tactile representation with generalization to unseen objects, 2024. URL https: //arxiv.org/abs/2408.06481
arXiv 2024
-
[19]
Han Xue, Jieji Ren, Wendi Chen, Gu Zhang, Yuan Fang, Guoying Gu, Huazhe Xu, and Cewu Lu. Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation, 2025. URL https://arxiv. org/abs/2503.02881
arXiv 2025
-
[20]
Learning to feel the future: Dreamtacvla for contact-rich manipulation, 2025
Guo Ye, Zexi Zhang, Xu Zhao, Shang Wu, Haoran Lu, Shihan Lu, and Han Liu. Learning to feel the future: Dreamtacvla for contact-rich manipulation, 2025. URL https://arxiv.org/abs/2512.23864
Pith/arXiv arXiv 2025
-
[21]
World action models are zero-shot policies, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, et al. World action models are zero-shot policies, 2026. URL https://arxiv.org/abs/2602.15922
Pith/arXiv arXiv 2026
-
[22]
Vtam: Video-tactile-action models for complex physical interaction beyond vlas,
Haoran Yuan, Weigang Yi, Zhenyu Zhang, Wendi Chen, Yuchen Mo, Jiashi Yin, et al. Vtam: Video-tactile-action models for complex physical interaction beyond vlas,
-
[23]
URL https://arxiv.org/abs/2603.23481
-
[24]
Wenzhen Yuan, Siyuan Dong, and Edward H. Adelson. Gelsight: High-resolution robot tactile sensors for esti- mating geometry and force.Sensors, 17(12):2762, 2017. doi: 10.3390/s17122762. URL https://www.mdpi.com/ 1424-8220/17/12/2762
-
[25]
Tacforesight: Force- guided tactile world model for contact-rich manipulation,
Yujie Zang, Yuhang Zheng, Xian Nie, Yupeng Zheng, Shuai Tian, Songen Gu, Chen Gao, Zining Wang, Shuicheng Yan, and Wenchao Ding. Tacforesight: Force- guided tactile world model for contact-rich manipulation,
-
[26]
URL https://arxiv.org/abs/2606.11184
-
[27]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manip- ulation with low-cost hardware, 2023. URL https://arxiv. org/abs/2304.13705
Pith/arXiv arXiv 2023
-
[28]
Omnivta: Visuo-tactile world modeling for contact-rich robotic manipulation,
Yuhang Zheng, Songen Gu, Weize Li, Yupeng Zheng, Yujie Zang, Shuai Tian, et al. Omnivta: Visuo-tactile world modeling for contact-rich robotic manipulation,
-
[29]
URL https://arxiv.org/abs/2603.19201. APPENDIXA RELATEDWORK a) Generalist manipulation policies and action gener- ation.:Large-scale manipulation policies have made rapid progress through cross-embodiment data, language condi- tioning, and generative action decoders. RT-X/Open X- Embodiment and Octo established broad data-driven policy scaling [13, 12], w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.