OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
Pith reviewed 2026-06-26 05:05 UTC · model grok-4.3
The pith
OPID extracts hierarchical skills from on-policy trajectories to supply dense token-level supervision that supplements sparse outcome rewards in agent RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OPID represents trajectory hindsight as hierarchical skills extracted from on-policy trajectories: episode-level skills capture global workflows or failure-avoidance rules while step-level skills capture local decision knowledge at critical timesteps. A critical-first routing mechanism applies step-level skills when critical decisions are identified and defaults to episode-level skills otherwise. The selected skill is injected into the interaction history so the old policy can re-score the sampled response under both original and skill-augmented contexts; the log-probability shift yields a token-level self-distillation advantage that is added to the outcome advantage for policy optimization.
What carries the argument
The critical-first routing mechanism that selects between step-level and episode-level skills extracted from completed on-policy trajectories, together with the token-level self-distillation advantage computed from the log-probability shift under skill-augmented context.
If this is right
- Agent performance, sample efficiency, and robustness improve on ALFWorld, WebShop, and Search-based QA compared with outcome-only RL and prior skill-distillation methods.
- RL remains the primary training objective while dense, distribution-matched supervision is added at the token level.
- No external skill memories or retrieved privileged context are required because skills come directly from the agent's own on-policy trajectories.
- The combination of hierarchical skill representation and critical-first routing supplies guidance at both global and local decision scales.
Where Pith is reading between the lines
- The same on-policy extraction pattern could be tested in non-language sequential decision tasks where sparse rewards also limit intermediate credit assignment.
- If the routing heuristic generalizes, similar hierarchical distillation might reduce reliance on large external retrieval stores in other agent frameworks.
- The log-probability shift technique offers a concrete way to turn hindsight analysis into an advantage signal without changing the underlying RL algorithm.
Load-bearing premise
Skills extracted from completed trajectories remain distribution-matched to the current policy's state distribution during multi-turn interaction and the critical-first routing correctly identifies when to apply step-level versus episode-level skills.
What would settle it
An experiment in which multi-turn state distributions diverge enough that the injected skills produce a negative distillation advantage and final performance falls below the outcome-only RL baseline.
Figures


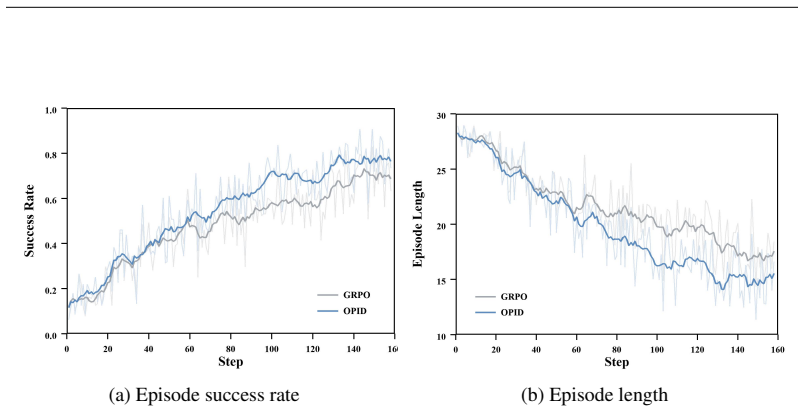
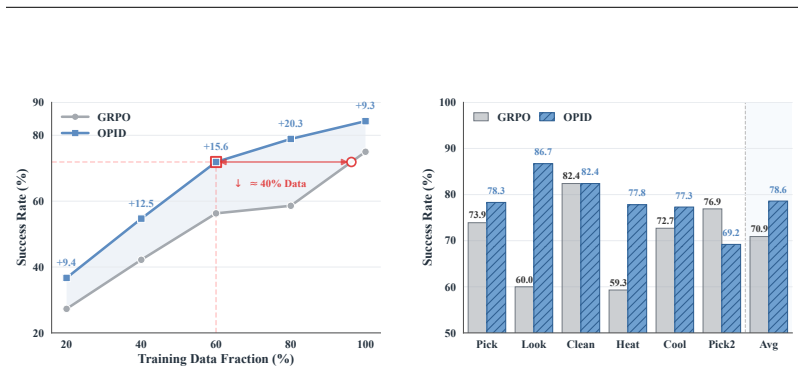


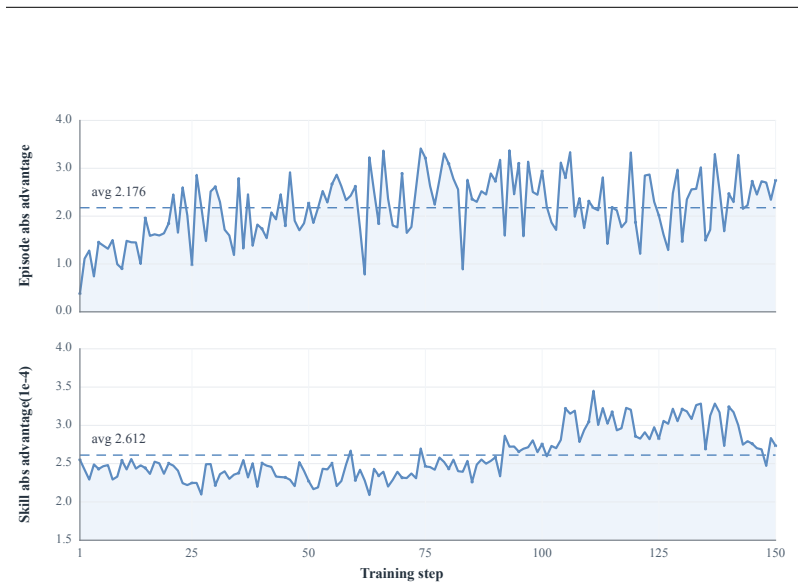







read the original abstract
Outcome-based reinforcement learning provides a stable optimization backbone for language agents, but its sparse trajectory-level rewards provide little guidance on which intermediate decisions should be reinforced or suppressed. On-policy self-distillation offers dense token-level supervision, yet existing skill-conditioned variants often rely on external skill memories or retrieved privileged context, which are costly to maintain and can be mismatched with the state distribution induced by the current policy in multi-turn interaction. We propose \textbf{OPID} (\textbf{O}n-\textbf{P}olicy Sk\textbf{i}ll \textbf{D}istillation), a framework that extracts skill supervision directly from completed on-policy trajectories. OPID represents trajectory hindsight as hierarchical skills: episode-level skills capture global workflows or failure-avoidance rules, while step-level skills capture local decision knowledge at critical timesteps. A critical-first routing mechanism uses step-level skills when critical decisions are identified and falls back to episode-level skills as default guidance otherwise. The selected skill is injected into the interaction history, allowing the old policy to re-score the same sampled response under both original and skill-augmented contexts. The resulting log-probability shift yields a token-level self-distillation advantage, which is combined with the outcome advantage for policy optimization. OPID thus preserves RL as the primary training objective while introducing dense, distribution-matched hindsight supervision. Experiments on ALFWorld, WebShop and Search-based QA demonstrate that OPID generally improves agent performance, sample efficiency, and robustness over outcome-only RL and existing skill-distillation baselines. Our code is available at https://github.com/jinyangwu/OPID/tree/main.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OPID, an on-policy skill distillation method for agentic RL. Skills (episode-level for global workflows and step-level for local decisions) are extracted from completed on-policy trajectories; a critical-first router selects the skill type; the chosen skill is injected into the history; and the log-probability shift between the original and skill-augmented contexts on the identical response supplies a token-level distillation advantage that is added to the outcome advantage for policy optimization. Experiments on ALFWorld, WebShop and Search-based QA report gains in performance, sample efficiency and robustness versus outcome-only RL and prior skill-distillation baselines. Code is released.
Significance. If the distribution-matching property of the token-level advantage holds, OPID supplies a practical route to dense, on-policy hindsight supervision while retaining outcome RL as the primary objective. This could improve training stability and efficiency for multi-turn language agents without external skill stores. The public code release supports reproducibility.
major comments (2)
- [Abstract and method description of advantage construction] Abstract / method description of advantage construction: the token-level advantage is defined directly as the log-probability shift obtained by re-scoring the same sampled response under the original versus skill-injected context drawn from the identical trajectory. This construction is internal to the policy’s own outputs and lacks an external validation or parameter-free derivation showing independence from the outcome signal; the resulting quantity may therefore reduce to a fitted difference rather than independent supervision.
- [Abstract and description of critical-first routing and skill injection] Abstract / description of critical-first routing and skill injection: the claim that the injected skill preserves the original state occupancy measure (and thus on-policy status) is load-bearing for the distribution-matched advantage. Skill injection necessarily alters the context for subsequent turns, and the additional selection step performed by the router is not shown to leave the state distribution unchanged; no derivation or diagnostic is supplied that the post-injection occupancy matches the extraction distribution.
minor comments (2)
- [Abstract] The abstract states that skills are represented as 'hierarchical skills' but provides no concrete description of their format, extraction procedure, or storage; this detail is needed for readers to assess implementation cost and reproducibility.
- [Experimental results] No error bars, run counts, or statistical tests are mentioned in the abstract for the reported improvements; these should be added to the experimental section.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our work. Below we provide point-by-point responses to the major comments. We have revised the manuscript to improve clarity on the advantage construction and the on-policy properties.
read point-by-point responses
-
Referee: [Abstract and method description of advantage construction] Abstract / method description of advantage construction: the token-level advantage is defined directly as the log-probability shift obtained by re-scoring the same sampled response under the original versus skill-injected context drawn from the identical trajectory. This construction is internal to the policy’s own outputs and lacks an external validation or parameter-free derivation showing independence from the outcome signal; the resulting quantity may therefore reduce to a fitted difference rather than independent supervision.
Authors: The token-level advantage is constructed as the difference in log-probabilities for the exact same token sequence under two different conditioning contexts: the original history versus the history augmented with the extracted skill. This difference quantifies the policy's sensitivity to the skill information for that particular response. Because the outcome advantage depends only on the scalar terminal reward while this quantity depends on the full token-level likelihood shift induced by the skill, the two are mathematically distinct. We will revise the method description to explicitly state this separation and include a short derivation showing that the distillation advantage corresponds to an on-policy estimate of the advantage under the skill-conditioned policy, independent of the reward function. Additionally, we will report the correlation between the two advantage signals in the experiments to empirically support their complementarity. revision: partial
-
Referee: [Abstract and description of critical-first routing and skill injection] Abstract / description of critical-first routing and skill injection: the claim that the injected skill preserves the original state occupancy measure (and thus on-policy status) is load-bearing for the distribution-matched advantage. Skill injection necessarily alters the context for subsequent turns, and the additional selection step performed by the router is not shown to leave the state distribution unchanged; no derivation or diagnostic is supplied that the post-injection occupancy matches the extraction distribution.
Authors: We clarify that skill injection and routing are performed exclusively during the offline advantage computation phase on already-collected trajectories; they do not modify the online rollout distribution, which remains strictly on-policy with respect to the current policy parameters. The critical-first router operates on the completed trajectory to decide which skill to extract and inject for re-scoring purposes only. Consequently, the state occupancy measure relevant to policy sampling is unaffected. We acknowledge that the manuscript does not include an explicit derivation or diagnostic plot for the post-injection context distribution, and we will add a dedicated paragraph in Section 3.3 explaining the separation between sampling and advantage computation, along with a small-scale diagnostic verifying that the re-scored responses correspond to states visited under the original policy. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a method in which skills extracted from on-policy trajectories are injected to produce a log-probability shift that is then used as a token-level advantage. This construction is presented explicitly as the source of the dense supervision signal rather than as a derived theorem or prediction that reduces to its own inputs by construction. No equations appear in the provided text that equate a claimed result to a fitted parameter or self-referential definition, and no self-citations are invoked as load-bearing uniqueness theorems. The central claim is supported by experiments on external environments (ALFWorld, WebShop, Search-based QA), rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.03300 , year=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[2]
International Conference on Learning Representations , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. International Conference on Learning Representations , year=
-
[3]
arXiv preprint arXiv:2601.18734 , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
-
[4]
arXiv preprint arXiv:2604.12002 , year=
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision , author=. arXiv preprint arXiv:2604.12002 , year=
-
[5]
arXiv preprint arXiv:2411.18478 , year=
Beyond examples: High-level automated reasoning paradigm in in-context learning via mcts , author=. arXiv preprint arXiv:2411.18478 , year=
-
[6]
arXiv preprint arXiv:2605.22177 , year=
Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles , author=. arXiv preprint arXiv:2605.22177 , year=
-
[7]
The Fourteenth International Conference on Learning Representations , year=
IterResearch: Rethinking Long-Horizon Agents with Interaction Scaling , author=. The Fourteenth International Conference on Learning Representations , year=
-
[8]
arXiv preprint arXiv:2602.05843 , year=
OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions , author=. arXiv preprint arXiv:2602.05843 , year=
-
[9]
arXiv preprint arXiv:2509.02547 , year=
The landscape of agentic reinforcement learning for llms: A survey , author=. arXiv preprint arXiv:2509.02547 , year=
-
[10]
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=
-
[11]
arXiv preprint arXiv:2605.15155 , year=
Self-Distilled Agentic Reinforcement Learning , author=. arXiv preprint arXiv:2605.15155 , year=
-
[12]
arXiv preprint arXiv:2601.20209 , year=
Spark: Strategic Policy-Aware Exploration via Dynamic Branching for Long-Horizon Agentic Learning , author=. arXiv preprint arXiv:2601.20209 , year=
-
[13]
arXiv preprint arXiv:2503.21460 , year=
Large language model agent: A survey on methodology, applications and challenges , author=. arXiv preprint arXiv:2503.21460 , year=
-
[14]
arXiv preprint arXiv:2601.03872 , year=
Atlas: Orchestrating Heterogeneous Models and Tools for Multi-Domain Complex Reasoning , author=. arXiv preprint arXiv:2601.03872 , year=
-
[15]
arXiv preprint arXiv:2604.02268 , year=
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization , author=. arXiv preprint arXiv:2604.02268 , year=
-
[16]
arXiv preprint arXiv:2604.10674 , year=
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents , author=. arXiv preprint arXiv:2604.10674 , year=
-
[17]
arXiv preprint arXiv:2604.03128 , year=
Self-Distilled RLVR , author=. arXiv preprint arXiv:2604.03128 , year=
-
[18]
arXiv preprint arXiv:2601.20802 , year=
Reinforcement Learning via Self-Distillation , author=. arXiv preprint arXiv:2601.20802 , year=
-
[19]
arXiv preprint arXiv:2010.03768 , year=
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , author=. arXiv preprint arXiv:2010.03768 , year=
Pith/arXiv arXiv 2010
-
[20]
Advances in Neural Information Processing Systems , year=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. Advances in Neural Information Processing Systems , year=
-
[21]
arXiv preprint arXiv:2503.09516 , year=
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[22]
arXiv preprint arXiv:2310.06770 , year=
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? , author=. arXiv preprint arXiv:2310.06770 , year=
-
[23]
International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. International Conference on Learning Representations , year=
-
[24]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
Math-Shepherd: Verify and Reinforce LLMs Step-by-Step without Human Annotations , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
-
[25]
arXiv preprint arXiv:2502.01456 , year=
Process Reinforcement through Implicit Rewards , author=. arXiv preprint arXiv:2502.01456 , year=
-
[26]
International Conference on Learning Representations , year=
MiniLLM: Knowledge Distillation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[27]
Advances in Neural Information Processing Systems , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[28]
Transactions on Machine Learning Research , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[29]
arXiv preprint arXiv:2602.08234 , year=
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author=. arXiv preprint arXiv:2602.08234 , year=
-
[30]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[31]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[32]
Transactions of the Association for Computational Linguistics , volume=
Natural Questions: A Benchmark for Question Answering Research , author=. Transactions of the Association for Computational Linguistics , volume=
-
[33]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics , pages=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics , pages=
-
[34]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages=
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages=
-
[35]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[36]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[37]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=
-
[38]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and Narrowing the Compositionality Gap in Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[39]
arXiv preprint arXiv:1503.02531 , year =
Distilling the Knowledge in a Neural Network , author =. arXiv preprint arXiv:1503.02531 , year =. 1503.02531 , archivePrefix =
-
[40]
IEEE Transactions on Information Theory , volume =
Divergence Measures Based on the Shannon Entropy , author =. IEEE Transactions on Information Theory , volume =. 1991 , doi =
1991
-
[41]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages =
Sequence-Level Knowledge Distillation , author =. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages =. 2016 , publisher =
2016
-
[42]
Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , series =
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , author =. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , series =. 2011 , publisher =
2011
-
[43]
Gu, Yuxian and Dong, Li and Wei, Furu and Huang, Minlie , booktitle =
-
[44]
arXiv preprint arXiv:1707.06347 , year =
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =. 1707.06347 , archivePrefix =
-
[45]
The Annals of Mathematical Statistics , volume =
On Information and Sufficiency , author =. The Annals of Mathematical Statistics , volume =. 1951 , doi =
1951
-
[46]
2026 , eprint =
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author =. 2026 , eprint =
2026
-
[47]
Thinking Machines Lab: Connectionism , year =
On-Policy Distillation , author =. Thinking Machines Lab: Connectionism , year =
-
[48]
arXiv preprint arXiv:2604.13016 , year =
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author =. arXiv preprint arXiv:2604.13016 , year =
-
[49]
arXiv preprint arXiv:2603.25562 , year =
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author =. arXiv preprint arXiv:2603.25562 , year =
-
[50]
arXiv preprint arXiv:2602.12275 , year =
On-Policy Context Distillation for Language Models , author =. arXiv preprint arXiv:2602.12275 , year =
-
[51]
Oh, Minjae and Song, Sangjun and Choi, Gyubin and Choi, Yunho and Jo, Yohan , journal =
-
[52]
2026 , month = jun, day =
2026
-
[53]
arXiv preprint arXiv:2601.05524 , year=
Double: Breaking the Acceleration Limit via Double Retrieval Speculative Parallelism , author=. arXiv preprint arXiv:2601.05524 , year=
-
[54]
arXiv preprint arXiv:2605.06234 , year=
RobotEQ: Transitioning from Passive Intelligence to Active Intelligence in Embodied AI , author=. arXiv preprint arXiv:2605.06234 , year=
-
[55]
arXiv preprint arXiv:2308.03688 , year=
AgentBench: Evaluating LLMs as Agents , author=. arXiv preprint arXiv:2308.03688 , year=
-
[56]
arXiv preprint arXiv:2307.13854 , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. arXiv preprint arXiv:2307.13854 , year=
-
[57]
arXiv preprint arXiv:2306.06070 , year=
Mind2Web: Towards a Generalist Agent for the Web , author=. arXiv preprint arXiv:2306.06070 , year=
-
[58]
arXiv preprint arXiv:2401.13649 , year=
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , author=. arXiv preprint arXiv:2401.13649 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.