Improving Vision-Language-Action Model Fine-Tuning with Structured Stage and Keyframe Supervision
Pith reviewed 2026-06-26 04:55 UTC · model grok-4.3
The pith
Structured stage and keyframe supervision derived automatically from gripper states improves VLA fine-tuning success rates on robotic manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
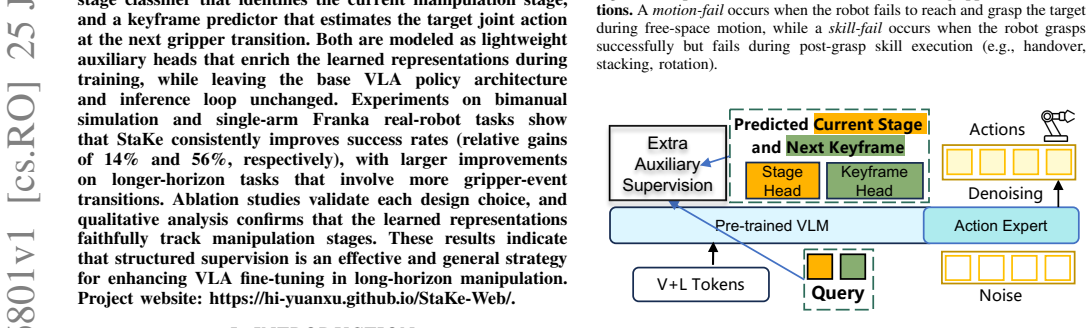
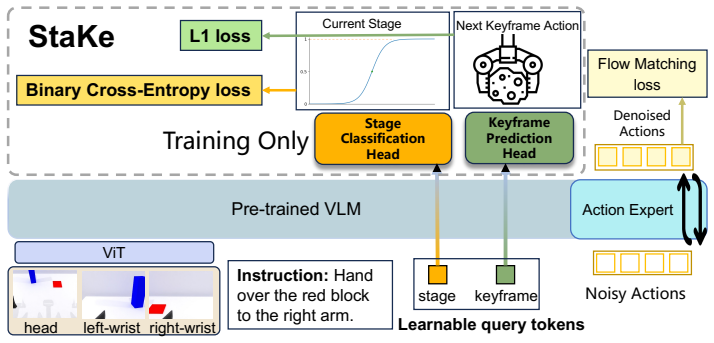
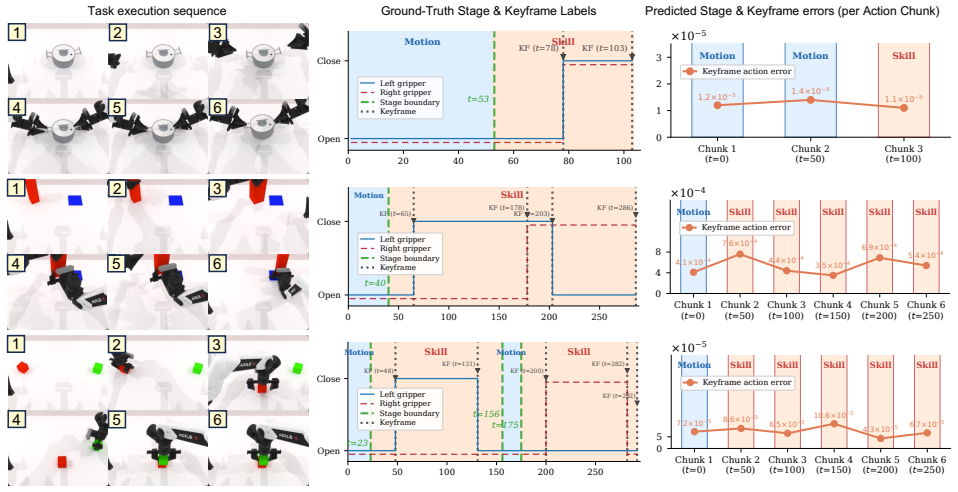
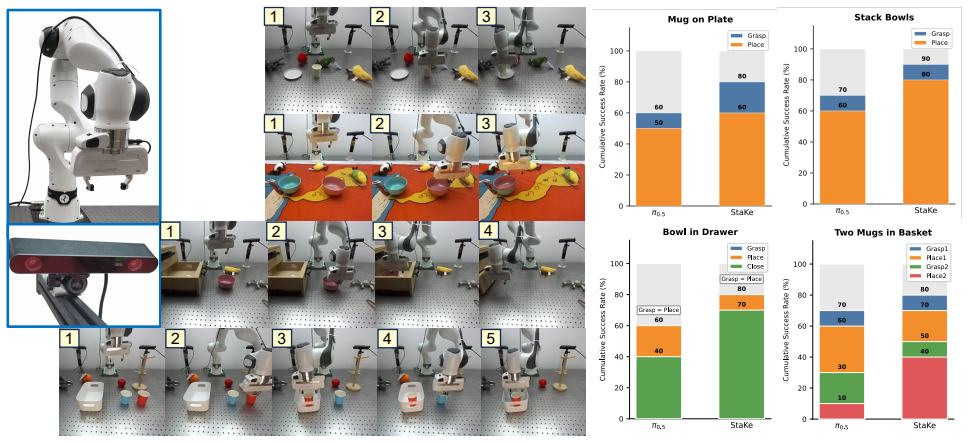
StaKe automatically derives two complementary signals from demonstration gripper states without manual annotation: a stage classifier that identifies the current manipulation stage and a keyframe predictor that estimates the target joint action at the next gripper transition. Both are implemented as lightweight auxiliary heads that enrich representations during training. Experiments on bimanual simulation and single-arm Franka real-robot tasks show consistent success-rate improvements with relative gains of 14 percent and 56 percent respectively, with larger benefits on longer-horizon tasks that involve more gripper-event transitions.
What carries the argument
The StaKe plug-in auxiliary heads that supply stage classification and keyframe prediction signals derived from gripper states to structure VLA fine-tuning.
If this is right
- Success rates rise by relative 14 percent on bimanual simulation tasks.
- Success rates rise by relative 56 percent on single-arm Franka real-robot tasks.
- Improvements are larger on longer-horizon tasks that contain more gripper-event transitions.
- The base VLA policy architecture and inference loop stay unchanged.
- Learned representations track manipulation stages according to qualitative analysis.
Where Pith is reading between the lines
- The same gripper-derived auxiliary signals could be tested on other sequential robot behaviors that lack clear stage boundaries.
- Combining StaKe with existing VLA fine-tuning methods might compound gains on complex multi-step tasks.
- Evaluating the method on tasks with noisy or inconsistent gripper recordings would test robustness to imperfect demonstration data.
Load-bearing premise
Gripper states recorded in demonstrations can be automatically segmented into meaningful manipulation stages and keyframes that provide useful auxiliary supervision signals without manual annotation or task-specific engineering.
What would settle it
Applying StaKe to a new set of manipulation tasks where gripper state changes do not align with distinct stages and measuring whether success rates increase, remain flat, or decrease.
Figures

read the original abstract
Vision-Language-Action (VLA) models have shown strong potential for generalizable robotic manipulation. During fine-tuning, however, action supervision applies equally across all timesteps, without structured supervision on which manipulation stage the robot is in or what the next gripper-event target should be. This causes failures to concentrate around challenging gripper-event transitions. To address this, we propose StaKe, a plug-in auxiliary supervision framework that automatically derives two complementary signals from demonstration gripper states without manual annotation: a stage classifier that identifies the current manipulation stage, and a keyframe predictor that estimates the target joint action at the next gripper transition. Both are modeled as lightweight auxiliary heads that enrich the learned representations during training, while leaving the base VLA policy architecture and inference loop unchanged. Experiments on bimanual simulation and single-arm Franka real-robot tasks show that StaKe consistently improves success rates (relative gains of 14% and 56%, respectively), with larger improvements on longer-horizon tasks that involve more gripper-event transitions. Ablation studies validate each design choice, and qualitative analysis confirms that the learned representations faithfully track manipulation stages. These results indicate that structured supervision is an effective and general strategy for enhancing VLA fine-tuning in long-horizon manipulation. Project website: https://hi-yuanxu.github.io/StaKe-Web/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes StaKe, a plug-in auxiliary supervision framework for fine-tuning Vision-Language-Action (VLA) models. It automatically derives two signals from demonstration gripper states (binary open/close transitions) without manual annotation or task-specific engineering: (1) a stage classifier identifying the current manipulation stage and (2) a keyframe predictor estimating the target joint action at the next gripper transition. These are implemented as lightweight auxiliary heads that enrich representations during training but are discarded at inference, leaving the base VLA policy unchanged. Experiments on bimanual simulation and single-arm Franka real-robot tasks report relative success-rate gains of 14% and 56%, respectively, with larger improvements on longer-horizon tasks; ablations isolate each head and qualitative analysis shows learned representations align with gripper-event stages.
Significance. If the reported gains and ablations hold under full experimental scrutiny, the work is significant for demonstrating a general, annotation-free method to inject structured stage and keyframe supervision into VLA fine-tuning. The approach directly targets failure modes at gripper transitions in long-horizon tasks, preserves the original inference loop, and requires only lightweight heads, making it broadly applicable. Credit is due for the automatic derivation of supervision signals purely from gripper logs and for including both simulation and real-robot validation with ablations.
minor comments (3)
- [Abstract and §4] The abstract and introduction state relative gains of 14% and 56% but do not specify the absolute success rates or the number of trials per condition; adding these numbers (with standard errors) would strengthen the results section.
- [§3] The description of how gripper-state transitions are segmented into stages and keyframes is presented at a high level; a short pseudocode or explicit rule set in §3 would improve reproducibility.
- [Figures 4-6] Figure captions and axis labels in the qualitative analysis figures should explicitly state which VLA backbone and task are shown to avoid ambiguity when comparing to baselines.
Simulated Author's Rebuttal
We thank the referee for their thorough summary and positive evaluation of StaKe. The recommendation for minor revision is noted; however, the report lists no specific major comments requiring response. We address the overall assessment below and confirm that the manuscript already incorporates the elements highlighted as strengths.
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical method for adding lightweight auxiliary heads (stage classifier and keyframe predictor) whose training signals are extracted directly from recorded binary gripper states in demonstrations. No equations, derivations, or self-citations are used to reduce the reported success-rate gains to quantities defined by construction from the same fitted parameters. The auxiliary heads are discarded at inference, the evaluation uses held-out tasks, and ablations isolate each component. The central claim therefore rests on external experimental validation rather than any self-definitional or fitted-input reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gripper states in demonstrations can be used to automatically derive manipulation stages and keyframes without manual annotation.
Reference graph
Works this paper leans on
-
[1]
A survey on vision-language-action models for embodied ai,
Y . Ma, Z. Song, Y . Zhuang, J. Hao, and I. King, “A survey on vision-language-action models for embodied ai,”arXiv preprint arXiv:2405.14093, 2024
Pith/arXiv arXiv 2024
-
[2]
Openflamingo: An open-source framework for training large autoregressive vision- language models,
A. Awadalla, I. Gao, J. Gardner, J. Hessel, Y . Hanafy, W. Zhu, K. Marathe, Y . Bitton, S. Gadre, S. Sagawa,et al., “Openflamingo: An open-source framework for training large autoregressive vision- language models,”arXiv preprint arXiv:2308.01390, 2023
Pith/arXiv arXiv 2023
-
[3]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34 892–34 916, 2023
2023
-
[4]
Rt-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu,et al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[5]
Rt-2: Vision- language-action models transfer web knowledge to robotic control, 2023,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choro- manski, T. Ding, D. Driess, A. Dubey, C. Finn,et al., “Rt-2: Vision- language-action models transfer web knowledge to robotic control, 2023,”URL https://arxiv. org/abs/2307.15818, vol. 1, p. 2, 2024
Pith/arXiv arXiv 2023
-
[6]
Palm-e: An embodied multimodal language model,
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu,et al., “Palm-e: An embodied multimodal language model,”arXiv preprint arXiv:2303.03378, 2023
Pith/arXiv arXiv 2023
-
[7]
Openvla: An open-source vision-language-action model, 2024,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi,et al., “Openvla: An open-source vision-language-action model, 2024,”URL https://arxiv. org/abs/2406.09246, vol. 1, no. 2, p. 4, 2024
Pith/arXiv arXiv 2024
-
[8]
Octo: An open-source generalist robot policy,
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu,et al., “Octo: An open-source generalist robot policy,”arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[9]
Open x-embodiment: Robotic learning datasets and rt-x models,
Q. Vuong, S. Levine, H. R. Walke, K. Pertsch, A. Singh, R. Doshi, C. Xu, J. Luo, L. Tan, D. Shah,et al., “Open x-embodiment: Robotic learning datasets and rt-x models,” 2023
2023
-
[10]
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot,
H.-S. Fang, H. Fang, Z. Tang, J. Liu, C. Wang, J. Wang, H. Zhu, and C. Lu, “Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot,”arXiv preprint arXiv:2307.00595, 2023
arXiv 2023
-
[11]
π 0: A Vision- Language-Action Flow Model for General Robot Control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter,et al., “π 0: A Vision- Language-Action Flow Model for General Robot Control,”arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[12]
π 0.5: A Vision-Language-Action Model with Open-World Generalization,
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai,et al., “π 0.5: A Vision-Language-Action Model with Open-World Generalization,” arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[13]
Fine-tuning vision-language- action models: Optimizing speed and success,
M. J. Kim, C. Finn, and P. Liang, “Fine-tuning vision-language- action models: Optimizing speed and success,”arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[14]
Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking,
H. Bharadhwaj, J. Vakil, M. Sharma, A. Gupta, S. Tulsiani, and V . Ku- mar, “Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking,” pp. 4788–4795, 2024
2024
-
[15]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu,et al., “Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,”arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[16]
Vision-language foundation models as effective robot imitators,
X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y . Jing, W. Zhang, H. Liu,et al., “Vision-language foundation models as effective robot imitators,” 2023
2023
-
[17]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang,et al., “Cogact: A foundational vision- language-action model for synergizing cognition and action in robotic manipulation,”arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[18]
Rdt-1b: a diffusion foundation model for bimanual manipulation,
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu, “Rdt-1b: a diffusion foundation model for bimanual manipulation,”arXiv preprint arXiv:2410.07864, 2024
Pith/arXiv arXiv 2024
-
[19]
Gr-2: A generative video-language- action model with web-scale knowledge for robot manipulation,
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang,et al., “Gr-2: A generative video-language- action model with web-scale knowledge for robot manipulation,”arXiv preprint arXiv:2410.06158, 2024
Pith/arXiv arXiv 2024
-
[20]
Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers,
L. Wang, X. Chen, J. Zhao, and K. He, “Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers,” vol. 37, 2024, pp. 124 420–124 450
2024
-
[21]
Spatialvla: Exploring spatial representations for visual-language-action model,
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang,et al., “Spatialvla: Exploring spatial representations for visual-language-action model,”arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[22]
Hybridvla: Collaborative diffusion and au- toregression in a unified vision-language-action model,
J. Liu, H. Chen, P. An, Z. Liu, R. Zhang, C. Gu, X. Li, Z. Guo, S. Chen, M. Liu,et al., “Hybridvla: Collaborative diffusion and au- toregression in a unified vision-language-action model,”arXiv preprint arXiv:2503.10631, 2025
Pith/arXiv arXiv 2025
-
[23]
Fast: Efficient action tokenization for vision-language-action models,
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine, “Fast: Efficient action tokenization for vision-language-action models,”arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[24]
Tinyvla: Towards fast, data-efficient vision- language-action models for robotic manipulation,
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen,et al., “Tinyvla: Towards fast, data-efficient vision- language-action models for robotic manipulation,”IEEE Robotics and Automation Letters, 2025
2025
-
[25]
Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution,
Y . Yue, Y . Wang, B. Kang, Y . Han, S. Wang, S. Song, J. Feng, and G. Huang, “Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution,” vol. 37, 2024, pp. 56 619–56 643
2024
-
[26]
Conrft: A reinforced fine-tuning method for vla models via consistency policy,
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao, “Conrft: A reinforced fine-tuning method for vla models via consistency policy,” arXiv preprint arXiv:2502.05450, 2025
arXiv 2025
-
[27]
Improving vision-language-action model with online reinforcement learning,
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen, “Improving vision-language-action model with online reinforcement learning,” pp. 15 665–15 672, 2025
2025
-
[28]
Perceiver-actor: A multi-task transformer for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “Perceiver-actor: A multi-task transformer for robotic manipulation,” pp. 785–799, 2023
2023
-
[29]
Rvt: Robotic view transformer for 3d object manipulation,
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox, “Rvt: Robotic view transformer for 3d object manipulation,” pp. 694–710, 2023
2023
-
[30]
Act3d: 3d feature field transformers for multi-task robotic manipulation,
T. Gervet, Z. Xian, N. Gkanatsios, and K. Fragkiadaki, “Act3d: 3d feature field transformers for multi-task robotic manipulation,” 2023
2023
-
[31]
Coarse-to-fine 3d keyframe transporter,
X. Zhu, D. Klee, D. Wang, B. Hu, H. Huang, A. Tangri, R. Walters, and R. Platt, “Coarse-to-fine 3d keyframe transporter,”arXiv preprint arXiv:2502.01773, 2025
arXiv 2025
-
[32]
Waypoint- based imitation learning for robotic manipulation,
L. X. Shi, A. Sharma, T. Z. Zhao, and C. Finn, “Waypoint- based imitation learning for robotic manipulation,”arXiv preprint arXiv:2307.14326, 2023
arXiv 2023
-
[33]
Pivot-r: Primitive-driven waypoint-aware world model for robotic manipulation,
K. Zhang, P. Ren, B. Lin, J. Lin, S. Ma, H. Xu, and X. Liang, “Pivot-r: Primitive-driven waypoint-aware world model for robotic manipulation,” vol. 37, 2024, pp. 54 105–54 136
2024
-
[34]
Keypoint action tokens enable in-context imitation learning in robotics,
N. Di Palo and E. Johns, “Keypoint action tokens enable in-context imitation learning in robotics,”arXiv preprint arXiv:2403.19578, 2024
arXiv 2024
-
[35]
Spatio- temporal reasoning of relational keypoint constraints for robotic ma- nipulation,
W. Huang, C. Wang, Y . Li, R. Zhang, and L. R. Fei-Fei, “Spatio- temporal reasoning of relational keypoint constraints for robotic ma- nipulation,”arXiv preprint arXiv:2409.01652, vol. 2, 2024
Pith/arXiv arXiv 2024
-
[36]
Kisa: A unified keyframe identifier and skill annotator for long-horizon robotics demonstrations,
L. Kou, F. Ni, Y . Zheng, J. Liu, Y . Yuan, Z. Dong, and J. Hao, “Kisa: A unified keyframe identifier and skill annotator for long-horizon robotics demonstrations,” inForty-first International Conference on Machine Learning, 2024
2024
-
[37]
Prime: Scaffolding manipulation tasks with behavior primitives for data-efficient imitation learning,
T. Gao, S. Nasiriany, H. Liu, Q. Yang, and Y . Zhu, “Prime: Scaffolding manipulation tasks with behavior primitives for data-efficient imitation learning,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8322–8329, 2024
2024
-
[38]
Learning semantic atomic skills for multi-task robotic manipulation,
Y . Zhu, W. Wang, S. Wu, Y . Shi, and J. Wang, “Learning semantic atomic skills for multi-task robotic manipulation,”arXiv preprint arXiv:2512.18368, 2025
arXiv 2025
-
[39]
Dexskills: Skill segmentation using haptic data for learning autonomous long-horizon robotic manipulation tasks,
X. Mao, G. Giudici, C. Coppola, K. Althoefer, I. Farkhatdinov, Z. Li, and L. Jamone, “Dexskills: Skill segmentation using haptic data for learning autonomous long-horizon robotic manipulation tasks,” in 2024 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2024, pp. 5104–5111
2024
-
[40]
Contrastive imitation learning for language-guided multi-task robotic manipulation,
T. Ma, J. Zhou, Z. Wang, R. Qiu, and J. Liang, “Contrastive imitation learning for language-guided multi-task robotic manipulation,”arXiv preprint arXiv:2406.09738, 2024
arXiv 2024
-
[41]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[42]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.