Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation
Pith reviewed 2026-06-29 04:56 UTC · model grok-4.3
The pith
Qwen-Image-Agent bridges the context gap in real-world image generation by treating user inputs as partial context and building complete generation contexts through planning and grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
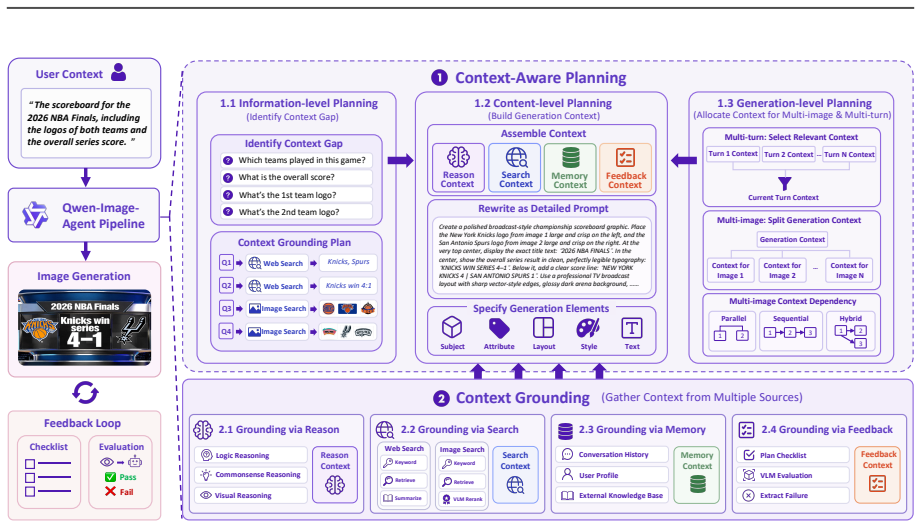
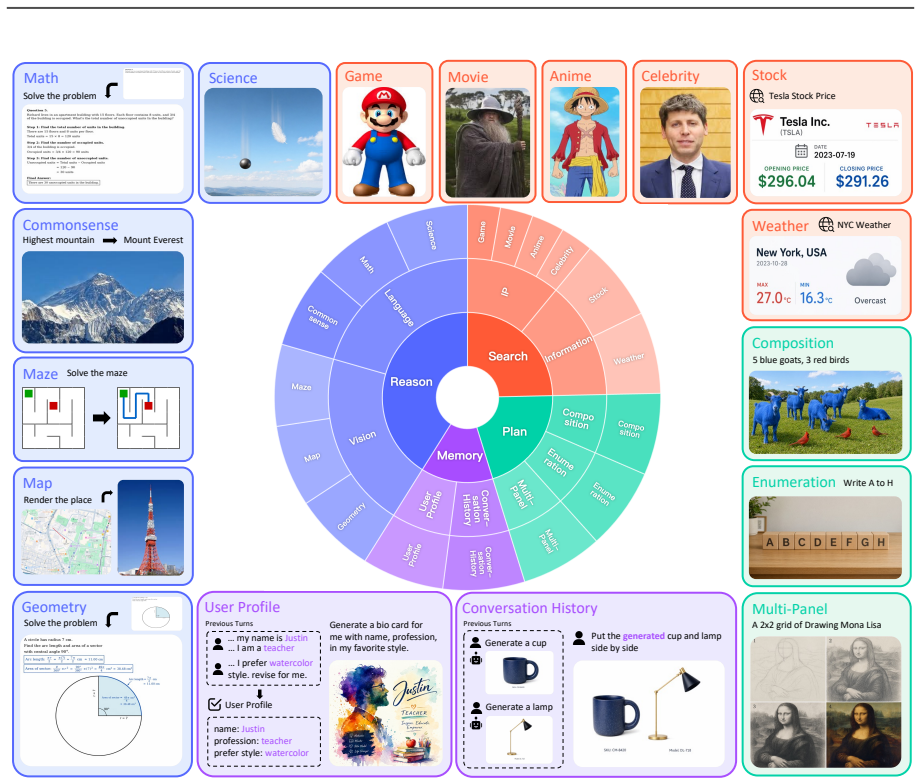
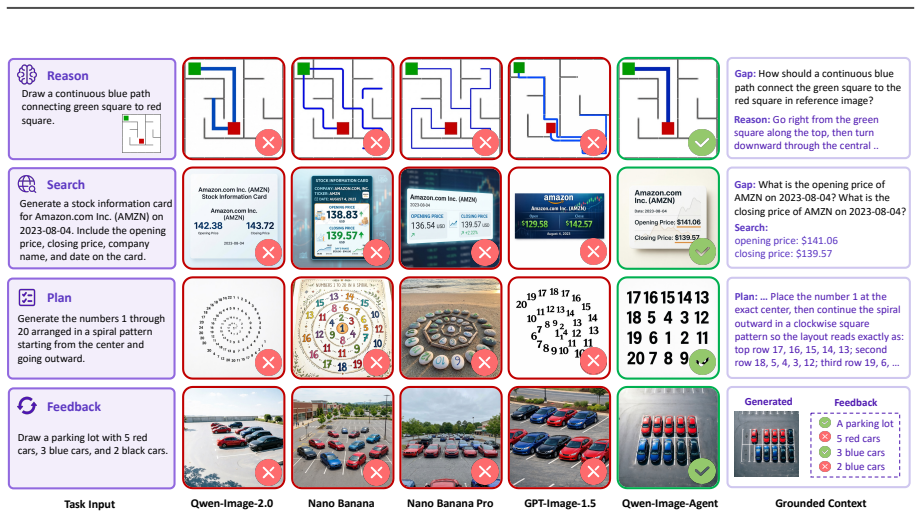
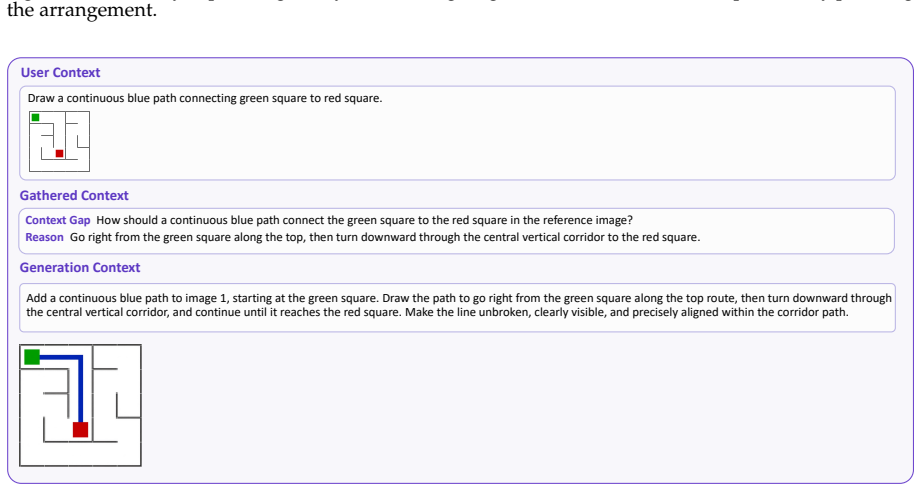
The paper claims that Qwen-Image-Agent, by integrating plan, reason, search, memory and feedback in a context-centric manner, treats user input as partial context and progressively constructs the full generation context via Context-Aware Planning and Context Grounding, thereby outperforming strong baselines and reaching state-of-the-art performance on IA-Bench, Mindbench and WISE-Verified.
What carries the argument
Context-Aware Planning and Context Grounding, which identify missing context and acquire it from reason, search, memory, and feedback to build complete generation contexts for text-to-image models.
If this is right
- Text-to-image models become able to handle implicit and underspecified user requests without extra manual prompt work.
- Performance gains appear on tasks that require planning missing details or retrieving external knowledge.
- A dedicated benchmark now exists for measuring plan, reason, search, and memory skills in image generation agents.
- Multiple agent functions are unified into one framework that focuses on context construction rather than isolated capabilities.
Where Pith is reading between the lines
- The same planning-and-grounding loop could be applied to other generative domains such as video or 3D where user requests are similarly incomplete.
- Adding real-time web search inside the grounding step would allow generations to reflect current events or facts.
- User studies comparing satisfaction with images from vague prompts versus direct text-to-image models would test whether the context gap reduction translates to practical benefit.
Load-bearing premise
The IA-Bench and other evaluation sets accurately capture real-world context acquisition needs and the agent's gathering steps succeed without introducing errors or hallucinations that degrade image quality.
What would settle it
A controlled test showing that images generated after the agent acquires incorrect context from search or memory are rated lower in quality or relevance than images from a non-agent baseline on the same inputs.
Figures






read the original abstract
While text-to-image (T2I) models have achieved remarkable progress, they struggle with real-world requests that are often underspecified, implicit, or dependent on up-to-date knowledge. We identify this challenge as the Context Gap: the mismatch between the user context and the sufficient generation context for T2I models. To bridge this gap, we propose Qwen-Image-Agent, a unified agentic framework that integrates plan, reason, search, memory and feedback in a context-centric manner. Qwen-Image-Agent treats user input as partial context and progressively constructs the generation context through Context-Aware Planning and Context Grounding. Specifically, Context-Aware Planning identifies missing context and plans how it should be acquired and used, while Context Grounding gathers this context from reason, search, memory, and feedback. To evaluate agentic image generation, we further introduce Image Agent Bench (IA-Bench), a benchmark covering four core image agent capabilities: Plan, Reason, Search, and Memory. Experiments on IA-Bench, Mindbench and WISE-Verified show that Qwen-Image-Agent outperforms strong baselines and achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies the Context Gap in text-to-image models for underspecified real-world requests and proposes Qwen-Image-Agent, an agentic framework that uses Context-Aware Planning and Context Grounding (integrating reason, search, memory, and feedback) to progressively build sufficient generation context. It introduces IA-Bench to evaluate Plan, Reason, Search, and Memory capabilities and reports that the method outperforms baselines to achieve SOTA on IA-Bench, Mindbench, and WISE-Verified.
Significance. If the performance claims hold under rigorous verification, the work would offer a concrete agentic paradigm for handling implicit or knowledge-dependent image requests, with IA-Bench potentially becoming a useful benchmark for context-acquisition capabilities in generation systems.
major comments (3)
- [IA-Bench and Experiments] IA-Bench introduction and evaluation sections: the SOTA claim on IA-Bench is load-bearing for the central thesis, yet the benchmark is author-introduced with no reported inter-annotator agreement, task-distribution statistics, or independent validation of realism; this leaves open the possibility that gains reflect benchmark design choices rather than genuine context-gap bridging.
- [Method and Experiments] Context Grounding description and ablations: the abstract and method claim that grounding via reason/search/memory/feedback succeeds without introducing hallucinations or quality-degrading errors, but no module-level ablations, error-rate measurements, or side-by-side image-quality comparisons (with vs. without grounding) are supplied; these are required to attribute gains to the proposed components.
- [Experiments] Cross-benchmark results: superiority is asserted on Mindbench and WISE-Verified, but the manuscript supplies no baseline implementation details, hyperparameter settings, or statistical tests, preventing assessment of whether reported margins are robust or reproducible.
minor comments (2)
- [Method] Notation for the five integrated modules (plan/reason/search/memory/feedback) is introduced without an explicit diagram or pseudocode showing their interaction order and data flow.
- [Abstract] The abstract uses 'state-of-the-art performance' without qualifying the exact metrics or number of baselines compared.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the paper. We address each major point below and will incorporate revisions where appropriate to improve clarity and rigor.
read point-by-point responses
-
Referee: [IA-Bench and Experiments] IA-Bench introduction and evaluation sections: the SOTA claim on IA-Bench is load-bearing for the central thesis, yet the benchmark is author-introduced with no reported inter-annotator agreement, task-distribution statistics, or independent validation of realism; this leaves open the possibility that gains reflect benchmark design choices rather than genuine context-gap bridging.
Authors: We agree that additional details on IA-Bench would strengthen the presentation. In the revision we will report inter-annotator agreement, provide task-distribution statistics, and include a more detailed description of the benchmark construction process and its alignment with real-world underspecified requests. While the SOTA results on the independent Mindbench and WISE-Verified benchmarks already provide external corroboration, these additions will directly address concerns about benchmark-specific artifacts. revision: yes
-
Referee: [Method and Experiments] Context Grounding description and ablations: the abstract and method claim that grounding via reason/search/memory/feedback succeeds without introducing hallucinations or quality-degrading errors, but no module-level ablations, error-rate measurements, or side-by-side image-quality comparisons (with vs. without grounding) are supplied; these are required to attribute gains to the proposed components.
Authors: We acknowledge the value of module-level evidence. The revised manuscript will include ablations that isolate each grounding module (reason, search, memory, feedback), report error rates for hallucination and quality degradation, and provide side-by-side qualitative comparisons of generated images with and without the full grounding pipeline. These experiments will be added to the Experiments section to more clearly attribute performance gains. revision: yes
-
Referee: [Experiments] Cross-benchmark results: superiority is asserted on Mindbench and WISE-Verified, but the manuscript supplies no baseline implementation details, hyperparameter settings, or statistical tests, preventing assessment of whether reported margins are robust or reproducible.
Authors: We agree that reproducibility details are necessary. The revision will expand the experimental setup to include full baseline implementation descriptions, hyperparameter values, and statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) for the reported margins on Mindbench and WISE-Verified. This will allow readers to assess robustness directly. revision: yes
Circularity Check
No circularity; empirical evaluation on benchmarks
full rationale
The paper introduces an agentic framework for bridging the context gap in image generation and reports experimental outperformance on IA-Bench (newly proposed), Mindbench, and WISE-Verified. No equations, fitted parameters, or derivation steps are described that reduce claims to self-defined inputs by construction. Performance is presented as measured outcomes against baselines rather than self-referential quantities, making the central claims self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Accessed: 2025-06-19. Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt
URLhttps://api.semanticscholar.org/CorpusID:286975158. Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.ArXiv, abs/2310.11513,
-
[5]
URL https://api.semanticscholar. org/CorpusID:264288728. Google DeepMind. Gemini image pro: High-quality image generation. https://deepmind.google/ models/gemini-image/pro/, 2025a. Accessed: 2026-01-26. Google DeepMind. Gemini image: High-quality image generation. https://deepmind.google/models/ gemini-image/flash/, 2025b. Accessed: 2026-01-26. Jun He, Ju...
-
[6]
URL https://api.semanticscholar. org/CorpusID:268296755. Dongzhi Jiang, Renrui Zhang, Haodong Li, Zhuofan Zong, Ziyu Guo, Jun He, Claire Guo, Junyan Ye, Rongyao Fang, Weijia Li, et al. Draco: Draft as cot for text-to-image preview and rare concept generation.arXiv preprint arXiv:2512.05112,
-
[7]
Genagent: Scaling text-to-image generation via agentic multimodal rea- soning.ArXiv, abs/2601.18543,
Kaixun Jiang, Yuzheng Wang, Junjie Zhou, Pandeng Li, Zhihang Liu, Chen-Wei Xie, Zhaoyu Chen, Yun Zheng, and Wenqiang Zhang. Genagent: Scaling text-to-image generation via agentic multimodal rea- soning.ArXiv, abs/2601.18543,
-
[8]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
URLhttps://arxiv.org/abs/2506.15742. 13 Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, et al. Uniworld: High-resolution semantic encoders for unified visual understanding and generation.arXiv preprint arXiv:2506.03147,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Fanqing Meng, Wenqi Shao, Li Ray Luo, Yahong Wang, Yiran Chen, Quanfeng Lu, Yue Yang, Tianshuo Yang, Kaipeng Zhang, Yu Qiao, and Ping Luo. Phybench: A physical commonsense benchmark for evaluating text-to-image models.ArXiv, abs/2406.11802,
-
[10]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
URL https://api.semanticscholar. org/CorpusID:270560653. Yuwei Niu, Munan Ning, Mengren Zheng, Bin Lin, Peng Jin, Jiaqi Liao, Kunpeng Ning, Bin Zhu, and Li Yuan. Wise: A world knowledge-informed semantic evaluation for text-to-image generation.ArXiv, abs/2503.07265,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Accessed: 2026-01-29. OpenAI. Gpt-image-1.5: Enhanced visual reasoning and creative generation. https://platform.openai. com/docs/models/gpt-image-1.5,
2026
-
[12]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Accessed: 2026-01-29. Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Stability AI. Stable diffusion 3.5 large. https://huggingface.co/stabilityai/stable-diffusion-3. 5-large, 2024a. Stability AI. Stable diffusion 3.5 medium. https://huggingface.co/stabilityai/stable-diffusion-3. 5-medium/, 2024b. Stability AI. Stable diffusion 3 medium. https://huggingface.co/stabilityai/ stable-diffusion-3-medium, 2024c. Kaishen Wang, Rui...
-
[14]
URL https://api. semanticscholar.org/CorpusID:283055363. Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a. Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Shengming Yin, Shuai Bai, Xiao Xu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Photoagent: Agentic photo editing with exploratory visual aesthetic planning.ArXiv, abs/2602.22809,
Mingde Yao, Zhiyuan You, King-Man Tam, Menglu Wang, and Tianfan Xue. Photoagent: Agentic photo editing with exploratory visual aesthetic planning.ArXiv, abs/2602.22809,
-
[16]
URL https: //api.semanticscholar.org/CorpusID:286082495. Junyan Ye, Dongzhi Jiang, Zihao Wang, Leqi Zhu, Zhenghao Hu, Zilong Huang, Jun He, Zhiyuan Yan, Jinghua Yu, Hongsheng Li, et al. Echo-4o: Harnessing the power of gpt-4o synthetic images for improved image generation.arXiv preprint arXiv:2508.09987,
-
[17]
Rossi, Wenhao Chai, and Zhengzhong Tu
14 Ruijie Ye, Jiayi Zhang, Zhuoxin Liu, Zihao Zhu, Siyuan Yang, Li Li, Tianfu Fu, Franck Dernoncourt, Yue Zhao, Jiacheng Zhu, Ryan A. Rossi, Wenhao Chai, and Zhengzhong Tu. Agent banana: High- fidelity image editing with agentic thinking and tooling.ArXiv, abs/2602.09084,
-
[18]
URL https://api.semanticscholar.org/CorpusID:288256176. Xiangyu Zhao, Peiyuan Zhang, Kexian Tang, Hao Li, Zicheng Zhang, Guangtao Zhai, Junchi Yan, Hua Yang, Xue Yang, and Haodong Duan. Envisioning beyond the pixels: Benchmarking reasoning- informed visual editing.ArXiv, abs/2504.02826,
-
[19]
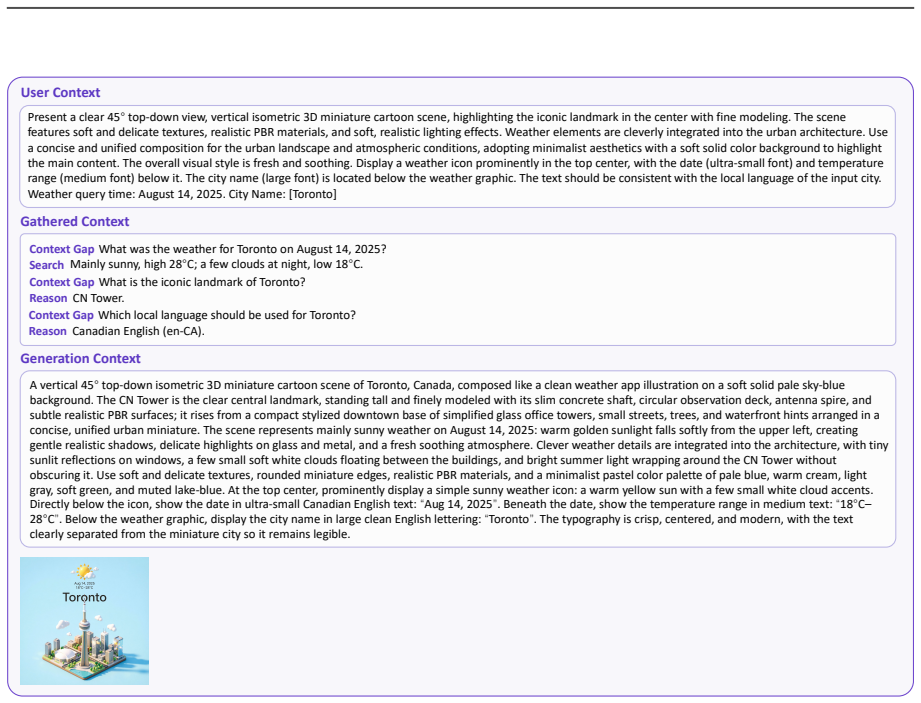
Aug 14, 2025
City Name: [Toronto]Gathered Context Generation Context What was the weather for Toronto on August 14, 2025?SearchContext GapMainly sunny, high 28°C; a few clouds at night, low 18°C.What is the iconic landmark of Toronto?ReasonContext GapCN Tower.Which local language should be used for Toronto?ReasonContext GapCanadian English (en-CA). A vertical 45°top-d...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.