Look-Before-Move: Narrative-Grounded World Visual Attention in Dynamic 3D Story Worlds
Pith reviewed 2026-06-29 04:53 UTC · model grok-4.3
The pith
A camera planning framework that first specifies what to observe before generating motion improves narrative intent and trajectory quality in dynamic 3D story worlds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
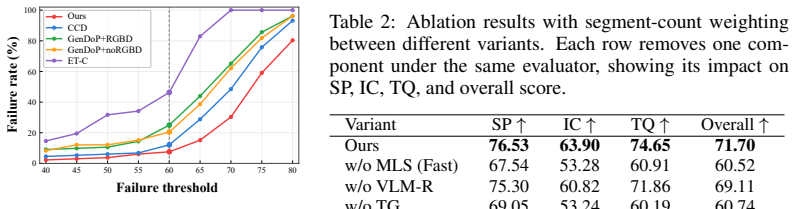
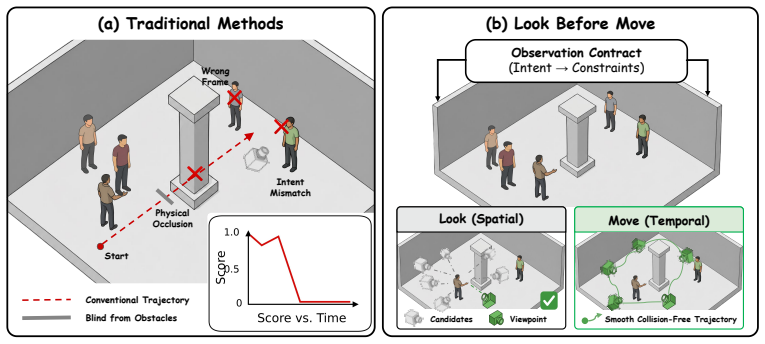
The paper claims that separating observation specification from motion execution through a Semantic Observation Contract, followed by Monte Carlo Viewpoint Search and Semantic Trajectory Grounding, produces camera paths that better satisfy narrative intent and physical constraints than direct motion generation methods.
What carries the argument
The Look-Before-Move framework, which first builds a Semantic Observation Contract to turn narrative intent into visual constraints before searching viewpoints and grounding trajectories.
If this is right
- Higher subject perception scores in generated shots compared to baselines.
- Stronger alignment between camera output and original narrative intent.
- Improved smoothness and collision avoidance in camera trajectories.
- Empirical support for prioritizing visual attention planning before motion synthesis.
Where Pith is reading between the lines
- The separation of observation rules from motion could apply to other tasks where an agent must decide where to look before acting in 3D space.
- Testing the contract construction step on stories with ambiguous or conflicting directions would reveal how robust the translation remains.
- The benchmark construction method might be reused to evaluate attention mechanisms in other embodied simulation settings.
Load-bearing premise
The Semantic Observation Contract accurately converts directorial narrative intent into executable visual constraints without significant loss of meaning or ambiguity.
What would settle it
Applying the framework to the dynamic 3D Story World Benchmark and measuring no improvement, or a decline, in subject perception, intent consistency, or trajectory quality relative to baselines would falsify the claim.
Figures










read the original abstract
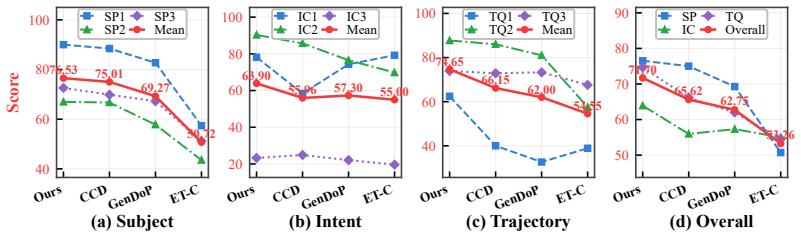
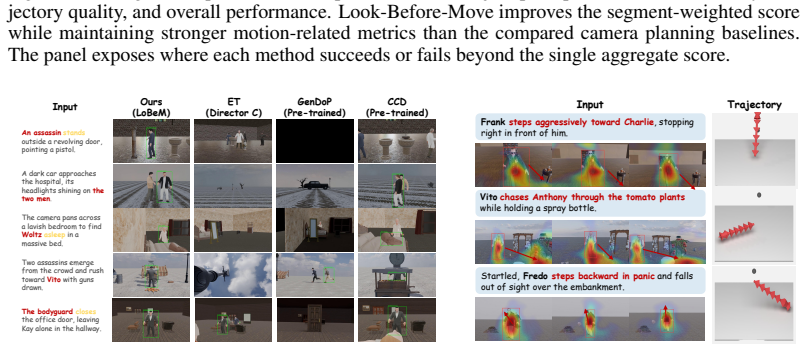
As embodied AI and world models increasingly operate in dynamic 3D environments, visual perception must move beyond passively interpreting given observations toward actively deciding what to observe. We study this problem through camera planning in dynamic 3D story worlds, where the camera must not only generate smooth motion, but also decide what visual evidence should be acquired before it moves. We formulate this capability as Narrative-Grounded World Visual Attention, where the camera acts as an embodied observer that determines what to observe, how to compose the observation, and how to shift attention over time under narrative intent and physical 3D constraints. To realize this capability, we propose Look-Before-Move, a camera planning framework that separates observation specification from motion execution. It first builds a Semantic Observation Contract to convert directorial intent into executable visual constraints, then performs Monte Carlo Viewpoint Search to find narrative-compliant and geometrically feasible viewpoints, and finally applies Semantic Trajectory Grounding to connect selected viewpoints into continuous, collision-aware, and temporally coherent camera motion. We further construct a dynamic 3D Story World Benchmark based on StoryBlender, covering 50 stories, 457 scenes, and 1585 shots with animated characters, semantic scene configurations, and executable 3D environments. Experiments show that our framework improves subject perception, intent consistency, and trajectory quality over representative baselines, demonstrating the importance of organizing visual attention before generating camera motion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
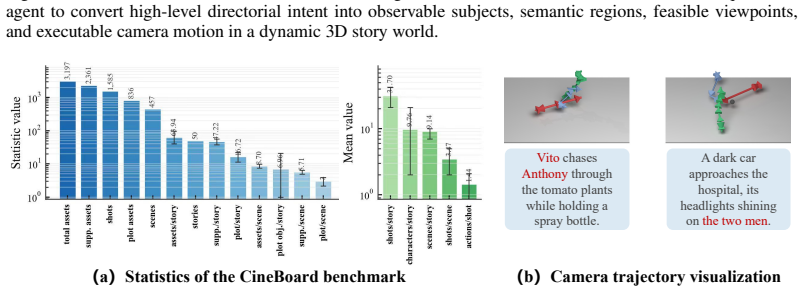
Summary. The paper introduces Look-Before-Move, a modular camera-planning framework for dynamic 3D story worlds that separates narrative-grounded observation specification (Semantic Observation Contract) from motion execution (Monte Carlo Viewpoint Search followed by Semantic Trajectory Grounding). It constructs a benchmark of 50 stories, 457 scenes, and 1585 shots in executable 3D environments derived from StoryBlender and reports that the framework improves subject perception, intent consistency, and trajectory quality relative to baselines, underscoring the value of organizing visual attention prior to generating camera motion.
Significance. If the experimental claims hold under detailed scrutiny, the work offers a concrete advance for embodied AI and world models by treating visual attention as an active, narrative-constrained planning step rather than a passive byproduct of motion generation. The construction of an executable 3D benchmark with animated characters and semantic scene configurations is a reusable, falsifiable resource that could support future research on story-driven camera control.
major comments (2)
- [§4] §4 (Experiments): the abstract and framework description assert quantitative improvements in subject perception, intent consistency, and trajectory quality, yet supply no definition of the metrics, choice of baselines, dataset splits, statistical tests, or error analysis; without these the central empirical claim cannot be evaluated.
- [§3.1] §3.1 (Semantic Observation Contract): the translation from directorial narrative intent into executable visual constraints is presented as lossless, but no validation procedure, ambiguity analysis, or failure cases are reported; this assumption is load-bearing for both the benchmark construction and the claimed consistency gains.
minor comments (2)
- [§3.2] Notation for the Monte Carlo Viewpoint Search objective and the Semantic Trajectory Grounding loss should be introduced with explicit variable definitions before their first use.
- [§4.1] The benchmark description would benefit from an explicit statement of how the 1585 shots were sampled and whether any scenes were held out for testing.
Simulated Author's Rebuttal
We thank the referee for the constructive critique. The two major comments identify genuine gaps in experimental reporting and validation that we will address through targeted revisions. We respond point-by-point below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the abstract and framework description assert quantitative improvements in subject perception, intent consistency, and trajectory quality, yet supply no definition of the metrics, choice of baselines, dataset splits, statistical tests, or error analysis; without these the central empirical claim cannot be evaluated.
Authors: We agree the current manuscript lacks explicit metric definitions, baseline specifications, split details, statistical tests, and error analysis. In the revision we will insert a new subsection 4.1 that (i) formally defines each metric (subject perception via IoU on character bounding boxes, intent consistency via semantic label overlap between contract and rendered frames, trajectory quality via smoothness and collision counts), (ii) lists the exact baselines and their implementations, (iii) reports the 80/20 story-level split, (iv) adds paired t-tests with p-values, and (v) includes per-scene error breakdowns. These additions will make the empirical claims directly evaluable. revision: yes
-
Referee: [§3.1] §3.1 (Semantic Observation Contract): the translation from directorial narrative intent into executable visual constraints is presented as lossless, but no validation procedure, ambiguity analysis, or failure cases are reported; this assumption is load-bearing for both the benchmark construction and the claimed consistency gains.
Authors: The referee correctly notes the absence of validation. While the contract is constructed via deterministic rule-based mapping from narrative predicates to visual constraints, we did not quantify translation fidelity. In revision we will add (a) a human validation study on 100 randomly sampled contracts measuring agreement with original intent, (b) an ambiguity taxonomy with examples of narrative underspecification, and (c) reported failure rates. This will substantiate the lossless claim or qualify it appropriately. revision: yes
Circularity Check
No significant circularity; framework and benchmark are independently specified
full rationale
The paper defines a modular pipeline (Semantic Observation Contract, Monte Carlo Viewpoint Search, Semantic Trajectory Grounding) whose components are presented as distinct steps converting narrative intent into constraints, then searching viewpoints, then grounding trajectories. The benchmark is described as constructed from StoryBlender with explicit counts (50 stories, 457 scenes, 1585 shots) and evaluated via measurable improvements in subject perception, intent consistency, and trajectory quality against baselines. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The central claim rests on experimental comparison rather than reduction to prior inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Narrative intent can be reliably converted into geometric and semantic visual constraints without loss of meaning
- domain assumption Monte Carlo sampling can efficiently identify narrative-compliant and collision-free viewpoints in 3D scenes
invented entities (2)
-
Semantic Observation Contract
no independent evidence
-
Narrative-Grounded World Visual Attention
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scenecraft: An llm agent for synthesizing 3d scenes as blender code,
Z. Hu, A. Iscen, A. Jain, T. Kipf, Y . Yue, D. A. Ross, C. Schmid, and A. Fathi, “Scenecraft: An llm agent for synthesizing 3d scenes as blender code,” inForty-first International Conference on Machine Learning, 2024
2024
-
[2]
Sceneweaver: All-in-one 3d scene synthesis with an extensible and self-reflective agent,
Y . Yang, B. Jia, S. Zhang, and S. Huang, “Sceneweaver: All-in-one 3d scene synthesis with an extensible and self-reflective agent,” 2025
2025
-
[3]
Worldcraft: Photo-realistic 3d world creation and cus- tomization via llm agents,
X. Liu, C.-K. Tang, and Y .-W. Tai, “Worldcraft: Photo-realistic 3d world creation and cus- tomization via llm agents,” 2025
2025
-
[4]
Pat3d: Physics-augmented text-to-3d scene generation,
G. Lin, K. Huang, M. Liu, R. Gao, H. Chen, L. Chen, B. Lu, T. Komura, Y . Liu, J.-Y . Zhu, and M. Li, “Pat3d: Physics-augmented text-to-3d scene generation,” 2025
2025
-
[5]
Intuitive and efficient camera control with the toric space,
C. Lino and M. Christie, “Intuitive and efficient camera control with the toric space,”ACM Transactions on Graphics (TOG), vol. 34, no. 4, pp. 1–12, 2015
2015
-
[6]
Camera trajectory gen- eration: A comprehensive survey of methods, metrics, and future directions,
Z. Dehghanian, P. Ardekhani, A. Vahedi, H. Beigy, and H. R. Rabiee, “Camera trajectory gen- eration: A comprehensive survey of methods, metrics, and future directions,”arXiv preprint arXiv:2506.00974, 2025
-
[7]
Dynamic storyboard generation in an engine-based virtual environment for video production,
A. Rao, X. Jiang, Y . Guo, L. Xu, L. Yang, L. Jin, D. Lin, and B. Dai, “Dynamic storyboard generation in an engine-based virtual environment for video production,” 2023
2023
-
[8]
Story3d-agent: Explor- ing 3d storytelling visualization with large language models,
Y . Huang, Y . Qin, S. Lu, X. Wang, R. Huang, Y . Shan, and R. Zhang, “Story3d-agent: Explor- ing 3d storytelling visualization with large language models,” 2024
2024
-
[9]
Storyblender: Inter-shot consistent and editable 3d storyboard with spatial-temporal dynamics,
B. Li, Z. Sun, J. Bian, Y . Wu, Y . Wang, H. Li, Y . Bian, H. Mo, and D. Dong, “Storyblender: Inter-shot consistent and editable 3d storyboard with spatial-temporal dynamics,” 2026
2026
-
[10]
Motionctrl: A unified and flexible motion controller for video generation,
Z. Wang, Z. Yuan, X. Wang, Y . Li, T. Chen, M. Xia, P. Luo, and Y . Shan, “Motionctrl: A unified and flexible motion controller for video generation,” inACM SIGGRAPH 2024 Conference Papers, pp. 1–11, 2024
2024
-
[11]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
H. He, Y . Xu, Y . Guo, G. Wetzstein, B. Dai, H. Li, and C. Yang, “Cameractrl: Enabling camera control for text-to-video generation,”arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Direct-a- video: Customized video generation with user-directed camera movement and object motion,
S. Yang, L. Hou, H. Huang, C. Ma, P. Wan, D. Zhang, X. Chen, and J. Liao, “Direct-a- video: Customized video generation with user-directed camera movement and object motion,” inACM SIGGRAPH 2024 Conference Papers, pp. 1–12, 2024
2024
-
[13]
Gendop: Auto-regressive camera trajectory generation as a director of photography,
M. Zhang, T. Wu, J. Tan, Z. Liu, G. Wetzstein, and D. Lin, “Gendop: Auto-regressive camera trajectory generation as a director of photography,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pp. 18229–18239, 2025
2025
-
[14]
Director3d: Real-world cam- era trajectory and 3d scene generation from text,
X. Li, Z. Lai, L. Xu, Y . Qu, L. Cao, S. Zhang, B. Dai, and R. Ji, “Director3d: Real-world cam- era trajectory and 3d scene generation from text,”Advances in neural information processing systems, vol. 37, pp. 75125–75151, 2024
2024
-
[15]
E.T. the exceptional trajectories: Text-to-camera- trajectory generation with character awareness,
R. Courant, N. Dufour, X. Wang,et al., “E.T. the exceptional trajectories: Text-to-camera- trajectory generation with character awareness,” inEuropean Conference on Computer Vision, pp. 464–480, 2024
2024
-
[16]
Vd3d: Taming large video diffusion transformers for 3d camera control,
S. Bahmani, I. Skorokhodov, A. Siarohin, W. Menapace, G. Qian, M. Vasilkovsky, H.-Y . Lee, C. Wang, J. Zou, A. Tagliasacchi,et al., “Vd3d: Taming large video diffusion transformers for 3d camera control,”arXiv preprint arXiv:2407.12781, 2024
-
[17]
Cavia: Camera-controllable multi-view video diffusion with view-integrated attention,
D. Xu, Y . Jiang, C. Huang, L. Song, T. Gernoth, L. Cao, Z. Wang, and H. Tang, “Cavia: Camera-controllable multi-view video diffusion with view-integrated attention,”arXiv preprint arXiv:2410.10774, 2024
-
[18]
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
D. Xu, W. Nie, C. Liu, S. Liu, J. Kautz, Z. Wang, and A. Vahdat, “Camco: Camera-controllable 3d-consistent image-to-video generation,”arXiv preprint arXiv:2406.02509, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Particlesfm: Exploiting dense point tra- jectories for localizing moving cameras in the wild,
W. Zhao, S. Liu, H. Guo, W. Wang, and Y .-J. Liu, “Particlesfm: Exploiting dense point tra- jectories for localizing moving cameras in the wild,” inEuropean Conference on Computer Vision, pp. 523–542, Springer, 2022
2022
-
[20]
Ac3d: Analyzing and improving 3d camera control in video diffusion transformers,
S. Bahmani, I. Skorokhodov, G. Qian, A. Siarohin, W. Menapace, A. Tagliasacchi, D. B. Lin- dell, and S. Tulyakov, “Ac3d: Analyzing and improving 3d camera control in video diffusion transformers,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 22875–22889, 2025. 11
2025
-
[21]
Towards understanding camera motions in any video,
Z. Lin, S. Cen, D. Jiang, J. Karhade, H. Wang, C. Mitra, T. Ling, Y . Huang, S. Liu, M. Chen,et al., “Towards understanding camera motions in any video,”arXiv preprint arXiv:2504.15376, 2025
-
[22]
Filmagent: A multi-agent framework for end-to-end film automation in virtual 3d spaces,
Z. Xu, L. Wang, J. Wang, Z. Li, S. Shi, X. Yang, Y . Wang, B. Hu, J. Yu, and M. Zhang, “Filmagent: A multi-agent framework for end-to-end film automation in virtual 3d spaces,” arXiv preprint arXiv:2501.12909, 2025
-
[23]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. e. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” inAdvances in Neural Information Processing Systems, vol. 36, pp. 8634–8652, 2023
2023
-
[24]
Self-refine: Iterative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prab- humoye, Y . Yang,et al., “Self-refine: Iterative refinement with self-feedback,” inAdvances in Neural Information Processing Systems, vol. 36, pp. 46534–46594, 2023
2023
-
[25]
Instruct-of-reflection: Enhancing large language models iter- ative reflection capabilities via dynamic-meta instruction,
L. Liu, C. Zhang, L. Wu,et al., “Instruct-of-reflection: Enhancing large language models iter- ative reflection capabilities via dynamic-meta instruction,” inProceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 9956–9978, 2025
2025
-
[26]
Vision-language models can self-improve reasoning via reflection,
K. Cheng, L. YanTao, F. Xu,et al., “Vision-language models can self-improve reasoning via reflection,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 8876– 8892, 2025
2025
-
[27]
Expel: Llm agents are expe- riential learners,
A. Zhao, D. Huang, Q. Xu, M. Lin, Y .-J. Liu, and G. Huang, “Expel: Llm agents are expe- riential learners,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 19632–19642, 2024
2024
-
[28]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
A. Zhou, K. Yan, M. Shlapentokh-Rothman, H. Liu, and C. Gan, “Language agent tree search unifies reasoning acting and planning in language models,”arXiv preprint arXiv:2310.04406, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Mirror: multi-agent intra-and inter-reflection for optimized reasoning in tool learning,
Z. Guo, B. Xu, X. Wang,et al., “Mirror: multi-agent intra-and inter-reflection for optimized reasoning in tool learning,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pp. 117–125, 2025
2025
-
[30]
Towards enhanced immersion and agency for llm-based interac- tive drama,
H. Wu, W. Wu, T. Xu,et al., “Towards enhanced immersion and agency for llm-based interac- tive drama,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pp. 11166–11182, 2025
2025
-
[31]
Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning,
B. Lin, Y . Nie, Z. Wei,et al., “Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[32]
Look again, think slowly: Enhancing visual reflection in vision- language models,
P. Jian, J. Wu, W. Sun,et al., “Look again, think slowly: Enhancing visual reflection in vision- language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 9262–9281, 2025
2025
-
[33]
Perception in reflection,
Y . Wei, L. Zhao, K. Lin,et al., “Perception in reflection,” inInternational Conference on Machine Learning, pp. 66378–66396, PMLR, 2025
2025
-
[34]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
G. Team, P. Georgiev, V . I. Lei,et al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Ultralytics YOLO11,
G. Jocher and J. Qiu, “Ultralytics YOLO11,” 2024
2024
-
[36]
ORB: An efficient alternative to SIFT or SURF,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “ORB: An efficient alternative to SIFT or SURF,” inProceedings of the International Conference on Computer Vision, pp. 2564–2571, 2011
2011
-
[37]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan,et al., “Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Cinematographic camera diffusion model,
H. Jiang, X. Wang, M. Christie,et al., “Cinematographic camera diffusion model,”Computer Graphics Forum, vol. 43, no. 2, p. e15055, 2024. 12 /uni00000036/uni00000046/uni00000048/uni00000051/uni00000057/uni00000003/uni00000052/uni00000049/uni00000003/uni00000044/uni00000003/uni0000003a/uni00000052/uni00000050/uni00000044/uni00000051 /uni0000002a/uni0000005...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.