Joint Learning of Experiential Rules and Policies for Large Language Model Agents
Pith reviewed 2026-06-26 04:30 UTC · model grok-4.3
The pith
LLM agents improve by jointly updating experiential rules and their policy from the same trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
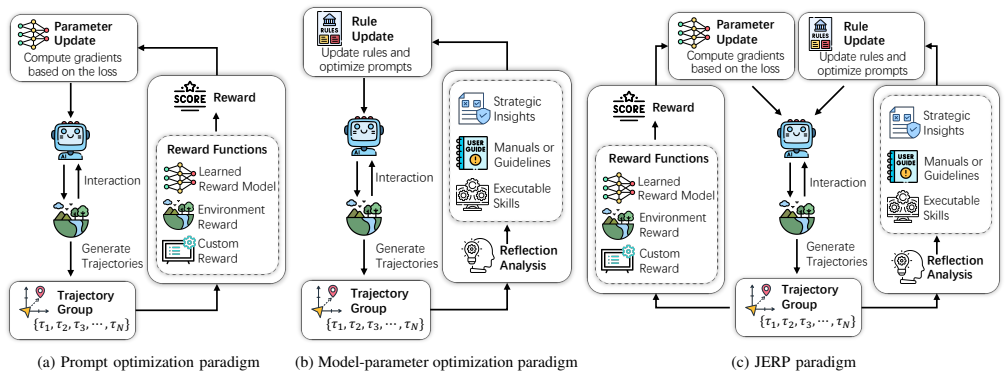
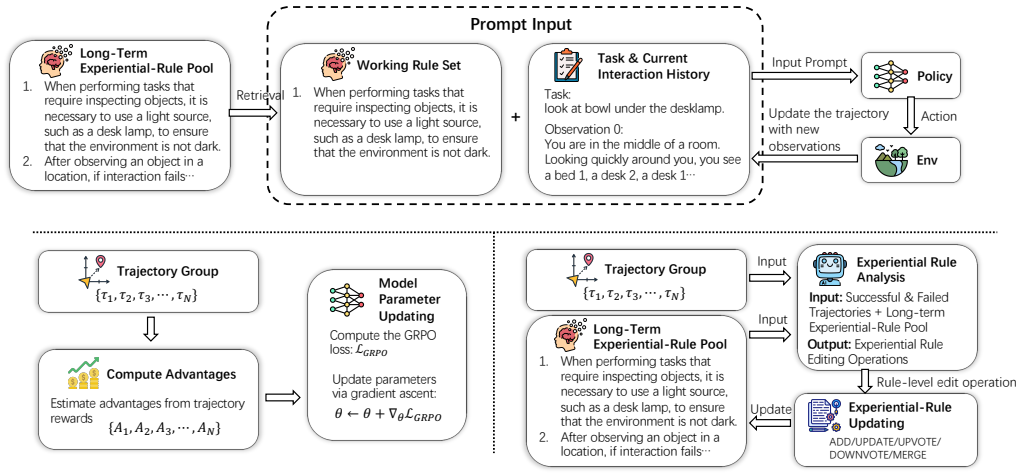
JERP updates a long-term experiential-rule pool and the policy from the same interaction trajectories. At decision time it retrieves task-relevant rules and conditions the agent on them together with the interaction history. After each episode it uses the collected trajectories both to optimize the policy and to revise the rule pool by comparing current rollouts with reference successful trajectories. This coupling keeps the rule pool aligned with the evolving policy while allowing stable and effective behaviors to be gradually absorbed into the model itself.
What carries the argument
The shared-trajectory revision step that compares current rollouts to reference successful trajectories to update both the rule pool and the policy parameters.
If this is right
- Rules stay aligned with the current policy as it changes through interaction.
- Stable successful behaviors can be absorbed into the model parameters over time.
- The approach yields consistent gains on complex interactive tasks such as AlfWorld and WebShop.
- Sparse-reward settings receive both broad policy improvement and targeted local correction.
Where Pith is reading between the lines
- The method could reduce reliance on manually written or separately maintained rule sets.
- Similar joint-update logic might be tested in other agent architectures that separate memory from parameters.
- Over longer horizons the rule pool might serve as an interpretable audit trail of what the policy has internalized.
Load-bearing premise
That comparing current rollouts with reference successful trajectories produces useful revisions to the rule pool that remain aligned with the evolving policy without introducing errors or misalignment.
What would settle it
An experiment in which rule revisions produced by the comparison step cause the agent's decisions to degrade relative to a policy-only update baseline on the same tasks.
Figures

read the original abstract
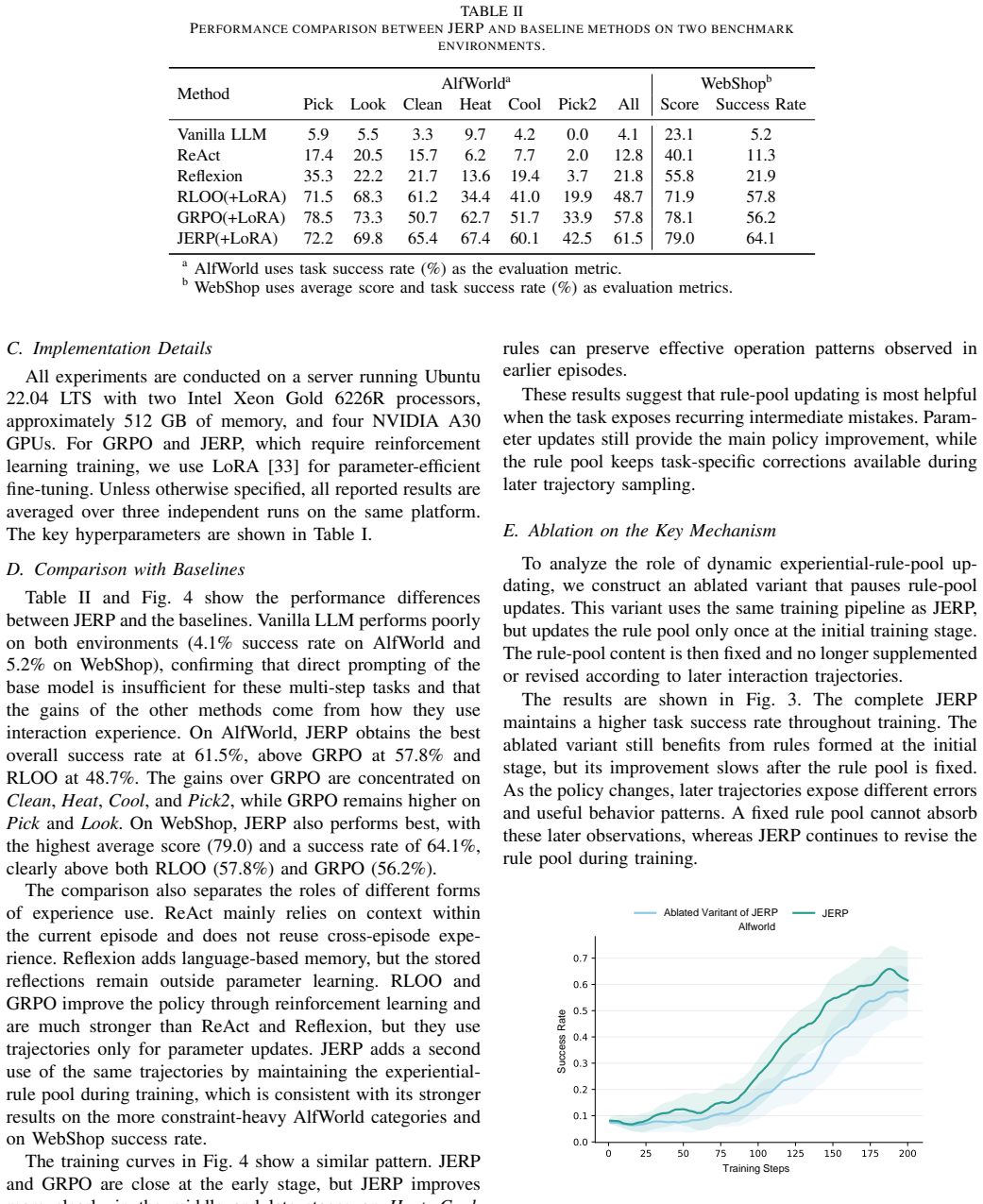
For LLM agents in multi-step interactive environments, a key challenge is to make effective use of accumulated interaction experience. Existing work has typically separated two uses of such experience: keeping it outside the model as natural-language rules for later prompting, or using trajectories and feedback to update the model parameters. The former is easy to interpret but can fall out of sync with the evolving policy; the latter improves the policy more broadly but provides only limited correction for local mistakes in sparse-reward settings. We present Joint Learning of Experiential Rules and Policies for LLM Agents (JERP), which updates a long-term experiential-rule pool and the policy from the same interaction trajectories. At decision time, JERP retrieves task-relevant rules and conditions the agent on them together with the interaction history. After each episode, it uses the collected trajectories both to optimize the policy and to revise the rule pool by comparing current rollouts with reference successful trajectories. This coupling keeps the rule pool aligned with the evolving policy while allowing stable and effective behaviors to be gradually absorbed into the model itself. Experiments on AlfWorld and WebShop show that JERP yields consistent gains in decision performance for complex interactive tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes JERP, a method for LLM agents in multi-step interactive environments that maintains a long-term experiential-rule pool and jointly updates both the rule pool and the policy parameters from the same interaction trajectories. At inference, task-relevant rules are retrieved and used to condition the agent alongside interaction history; after each episode, trajectories are used both for policy optimization and for revising the rule pool via comparison of current rollouts against reference successful trajectories. The central claim is that this coupling keeps rules aligned with the evolving policy and produces consistent decision-performance gains on complex tasks, as demonstrated on AlfWorld and WebShop.
Significance. If the empirical results and alignment mechanism hold under scrutiny, the work would offer a concrete way to combine the interpretability and stability of external natural-language rules with the broader adaptability of policy updates, addressing a recognized tension in LLM-agent literature between rule prompting and parameter tuning.
major comments (2)
- [Abstract / §3] Abstract / §3 (Method): the rule-revision step is described only as 'comparing current rollouts with reference successful trajectories' with no specification of reference selection criteria, the comparison algorithm or prompt template, or any safeguard against propagating errors when references are suboptimal or when partial information in the current rollout is useful. This mechanism is load-bearing for the claimed policy-rule alignment benefit.
- [§4] §4 (Experiments): the abstract asserts 'consistent gains' on AlfWorld and WebShop, yet the provided text contains no quantitative results, baseline comparisons, number of runs, variance estimates, or error analysis, preventing assessment of whether the joint-learning advantage is supported by the data.
minor comments (1)
- [Abstract] Abstract: the description of the retrieval step ('retrieves task-relevant rules') would benefit from a short statement of the retrieval method or similarity metric used.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The comments highlight areas where the current manuscript description is insufficiently precise, and we will revise accordingly to strengthen the presentation of the method and results.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract / §3 (Method): the rule-revision step is described only as 'comparing current rollouts with reference successful trajectories' with no specification of reference selection criteria, the comparison algorithm or prompt template, or any safeguard against propagating errors when references are suboptimal or when partial information in the current rollout is useful. This mechanism is load-bearing for the claimed policy-rule alignment benefit.
Authors: We agree that the current description in the abstract and §3 is high-level and does not provide the requested implementation details. In the revised manuscript we will expand §3 with: (i) reference selection criteria (trajectories drawn from a replay buffer of prior successful episodes, ranked by cumulative reward); (ii) the comparison procedure (an LLM prompt that performs structured difference analysis between the current rollout and the reference, then proposes candidate rule edits); (iii) the exact prompt template used; and (iv) safeguards (a reward-margin filter that only accepts a rule update when the new trajectory strictly outperforms the reference, plus an optional human-in-the-loop verification step for the initial rule pool). These additions will make the alignment mechanism explicit and address concerns about error propagation. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract asserts 'consistent gains' on AlfWorld and WebShop, yet the provided text contains no quantitative results, baseline comparisons, number of runs, variance estimates, or error analysis, preventing assessment of whether the joint-learning advantage is supported by the data.
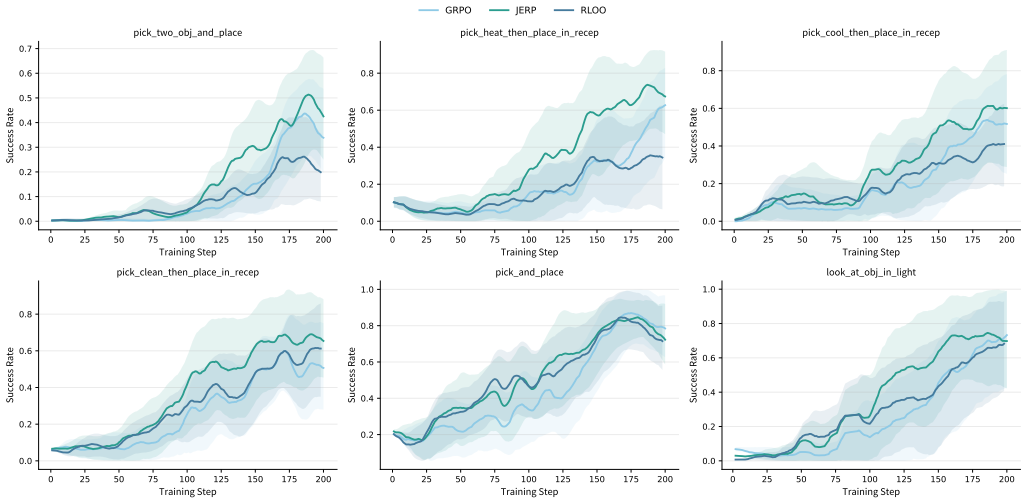
Authors: The referee is correct that the version under review lacks the quantitative experimental section. We will add a complete §4 containing: success-rate tables for AlfWorld and WebShop with means and standard deviations over multiple random seeds, direct comparisons against the listed baselines, and a short error analysis of failure modes. This will allow readers to evaluate the claimed gains. revision: yes
Circularity Check
No circularity: empirical joint-update procedure is self-contained
full rationale
The paper presents JERP as an algorithmic method that collects trajectories, optimizes the policy, and revises the rule pool via direct comparison to reference trajectories. No equations, derivations, or parameter-fitting steps are described that reduce to their own inputs. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The alignment claim is an empirical hypothesis about the procedure's effect, not a definitional or fitted tautology. This matches the default case of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agentic large language models, a survey,
A. Plaat, M. van Duijn, N. Van Stein, M. Preuss, P. van der Putten, and K. J. Batenburg, “Agentic large language models, a survey,”Journal of Artificial Intelligence Research, vol. 84, no. 29, 2025
2025
-
[2]
A survey of webagents: Towards next- generation ai agents for web automation with large foundation models,
L. Ning, Z. Liang, Z. Jiang, H. Qu, Y . Ding, W. Fan, X.-y. Wei, S. Lin, H. Liu, P. S. Yuet al., “A survey of webagents: Towards next- generation ai agents for web automation with large foundation models,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 6140–6150
2025
-
[3]
Large language models for robotics: A survey,
F. Zeng, W. Gan, Y . Wang, N. Liu, and P. S. Yu, “Large language models for robotics: A survey,”arXiv preprint arXiv:2311.07226, 2023
-
[4]
W. Liang, R. Zhou, Y . Ma, B. Zhang, S. Li, Y . Liao, and P. Kuang, “Large model empowered embodied ai: A survey on decision-making and embodied learning,”arXiv preprint arXiv:2508.10399, 2025
-
[5]
LLM-based agents for tool learning: a survey,
W. Xu, C. Huang, S. Gao, and S. Shang, “LLM-based agents for tool learning: a survey,”Data Science and Engineering, vol. 10, no. 4, pp. 1–31, 2025
2025
-
[6]
H.-a. Gao, J. Geng, W. Hua, M. Hu, X. Juan, H. Liu, S. Liu, J. Qiu, X. Qi, Y . Wuet al., “A survey of self-evolving agents: On path to artificial super intelligence,”arXiv preprint arXiv:2507.21046, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
A survey on the optimization of large language model-based agents,
S. Du, J. Zhao, J. Shi, Z. Xie, X. Jiang, Y . Bai, and L. He, “A survey on the optimization of large language model-based agents,”ACM Computing Surveys, vol. 58, no. 9, pp. 1–37, 2026
2026
-
[8]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 8634–8652
2023
-
[9]
Expel: Llm agents are experiential learners,
A. Zhao, D. Huang, Q. Xu, M. Lin, Y .-J. Liu, and G. Huang, “Expel: Llm agents are experiential learners,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 19 632–19 642
2024
-
[10]
Autoguide: Automated generation and selection of context- aware guidelines for large language model agents,
Y . Fu, D.-K. Kim, J. Kim, S. Sohn, L. Logeswaran, K. Bae, and H. Lee, “Autoguide: Automated generation and selection of context- aware guidelines for large language model agents,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 119 919– 119 948
2024
-
[11]
Automanual: Constructing instruction manuals by llm agents via interactive environ- mental learning,
M. Chen, Y . Li, Y . Yang, S. Yu, B. Lin, and X. He, “Automanual: Constructing instruction manuals by llm agents via interactive environ- mental learning,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 589–631
2024
-
[12]
Contextual experience replay for self-improvement of language agents,
Y . Liu, C. Si, K. R. Narasimhan, and S. Yao, “Contextual experience replay for self-improvement of language agents,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 14 179–14 198
2025
-
[13]
How memory management impacts llm agents: An empirical study of experience-following behavior,
Z. Xiong, Y . Lin, W. Xie, P. He, Z. Liu, J. Tang, H. Lakkaraju, and Z. Xi- ang, “How memory management impacts llm agents: An empirical study of experience-following behavior,”arXiv preprint arXiv:2505.16067, 2025
-
[14]
Group-in-group policy optimization for llm agent training,
L. Feng, Z. Xue, T. Liu, and B. An, “Group-in-group policy optimization for llm agent training,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[15]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023, pp. 1–22. 8
2023
-
[16]
Memorybank: En- hancing large language models with long-term memory,
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y . Wang, “Memorybank: En- hancing large language models with long-term memory,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 19 724–19 731
2024
-
[17]
MemGPT: Towards LLMs as Operating Systems
C. Packer, V . Fang, S. G. Patil, K. Lin, S. Wooders, and J. E. Gonzalez, “Memgpt: towards llms as operating systems.”arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
V oyager: An open-ended embodied agent with large language models,
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”Transactions on Machine Learning Research, 2024
2024
-
[19]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 68 539–68 551
2023
-
[20]
Agent workflow memory,
Z. Z. Wang, J. Mao, D. Fried, and G. Neubig, “Agent workflow memory,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 63 897–63 911
2025
-
[21]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
B. Zheng, M. Y . Fatemi, X. Jin, Z. Z. Wang, A. Gandhi, Y . Song, Y . Gu, J. Srinivasa, G. Liu, G. Neubiget al., “Skillweaver: Web agents can self-improve by discovering and honing skills,”arXiv preprint arXiv:2504.07079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
arXiv preprint arXiv:2507.06229 , year=
X. Tang, T. Qin, T. Peng, Z. Zhou, D. Shao, T. Du, X. Wei, P. Xia, F. Wu, H. Zhuet al., “Agent kb: Leveraging cross-domain experience for agentic problem solving,”arXiv preprint arXiv:2507.06229, 2025
-
[23]
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents,
Z. Tan, J. Yan, I.-H. Hsu, R. Han, Z. Wang, L. Le, Y . Song, Y . Chen, H. Palangi, G. Leeet al., “In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents,” inProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 8416–8439
2025
-
[24]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 27 730– 27 744
2022
-
[25]
arXiv preprint arXiv:2503.06072 , year=
G. Tie, Z. Zhao, D. Song, F. Wei, R. Zhou, Y . Dai, W. Yin, Z. Yang, J. Yan, Y . Suet al., “A survey on post-training of large language models,” arXiv preprint arXiv:2503.06072, 2025
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 53 728–53 741
2023
-
[28]
Direct multi-turn preference optimization for language agents,
W. Shi, M. Yuan, J. Wu, Q. Wang, and F. Feng, “Direct multi-turn preference optimization for language agents,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 2312–2324
2024
-
[29]
Alfworld: Aligning text and embodied environments for interactive learning,
M. Shridhar, X. Yuan, M.-A. Cote, Y . Bisk, A. Trischler, and M. Hausknecht, “Alfworld: Aligning text and embodied environments for interactive learning,” inInternational Conference on Learning Rep- resentations, 2021
2021
-
[30]
Webshop: Towards scalable real-world web interaction with grounded language agents,
S. Yao, H. Chen, J. Yang, and K. Narasimhan, “Webshop: Towards scalable real-world web interaction with grounded language agents,” in Advances in Neural Information Processing Systems, vol. 35, 2022, pp. 20 744–20 757
2022
-
[31]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inInternational Conference on Learning Representations, 2023
2023
-
[32]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms,
A. Ahmadian, C. Cremer, M. Gall ´e, M. Fadaee, J. Kreutzer, O. Pietquin, A. ¨Ust¨un, and S. Hooker, “Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 12 248–12 267
2024
-
[33]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022. 9
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.