ViQ: Text-Aligned Visual Quantized Representations at Any Resolution
Pith reviewed 2026-07-01 06:26 UTC · model grok-4.3
The pith
ViQ turns images into discrete tokens that match continuous vision encoders on multimodal tasks while preserving reconstruction accuracy and accelerating training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
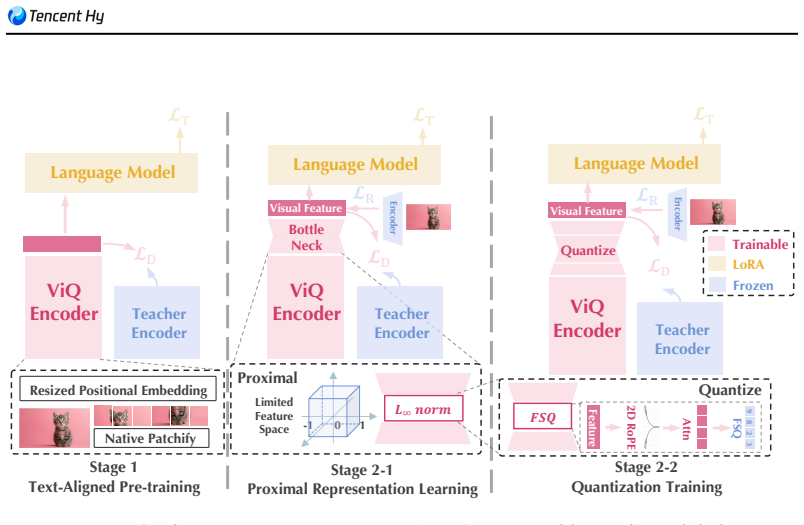
ViQ structures quantization learning into two stages: text-aligned pre-training and feature discretization. Text-aligned pre-training supplies semantic-rich supervision from a pretrained language model and equips the encoder to handle native-resolution inputs. Discretization then applies proximal representation learning to compact the feature space progressively together with a position-aware head-wise quantization mechanism that supports arbitrary resolutions. The resulting discrete representations achieve performance comparable to state-of-the-art continuous multimodal vision encoders, maintain high precision in low-level reconstruction, and enable 20-70 percent acceleration in multimodal
What carries the argument
Two-stage quantization: text-aligned pre-training to add semantic supervision followed by proximal representation learning and position-aware head-wise quantization to compact features at any resolution.
If this is right
- Discrete visual tokens become viable replacements for continuous high-dimensional features in multimodal models without sacrificing task performance.
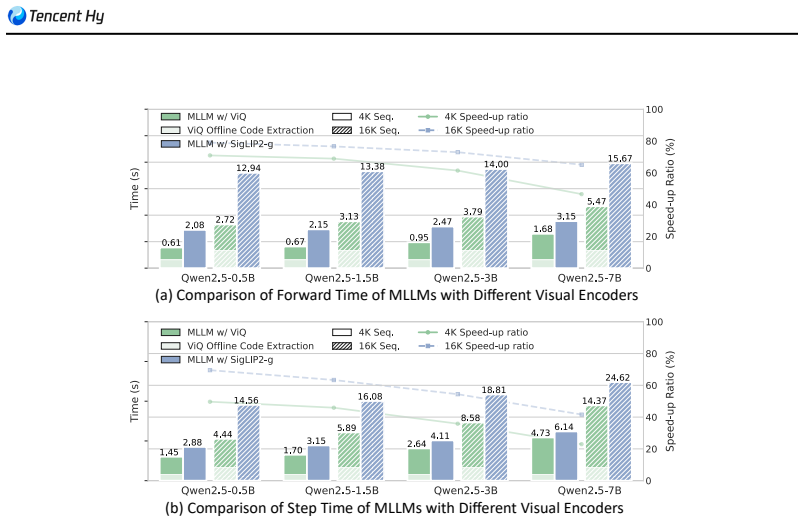
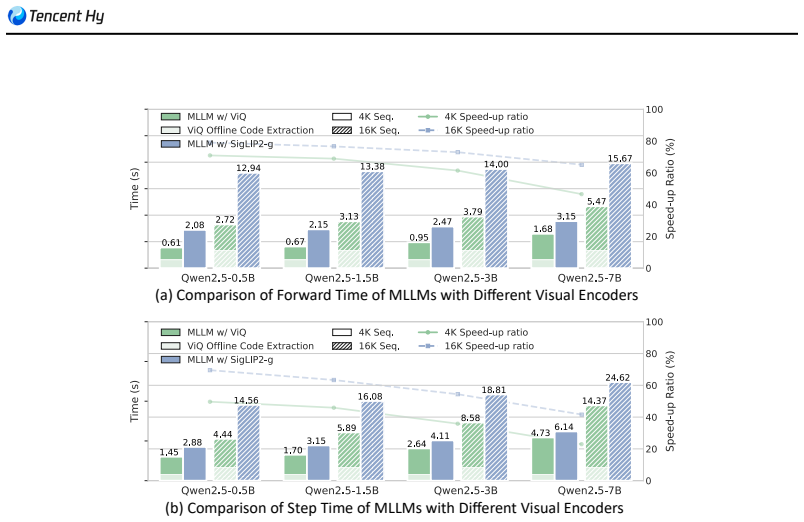
- Multimodal training pipelines can run 20-70 percent faster depending on the base language model and recipe.
- Vision encoders can process inputs at their native resolutions instead of fixed resized grids.
- Low-level reconstruction fidelity remains high even after discretization, supporting tasks that need both semantics and detail.
Where Pith is reading between the lines
- Fully discrete end-to-end multimodal models become feasible, mirroring the token-only structure of language models.
- The approach could extend to video or 3D inputs by reusing the same position-aware quantization logic.
- Efficiency gains might compound in large-scale pretraining, lowering the compute barrier for vision-language work.
Load-bearing premise
That structuring quantization into text-aligned pre-training then proximal learning and position-aware head-wise quantization can retain both semantic richness and low-level details for arbitrary-resolution inputs without unacceptable loss.
What would settle it
A controlled comparison in which ViQ representations produce substantially lower accuracy than continuous encoders on standard multimodal benchmarks while also showing visibly degraded image reconstruction or no measurable training speedup.
Figures





read the original abstract
A unified representation for text and vision is a natural pursuit, as it enables simpler multimodal modeling and more efficient training. However, representing images as discrete signals in the same way as text inevitably introduces severe information loss. Existing work struggles to balance low-level details and high-level semantics in discrete representations: reconstruction-oriented representations often lack semantic information, whereas semantically stronger features typically suffer from severe loss of detail. We present ViQ, a Visual Quantized Representations framework, which is designed to balance semantics and details in discrete representations while supporting inputs at native resolutions, thereby enabling it to serve as a unified and general discrete representation for arbitrary visual inputs. Our approach structures quantization learning into two stages: text-aligned pre-training and feature discretization. With text-aligned pre-training, we enhance the visual encoder semantic-rich supervision from the pretrained language model and enable it to process native-resolution visual inputs. During discretization, we propose a proximal representation learning strategy to progressively compact the feature space, along with a position-aware head-wise quantization mechanism that enables flexible processing of arbitrary resolutions. Extensive experiments on multimodal tasks demonstrate that ViQ achieves competitive performance compared to state-of-the-art multimodal vision encoders with continuous and high-dimensional visual features, while maintaining high precision in low-level reconstruction. We also show that multimodal training with visual quantized representations largely improves efficiency, yielding up to 20\%-70\% acceleration with different base LLMs and training recipes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViQ, a framework for text-aligned visual quantized representations supporting arbitrary resolutions. It structures quantization into two stages: text-aligned pre-training of a visual encoder with semantic supervision from a pretrained language model, followed by feature discretization via proximal representation learning and a position-aware head-wise quantization mechanism. The central claims are that ViQ achieves competitive performance on multimodal tasks relative to state-of-the-art continuous high-dimensional vision encoders while preserving high precision in low-level reconstruction, and that multimodal training with these quantized representations yields 20%-70% efficiency gains across different base LLMs and recipes.
Significance. If the performance and efficiency claims hold with the discretization stage successfully balancing semantic richness and detail preservation, ViQ would represent a meaningful step toward unified discrete multimodal representations. This could simplify modeling pipelines and reduce training costs for vision-language models handling native-resolution inputs, with potential downstream benefits for efficiency in large-scale multimodal training.
major comments (2)
- [Abstract] Abstract: the central claims of competitive performance and 20%-70% efficiency gains are asserted on the basis of 'extensive experiments' but no metrics, baselines, ablation results, error analysis, or references to specific tables/figures are supplied; this leaves the primary empirical support for the framework unverified and load-bearing for the paper's contribution.
- [Abstract] The discretization stage (text-aligned pre-training followed by proximal representation learning + position-aware head-wise quantization) is presented as resolving the semantics-vs-detail trade-off for arbitrary resolutions, yet the manuscript provides no quantitative assessment of information loss (e.g., reconstruction metrics or semantic alignment scores) that would confirm the weakest assumption does not introduce unacceptable degradation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we respond point-by-point to the major comments, clarifying the empirical support in the full paper while noting where revisions can strengthen the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of competitive performance and 20%-70% efficiency gains are asserted on the basis of 'extensive experiments' but no metrics, baselines, ablation results, error analysis, or references to specific tables/figures are supplied; this leaves the primary empirical support for the framework unverified and load-bearing for the paper's contribution.
Authors: The abstract is a concise summary constrained by length limits and therefore omits specific numbers and table citations. The full manuscript contains the supporting evidence in the Experiments section, including direct comparisons to continuous vision encoders, ablation studies on the two-stage quantization, error analyses, and efficiency measurements (20-70% gains across LLMs) reported in Tables 2-5 and Figures 4-6. We can revise the abstract to incorporate one or two key quantitative highlights and explicit table references. revision: partial
-
Referee: [Abstract] The discretization stage (text-aligned pre-training followed by proximal representation learning + position-aware head-wise quantization) is presented as resolving the semantics-vs-detail trade-off for arbitrary resolutions, yet the manuscript provides no quantitative assessment of information loss (e.g., reconstruction metrics or semantic alignment scores) that would confirm the weakest assumption does not introduce unacceptable degradation.
Authors: The manuscript reports that ViQ maintains high precision in low-level reconstruction while achieving competitive semantic performance, but we acknowledge that the abstract does not include explicit numerical assessments of the trade-off. We will add a brief statement referencing the reconstruction PSNR/SSIM metrics and semantic alignment scores from the results section to make this evidence visible in the abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a two-stage framework (text-aligned pre-training followed by proximal representation learning and position-aware head-wise quantization) whose components are introduced as novel mechanisms and whose value is asserted via separate experiments on multimodal tasks and efficiency benchmarks. No equations, predictions, or uniqueness claims are shown that reduce by construction to fitted inputs or prior self-citations; the discretization stage is presented as an independent design choice whose success is externally validated rather than presupposed. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330, 2024a. Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Data filtering networks.arXiv preprint arXiv:2309.17425,
Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander Toshev, and Vaishaal Shankar. Data filtering networks.arXiv preprint arXiv:2309.17425,
-
[4]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Adam: A Method for Stochastic Optimization
URL https://arxiv.org/abs/1412.6980. Hugo Laurenc ¸on, L ´eo Tronchon, Matthieu Cord, and Victor Sanh. What matters when building vision-language models?arXiv preprint arXiv:2405.02246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Peiyuan Zhang, Kaichen Zhang, Fanyi Pu, Xinrun Du, Yuhao Dong, Haotian Liu, Yuanhan Zhang, Ge Zhang, Chunyuan Li, et al. Lmms-eval: Accelerating the development of large multimoal models, 2024a. Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task t...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Zuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao. Oryx mllm: On-demand spatial-temporal understanding at arbitrary resolution.arXiv preprint arXiv:2409.12961, 2024c. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
-
[8]
Zhuoyan Luo, Fengyuan Shi, Yixiao Ge, Yujiu Yang, Limin Wang, and Ying Shan. Open- magvit2: An open-source project toward democratizing auto-regressive visual generation. arXiv preprint arXiv:2409.04410,
-
[9]
Unitok: A unified tokenizer for visual generation and understanding.arXiv preprint arXiv:2502.20321,
Chuofan Ma, Yi Jiang, Junfeng Wu, Jihan Yang, Xin Yu, Zehuan Yuan, Bingyue Peng, and Xiaojuan Qi. Unitok: A unified tokenizer for visual generation and understanding.arXiv preprint arXiv:2502.20321,
-
[10]
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning.arXiv preprint arXiv:2203.10244,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DINOv2: Learning Robust Visual Features without Supervision
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple. InThe Twelfth International Conference on Learning Representations. Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khali- dov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al....
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491,
work page internal anchor Pith review Pith/arXiv arXiv
- [14]
-
[15]
URL https://qwenlm.github.io/blog/qwen2. 5-vl/. Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Al- abdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Wan: Open and Advanced Large-Scale Video Generative Models
14 Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Sail-vl2 technical report.arXiv preprint arXiv:2509.14033,
Weijie Yin, Yongjie Ye, Fangxun Shu, Yue Liao, Zijian Kang, Hongyuan Dong, Haiyang Yu, Dingkang Yang, Jiacong Wang, Han Wang, et al. Sail-vl2 technical report.arXiv preprint arXiv:2509.14033,
-
[20]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025a. Yongxin Zhu, Bocheng Li, Yifei Xin, Zhihua Xia, and Linli Xu. Addressing representation collapse i...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The previously applied non-parameteric constraints like the L∞ regularization were replaced with the FSQ module. This module incorporates a quantization mechanism along the 6-dimensional feature space, followed by fully connected layers before and after quantization, along with an attention layer that adds Rotary Positional Embedding Su et al. (2024) info...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.