Glite ARF: Verifier-Driven Research with Parallel LLM Coding Agents
Pith reviewed 2026-06-29 01:12 UTC · model grok-4.3
The pith
Glite ARF uses deterministic verifier scripts to let parallel LLM coding agents handle large research projects without losing reproducibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
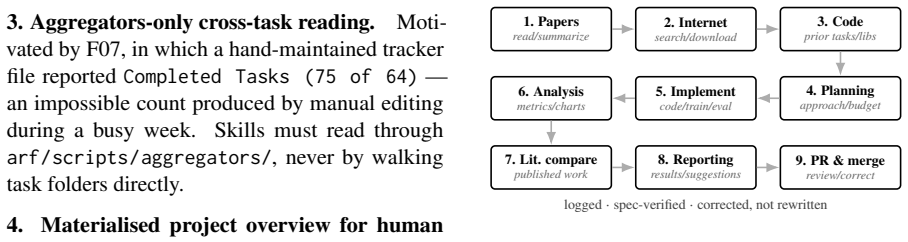
We present Glite ARF, an open-source Python framework for running many LLM coding agents in parallel on a research repository without sacrificing reproducibility or auditability. The framework defines a three-role stack: a human researcher chooses which hypotheses to test, coding agents implement individual tasks under a fixed structure, and deterministic Python verifier scripts enforce task isolation, immutability of completed work, a corrections overlay, and a materialised project overview. We call this verifier-driven research: the rules of the research process live in code that fails loudly when violated, not in prose that agents are merely asked to follow.
What carries the argument
The three-role stack of human hypothesis selection, LLM coding agents operating under fixed structure, and deterministic Python verifier scripts that enforce isolation and immutability.
If this is right
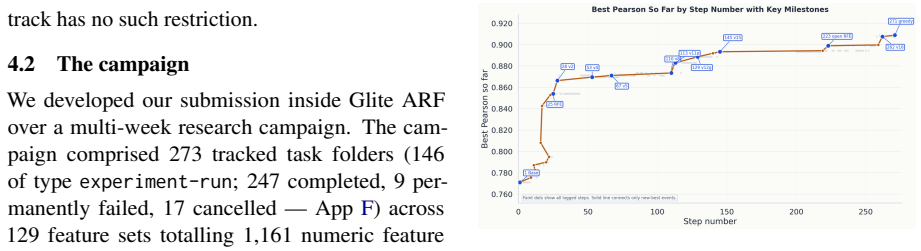
- Campaigns of 273 tracked tasks across 146 experiment runs become feasible with up to twelve parallel agents from one laptop.
- Full per-fold provenance tracking catches and removes leaking feature sets before final submission.
- The structural overhead remains around 1 percent of total wall-clock time in multiple domains.
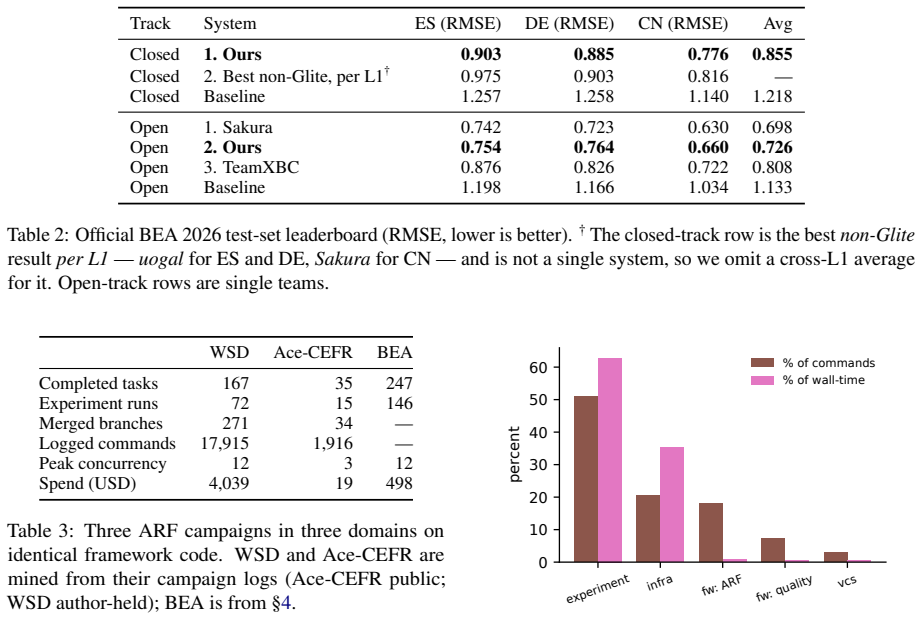
- Top placements and 29.9 to 35.9 percent RMSE reductions on a shared task are achieved at roughly 450 dollars in API cost.
Where Pith is reading between the lines
- The same verifier pattern could be adapted to enforce statistical or ethical constraints in automated experiments beyond coding tasks.
- Teams without large compute budgets might apply the framework to other benchmark competitions that reward systematic feature exploration.
- Extending the verifier layer to include automated checks for model stability across folds would be a direct next step.
Load-bearing premise
Deterministic Python verifier scripts can reliably enforce task isolation, immutability of completed work, a corrections overlay, and a materialised project overview when agents operate under a fixed structure.
What would settle it
An observed case in which an LLM agent alters a completed task or introduces undetected target leakage despite the verifier scripts running.
Figures



read the original abstract
LLM coding agents make it tempting to automate empirical research by delegating experiments to them directly, but naive delegation does not scale to large projects: low-rate instruction lapses compound into broken, irreproducible artefacts. To address this problem, we present Glite ARF, an open-source Python framework for running many LLM coding agents in parallel on a research repository without sacrificing reproducibility or auditability. The framework defines a three-role stack: a human researcher chooses which hypotheses to test, coding agents (Claude Code, Codex CLI) implement individual tasks under a fixed structure, and deterministic Python verifier scripts enforce task isolation, immutability of completed work, a corrections overlay, and a materialised project overview. We call this verifier-driven research: the rules of the research process live in code that fails loudly when violated, not in prose that agents are merely asked to follow. Using Glite ARF, we developed our submission to the BEA 2026 vocabulary-difficulty shared task, placing first in the closed track and second in the open track on all three target languages (Spanish, German, Mandarin) and reducing the official baseline RMSE by 29.9% (closed) and 35.9% (open). The campaign comprised 273 tracked tasks (146 experiment runs) across 129 feature sets, run by up to twelve parallel agents orchestrated from a single laptop - with some model training on rented A100s - at approximately \$450 in LLM API spend (\$498 total third-party cost), and structured per-fold provenance let us catch and strip four target-leaking feature sets, correcting an implausible 0.609 RMSE to 0.802. Across three campaigns in three domains, the framework's structural machinery adds only about 1% of wall-clock time. Framework and a public demo project accompany this paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Glite ARF, an open-source Python framework for orchestrating parallel LLM coding agents (e.g., Claude Code, Codex CLI) on research repositories. It defines a three-role stack in which a human selects hypotheses, agents implement tasks under a fixed structure, and deterministic verifier scripts enforce isolation, immutability, corrections, and project overview. The central demonstration is its use in the BEA 2026 vocabulary-difficulty shared task, yielding first place (closed track) and second place (open track) across Spanish, German, and Mandarin, with 29.9% and 35.9% RMSE reductions versus the baseline, 273 tracked tasks, leakage detection via provenance, ~$450 LLM spend, and ~1% overhead across three campaigns.
Significance. If the reported outcomes hold, the work supplies a concrete, low-overhead method for scaling LLM-assisted empirical research while embedding auditability in executable verifiers rather than prose instructions. Notable strengths include the open-source framework release with public demo project, explicit per-fold provenance that caught four leaking feature sets, and external validation through shared-task placements rather than internal benchmarks alone. These elements directly address reproducibility concerns in multi-agent LLM workflows.
minor comments (2)
- Abstract: the description of verifier enforcement (task isolation, immutability, corrections overlay, materialised overview) remains high-level; a short concrete example of one verifier rule or its failure mode would clarify the 'verifier-driven' mechanism without lengthening the paper.
- Abstract: the statement that the framework was used 'across three campaigns in three domains' is mentioned only in passing; a one-sentence summary of the other two domains would give readers a fuller sense of generality.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the framework's strengths in auditability and external validation, and recommendation to accept.
Circularity Check
No significant circularity identified
full rationale
The paper introduces Glite ARF as a software framework with a three-role stack and deterministic verifiers, then validates it via external shared-task results (BEA 2026: first/second place, 29.9–35.9% RMSE reduction across languages, leakage detection in 273 tasks). No equations, parameter fits, or self-citations appear in the provided text; the central claim rests on reproducible external outcomes and open-source release rather than any reduction to prior inputs or definitions by construction. This matches the default expectation of a non-circular empirical tool paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coding agents will produce code that can be verified by deterministic scripts when given a fixed structure.
Reference graph
Works this paper leans on
-
[1]
Findings of the
Felice, Mariano and Skidmore, Lucy , booktitle =. Findings of the. 2026 , note =
2026
-
[2]
2024 , doi =
Knowledge-based Vocabulary Lists , author =. 2024 , doi =
2024
-
[3]
2026 , url =
Philippov, Vassili and Andreev, Dmitrii and Katunin, Pavel and Nikolaev, Anton , booktitle =. 2026 , url =
2026
-
[4]
2026 , howpublished =
Glite Autonomous Research Framework (Glite ARF) , author =. 2026 , howpublished =
2026
-
[5]
2026 , howpublished =
2026
-
[9]
2023 , eprint =
Li, Guohao and Hammoud, Hasan Abed Al Kader and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , booktitle =. 2023 , eprint =
2023
-
[10]
2025 , howpublished =
smolagents: a barebones library for agents that think in code , author =. 2025 , howpublished =
2025
-
[11]
2023 , howpublished =
2023
-
[12]
2025 , howpublished =
Claude Code , author =. 2025 , howpublished =
2025
-
[13]
2025 , howpublished =
2025
-
[14]
Gauthier, Paul , year =. Aider:
-
[16]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =. 2024 , eprint =
2024
-
[17]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =. 2024 , eprint =
2024
-
[18]
Karpathy, Andrej , year =
-
[21]
2026 , howpublished =
Autoreason: Self-Refinement That Knows When to Stop , author =. 2026 , howpublished =
2026
-
[26]
2025 , eprint =
Automated Design of Agentic Systems , author =. 2025 , eprint =
2025
-
[28]
2025 , eprint =
From Automation to Autonomy: A Survey on Large Language Models in Scientific Discovery , author =. 2025 , eprint =
2025
-
[30]
2024 , eprint =
Huang, Qian and Vora, Jian and Liang, Percy and Leskovec, Jure , booktitle =. 2024 , eprint =
2024
-
[34]
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. 2026. https://arxiv.org/abs/2603.02766 EvoSkill : Automated skill discovery for multi-agent systems . Preprint, arXiv:2603.02766
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Anthropic . 2025. Claude code. https://www.anthropic.com/claude-code
2025
- [36]
-
[37]
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander M a dry. 2025. https://arxiv.org/abs/2410.07095 MLE-bench : Evaluating machine learning agents on machine learning engineering . In The Thirteenth International Conference on Learning Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Hui Chen, Miao Xiong, Yujie Lu, Wei Han, Ailin Deng, Yufei He, Jiaying Wu, Yibo Li, Yue Liu, and Bryan Hooi. 2025. https://arxiv.org/abs/2505.19955 MLR-Bench : Evaluating AI agents on open-ended machine learning research . Preprint, arXiv:2505.19955. NeurIPS 2025 Datasets & Benchmarks Track
-
[39]
CrewAI Inc. 2023. CrewAI : Framework for orchestrating role-playing, autonomous AI agents. GitHub: https://github.com/crewAIInc/crewAI
2023
-
[40]
Mariano Felice and Lucy Skidmore. 2026. Findings of the BEA 2026 shared task on vocabulary difficulty prediction for English learners. In Proceedings of the 21st Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2026), San Diego, California. Association for Computational Linguistics. To appear; co-located with ACL 2026
2026
-
[41]
Paul Gauthier. 2023. Aider: AI pair programming in your terminal. GitHub: https://github.com/Aider-AI/aider
2023
-
[42]
Glite Tech Ltd . 2026. research-ace-cefr : A public Glite ARF demo project on conversational-text CEFR difficulty prediction. https://github.com/GliteTech/research-ace-cefr. Apache-2.0 license
2026
-
[43]
Glite Tech Ltd , Vassili Philippov, Pavel Katunin, Dmitry Andreev, and Igor Ostanin. 2026. Glite autonomous research framework (glite arf). https://github.com/GliteTech/glite-arf. Version 0.1.0, Apache-2.0 license
2026
-
[44]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and J \"u rgen Schmidhuber. 2024. https://arxiv.org/abs/2308.00352 MetaGPT : Meta programming for a multi-agent collaborative framework . In The Twelfth International ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Shengran Hu, Cong Lu, and Jeff Clune. 2025. https://arxiv.org/abs/2408.08435 Automated design of agentic systems . Preprint, arXiv:2408.08435. ICLR 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [46]
-
[47]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. https://arxiv.org/abs/2310.06770 SWE-bench : Can language models resolve real-world GitHub issues? In The Twelfth International Conference on Learning Representations (ICLR)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Andrej Karpathy. 2026. autoresearch : AI agents running research on single- GPU nanochat training automatically. GitHub: https://github.com/karpathy/autoresearch
2026
-
[49]
David Kogan, Max Schumacher, Sam Nguyen, Masanori Suzuki, Melissa Smith, Chloe Sophia Bellows, and Jared Bernstein. 2025. https://arxiv.org/abs/2506.14046 Ace-CEFR : A dataset for automated evaluation of the linguistic difficulty of conversational texts for LLM applications . Preprint, arXiv:2506.14046
-
[50]
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney Von Arx, Ryan Bloom, Thomas Broadley, Haoxing Du, Brian Goodrich, Nikola Jurkovic, Luke Harold Miles, Seraphina Nix, Tao Lin, Neev Parikh, and 6 others. 2025. https://arxiv.org/abs/2503.14499 Measuring AI ability to complete long softwa...
-
[51]
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. https://arxiv.org/abs/2303.17760 CAMEL : Communicative agents for ``mind'' exploration of large language model society . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, and 3 others. 2024. https://arxiv.org/abs/2308.03688 AgentBench : Evaluating LLMs as agents . Preprint, arXiv:2308.03688. ICLR 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. https://arxiv.org/abs/2408.06292 The AI scientist: Towards fully automated open-ended scientific discovery . Preprint, arXiv:2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
OpenAI . 2025. Codex CLI : a lightweight coding agent that runs in your terminal. GitHub: https://github.com/openai/codex
2025
-
[55]
Vassili Philippov, Dmitrii Andreev, Pavel Katunin, and Anton Nikolaev. 2026. https://aclanthology.org/2026.bea-1.78/ Glite at BEA 2026 shared task 1: Holistic difficulty models dominate, feature engineering closes the gap in L1 -aware vocabulary difficulty prediction . In Proceedings of the 21st Workshop on Innovative Use of NLP for Building Educational A...
2026
-
[56]
Ao Qu, Han Zheng, Zijian Zhou, Yihao Yan, Yihong Tang, Shao Yong Ong, Fenglu Hong, Kaichen Zhou, Chonghe Jiang, Minwei Kong, Jiacheng Zhu, Xuan Jiang, Sirui Li, Cathy Wu, Bryan Kian Hsiang Low, Jinhua Zhao, and Paul Pu Liang. 2026. https://arxiv.org/abs/2604.01658 CORAL : Towards autonomous multi-agent evolution for open-ended discovery . Preprint, arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Aymeric Roucher, Albert Villanova del Moral, Thomas Wolf, Leandro von Werra, and Erik Kaunism \"a ki. 2025. smolagents: a barebones library for agents that think in code. GitHub: https://github.com/huggingface/smolagents
2025
-
[58]
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. 2025. https://arxiv.org/abs/2501.04227 Agent laboratory: Using LLM agents as research assistants . Preprint, arXiv:2501.04227
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Norbert Schmitt, Karen Dunn, Barry O'Sullivan, Laurence Anthony, and Benjamin Kremmel. 2024. https://doi.org/10.3138/9781800504158 Knowledge-based Vocabulary Lists , volume 5 of British Council Monographs on Modern Language Testing. University of Toronto Press
-
[60]
SHL0MS and Hermes Agent . 2026. Autoreason: Self-refinement that knows when to stop. Nous Research: https://github.com/NousResearch/autoreason
2026
- [61]
-
[62]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, and 5 others. 2024. https://arxiv.org/abs/2407.16741 OpenHands : An open platform for AI software develope...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. 2023. https://arxiv.org/abs/2308.08155 AutoGen : Enabling next-gen LLM applications via multi-agent conversation . Preprint, arXiv:2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. 2025. https://arxiv.org/abs/2504.08066 The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search . Preprint, arXiv:2504.08066
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. https://arxiv.org/abs/2405.15793 SWE-agent : Agent-computer interfaces enable automated software engineering . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [66]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.