From Signals to Transfer: A Factorised Study of Probe-Based Uncertainty Estimation in Large Language Models
Pith reviewed 2026-06-29 05:02 UTC · model grok-4.3
The pith
Factorised study shows raw hidden states hard to beat in-domain for LLM uncertainty probes but structured features are more robust under distribution shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
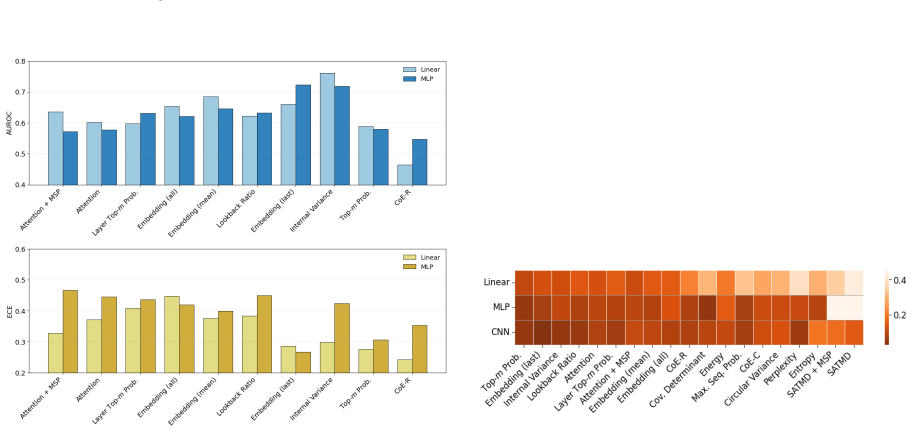
Under matched conditions that isolate feature design, data construction, and evaluation setting, raw hidden states and attention features are difficult to outperform in-domain, yet structured and compressed features prove more robust under distribution shift; prompting and label construction significantly affect probe behaviour; and benchmark-based pretrained probes transfer reasonably well to open-ended factual generation.
What carries the argument
The factorised study design that holds all but one variable matched across experiments to isolate the separate contributions of feature choice, training data, and evaluation setting.
If this is right
- In-domain performance alone is insufficient to measure progress in probe-based uncertainty estimation.
- Structured and compressed features should be preferred when probes must operate under distribution shift.
- Prompting and label construction must be treated as first-class design choices rather than afterthoughts.
- Benchmark-based pretrained probes can serve as stable off-the-shelf baselines for open-ended factual generation tasks.
Where Pith is reading between the lines
- Future evaluations of uncertainty estimators should routinely include explicit distribution-shift tests rather than relying on in-domain metrics.
- The transfer results suggest that pretrained probes could reduce the need for task-specific retraining across different generation settings.
- Extending the same factorised design to other uncertainty methods might reveal whether the in-domain versus shift pattern holds beyond probes.
Load-bearing premise
The chosen matched conditions and distribution-shift setups isolate the contributions of feature design, training data construction, and evaluation setting without residual confounding from model choice or prompt formatting details.
What would settle it
A replication under the same matched conditions that finds raw hidden states still outperform structured features even after distribution shift would falsify the robustness claim.
Figures






read the original abstract
Probe-based uncertainty estimation (UE) has emerged as a prominent approach to detect hallucinations in Large Language Models (LLMs) by learning uncertainty from internal model signals. Yet, recent methods vary simultaneously across feature design, training data construction, and evaluation setting, obscuring what actually drives performance. To address this issue, we propose a factorised study of probe-based UE under matched conditions. Our results show that raw hidden states and attention features are difficult to outperform in-domain. However, under distribution shift, structured and compressed features are more robust, suggesting that in-domain performance alone is insufficient to measure progress. Furthermore, prompting and label construction significantly affect probe behaviour. Building on these best-practice findings, we train benchmark-based pretrained probes that transfer reasonably well to open-ended factual generation, providing a stable off-the-shelf baseline. Our work encourages more deployment-oriented evaluation of probe-based uncertainty estimators. The code repository is available at https://github.com/ponhvoan/ProbeUE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a factorised empirical study of probe-based uncertainty estimation (UE) for hallucination detection in LLMs. It varies feature design (raw hidden states/attention vs. structured/compressed), training data construction, and evaluation setting under matched conditions, reporting that raw features are difficult to outperform in-domain while structured features are more robust under distribution shift. Prompting and label construction are found to significantly affect probe behaviour, and benchmark-based pretrained probes are shown to transfer reasonably well to open-ended factual generation, supporting a call for deployment-oriented evaluation.
Significance. If the matched-conditions factorisation holds without residual confounding, the results would provide actionable best-practice guidance on feature choice and evaluation for probe-based UE, highlighting that in-domain performance is an incomplete proxy for progress and supplying a stable off-the-shelf baseline for factual-generation settings.
major comments (2)
- [Abstract] Abstract (factorised study design): The attribution of robustness advantages under distribution shift to structured/compressed features requires that prompt formatting, label construction, and base-model choice are demonstrably orthogonal to feature type; the manuscript provides no explicit verification (e.g., interaction tables or ablation on prompt-feature crosses) that these factors do not interact, which is load-bearing for the claim that in-domain performance alone is insufficient.
- [Abstract] Transfer results paragraph: The statement that benchmark-based pretrained probes 'transfer reasonably well' to open-ended factual generation is presented without quantitative metrics, error bars, or explicit baselines, preventing assessment of whether the transfer performance supports the deployment-oriented recommendation.
minor comments (1)
- [Abstract] The abstract states that code is available at the cited GitHub link but does not indicate whether the repository contains the exact experimental configurations, random seeds, and data splits used for the reported factorised comparisons.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our factorised study. Below we respond point-by-point to the major comments. We have revised the manuscript where the comments identify gaps that can be addressed without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (factorised study design): The attribution of robustness advantages under distribution shift to structured/compressed features requires that prompt formatting, label construction, and base-model choice are demonstrably orthogonal to feature type; the manuscript provides no explicit verification (e.g., interaction tables or ablation on prompt-feature crosses) that these factors do not interact, which is load-bearing for the claim that in-domain performance alone is insufficient.
Authors: Our experimental design holds prompt formatting, label construction, and base-model choice fixed while varying only the feature type, which by construction isolates the contribution of feature design under matched conditions. This matching was applied uniformly across all in-domain and distribution-shift evaluations. We acknowledge that the manuscript does not include explicit interaction tables or prompt-feature cross-ablation results. To further substantiate the orthogonality claim, we will add a supplementary table summarising performance across a small set of prompt variations crossed with feature types. revision: partial
-
Referee: [Abstract] Transfer results paragraph: The statement that benchmark-based pretrained probes 'transfer reasonably well' to open-ended factual generation is presented without quantitative metrics, error bars, or explicit baselines, preventing assessment of whether the transfer performance supports the deployment-oriented recommendation.
Authors: We agree that the abstract phrasing is qualitative and would benefit from supporting numbers to allow readers to evaluate the transfer claim. The full paper reports concrete metrics (including means and standard deviations across seeds) and comparisons against simple baselines in the transfer experiments. We will revise the abstract to include the key quantitative results and error bars from those experiments so that the statement is self-contained and evidence-based. revision: yes
Circularity Check
Empirical ablation study with no derivation chain
full rationale
This is an empirical factorised study reporting performance comparisons across feature designs, data constructions, and evaluation settings under matched conditions. No equations, derivations, or predictions are presented that reduce reported outcomes to quantities defined by the same fit or by self-citation chains. Central claims rest on experimental metrics rather than any self-definitional or fitted-input reductions, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Internal State of an LLM Knows When It ' s Lying
Azaria, Amos and Mitchell, Tom. The Internal State of an LLM Knows When It ' s Lying. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.68
-
[2]
P o LLM graph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics
Zhu, Derui and Chen, Dingfan and Li, Qing and Chen, Zongxiong and Ma, Lei and Grossklags, Jens and Fritz, Mario. P o LLM graph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.294
-
[3]
arXiv preprint arXiv:2604.15741 , url =
Learning Uncertainty from Sequential Internal Dispersion in Large Language Models , author=. arXiv preprint arXiv:2604.15741 , url =
-
[4]
Towards Harmonized Uncertainty Estimation for Large Language Models
Li, Rui and Long, Jing and Qi, Muge and Xia, Heming and Sha, Lei and Wang, Peiyi and Sui, Zhifang. Towards Harmonized Uncertainty Estimation for Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1118
-
[5]
arXiv preprint arXiv:2604.00445 , year=
Towards Reliable Truth-Aligned Uncertainty Estimation in Large Language Models , author=. arXiv preprint arXiv:2604.00445 , year=
-
[6]
Prompt-Guided Internal States for Hallucination Detection of Large Language Models
Zhang, Fujie and Yu, Peiqi and Yi, Biao and Zhang, Baolei and Li, Tong and Liu, Zheli. Prompt-Guided Internal States for Hallucination Detection of Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1058
-
[7]
arXiv preprint arXiv:2310.06824 , year=
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
-
[8]
arXiv preprint arXiv:2212.03827 , year=
Discovering latent knowledge in language models without supervision , author=. arXiv preprint arXiv:2212.03827 , year=
-
[9]
A Comprehensive Survey of Hallucination in Large Language, Image, Video and Audio Foundation Models
Sahoo, Pranab and Meharia, Prabhash and Ghosh, Akash and Saha, Sriparna and Jain, Vinija and Chadha, Aman. A Comprehensive Survey of Hallucination in Large Language, Image, Video and Audio Foundation Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.685
-
[10]
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , title =. 2025 , issue_date =. doi:10.1145/3703155 , journal =
-
[11]
Unsupervised Hallucination Detection by Inspecting Reasoning Processes
Srey, Ponhvoan and Wu, Xiaobao and Luu, Anh Tuan. Unsupervised Hallucination Detection by Inspecting Reasoning Processes. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1124
-
[12]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Zhang, Yue and Li, Yafu and Cui, Leyang and Cai, Deng and Liu, Lemao and Fu, Tingchen and Huang, Xinting and Zhao, Enbo and Zhang, Yu and Chen, Yulong and Wang, Longyue and Luu, Anh Tuan and Bi, Wei and Shi, Freda and Shi, Shuming. Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models. Computational Linguistics. 2025. doi:10.116...
-
[13]
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM -Polygraph
Vashurin, Roman and Fadeeva, Ekaterina and Vazhentsev, Artem and Rvanova, Lyudmila and Vasilev, Daniil and Tsvigun, Akim and Petrakov, Sergey and Xing, Rui and Sadallah, Abdelrahman and Grishchenkov, Kirill and Panchenko, Alexander and Baldwin, Timothy and Nakov, Preslav and Panov, Maxim and Shelmanov, Artem. Benchmarking Uncertainty Quantification Method...
-
[14]
Vazhentsev, Artem and Rvanova, Lyudmila and Lazichny, Ivan and Panchenko, Alexander and Panov, Maxim and Baldwin, Timothy and Shelmanov, Artem. Token-Level Density-Based Uncertainty Quantification Methods for Eliciting Truthfulness of Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Co...
-
[15]
Shelmanov, Artem and Fadeeva, Ekaterina and Tsvigun, Akim and Tsvigun, Ivan and Xie, Zhuohan and Kiselev, Igor and Daheim, Nico and Zhang, Caiqi and Vazhentsev, Artem and Sachan, Mrinmaya and Nakov, Preslav and Baldwin, Timothy. A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Output...
-
[16]
LM -Polygraph: Uncertainty Estimation for Language Models
Fadeeva, Ekaterina and Vashurin, Roman and Tsvigun, Akim and Vazhentsev, Artem and Petrakov, Sergey and Fedyanin, Kirill and Vasilev, Daniil and Goncharova, Elizaveta and Panchenko, Alexander and Panov, Maxim and Baldwin, Timothy and Shelmanov, Artem. LM -Polygraph: Uncertainty Estimation for Language Models. Proceedings of the 2023 Conference on Empirica...
-
[17]
LLM Factoscope: Uncovering LLM s' Factual Discernment through Measuring Inner States
He, Jinwen and Gong, Yujia and Lin, Zijin and Wei, Cheng ' an and Zhao, Yue and Chen, Kai. LLM Factoscope: Uncovering LLM s' Factual Discernment through Measuring Inner States. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.608
-
[18]
Chuang, Yung-Sung and Qiu, Linlu and Hsieh, Cheng-Yu and Krishna, Ranjay and Kim, Yoon and Glass, James R. Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.84
-
[19]
Do Androids Know They ' re Only Dreaming of Electric Sheep?
CH-Wang, Sky and Van Durme, Benjamin and Eisner, Jason and Kedzie, Chris. Do Androids Know They ' re Only Dreaming of Electric Sheep?. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.260
-
[20]
Too Consistent to Detect: A Study of Self-Consistent Errors in LLM s
Tan, Hexiang and Sun, Fei and Liu, Sha and Su, Du and Cao, Qi and Chen, Xin and Wang, Jingang and Cai, Xunliang and Wang, Yuanzhuo and Shen, Huawei and Cheng, Xueqi. Too Consistent to Detect: A Study of Self-Consistent Errors in LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.238
-
[21]
Journal of Machine Learning Research , volume=
Uqlm: A python package for uncertainty quantification in large language models , author=. Journal of Machine Learning Research , volume=
-
[22]
and Yilmaz, Emine and Shi, Shuming and Tu, Zhaopeng , title =
Ye, Fanghua and Yang, Mingming and Pang, Jianhui and Wang, Longyue and Wong, Derek F. and Yilmaz, Emine and Shi, Shuming and Tu, Zhaopeng , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[23]
Factual Confidence of LLM s: on Reliability and Robustness of Current Estimators
Mahaut, Mat. Factual Confidence of LLM s: on Reliability and Robustness of Current Estimators. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.250
-
[24]
arXiv preprint arXiv:2511.03166 , year=
Measuring Aleatoric and Epistemic Uncertainty in LLMs: Empirical Evaluation on ID and OOD QA Tasks , author=. arXiv preprint arXiv:2511.03166 , year=
-
[25]
The Illusion of Progress: Re-evaluating Hallucination Detection in LLM s
Janiak, Denis and Binkowski, Jakub and Sawczyn, Albert and Gabrys, Bogdan and Shwartz-Ziv, Ravid and Kajdanowicz, Tomasz Jan. The Illusion of Progress: Re-evaluating Hallucination Detection in LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1761
-
[26]
Advances in Neural Information Processing Systems , volume=
Reasoning models better express their confidence , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2501.09775 , year=
Multiple choice questions: Reasoning makes large language models (llms) more self-confident even when they are wrong , author=. arXiv preprint arXiv:2501.09775 , year=
-
[28]
Reasoning about Uncertainty: Do Reasoning Models Know When They Don ' t Know?
Mei, Zhiting and Zhang, Christina and Yin, Tenny and Lidard, Justin and Sho, Ola and Majumdar, Anirudha. Reasoning about Uncertainty: Do Reasoning Models Know When They Don ' t Know?. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.178
-
[29]
Han, Jiatong and Band, Neil and Razzak, Muhammed and Kossen, Jannik and Rudner, Tim G. J. and Gal, Yarin. Simple Factuality Probes Detect Hallucinations in Long-Form Natural Language Generation. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.880
-
[30]
C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan. C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/...
-
[31]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[32]
Welbl, Johannes and Liu, Nelson F. and Gardner, Matt. Crowdsourcing Multiple Choice Science Questions. Proceedings of the 3rd Workshop on Noisy User-generated Text. 2017. doi:10.18653/v1/W17-4413
-
[33]
Mallen, Alex and Asai, Akari and Zhong, Victor and Das, Rajarshi and Khashabi, Daniel and Hajishirzi, Hannaneh. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023...
-
[34]
Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies
Geva, Mor and Khashabi, Daniel and Segal, Elad and Khot, Tushar and Roth, Dan and Berant, Jonathan. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00370
-
[35]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina. B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[36]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[37]
2026 , note =
Gemini 3.1 Flash-Lite , howpublished =. 2026 , note =
2026
-
[38]
2026 , note =
Introducing GPT‑5.4 mini and nano , howpublished =. 2026 , note =
2026
-
[39]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[40]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[41]
arXiv preprint arXiv:2503.19786 , volume=
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , volume=. 2025 , publisher=
Pith/arXiv arXiv 2025
-
[42]
Proceedings of the 23rd international conference on Machine learning , pages=
The relationship between Precision-Recall and ROC curves , author=. Proceedings of the 23rd international conference on Machine learning , pages=. 2006 , url=
2006
-
[43]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[44]
International Conference on Learning Representations , volume=
Latent space chain-of-embedding enables output-free llm self-evaluation , author=. International Conference on Learning Representations , volume=. 2025 , url=
2025
-
[45]
IEEE Transactions on Software Engineering , volume=
Look before you leap: An exploratory study of uncertainty analysis for large language models , author=. IEEE Transactions on Software Engineering , volume=. 2025 , publisher=
2025
-
[46]
Advances in neural information processing systems , volume=
Energy-based out-of-distribution detection , author=. Advances in neural information processing systems , volume=. 2020 , url=
2020
-
[47]
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Su, Weihang and Wang, Changyue and Ai, Qingyao and Hu, Yiran and Wu, Zhijing and Zhou, Yujia and Liu, Yiqun. Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.854
-
[48]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[49]
A lign S core: Evaluating Factual Consistency with A Unified Alignment Function
Zha, Yuheng and Yang, Yichi and Li, Ruichen and Hu, Zhiting. A lign S core: Evaluating Factual Consistency with A Unified Alignment Function. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.634
-
[50]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=. 2022 , url=
2022
-
[51]
arXiv preprint arXiv:2509.03531 , year=
Real-time detection of hallucinated entities in long-form generation , author=. arXiv preprint arXiv:2509.03531 , year=
-
[52]
Duan, Jinhao and Cheng, Hao and Wang, Shiqi and Zavalny, Alex and Wang, Chenan and Xu, Renjing and Kailkhura, Bhavya and Xu, Kaidi. Shifting Attention to Relevance: Towards the Predictive Uncertainty Quantification of Free-Form Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa...
-
[53]
arXiv preprint arXiv:2302.09664 , year=
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
-
[54]
FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh. FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[55]
arXiv preprint arXiv:2310.03951 , year=
Chain of natural language inference for reducing large language model ungrounded hallucinations , author=. arXiv preprint arXiv:2310.03951 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.