Improving Adversarial Robustness via Activation Amplification and Attenuation
Pith reviewed 2026-06-29 04:59 UTC · model grok-4.3
The pith
Learning to amplify non-robust features via activation scaling improves robustness when the scaling is reversed for attenuation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that training the scaling parameters in amplification mode to serve as negative references in contrastive and ranking losses simultaneously improves the effectiveness of those same parameters, when the sign is flipped, at attenuating adversarial perturbations during inference.
What carries the argument
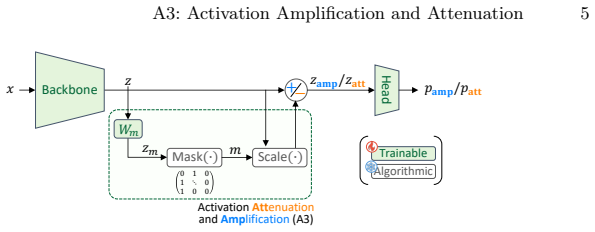
The A3 module, which dynamically rescales activations using a learnable mask and magnitude-derived scaling factor, with the sign of the scaling operation flipped to switch between amplification for loss construction and attenuation for robust inference.
If this is right
- Adversarial robustness improves consistently when A3 is integrated into different network backbones.
- The approach maintains clean accuracy while gaining robustness.
- Only a small number of additional parameters are required.
- The module adds negligible computational and memory cost compared with existing plug-in defenses.
Where Pith is reading between the lines
- The contrastive losses built from amplified signals may provide a direct way to target non-robust features without explicit pruning or masking.
- The sign-flip reuse pattern could be tested on other perturbation-sensitive components inside networks.
- Further experiments could check whether amplification-mode training helps against non-adversarial distribution shifts.
Load-bearing premise
That the same learnable parameters can be reused for both amplification and attenuation by flipping the sign without creating optimization conflicts or harming clean-data performance.
What would settle it
Training A3 in amplification mode and then measuring whether attenuation-mode robustness metrics on standard adversarial benchmarks remain no better than a baseline network without A3.
Figures



read the original abstract
The existence of adversarial attacks is often attributed to the presence of non-robust features in neural networks. While prior defenses reduce their impact via pruning, masking, or feature recalibration, we instead propose to jointly learn to amplify and attenuate these signals through a simple activation scaling mechanism. To this end, we introduce Activation Amplification and Attenuation (A3), a lightweight plug-in module that enhances adversarial robustness with minimal modifications of the activations. A3 dynamically rescales the activations using a learnable mask and a scaling factor derived from the original activation magnitudes. The influence of adversarial perturbations can be amplified or attenuated using the same learnable parameters by simply flipping the sign of the scaling operation. The amplified signals serve as negative references to construct novel contrastive and ranking loss functions. Experimental analysis shows that learning to degrade the predictions in amplification mode simultaneously improves adversarial robustness in attenuation mode. Moreover, A3 relies on only a small number of learnable parameters, with most of its behavior being determined by the scaling mechanism rather than additional network capacity. Extensive experiments demonstrate that integrating A3 into different backbones, datasets, and training methods consistently improves adversarial robustness while introducing negligible computational and memory overhead compared to existing plug-in modules. Code is available at: https://github.com/tgoncalv/A3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Activation Amplification and Attenuation (A3), a lightweight plug-in module that introduces a learnable mask and scaling factor derived from activation magnitudes. During training, the module amplifies non-robust signals to serve as negatives in novel contrastive and ranking losses; at inference the same parameters are reused for attenuation by flipping the sign of the scaling operation. The central claim is that this joint procedure yields consistent adversarial robustness gains across backbones, datasets, and training regimes while adding negligible overhead, with most behavior determined by the scaling mechanism rather than extra capacity.
Significance. If the sign-flip transfer holds without optimization conflicts or clean-accuracy degradation, A3 would supply a simple, low-parameter defense that exploits the same learned mask for both degradation and protection. The code release supports reproducibility. The approach is internally consistent as an empirical procedure but its load-bearing assumption—that parameters optimized to degrade predictions under amplification remain effective under sign-flipped attenuation—requires explicit verification to establish broader utility.
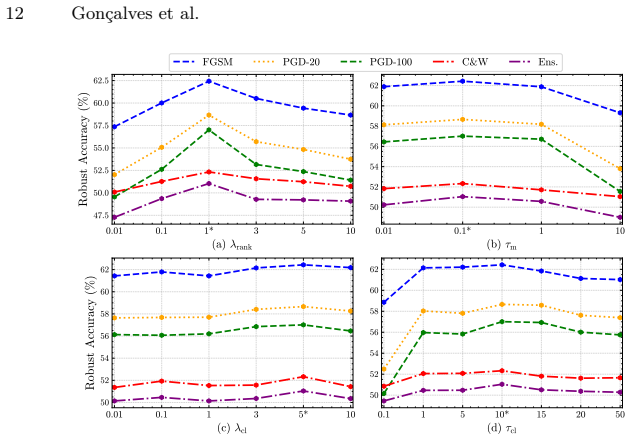
major comments (2)
- [§3] §3 (A3 module and loss construction): the claim that the same learnable mask and scaling factor can be reused for attenuation simply by sign flip is load-bearing for the central result, yet the text provides no gradient-conflict analysis, loss-landscape visualization, or ablation that trains the mask exclusively under attenuation versus the joint amplification procedure. Without such evidence the reported robustness gains cannot be attributed to the sign-flip reuse rather than incidental regularization.
- [§4] §4 (main experimental tables and ablations): the abstract states that amplification training “simultaneously improves” attenuation performance, but the reported tables do not isolate the transfer effect (e.g., a row comparing joint training against an attenuation-only baseline using the identical mask parameterization). This omission directly affects whether the cross-mode claim is supported by the data.
minor comments (2)
- [§3] Notation for the scaling factor and mask should be introduced once with explicit dimensions and initialization details; repeated re-definition across subsections reduces clarity.
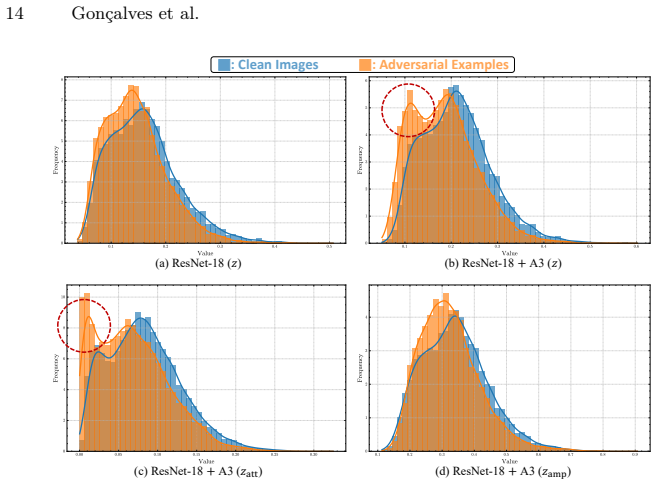
- [§4] Figure captions for activation visualizations should state the exact backbone, layer, and attack strength used so readers can reproduce the qualitative observations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger verification of the sign-flip transfer in A3. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
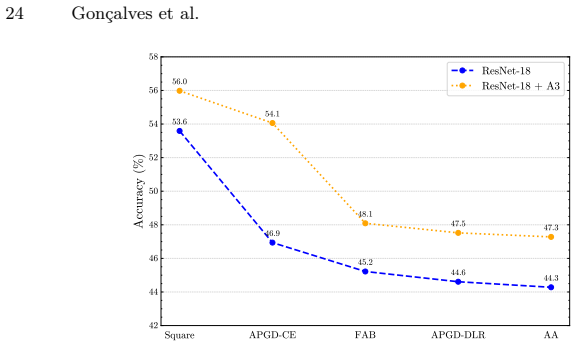
Referee: [§3] §3 (A3 module and loss construction): the claim that the same learnable mask and scaling factor can be reused for attenuation simply by sign flip is load-bearing for the central result, yet the text provides no gradient-conflict analysis, loss-landscape visualization, or ablation that trains the mask exclusively under attenuation versus the joint amplification procedure. Without such evidence the reported robustness gains cannot be attributed to the sign-flip reuse rather than incidental regularization.
Authors: We agree that the current manuscript lacks an explicit gradient-conflict analysis, loss-landscape visualization, or ablation training the mask exclusively under attenuation. The reported gains are observed when the jointly optimized parameters are deployed in attenuation mode, but without the requested controls it is difficult to fully attribute them to the sign-flip reuse. In revision we will add an ablation that trains an identical mask parameterization solely in attenuation mode and compares it directly to the joint procedure; we will also include a brief gradient-conflict discussion based on the observed training dynamics. revision: yes
-
Referee: [§4] §4 (main experimental tables and ablations): the abstract states that amplification training “simultaneously improves” attenuation performance, but the reported tables do not isolate the transfer effect (e.g., a row comparing joint training against an attenuation-only baseline using the identical mask parameterization). This omission directly affects whether the cross-mode claim is supported by the data.
Authors: The existing tables report results only for the joint training regime. We concur that an attenuation-only baseline with the same mask parameterization is required to isolate the transfer effect. In the revised version we will insert this baseline comparison into the main experimental tables and ablations to directly support the claim that amplification training simultaneously improves attenuation performance. revision: yes
Circularity Check
No significant circularity; empirical training procedure with independent experimental validation.
full rationale
The paper introduces a plug-in module with learnable parameters trained via novel contrastive and ranking losses on amplified activations, then evaluates robustness gains under sign-flipped attenuation at inference. The central claim rests on experimental results across backbones and datasets rather than any derivation that reduces reported robustness improvements to quantities defined solely by the fitted parameters or by self-citation. No equations are shown that equate predictions to inputs by construction, and the method is framed as data-driven optimization without load-bearing self-citations or uniqueness theorems imported from prior author work. This is the expected non-finding for an empirical defense paper whose performance claims are externally falsifiable via the released code.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable mask
- scaling factor
invented entities (1)
-
A3 module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: International Con- ference on Machine Learning
Athalye, A., Carlini, N., Wagner, D.: Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In: International Con- ference on Machine Learning. pp. 274–283. PMLR (2018),https://proceedings. mlr.press/v80/athalye18a.html
2018
-
[2]
In: International Confer- ence on Learning Representations (2021),https://openreview.net/forum?id= zQTezqCCtNx 16 Gonçalves et al
Bai, Y., Zeng, Y., Jiang, Y., Xia, S.T., Ma, X., Wang, Y.: Improving Adversar- ial Robustness via Channel-wise Activation Suppressing. In: International Confer- ence on Learning Representations (2021),https://openreview.net/forum?id= zQTezqCCtNx 16 Gonçalves et al
2021
-
[3]
Bu, Q., Huang, D., Cui, H.: Towards Building More Robust Models with Frequency Bias. In: IEEE/CVF International Conference on Computer Vision. pp. 4379–4388 (2023).https://doi.org/10.1109/ICCV51070.2023.00406
-
[4]
Towards Evaluating the Robustness of Neural Networks
Carlini, N., Wagner, D.: Towards Evaluating the Robustness of Neural Networks. In: IEEE Symposium on Security and Privacy. pp. 39–57 (2017).https://doi. org/10.1109/SP.2017.49
-
[5]
In: Advances in Neural Information Processing Systems (2021), https://openreview.net/forum?id=SSKZPJCt7B
Croce, F., Andriushchenko, M., Sehwag, V., Debenedetti, E., Flammarion, N., Chiang, M., Mittal, P., Hein, M.: RobustBench: A standardized adversarial robust- ness benchmark. In: Advances in Neural Information Processing Systems (2021), https://openreview.net/forum?id=SSKZPJCt7B
2021
-
[6]
In: International Conference on Machine Learning
Croce, F., Hein, M.: Reliable evaluation of adversarial robustness with an ensem- ble of diverse parameter-free attacks. In: International Conference on Machine Learning. pp. 2206–2216. PMLR (2020),https://proceedings.mlr.press/v119/ croce20b.html
2020
-
[7]
ImageNet: A large-scale hierarchical image database
Deng,J.,Dong,W.,Socher,R.,Li,L.J.,Li,K.,Fei-Fei,L.:ImageNet:ALarge-Scale Hierarchical Image Database. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 248–255 (2009).https://doi.org/10.1109/CVPR.2009. 5206848
-
[8]
In: International Conference on Learning Representations (2018),https: //openreview.net/forum?id=H1uR4GZRZ
Dhillon,G.S.,Azizzadenesheli,K.,Lipton,Z.C.,Bernstein,J.,Kossaifi,J.,Khanna, A., Anandkumar, A.: Stochastic Activation Pruning for Robust Adversarial De- fense. In: International Conference on Learning Representations (2018),https: //openreview.net/forum?id=H1uR4GZRZ
2018
-
[9]
In: International Conference on Learning Representations (2023),https://openreview.net/forum?id=ndYXTEL6cZz
Djurisic, A., Bozanic, N., Ashok, A., Liu, R.: Extremely Simple Activation Shap- ing for Out-of-Distribution Detection. In: International Conference on Learning Representations (2023),https://openreview.net/forum?id=ndYXTEL6cZz
2023
-
[10]
Machine Vision and Applications36(5), 108 (2025).https://doi.org/10.1007/ s00138-025-01730-8
Djurisic, A., Liu, R., Nikolic, M.: Logit scaling for out-of-distribution detection. Machine Vision and Applications36(5), 108 (2025).https://doi.org/10.1007/ s00138-025-01730-8
2025
-
[11]
Neural Networks194, 108176 (2026).https://doi.org/10.1016/j.neunet.2025.108176
Gao, Z., Liu, C., Shi, Y., Guo, X., Xu, J., Zhang, H., Shi, L.: FTA2C: Achieving Su- perior Trade-off between Accuracy and Robustness in Adversarial Training. Neural Networks194, 108176 (2026).https://doi.org/10.1016/j.neunet.2025.108176
-
[12]
Explaining and Harnessing Adversarial Examples
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and Harnessing Adversar- ial Examples. In: International Conference on Learning Representations (2015), https://arxiv.org/abs/1412.6572
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
A Series of Lectures
Gumbel, E.J.: Statistical Theory of Extreme Values and Some Practical Applica- tions. A Series of Lectures. Tech. Rep. PB175818, National Bureau of Standards, Washington, D. C. Applied Mathematics Div. (1954),https://ntrl.ntis.gov/ NTRL/dashboard/searchResults/titleDetail/PB175818.xhtml
1954
-
[14]
In: International Conference on Machine Learning
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On Calibration of Modern Neu- ral Networks. In: International Conference on Machine Learning. pp. 1321–1330. PMLR (2017),https://proceedings.mlr.press/v70/guo17a.html
2017
-
[15]
He, K., Zhang, X., Ren, S., Sun, J.: Deep Residual Learning for Image Recognition. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 770– 778 (2016).https://doi.org/10.1109/CVPR.2016.90
-
[16]
In: International Conference on Learning Representations (2017),https : / / openreview.net/forum?id=rkE3y85ee
Jang, E., Gu, S., Poole, B.: Categorical Reparameterization with Gumbel-Softmax. In: International Conference on Learning Representations (2017),https : / / openreview.net/forum?id=rkE3y85ee
2017
-
[17]
Jia, X., Zhang, Y., Wu, B., Ma, K., Wang, J., Cao, X.: LAS-AT: Adversarial Training with Learnable Attack Strategy. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13388–13398 (2022).https://doi.org/10. 1109/CVPR52688.2022.01304 A3: Activation Amplification and Attenuation 17
-
[18]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kim, W.J., Cho, Y., Jung, J., Yoon, S.E.: Feature Separation and Recalibration for Adversarial Robustness. In: IEEE/CVF Conference on Computer Vision and Pat- tern Recognition. pp. 8183–8192 (2023).https://doi.org/10.1109/CVPR52729. 2023.00791
-
[19]
Techni- cal Report, University of Toronto (2009),https://cave.cs.toronto.edu/kriz/ learning-features-2009-TR.pdf
Krizhevsky, A.: Learning Multiple Layers of Features from Tiny Images. Techni- cal Report, University of Toronto (2009),https://cave.cs.toronto.edu/kriz/ learning-features-2009-TR.pdf
2009
-
[20]
In: Advances in Neural Informa- tion Processing Systems
Lee, K., Lee, K., Lee, H., Shin, J.: A Simple Unified Framework for Detecting Out- of-Distribution Samples and Adversarial Attacks. In: Advances in Neural Informa- tion Processing Systems. vol. 31. Curran Associates, Inc. (2018),https://papers. nips.cc/paper_files/paper/2018/hash/abdeb6f575ac5c6676b747bca8d09cc2- Abstract.html
2018
-
[21]
Li, Z., Yu, D., Wei, L., Jin, C., Zhang, Y., Chan, S.: Soften to Defend: Towards Adversarial Robustness via Self-Guided Label Refinement. In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 24776–24785 (2024). https://doi.org/10.1109/CVPR52733.2024.02340
-
[22]
In: International Conference on Learning Representations (2018),https://openreview.net/forum?id=H1VGkIxRZ
Liang, S., Li, Y., Srikant, R.: Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks. In: International Conference on Learning Representations (2018),https://openreview.net/forum?id=H1VGkIxRZ
2018
-
[23]
In: Advances in Neural Information Processing Systems
Liu, W., Wang, X., Owens, J.D., Li, Y.: Energy-based Out-of-distribution De- tection. In: Advances in Neural Information Processing Systems. vol. 33, pp. 21464–21475 (2020),https : / / proceedings . neurips . cc / paper / 2020 / hash / f5496252609c43eb8a3d147ab9b9c006-Abstract.html
2020
-
[24]
In: International Conference on Learning Representations (2018),https://openreview.net/forum?id=rJzIBfZAb
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards Deep Learn- ing Models Resistant to Adversarial Attacks. In: International Conference on Learning Representations (2018),https://openreview.net/forum?id=rJzIBfZAb
2018
-
[25]
arXiv preprint arXiv:2503.08023 (2025)
Regmi, S.: AdaSCALE: Adaptive Scaling for OOD Detection. arXiv preprint arXiv:2503.08023 (2025)
-
[26]
Int J Comput Vis128(2), 336–359 (2017).https://doi.org/10.1007/s11263- 019-01228-7
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Int J Comput Vis128(2), 336–359 (2017).https://doi.org/10.1007/s11263- 019-01228-7
-
[27]
In: Proceedings of the 32nd ACM International Conference onMultimedia.pp
Tong, H., Zhang, X., Jin, Y., Lou, J., Wu, K., Chen, X.: Balancing Generalization andRobustnessinAdversarialTrainingviaSteeringthroughCleanandAdversarial Gradient Directions. In: Proceedings of the 32nd ACM International Conference onMultimedia.pp. 1014–1023. ACM (2024).https://doi.org/10.1145/3664647. 3680963
-
[28]
In: Advances in Neural Information Processing Systems
Tramèr, F., Carlini, N., Brendel, W., Madry, A.: On Adaptive Attacks to Adver- sarial Example Defenses. In: Advances in Neural Information Processing Systems. vol. 33, pp. 1633–1645 (2020),https://proceedings.neurips.cc/paper/2020/ hash/11f38f8ecd71867b42433548d1078e38-Abstract.html
2020
-
[29]
In: International Confer- ence on Learning Representations (2020),https://openreview.net/forum?id= rklOg6EFwS
Wang, Y., Zou, D., Yi, J., Bailey, J., Ma, X., Gu, Q.: Improving Adversarial Robustness Requires Revisiting Misclassified Examples. In: International Confer- ence on Learning Representations (2020),https://openreview.net/forum?id= rklOg6EFwS
2020
-
[30]
Wang, Z., Xu, X., Zhu, L., Bin, Y., Wang, G., Yang, Y., Shen, H.T.: Evidence- Based Multi-Feature Fusion for Adversarial Robustness. IEEE Transactions on Pattern Analysis and Machine Intelligence47(10), 8923–8937 (2025).https:// doi.org/10.1109/TPAMI.2025.3582518 18 Gonçalves et al
-
[31]
In: International Conferenceon LearningRepresentations(2025),https://openreview.net/forum? id=M9SKazbVkJ
Waseda, F., Chang, C.C., Echizen, I.: Rethinking Invariance Regularization in Adversarial Training to Improve Robustness-Accuracy Trade-off. In: International Conferenceon LearningRepresentations(2025),https://openreview.net/forum? id=M9SKazbVkJ
2025
-
[32]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wei, Z., Wang, Y., Guo, Y., Wang, Y.: CFA: Class-Wise Calibrated Fair Adversar- ial Training. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition. pp. 8193–8201 (2023).https://doi.org/10.1109/CVPR52729.2023.00792
-
[33]
In: International Conference on Learning Representations (2020),https: //openreview.net/forum?id=Pr86Lt1nOU
Xiao, C., Zhong, P., Zheng, C.: Enhancing Adversarial Defense by k-Winners- Take-All. In: International Conference on Learning Representations (2020),https: //openreview.net/forum?id=Pr86Lt1nOU
2020
-
[34]
Xie, C., Wu, Y.: Feature Denoising for Improving Adversarial Robustness. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 501– 509 (2019).https://doi.org/10.1109/CVPR.2019.00059
-
[35]
In: International Confer- ence on Learning Representations (2024),https://openreview.net/forum?id= RDSTjtnqCg
Xu, K., Chen, R., Franchi, G., Yao, A.: Scaling for Training Time and Post-hoc Out-of-distribution Detection Enhancement. In: International Confer- ence on Learning Representations (2024),https://openreview.net/forum?id= RDSTjtnqCg
2024
-
[36]
In: International Conference on Machine Learning
Yan, H., Zhang, J., Niu, G., Feng, J., Tan, V.Y.F., Sugiyama, M.: CIFS: Improv- ing Adversarial Robustness of CNNs via Channel-wise Importance-based Feature Selection. In: International Conference on Machine Learning. pp. 11693–11703. PMLR (2021),https://proceedings.mlr.press/v139/yan21e.html
2021
-
[37]
Zagoruyko,S.,Komodakis,N.:WideResidualNetworks.In:BritishMachineVision Conference. pp. 87.1–87.12. British Machine Vision Association (2016).https: //doi.org/10.5244/C.30.87
-
[38]
In: International Confer- ence on Machine Learning
Zhang, H., Yu, Y., Jiao, J., Xing, E.P., Ghaoui, L.E., Jordan, M.I.: Theoretically Principled Trade-off between Robustness and Accuracy. In: International Confer- ence on Machine Learning. pp. 7472–7482. PMLR (2019),https://proceedings. mlr.press/v97/zhang19p.html
2019
-
[39]
Zhu, K., Wang, J., Hu, X., Xie, X., Yang, G.: Improving Generalization of Ad- versarial Training via Robust Critical Fine-Tuning. In: IEEE/CVF International Conference on Computer Vision. pp. 4401–4411 (2023).https://doi.org/10. 1109/ICCV51070.2023.00408 A3: Activation Amplification and Attenuation 19 A Additional Results In this section, we provide addit...
-
[40]
As expected, the robust accuracy decreases when increasing eitherϵor the number of iterations (i.e., when increasing the attack strength). Importantly, the gap between the two curves remains consistent across attack strengths, indicating that A3 provides stable robustness improvements rather than gains limited to specific settings. This behavior provides ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.