NLL-Guided Full-Attention Layer Selection for Training-Free Sliding-Window Adaptation
Pith reviewed 2026-06-29 04:58 UTC · model grok-4.3
The pith
NLL degradation on answer tokens identifies the minimal set of full-attention layers needed for long-context accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NLL-guided layer selection ranks layers by the negative log-likelihood increase on answer tokens when each layer is forced to sliding-window attention, then retains full attention only for the highest-ranked subset; this produces hybrid models whose downstream accuracy matches or exceeds periodic full-attention patterns at substantially lower compute.
What carries the argument
NLL-guided layer selection, which measures each layer's task contribution via the negative log-likelihood degradation on answer tokens when that layer alone uses sliding-window attention instead of full attention.
If this is right
- Hybrid attention models can reach near-baseline accuracy with only one-quarter of layers using full attention.
- The one-time calibration cost of roughly fifteen minutes enables repeated inference savings on long contexts.
- The method outperforms fixed periodic patterns and attention-heuristic baselines on the same compute budget.
- De-confounding shows the NLL signal aligns with long-range attention requirements rather than generic layer importance.
Where Pith is reading between the lines
- The same NLL proxy could be recomputed on a per-task or per-prompt basis if calibration cost drops further.
- The approach might extend to other efficiency techniques such as sparse or grouped-query attention by substituting the attention variant in the calibration step.
Load-bearing premise
The negative log-likelihood degradation on answer tokens when a layer is forced to sliding-window attention is a reliable proxy for that layer's contribution to final task accuracy.
What would settle it
Running the identical calibration on a new long-context benchmark or different model family and then measuring whether the selected quarter of layers still matches the half-layer periodic baseline accuracy.
Figures

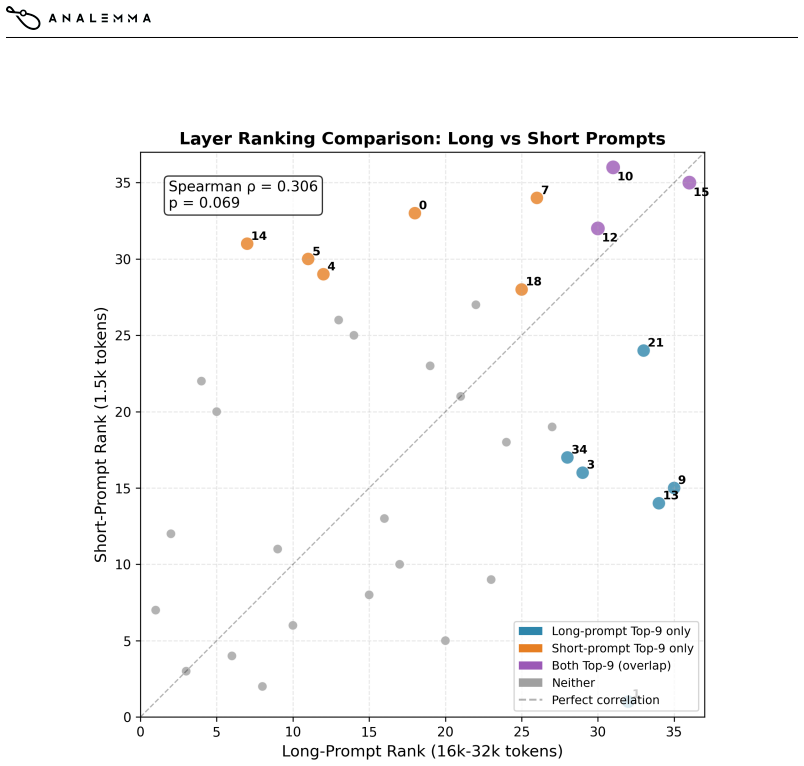
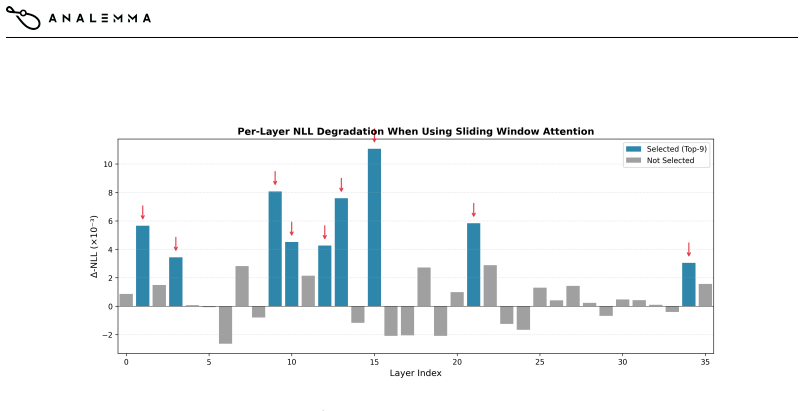
read the original abstract
Hybrid attention models that mix full and sliding-window attention across layers offer a promising approach to efficient long-context inference, but the critical question of \emph{which layers} should retain full attention remains unsolved. Existing methods use either fixed periodic patterns or attention-based heuristics that may not capture what matters for downstream accuracy. We propose NLL-guided layer selection, a training-free method that directly measures each layer's importance by computing the negative log-likelihood degradation on answer tokens when that layer uses sliding-window instead of full attention. On LongMemEval with Qwen3-4B, our method achieves 64.6\% accuracy using only 1/4 full-attention layers, matching the 1/2-FA periodic baseline (65.0\%) while halving the computational budget. NLL-guided selection outperforms the SWAA-reported periodic 1/4-FA baseline by 10.4 percentage points and a matched LightTransfer-style baseline by 26.4 percentage points. De-confounding analysis shows the signal is consistent with long-range attention needs rather than generic layer sensitivity. The method requires only $\sim$15 minutes of one-time calibration, advancing the efficiency-accuracy Pareto frontier for long-context LLM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes NLL-guided full-attention layer selection, a training-free method that ranks layers by the increase in negative log-likelihood on answer tokens when each layer is individually forced to use sliding-window attention instead of full attention. The selected layers retain full attention in an otherwise sliding-window model. On LongMemEval with Qwen3-4B, the method reaches 64.6% accuracy using only 1/4 full-attention layers, matching the 1/2-FA periodic baseline (65.0%) while halving compute, and outperforming the SWAA 1/4-FA baseline by 10.4 points and a LightTransfer-style baseline by 26.4 points. A de-confounding analysis is claimed to show the signal reflects long-range attention needs rather than generic sensitivity.
Significance. If the NLL proxy is shown to be a reliable indicator of layers critical for downstream long-context reasoning, the approach would provide a low-cost, training-free route to improve the efficiency-accuracy frontier for hybrid-attention LLMs. The one-time ~15-minute calibration cost is a practical strength. However, the significance is limited by the absence of quantitative validation that the proxy correlates with task accuracy contributions rather than calibration artifacts.
major comments (2)
- [Abstract] Abstract: the de-confounding analysis is described only qualitatively and supplies no explicit metrics (e.g., rank correlation between per-layer NLL deltas and per-layer accuracy ablation deltas on LongMemEval, or transfer performance on held-out calibration data), so it does not yet rule out that the selection is driven by prompt statistics rather than general long-range dependency requirements.
- [Abstract] Abstract: accuracy figures (64.6%, 65.0%) are given without error bars, without stating the number of examples or tokens used for NLL calibration, and without describing prompt construction, all of which are required to assess statistical reliability and reproducibility of the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point-by-point below, indicating where revisions will be made to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the de-confounding analysis is described only qualitatively and supplies no explicit metrics (e.g., rank correlation between per-layer NLL deltas and per-layer accuracy ablation deltas on LongMemEval, or transfer performance on held-out calibration data), so it does not yet rule out that the selection is driven by prompt statistics rather than general long-range dependency requirements.
Authors: We acknowledge that the abstract presents the de-confounding analysis qualitatively. The full manuscript includes a de-confounding section that compares NLL-based rankings against generic sensitivity measures and attention-pattern heuristics, showing selected layers align with positions requiring long-range dependencies. To strengthen this, we will add explicit quantitative metrics in the revision: Spearman rank correlation between per-layer NLL deltas and per-layer accuracy drops from ablation studies on LongMemEval, plus transfer accuracy on held-out calibration prompts. These will be reported in the main text and briefly referenced in the abstract. revision: yes
-
Referee: [Abstract] Abstract: accuracy figures (64.6%, 65.0%) are given without error bars, without stating the number of examples or tokens used for NLL calibration, and without describing prompt construction, all of which are required to assess statistical reliability and reproducibility of the central empirical claim.
Authors: We agree these details are essential for reproducibility. The experimental section of the manuscript specifies the LongMemEval subset size, the exact number of tokens (and examples) used for the one-time NLL calibration, and the prompt template construction. In the revision we will (1) add error bars to the reported accuracies (computed across 3 random seeds), (2) include the calibration token count and example count in the abstract, and (3) add a one-sentence description of prompt construction. These changes address the statistical reliability concern without altering the central claims. revision: yes
Circularity Check
No circularity: direct empirical NLL measurement for layer selection
full rationale
The paper defines its method as computing the per-layer negative log-likelihood increase on answer tokens when a single layer is switched to sliding-window attention, then selecting the lowest-degradation layers to retain full attention. This is an explicit measurement on calibration data rather than a derivation, fitted parameter, or quantity defined in terms of the target accuracy. No equations reduce the selection criterion to itself, no predictions are statistically forced by prior fits, and the text contains no self-citation chains or imported uniqueness theorems that bear the central claim. Performance numbers on LongMemEval are reported as downstream validation of the empirical procedure, not as a mathematical consequence of the selection rule. The approach is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Negative log-likelihood degradation on answer tokens when a layer is switched to sliding-window attention measures that layer's importance for long-range context needs.
Reference graph
Works this paper leans on
-
[1]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer. ArXiv, abs/2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
H., Li, D., Lin, C.-Y ., Yang, Y ., and Qiu, L
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhen- hua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Minfer- ence 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.ArXiv, abs/2407.02490,
-
[3]
Distilling to hybrid attention models via kl-guided layer selection.ArXiv, abs/2512.20569,
Yanhong Li, Songlin Yang, Shawn Tan, Mayank Mishra, Rameswar Panda, Jiawei Zhou, and Yoon Kim. Distilling to hybrid attention models via kl-guided layer selection.ArXiv, abs/2512.20569,
-
[4]
SnapKV: LLM Knows What You are Looking for Before Generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr F. Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.ArXiv, abs/2404.14469,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context llm inference.ArXiv, abs/2406.10774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gemma 2: Improving Open Language Models at a Practical Size
7 Gemma Team, Morgane Riviere, et al. Gemma 2: Improving open language models at a practical size.ArXiv, abs/2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report.ArXiv, abs/2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Training-free context-adaptive attention for efficient long context modeling.CoRR, abs/2512.09238,
Zeng You, Yaofo Chen, Shuhai Zhang, Zhijie Qiu, Tingyu Wu, Yingjian Li, Yaowei Wang, and Mingkui Tan. Training-free context-adaptive attention for efficient long context modeling.CoRR, abs/2512.09238,
-
[9]
Yijiong Yu, Jiale Liu, Qingyun Wu, Huazheng Wang, and Ji Pei. Swaa: Sliding window attention adaptation for efficient and quality preserving long context processing.ArXiv, abs/2512.10411,
-
[10]
Big Bird: Transformers for Longer Sequences
M. Zaheer, Guru Guruganesh, Kumar Avinava Dubey, J. Ainslie, Chris Alberti, Santiago Onta ˜n´on, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences.ArXiv, abs/2007.14062,
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[11]
Light- transfer: Your long-context LLM is secretly a hybrid model with effortless adaptation.Trans
Xuan Zhang, Fengzhuo Zhang, Cunxiao Du, Chao Du, Tianyu Pang, Wei Gao, and Min Lin. Light- transfer: Your long-context LLM is secretly a hybrid model with effortless adaptation.Trans. Mach. Learn. Res., 2025,
2025
-
[12]
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Zhenyu (Allen) Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R ´e, Clark W. Barrett, Zhangyang Wang, and Beidi Chen. H2o: Heavy-hitter oracle for efficient generative inference of large language models.ArXiv, abs/2306.14048,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Examples are selected to have answer lengths of at least 20 tokens to ensure meaningful NLL computation
A IMPLEMENTATIONDETAILS A.1 CALIBRATIONDATA We use 64 long-context examples sampled from LongAlign-10k and fusang-v1-filtered datasets, with prompt lengths between 16k and 32k tokens. Examples are selected to have answer lengths of at least 20 tokens to ensure meaningful NLL computation. A.2 SCORINGPROCEDURE For each of the 36 layers, we compute the mean ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.