Parameter-Efficient Quantum-Inspired Fast Weight Programmers for Traffic-Matrix Forecasting
Pith reviewed 2026-06-29 04:47 UTC · model grok-4.3
The pith
A gated quantum-inspired fast-weight programmer forecasts Abilene traffic matrices with the lowest pooled RMSE using only 22.4% of a larger LSTM's parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
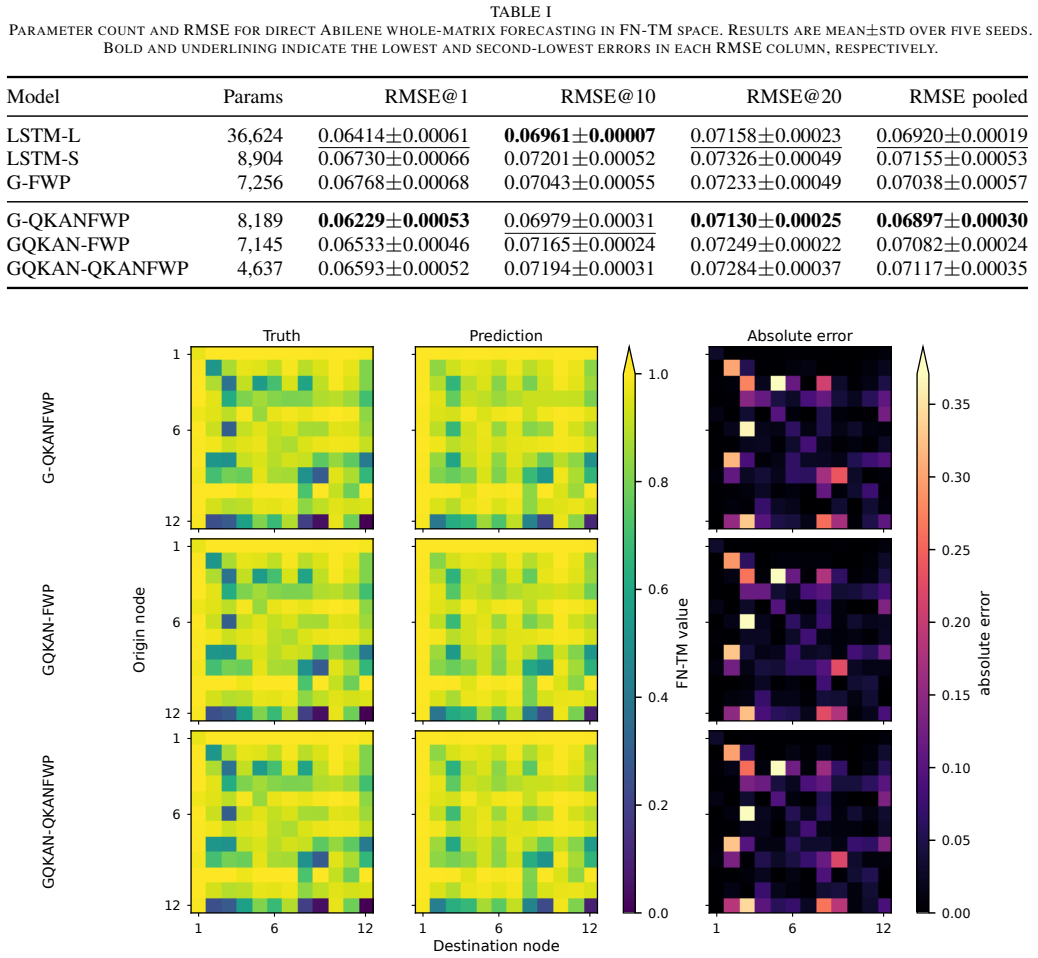
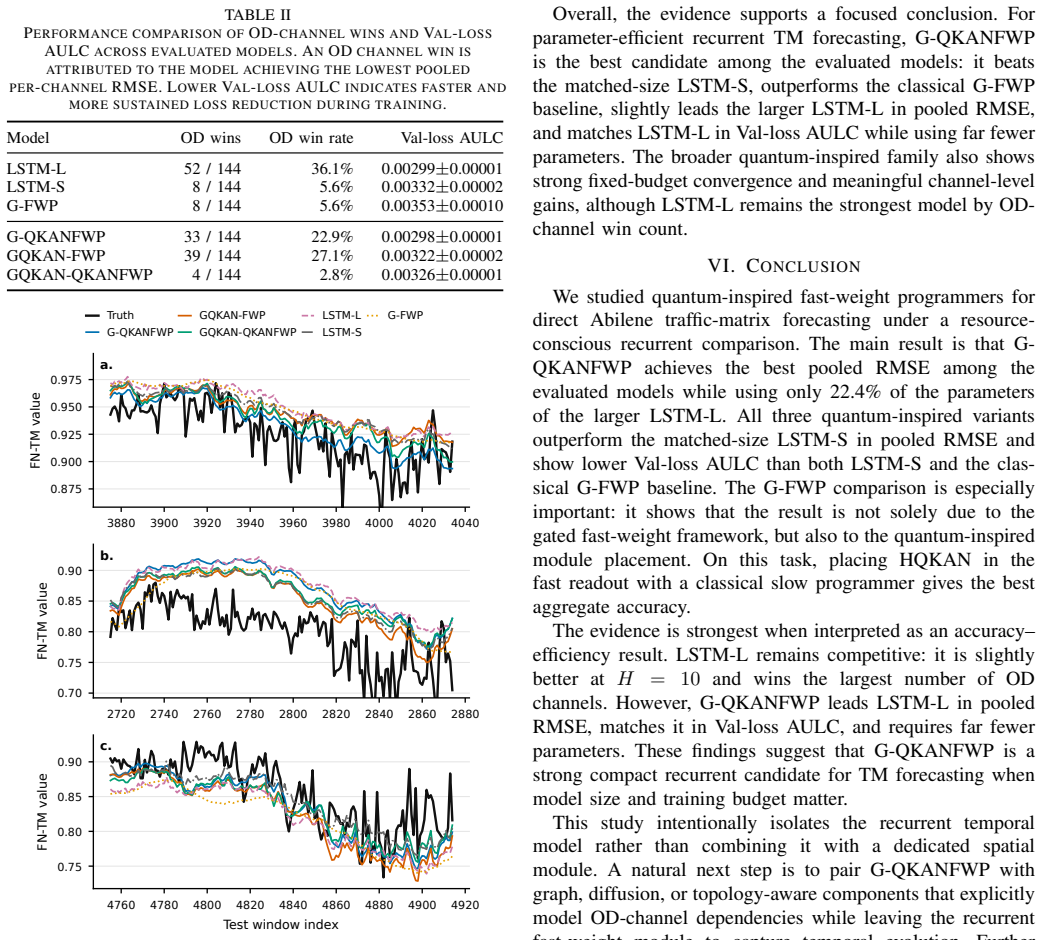
The gated quantum-inspired Kolmogorov-Arnold network fast-weight programmer (G-QKANFWP) achieves the best pooled root-mean-square error for direct multi-step Abilene traffic-matrix forecasting, using only 22.4% of the parameters of a larger LSTM while also outperforming a matched-size LSTM and the classical gated fast-weight programmer baseline. Convergence analysis shows lower validation-loss area under the learning curve for quantum-inspired variants, and channel-wise results indicate more origin-destination channel wins for G-QKANFWP and GQKAN-FWP.
What carries the argument
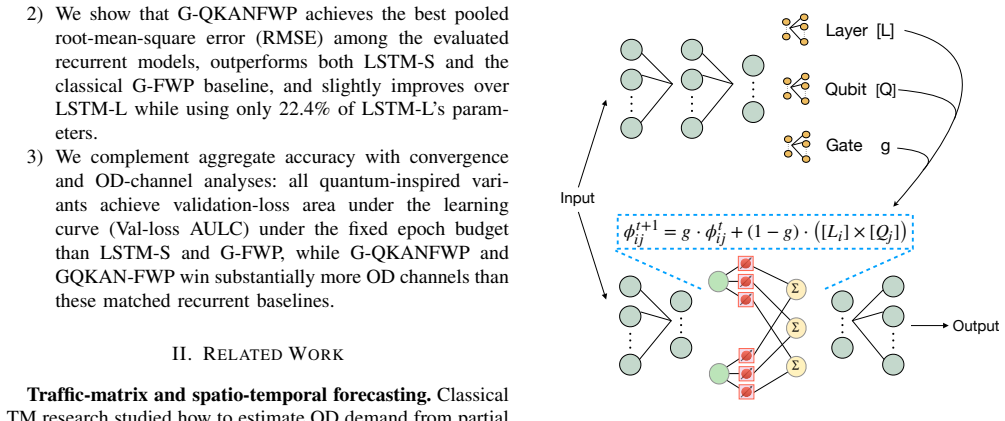
Gated quantum-inspired Kolmogorov-Arnold network fast-weight programmer (G-QKANFWP), a recurrent architecture that pairs a classical slow programmer with a quantum-inspired fast programmer for multi-step forecasting of origin-destination matrices.
If this is right
- Quantum-inspired variants obtain lower validation-loss area under the learning curve than matched-size recurrent baselines.
- G-QKANFWP and GQKAN-FWP achieve substantially more origin-destination channel wins than baselines.
- The results identify a classical slow programmer with a quantum-inspired fast programmer as a promising accuracy-efficiency design for resource-conscious network traffic-matrix forecasting.
Where Pith is reading between the lines
- Similar quantum-inspired fast-weight designs could be tested on other time-series forecasting tasks in networking or infrastructure monitoring.
- If the efficiency holds, these models might reduce the computational overhead of real-time traffic engineering systems without sacrificing forecast quality.
- The approach suggests that quantum-inspired numerical methods can serve as drop-in enhancements for classical recurrent architectures in constrained environments.
Load-bearing premise
The fixed-budget training protocol and size-matching procedure produce a fair comparison across architectures, with any performance gains attributable to the quantum-inspired components rather than differences in implementation or tuning.
What would settle it
Retraining all models on the Abilene dataset with an exhaustive hyperparameter search and multiple random seeds, then finding that the performance advantage of G-QKANFWP disappears or reverses, would falsify the claim that the quantum-inspired design is responsible for the gains.
Figures
read the original abstract
Traffic matrices (TMs) capture network-wide origin-destination demand and are central to traffic engineering, yet accurate whole-matrix forecasting remains challenging when prediction must be performed under the memory, update, and training-budget constraints of online network control. This paper investigates whether compact quantum-inspired recurrent models can provide effective TM forecasts without relying on dedicated graph, transformer, or diffusion modules. We adapt gated quantum-inspired Kolmogorov-Arnold network fast-weight programmers (QKAN-FWPs) to direct multi-step Abilene TM forecasting, where each model predicts the next 20 five-minute frames of a 144-channel origin-destination (OD) matrix from a two-hour history. We benchmark three QKAN placement variants against a matched-size long short-term memory (LSTM) network, a larger LSTM, and a classical gated fast-weight programmer under a shared fixed-budget training protocol. Among the evaluated recurrent models, G-QKANFWP achieves the best pooled root-mean-square error (RMSE), while using only 22.4% of the larger LSTM. It also outperforms both the matched-size LSTM and the classical G-FWP baseline, indicating that the gain is not due to gated fast-weight framework alone. Convergence and channel-wise analyses further show that the quantum-inspired variants obtain lower validation-loss area under the learning curve (AULC) than matched-size recurrent baselines, while G-QKANFWP and GQKAN-FWP achieve substantially more OD-channel wins. These results identify a classical slow programmer with a quantum-inspired fast programmer as a promising accuracy-efficiency design for resource-conscious network traffic-matrix forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes adapting gated quantum-inspired Kolmogorov-Arnold network fast-weight programmers (G-QKANFWP and variants) for direct multi-step Abilene traffic-matrix forecasting, where each model predicts the next 20 five-minute frames of a 144-channel OD matrix from a two-hour history. It benchmarks the quantum-inspired models against a matched-size LSTM, a larger LSTM, and a classical gated fast-weight programmer (G-FWP) under a shared fixed-budget training protocol, claiming that G-QKANFWP achieves the lowest pooled RMSE while using only 22.4% of the parameters of the larger LSTM and outperforming both the size-matched LSTM and classical G-FWP, with additional support from lower validation-loss AULC and more OD-channel wins.
Significance. If the performance advantages can be robustly attributed to the quantum-inspired components after clarifying the experimental controls, the result would indicate that pairing a classical slow programmer with a quantum-inspired fast programmer yields a favorable accuracy-efficiency trade-off for resource-constrained TM forecasting, offering a compact recurrent alternative to larger LSTMs or graph/transformer modules in online network control.
major comments (3)
- [Abstract/Methods] Abstract and Methods: The central attribution of RMSE gains to the quantum-inspired fast programmer (rather than the gated fast-weight framework or implementation differences) requires that the matched-size LSTM and classical G-FWP received equivalent optimization under the fixed-budget protocol. The manuscript provides no description of the exact parameter-count matching procedure, whether a common hyperparameter grid/search was used, or if initialization and random seeds were identical across models.
- [Results] Results: The pooled RMSE, AULC, and channel-wise win counts are reported without error bars, number of independent training runs, or statistical significance tests. This makes it impossible to assess whether the reported superiority of G-QKANFWP over the matched LSTM and G-FWP is reliable or could arise from training stochasticity.
- [Results] Results: No ablation studies isolate the contribution of the quantum-inspired Kolmogorov-Arnold components (e.g., by replacing them with classical equivalents while keeping the fast-weight programmer fixed), which is necessary to support the claim that the gains are specifically due to the quantum-inspired design rather than other architectural choices.
minor comments (1)
- [Abstract] Abstract: The phrase 'pooled root-mean-square error' is used without defining the pooling operation (across channels, time steps, or both); a brief clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the experimental details and claims.
read point-by-point responses
-
Referee: [Abstract/Methods] Abstract and Methods: The central attribution of RMSE gains to the quantum-inspired fast programmer (rather than the gated fast-weight framework or implementation differences) requires that the matched-size LSTM and classical G-FWP received equivalent optimization under the fixed-budget protocol. The manuscript provides no description of the exact parameter-count matching procedure, whether a common hyperparameter grid/search was used, or if initialization and random seeds were identical across models.
Authors: We agree that the parameter-count matching and optimization controls require explicit documentation. In the revised manuscript we will add a dedicated subsection in Methods that specifies the exact procedure used to match parameter counts across models, the common hyperparameter grid and search protocol applied under the fixed-budget regime, and confirmation that initialization distributions and random seeds were held identical for all compared models. revision: yes
-
Referee: [Results] Results: The pooled RMSE, AULC, and channel-wise win counts are reported without error bars, number of independent training runs, or statistical significance tests. This makes it impossible to assess whether the reported superiority of G-QKANFWP over the matched LSTM and G-FWP is reliable or could arise from training stochasticity.
Authors: We accept that the absence of variability measures and statistical tests limits interpretability. We will rerun the experiments with multiple independent random seeds, report means and standard deviations (error bars) for pooled RMSE and AULC, and add appropriate significance tests (e.g., paired t-tests or Wilcoxon tests) for the key model comparisons in the revised Results section. revision: yes
-
Referee: [Results] Results: No ablation studies isolate the contribution of the quantum-inspired Kolmogorov-Arnold components (e.g., by replacing them with classical equivalents while keeping the fast-weight programmer fixed), which is necessary to support the claim that the gains are specifically due to the quantum-inspired design rather than other architectural choices.
Authors: The existing comparison against the classical G-FWP already holds the gated fast-weight programmer framework constant while varying only the programmer implementation, thereby isolating the quantum-inspired KAN substitution. Nevertheless, we agree that an explicit within-framework ablation would further strengthen attribution. We will therefore add a targeted ablation that replaces the quantum-inspired KAN blocks with classical MLP equivalents while keeping the remainder of the G-FWP architecture fixed. revision: yes
Circularity Check
No significant circularity in empirical model comparisons
full rationale
The paper reports empirical benchmarks of G-QKANFWP and variants against matched-size LSTM, larger LSTM, and classical G-FWP baselines under a shared fixed-budget training protocol for Abilene TM forecasting. No derivation chain, equations, or self-citations are invoked that reduce a claimed prediction to a fitted parameter or input by construction. Performance metrics (pooled RMSE, AULC, channel-wise wins) are measured outcomes rather than quantities defined in terms of the model itself. The size-matching procedure is presented as an external control, not an internal tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Abilene traffic matrix dataset and fixed-budget training protocol allow fair comparison of recurrent architectures for online forecasting.
Reference graph
Works this paper leans on
-
[1]
Network tomography: Estimating source-destination traffic in- tensities from link data,
Y . Vardi, “Network tomography: Estimating source-destination traffic in- tensities from link data,”Journal of the American statistical association, vol. 91, no. 433, pp. 365–377, 1996
1996
-
[2]
Fast accurate computation of large-scale ip traffic matrices from link loads,
Y . Zhang, M. Roughan, N. Duffield, and A. Greenberg, “Fast accurate computation of large-scale ip traffic matrices from link loads,”ACM SIGMETRICS Performance Evaluation Review, vol. 31, no. 1, pp. 206– 217, 2003
2003
-
[3]
Traffic matrix estimation: Existing techniques and new directions,
A. Medina, N. Taft, K. Salamatian, S. Bhattacharyya, and C. Diot, “Traffic matrix estimation: Existing techniques and new directions,” ACM SIGCOMM Computer Communication Review, vol. 32, no. 4, pp. 161–174, 2002
2002
-
[4]
Internet traffic matrices: A primer,
P. Tune, M. Roughan, H. Haddadi, and O. Bonaventure, “Internet traffic matrices: A primer,”Recent Advances in Networking, vol. 1, pp. 1–56, 2013
2013
-
[5]
Traffic datsets: Abilene, GEANT, TaxiBJ,
R. Xie, “Traffic datsets: Abilene, GEANT, TaxiBJ,” IEEE Dataport, May 2024. [Online]. Available: https://dx.doi.org/10.21227/7x3c-5p06
-
[6]
Traffic matrix prediction based on deep learning for dynamic traffic engineering,
Z. Liu, Z. Wang, X. Yin, X. Shi, Y . Guo, and Y . Tian, “Traffic matrix prediction based on deep learning for dynamic traffic engineering,” in 2019 IEEE Symposium on Computers and Communications (ISCC). IEEE, 2019, pp. 1–7
2019
-
[7]
Neutm: A neural network-based framework for traffic matrix prediction in sdn,
A. Azzouni and G. Pujolle, “Neutm: A neural network-based framework for traffic matrix prediction in sdn,” inNOMS 2018-2018 IEEE/IFIP Network Operations and Management Symposium. IEEE, 2018, pp. 1–5
2018
-
[8]
Network traffic prediction by learning time series as images,
R. Kablaoui, I. Ahmad, S. Abed, and M. Awad, “Network traffic prediction by learning time series as images,”Engineering Science and Technology, an International Journal, vol. 55, p. 101754, 2024
2024
-
[9]
Y . Sun, Y . Liu, N. Cheng, J. Li, Z. Jia, X. Du, and M. Peng, “Accurate network traffic matrix prediction via lead: an llm-enhanced adapter- based conditional diffusion model,”arXiv preprint arXiv:2601.21437, 2026
-
[10]
A network traffic measurement approach in cloud-edge sdn networks,
L. Huo, D. Jiang, and L. Cheng, “A network traffic measurement approach in cloud-edge sdn networks,” inInternational Conference on Simulation Tools and Techniques. Springer, 2020, pp. 204–214
2020
-
[11]
Forecasting network traffic: A survey and tutorial with open-source comparative evaluation,
G. O. Ferreira, C. Ravazzi, F. Dabbene, G. C. Calafiore, and M. Fiore, “Forecasting network traffic: A survey and tutorial with open-source comparative evaluation,”IEEe Access, vol. 11, pp. 6018–6044, 2023
2023
-
[12]
Towards energy-aware federated traffic prediction for cellular networks,
V . Perifanis, N. Pavlidis, S. F. Yilmaz, F. Wilhelmi, E. Guerra, M. Miozzo, P. S. Efraimidis, P. Dini, and R.-A. Koutsiamanis, “Towards energy-aware federated traffic prediction for cellular networks,” in2023 Eighth International Conference on Fog and Mobile Edge Computing (FMEC). IEEE, 2023, pp. 93–100
2023
-
[13]
Network traffic prediction in an edge–cloud continuum network for multiple network service providers,
Y . Hu, B. Liu, J. Li, L. Zhu, J. Han, Z. Cai, and J. Zhang, “Network traffic prediction in an edge–cloud continuum network for multiple network service providers,”Electronics, vol. 13, no. 17, p. 3515, 2024
2024
-
[14]
Lightweight graph networks for ai- integrated network traffic prediction: Towards efficient edge computing solutions,
L. Zhu, X. Sun, and L. Huang, “Lightweight graph networks for ai- integrated network traffic prediction: Towards efficient edge computing solutions,”Internet Technology Letters, vol. 8, no. 6, p. e70152, 2025
2025
-
[15]
Gated QKAN-FWP: Scalable Quantum-inspired Sequence Learning
K.-C. Peng, S. Y .-C. Chen, J.-C. Jiang, C.-Y . Liu, E.-J. Kuo, Y .-Y . Wang, P. Tiwari, A. Ceschini, C.-S. Chen, Y .-C. Hsuet al., “Gated qkan-fwp: Scalable quantum-inspired sequence learning,”arXiv preprint arXiv:2605.06734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
Y . Li, R. Yu, C. Shahabi, and Y . Liu, “Diffusion convolutional re- current neural network: Data-driven traffic forecasting,”arXiv preprint arXiv:1707.01926, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting
B. Yu, H. Yin, and Z. Zhu, “Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting,”arXiv preprint arXiv:1709.04875, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Graph WaveNet for Deep Spatial-Temporal Graph Modeling
Z. Wu, S. Pan, G. Long, J. Jiang, and C. Zhang, “Graph wavenet for deep spatial-temporal graph modeling,”arXiv preprint arXiv:1906.00121, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[19]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[20]
Learning to control fast-weight memories: An alterna- tive to dynamic recurrent networks,
J. Schmidhuber, “Learning to control fast-weight memories: An alterna- tive to dynamic recurrent networks,”Neural Computation, vol. 4, no. 1, pp. 131–139, 1992
1992
-
[21]
Linear transformers are secretly fast weight programmers,
I. Schlag, K. Irie, and J. Schmidhuber, “Linear transformers are secretly fast weight programmers,” inInternational conference on machine learning. PMLR, 2021, pp. 9355–9366
2021
-
[22]
Going beyond linear transformers with recurrent fast weight programmers,
K. Irie, I. Schlag, R. Csord ´as, and J. Schmidhuber, “Going beyond linear transformers with recurrent fast weight programmers,”Advances in neural information processing systems, vol. 34, pp. 7703–7717, 2021
2021
-
[23]
Time-series quantum reservoir computing with weak and pro- jective measurements,
P. Mujal, R. Mart ´ınez-Pe˜na, G. L. Giorgi, M. C. Soriano, and R. Zam- brini, “Time-series quantum reservoir computing with weak and pro- jective measurements,”npj Quantum Information, vol. 9, no. 1, p. 16, 2023
2023
-
[24]
Feedback-driven quantum reservoir computing for time-series analysis,
K. Kobayashi, K. Fujii, and N. Yamamoto, “Feedback-driven quantum reservoir computing for time-series analysis,”PRX quantum, vol. 5, no. 4, p. 040325, 2024
2024
-
[25]
Efficient quantum recurrent reinforcement learning via quantum reservoir computing,
S. Y .-C. Chen, “Efficient quantum recurrent reinforcement learning via quantum reservoir computing,” inICASSP 2024-2024 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 13 186–13 190
2024
-
[26]
Quantum long short- term memory,
S. Y .-C. Chen, S. Yoo, and Y .-L. L. Fang, “Quantum long short- term memory,” inIcassp 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2022, pp. 8622–8626
2022
-
[27]
Quantum long short-term memory (qlstm) vs. classical lstm in time series forecasting: a comparative study in solar power forecasting,
S. Z. Khan, N. Muzammil, S. Ghafoor, H. Khan, S. M. H. Zaidi, A. J. Aljohani, and I. Aziz, “Quantum long short-term memory (qlstm) vs. classical lstm in time series forecasting: a comparative study in solar power forecasting,”Frontiers in Physics, vol. 12, p. 1439180, 2024
2024
-
[28]
Qkan-lstm: Quantum-inspired kolmogorov–arnold long short-term memory,
Y .-C. Hsu, J.-C. Jiang, C.-H. Lin, K.-C. Peng, N.-Y . Chen, S. Y .- C. Chen, E.-J. Kuo, and H.-S. Goan, “Qkan-lstm: Quantum-inspired kolmogorov–arnold long short-term memory,” in2026 International Conference on Quantum Communications, Networking, and Computing (QCNC). IEEE, 2026, pp. 650–659
2026
-
[29]
Quantum-train long short- term memory: Application on flood prediction problem,
C.-H. A. Lin, C.-Y . Liu, and K.-C. Chen, “Quantum-train long short- term memory: Application on flood prediction problem,” in2024 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 2. IEEE, 2024, pp. 268–273
2024
-
[30]
Quantum kernel-based long short-term memory for climate time-series forecasting,
Y .-C. Hsu, N.-Y . Chen, T.-Y . Li, P.-H. H. Lee, and K.-C. Chen, “Quantum kernel-based long short-term memory for climate time-series forecasting,” in2025 International Conference on Quantum Communica- tions, Networking, and Computing (QCNC). IEEE, 2025, pp. 421–426
2025
-
[31]
Quantum-enhanced channel mixing in rwkv models for time series forecasting,
C.-S. Chen and E.-J. Kuo, “Quantum-enhanced channel mixing in rwkv models for time series forecasting,”arXiv preprint arXiv:2505.13524, 2025
-
[32]
Hqnn-fsp: A hybrid classical-quantum neural network for regression-based financial stock market prediction,
P. K. Choudhary, N. Innan, M. Shafique, and R. Singh, “Hqnn-fsp: A hybrid classical-quantum neural network for regression-based financial stock market prediction,”Quantum Machine Intelligence, vol. 8, no. 1, p. 55, 2026
2026
-
[33]
Time series forecasting with quantum machine learning architectures,
M. A. Rivera-Ruiz, A. Mendez-Vazquez, and J. M. L ´opez-Romero, “Time series forecasting with quantum machine learning architectures,” inMexican international conference on artificial intelligence. Springer, 2022, pp. 66–82
2022
-
[34]
Quantum-enhanced parameter-efficient learning for typhoon trajectory forecasting,
C.-Y . Liu, K.-C. Chen, Y .-C. Chen, S. Y .-C. Chen, W.-H. Huang, W.-J. Huang, and Y .-J. Chang, “Quantum-enhanced parameter-efficient learning for typhoon trajectory forecasting,” in2025 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2025, pp. 2046–2056
2025
-
[35]
Learning to program variational quantum circuits with fast weights,
S. Y .-C. Chen, “Learning to program variational quantum circuits with fast weights,” in2024 International Joint Conference on Neural Networks (IJCNN). IEEE, 2024, pp. 1–9
2024
-
[36]
Programming variational quantum circuits with quantum-train agent,
C.-Y . Liu, S. Y .-C. Chen, K.-C. Chen, W.-J. Huang, and Y .-J. Chang, “Programming variational quantum circuits with quantum-train agent,” in2025 International Conference on Quantum Communications, Net- working, and Computing (QCNC). IEEE, 2025, pp. 544–548
2025
-
[37]
Quantum fast weight programming for time series prediction,
A. Ceschini, A. Rosato, M. Panella, and S. Y .-C. Chen, “Quantum fast weight programming for time series prediction,” inICASSP 2026- 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 22 032–22 036
2026
-
[38]
Quantum variational activation functions empower kolmogorov-arnold networks,
J.-C. Jiang, M. Y .-C. Huang, T. Chen, and H.-S. Goan, “Quantum variational activation functions empower kolmogorov-arnold networks,” arXiv preprint arXiv:2509.14026, 2025
-
[39]
QKAN: Quantum-inspired Kolmogorov-Arnold network,
J.-C. Jiang, “QKAN: Quantum-inspired Kolmogorov-Arnold network,”
-
[40]
Available: https://github.com/Jim137/qkan
[Online]. Available: https://github.com/Jim137/qkan
-
[41]
Adam: A Method for Stochastic Optimization
D. P. Kingma, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[42]
The shape of learning curves: a review,
T. Viering and M. Loog, “The shape of learning curves: a review,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 6, pp. 7799–7819, 2022
2022
-
[43]
Active learning in the presence of unlabelable examples,
D. Mazzoni and K. Wagstaff, “Active learning in the presence of unlabelable examples,” inEuropean Conference on Machine Learning, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.