S²-VLA: State-Space Guided Vision-Language-Action Models for Long-Horizon Manipulation
Pith reviewed 2026-06-29 04:38 UTC · model grok-4.3
The pith
A state-space belief mechanism enables compact 2B-parameter vision-language-action models to outperform 7B models on long-horizon robotic manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
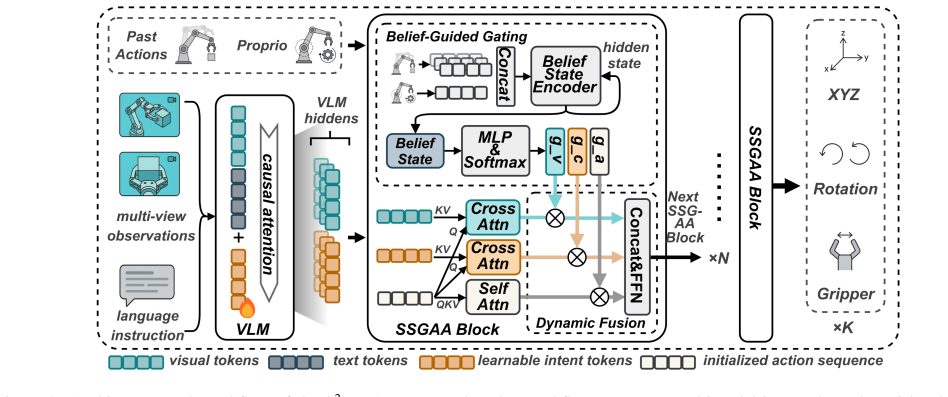
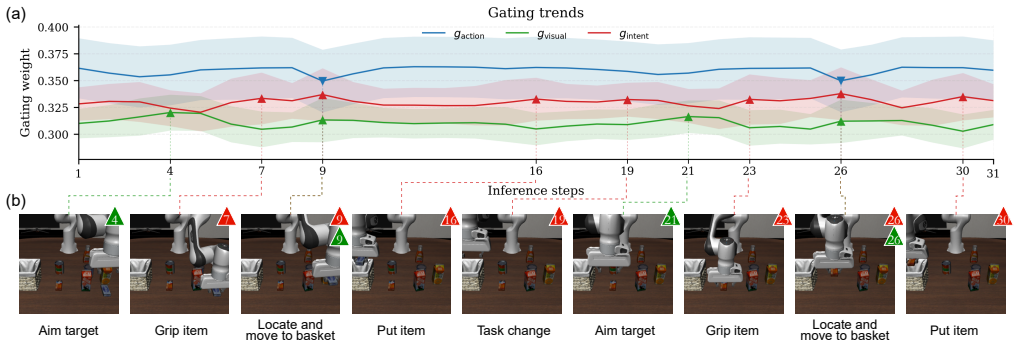
S²-VLA maintains a belief state inside the SSGAA module that tracks task progression and produces dynamic gating weights. These weights adaptively fuse visual features for spatial perception, task intents for high-level planning, and temporal action sequences for execution consistency. This dynamic fusion replaces fixed-weight combinations and reduces cumulative errors in long-horizon tasks.
What carries the argument
The State-Space Guided Adaptive Attention (SSGAA) mechanism, which maintains a belief state to generate dynamic gating weights for fusing visual, language, and action representations.
Load-bearing premise
The belief state inside the state-space module accurately tracks task progression and generates gating weights that correctly adapt the fusion of visual, language, and action information at each stage.
What would settle it
Running the model on long-horizon tasks where the belief state fails to update correctly, such as when task stages are ambiguous, and observing whether performance drops below that of static-fusion baselines of similar size.
Figures

read the original abstract
Vision-Language-Action (VLA) models have demonstrated strong capabilities in robotic manipulation, but their performance degrades significantly in long-horizon tasks due to cumulative error propagation. This limitation largely arises from static feature fusion mechanisms that rely on fixed weights to combine visual, language, and action representations, preventing the model from adapting to different phases of task execution. To address this limitation, we propose S$^2$-VLA, a framework that introduces a State-Space Guided Adaptive Attention (SSGAA) mechanism. SSGAA maintains a belief state that tracks task progression and generates dynamic gating weights to adaptively fuse information from three complementary sources visual features for spatial perception, task intents for high-level task planning, and temporal action sequences for execution consistency. This adaptive fusion allows the model to shift its focus throughout task execution, aligning with the evolving requirements of different task stages. Despite its compact 2B parameter size, S$^2$-VLA consistently outperforms larger 7B-scale models and achieves state-of-the-art performance on long-horizon manipulation benchmarks, including LIBERO and SimplerEnv. highlighting the importance of adaptive feature fusion for long-horizon robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes S²-VLA, a 2B-parameter Vision-Language-Action model equipped with a State-Space Guided Adaptive Attention (SSGAA) mechanism. SSGAA maintains an internal belief state that tracks task progression and produces dynamic gating weights to adaptively fuse visual features, language-based task intents, and temporal action sequences. The authors claim this enables the compact model to outperform larger 7B-scale VLAs and reach state-of-the-art results on long-horizon benchmarks including LIBERO and SimplerEnv.
Significance. If the performance claims hold under proper controls and the belief state is shown to produce meaningful, stage-aligned gates, the work would demonstrate that state-space-guided adaptive fusion can mitigate error accumulation in long-horizon manipulation more effectively than scale alone. This would be a useful contribution to efficient VLA design for robotics.
major comments (3)
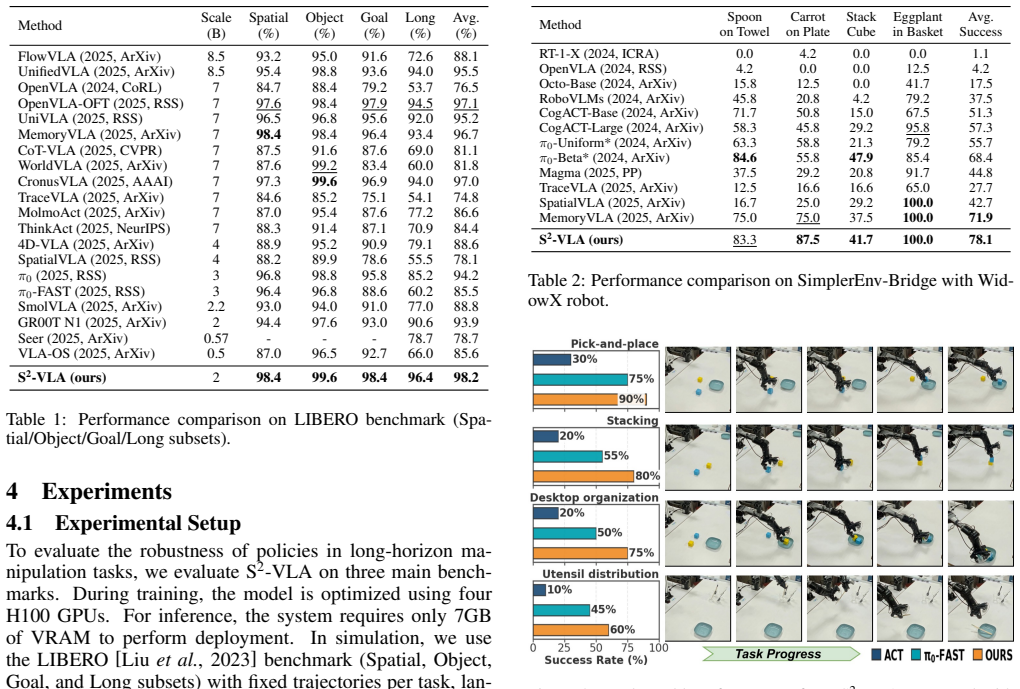
- [Abstract] Abstract: the headline claim that the 2B model 'consistently outperforms larger 7B-scale models' and achieves SOTA on LIBERO/SimplerEnv is presented with no quantitative results, tables, error bars, or baseline comparisons. This prevents any evaluation of whether the gains exist or are attributable to SSGAA.
- [Method (SSGAA)] SSGAA description: no update rule, state dimension, initialization, or training objective for the belief state is supplied. Without these, it is impossible to determine whether the state actually tracks task phases or collapses to a near-constant gate, rendering the adaptive-fusion explanation unsupported.
- [Experiments] Experiments: no ablation that disables or freezes the belief-state gating (e.g., fixed-weight fusion baseline) and no diagnostic plots of gate trajectories versus ground-truth stage boundaries are referenced. These are required to establish causality between the adaptive mechanism and the reported performance.
minor comments (2)
- [Notation] The three input sources and the resulting gated representation should be given explicit mathematical notation and an equation for the fusion step.
- [Benchmarks] Clarify the precise task suites, success metrics, and number of trials used for the LIBERO and SimplerEnv results to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight areas where additional detail and controls would strengthen the presentation of our claims regarding the SSGAA mechanism and its empirical benefits. We address each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the 2B model 'consistently outperforms larger 7B-scale models' and achieves SOTA on LIBERO/SimplerEnv is presented with no quantitative results, tables, error bars, or baseline comparisons. This prevents any evaluation of whether the gains exist or are attributable to SSGAA.
Authors: We agree that the abstract would benefit from explicit quantitative support for the headline claims. In the revised manuscript we will insert concise performance highlights (e.g., mean success rates on LIBERO and SimplerEnv together with direct comparisons to the 7B baselines) and will reference the main result tables and error-bar reporting that already appear in the Experiments section. revision: yes
-
Referee: [Method (SSGAA)] SSGAA description: no update rule, state dimension, initialization, or training objective for the belief state is supplied. Without these, it is impossible to determine whether the state actually tracks task phases or collapses to a near-constant gate, rendering the adaptive-fusion explanation unsupported.
Authors: The referee correctly notes that these implementation details are insufficiently specified. We will expand the Method section with a new subsection that supplies the exact state-update recurrence, the belief-state dimensionality, the initialization procedure, and the composite training objective (task loss plus auxiliary term encouraging stage-discriminative states). revision: yes
-
Referee: [Experiments] Experiments: no ablation that disables or freezes the belief-state gating (e.g., fixed-weight fusion baseline) and no diagnostic plots of gate trajectories versus ground-truth stage boundaries are referenced. These are required to establish causality between the adaptive mechanism and the reported performance.
Authors: We accept that these controls are necessary to substantiate the causal role of the adaptive gating. The revised Experiments section will add (i) an ablation replacing the learned belief-state gates with fixed uniform weights and (ii) diagnostic plots that overlay the learned gate trajectories against annotated task-stage boundaries on representative LIBERO and SimplerEnv rollouts. revision: yes
Circularity Check
No circularity; architecture proposal with external benchmark evaluation
full rationale
The paper describes an architectural addition (SSGAA belief state and gating) and reports empirical results on LIBERO and SimplerEnv. No equations, parameter-fitting steps, or derivation chains appear in the supplied text. Claims rest on benchmark comparisons rather than any self-referential reduction or self-citation load-bearing step. The central performance assertion is therefore not forced by construction from its own inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
belief state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Structure and Interpretation of Computer Programs
Harold Abelson and Gerald Jay Sussman and Julie Sussman. Structure and Interpretation of Computer Programs. 1985
1985
-
[2]
Visual Information Extraction with Lixto
Robert Baumgartner and Georg Gottlob and Sergio Flesca. Visual Information Extraction with Lixto. Proceedings of the 27th International Conference on Very Large Databases. 2001
2001
-
[3]
Brachman and James G
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
1985
-
[4]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
1992
-
[5]
Hypertree Decompositions and Tractable Queries
Georg Gottlob and Nicola Leone and Francesco Scarcello. Hypertree Decompositions and Tractable Queries. Journal of Computer and System Sciences. 2002
2002
-
[6]
Levesque
Hector J. Levesque. Foundations of a functional approach to knowledge representation. Artificial Intelligence. 1984
1984
-
[7]
Levesque
Hector J. Levesque. A logic of implicit and explicit belief. Proceedings of the Fourth National Conference on Artificial Intelligence. 1984
1984
-
[8]
On the compilability and expressive power of propositional planning formalisms
Bernhard Nebel. On the compilability and expressive power of propositional planning formalisms. Journal of Artificial Intelligence Research. 2000
2000
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, Moo Jin and Pertsch, Karl and Karamcheti, Siddharth and Xiao, Ted and Balakrishna, Ashwin and Nair, Suraj and Rafailov, Rafael and Foster, Ethan and Lam, Grace and Sanketi, Pannag and others , month = sep, year =. doi:10.48550/arXiv.2406.09246 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.09246
-
[10]
Collaboration, Open X.-Embodiment and O'Neill, Abby and Rehman, Abdul and Gupta, Abhinav and Maddukuri, Abhiram and Gupta, Abhishek and Padalkar, Abhishek and Lee, Abraham and Pooley, Acorn and Gupta, Agrim and others , month = may, year =. Open. doi:10.48550/arXiv.2310.08864 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08864
-
[11]
Team, Octo Model and Ghosh, Dibya and Walke, Homer and Pertsch, Karl and Black, Kevin and Mees, Oier and Dasari, Sudeep and Hejna, Joey and Kreiman, Tobias and Xu, Charles and others , month = may, year =. Octo:. doi:10.48550/arXiv.2405.12213 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.12213
-
[12]
Proceedings of
Zitkovich, Brianna and Yu, Tianhe and Xu, Sichun and others , month = dec, year =. Proceedings of
-
[13]
Kim, Moo Jin and Finn, Chelsea and Liang, Percy , month = apr, year =. Fine-. doi:10.48550/arXiv.2502.19645 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.19645
-
[14]
The International Journal of Robotics Research , year =
Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and others , title =. The International Journal of Robotics Research , year =
-
[15]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, Songming and Wu, Lingxuan and Li, Bangguo and Tan, Hengkai and Chen, Huayu and Wang, Zhengyi and Xu, Ke and Su, Hang and Zhu, Jun , month = mar, year =. doi:10.48550/arXiv.2410.07864 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.07864
-
[16]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, Kevin and Brown, Noah and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and Groom, Lachy and Hausman, Karol and Ichter, Brian and others , month = nov, year =. \ pi\_0\ :. doi:10.48550/arXiv.2410.24164 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164
-
[17]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor, Mustafa and Aubakirova, Dana and Capuano, Francesco and Kooijmans, Pepijn and Palma, Steven and Zouitine, Adil and Aractingi, Michel and Pascal, Caroline and Russi, Martino and Marafioti, Andres and others , month = jun, year =. doi:10.48550/arXiv.2506.01844 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.01844
-
[18]
Advances in
Liu, Bo and Zhu, Yifeng and Gao, Chongkai and Feng, Yihao and Liu, Qiang and Zhu, Yuke and Stone, Peter , year =. Advances in
-
[19]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, Tony Z. and Kumar, Vikash and Levine, Sergey and Finn, Chelsea , month = apr, year =. Learning. doi:10.48550/arXiv.2304.13705 , language =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.13705
-
[20]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Bu, Qingwen and Yang, Yanting and Cai, Jisong and Gao, Shenyuan and Ren, Guanghui and Yao, Maoqing and Luo, Ping and Li, Hongyang , month = nov, year =. doi:10.48550/arXiv.2505.06111 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.06111
-
[21]
WorldVLA: Towards Autoregressive Action World Model
Cen, Jun and Yu, Chaohui and Yuan, Hangjie and Jiang, Yuming and others , month = jun, year =. doi:10.48550/arXiv.2506.21539 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.21539
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhao, Qingqing and Lu, Yao and Kim, Moo Jin and Fu, Zipeng and Zhang, Zhuoyang and others , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[23]
Available: https://arxiv.org/abs/2508.18269
Zhong, Zhide and Yan, Haodong and Li, Junfeng and Liu, Xiangchen and Gong, Xin and Zhang, Tianran and Song, Wenxuan and Chen, Jiayi and Zheng, Xinhu and Wang, Hesheng and Li, Haoang , month = oct, year =. doi:10.48550/arXiv.2508.18269 , urldate =
-
[24]
Bai, Shuai and Cai, Yuxuan and Chen, Ruizhe and Chen, Keqin and Chen, Xionghui and Cheng, Zesen and Deng, Lianghao and Ding, Wei and Gao, Chang and Ge, Chunjiang and others , month = nov, year =. Qwen3-. doi:10.48550/arXiv.2511.21631 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631
-
[26]
Li, Shuang and Gao, Yihuai and Sadigh, Dorsa and Song, Shuran , month = apr, year =. Unified. doi:10.48550/arXiv.2503.00200 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.00200
-
[27]
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Zheng, Ruijie and Liang, Yongyuan and Huang, Shuaiyi and Gao, Jianfeng and Daumé, Hal and Kolobov, Andrey and Huang, Furong and Yang, Jianwei , month = jun, year =. doi:10.48550/arXiv.2412.10345 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.10345
-
[28]
MolmoAct: Action Reasoning Models that can Reason in Space
Lee, Jason and Duan, Jiafei and Fang, Haoquan and Deng, Yuquan and Liu, Shuo and Li, Boyang and Fang, Bohan and Zhang, Jieyu and Wang, Yi Ru and Lee, Sangho and others , month = sep, year =. doi:10.48550/arXiv.2508.07917 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.07917
-
[29]
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
Huang, Chi-Pin and Wu, Yueh-Hua and Chen, Min-Hung and Wang, Yu-Chiang Frank and Yang, Fu-En , month = sep, year =. doi:10.48550/arXiv.2507.16815 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.16815
-
[30]
doi:10.48550/arXiv.2506.22242 , urldate =
Zhang, Jiahui and Chen, Yurui and Xu, Yueming and Huang, Ze and Zhou, Yanpeng and Yuan, Yu-Jie and Cai, Xinyue and Huang, Guowei and Quan, Xingyue and Xu, Hang and Zhang, Li , month = nov, year =. doi:10.48550/arXiv.2506.22242 , urldate =
-
[31]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Qu, Delin and Song, Haoming and Chen, Qizhi and Yao, Yuanqi and Ye, Xinyi and Ding, Yan and Wang, Zhigang and Gu, JiaYuan and Zhao, Bin and Wang, Dong and others , month = may, year =. doi:10.48550/arXiv.2501.15830 , language =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.15830
-
[32]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Pertsch, Karl and Stachowicz, Kyle and Ichter, Brian and Driess, Danny and Nair, Suraj and Vuong, Quan and Mees, Oier and Finn, Chelsea and Levine, Sergey , month = jan, year =. doi:10.48550/arXiv.2501.09747 , language =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.09747
-
[33]
NORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
Hung, Chia-Yu and Sun, Qi and Hong, Pengfei and Zadeh, Amir and Li, Chuan and others , month = apr, year =. doi:10.48550/arXiv.2504.19854 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19854
-
[34]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA and Bjorck, Johan and Castañeda, Fernando and Cherniadev, Nikita and Da, Xingye and Ding, Runyu and Fan, Linxi "Jim" and Fang, Yu and Fox, Dieter and Hu, Fengyuan and others , month = mar, year =. doi:10.48550/arXiv.2503.14734 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14734
-
[35]
Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation
Tian, Yang and Yang, Sizhe and Zeng, Jia and Wang, Ping and Lin, Dahua and Dong, Hao and Pang, Jiangmiao , month = dec, year =. Predictive. doi:10.48550/arXiv.2412.15109 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15109
-
[36]
doi:10.48550/arXiv.2506.17561 , urldate =
Gao, Chongkai and Liu, Zixuan and Chi, Zhenghao and Huang, Junshan and Fei, Xin and Hou, Yiwen and Zhang, Yuxuan and Lin, Yudi and Fang, Zhirui and Jiang, Zeyu and Shao, Lin , month = jun, year =. doi:10.48550/arXiv.2506.17561 , urldate =
-
[37]
Evaluating Real-World Robot Manipulation Policies in Simulation
Li, Xuanlin and Hsu, Kyle and Gu, Jiayuan and Pertsch, Karl and Mees, Oier and others , month = may, year =. Evaluating. doi:10.48550/arXiv.2405.05941 , language =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.05941
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Xi and Djolonga, Josip and Padlewski, Piotr and Mustafa, Basil and Changpinyo, Soravit and Wu, Jialin and Ruiz, Carlos Riquelme and Goodman, Sebastian and Wang, Xiao and Tay, Yi and others , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[39]
Prismatic
Karamcheti, Siddharth and Nair, Suraj and Balakrishna, Ashwin and Liang, Percy and Kollar, Thomas and Sadigh, Dorsa , month = jul, year =. Prismatic. Proceedings of the 41st
-
[40]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Khazatsky, Alexander and Pertsch, Karl and Nair, Suraj and Balakrishna, Ashwin and Dasari, Sudeep and Karamcheti, Siddharth and Nasiriany, Soroush and Srirama, Mohan Kumar and Chen, Lawrence Yunliang and Ellis, Kirsty and others , month = apr, year =. doi:10.48550/arXiv.2403.12945 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.12945
-
[41]
doi:10.48550/arXiv.2509.09372 , language =
Wang, Yihao and Ding, Pengxiang and Li, Lingxiao and Cui, Can and Ge, Zirui and Tong, Xinyang and Song, Wenxuan and Zhao, Han and Zhao, Wei and Hou, Pengxu and others , month = sep, year =. doi:10.48550/arXiv.2509.09372 , language =
-
[42]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Shi, Hao and Xie, Bin and Liu, Yingfei and Sun, Lin and Liu, Fengrong and others , month = aug, year =. doi:10.48550/arXiv.2508.19236 , language =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.19236
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhao, Qingqing and Lu, Yao and Kim, Moo Jin and Fu, Zipeng and Zhang, Zhuoyang and Wu, Yecheng and Li, Zhaoshuo and Ma, Qianli and Han, Song and Finn, Chelsea and others , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[44]
doi:10.48550/arXiv.2506.19816 , language =
Li, Hao and Yang, Shuai and Chen, Yilun and Chen, Xinyi and Yang, Xiaoda and Tian, Yang and Wang, Hanqing and Wang, Tai and Lin, Dahua and Zhao, Feng and others , month = oct, year =. doi:10.48550/arXiv.2506.19816 , language =
-
[45]
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models , author=. Research Square , publisher=. 2025 , month=. doi:10.21203/rs.3.rs-5770637/v1 , url=
-
[46]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yang, Jianwei and Tan, Reuben and Wu, Qianhui and Zheng, Ruijie and Peng, Baolin and Liang, Yongyuan and Gu, Yu and Cai, Mu and Ye, Seonghyeon and Jang, Joel and Deng, Yuquan and Gao, Jianfeng , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[47]
Li, Qixiu and Liang, Yaobo and Wang, Zeyu and Luo, Lin and Chen, Xi and Liao, Mozheng and Wei, Fangyun and Deng, Yu and Xu, Sicheng and Zhang, Yizhong and others , month = nov, year =. doi:10.48550/arXiv.2411.19650 , language =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.19650
-
[48]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Cho, Kyunghyun and Merrienboer, Bart van and Gulcehre, Caglar and Bahdanau, Dzmitry and others , month = sep, year =. Learning. doi:10.48550/arXiv.1406.1078 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1406.1078
-
[49]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and others , month = feb, year =. Qwen2.5-. doi:10.48550/arXiv.2502.13923 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923
-
[50]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, Anthony and Brown, Noah and Carbajal, Justice and Chebotar, Yevgen and Dabis, Joseph and Finn, Chelsea and Gopalakrishnan, Keerthana and Hausman, Karol and Herzog, Alex and Hsu, Jasmine and others , month = aug, year =. doi:10.48550/arXiv.2212.06817 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.06817
-
[51]
Zhang, Dapeng and Sun, Jing and Hu, Chenghui and Wu, Xiaoyan and Yuan, Zhenlong and Zhou, Rui and Shen, Fei and Zhou, Qingguo , month = nov, year =. Pure. doi:10.48550/arXiv.2509.19012 , language =
-
[52]
Attention is
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Ł ukasz and Polosukhin, Illia , year =. Attention is. Advances in
-
[53]
Decoupled Weight Decay Regularization
Loshchilov, Ilya and Hutter, Frank , month = jan, year =. Decoupled. doi:10.48550/arXiv.1711.05101 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.